
Содержание
- Как в экселе найти фамилию в списке?
- Видео
- Определение пола по имени
- Вариант 1. Полные ФИО, только «наши»
- Вариант 2. Полные ФИО, есть «экспаты»
- Вариант 3. Неполные или переставленные ФИО, только «наши»
- Вариант 4. Неполные ФИО, есть «экспаты»
- Как в excel определить пол по фио
- Как отсортировать мужчин и женщин в Excel?
- Определить пол по отчеству
- Определить пол по ФИО
- Как определить пол по отчеству в excel
- Как определить пол подписчика для email-рассылки
- Первый метод: определение пола по ФИО
- Определение пола для базы с некорректными или нетипичными именами/отсутствующим отчеством
- Второй метод: определение пола подписчика с опорой на базу имен
- Фильтрация по полу и исправление данных в системе eSputnik
Как в экселе найти фамилию в списке?
Давайте разберемся, как можно найти фамилию в списке в программе эксель. Сделаем это на конкретном примере, перед нами таблица, состоящая из десяти ФИО, нам нужно найти людей с фамилией Сидоренко.

Первый способ.
Воспользуемся фильтром, чтобы найти нужную фамилию. Для этого выделим ячейку «А1», а на верхней панели настроек перейдем во вкладку «Данные», где нажмем на иконку в виде воронки и имеющую подпись «Филтьр».

В ячейке «А1» появится слева стрелочка, нужно нажать и перед вами откроется меню. Нажмем на строчку «Текстовые фильтры», в появившемся списке выберем строку «Содержит».

В появившемся меню, наберем фамилию Сидоренко, после нажмем на кнопку «ОК».

В итоге таблица отформатируется, и останутся только люди с фамилией Сидоренко.

Второй способ.
Снова перед нами та же табличка, только теперь нажмем на клавиатуре сочетание клавиш «Ctrl+F», а в строке «Найти» наберем слово «Сидоренко». После нажимаем на кнопку «Найти все». В нижней части меню, отразиться адреса ячеек, в которых содержится фамилия Сидоренко.

Видео
Источник
Определение пола по имени
Классическая задача, с которой периодически сталкивается почти любой пользователь Microsoft Excel: нужно определить пол для каждого человека в списке. Давайте рассмотрим несколько решений для такой задачи.
Вариант 1. Полные ФИО, только «наши»
Начнем, для разогрева, с самого простого случая, когда у нас есть правильно записанные полные ФИО для всех людей в списке. Как легко сообразить, для большинства жителей бывшего СНГ тут сработает простой принцип: «если отчество оканчивается на Ч, то это мужчина, в противном случае — женщина». Реализовать эту логику можно простой формулой:
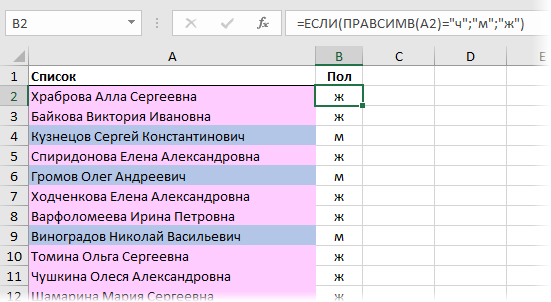
Функция ПРАВСИМВ (RIGHT) извлекает из ФИО один символ справа (последнюю букву отчества), а функция ЕСЛИ (IF) проверяет извлеченный символ и выводит «ж» или «м», в зависимости от результата проверки.
Вариант 2. Полные ФИО, есть «экспаты»
Если в списке есть имена не только русского типа (назовем их «экспаты»), то к приведенной ранее формуле можно добавить еще одну проверку, чтобы отлавливать их тоже:
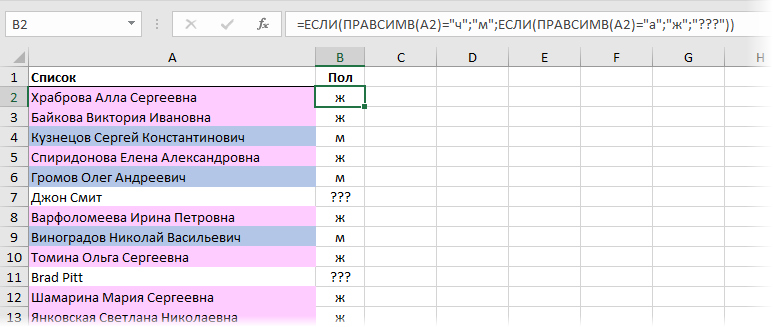
То есть «м» будет выводиться только если отчество заканчивается на Ч, «ж» — если заканчивается на А. Во всех же остальных случаях («экспаты») наша формула выдаст три вопросительных знака.
Вариант 3. Неполные или переставленные ФИО, только «наши»
Если в нашем списке отчества есть не у всех (или их нет совсем) или ФИО идет в другом порядке (ИФО, ИФ, ФИ), то придется использовать принципиально другой подход. Создадим таблицу-справочника со всеми женскими именами (я использовал для этого википедию):
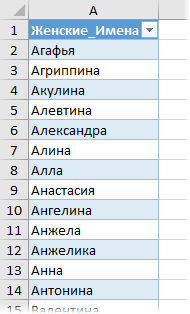
Созданную таблицу я преобразовал в «умную» (выделить ее и нажать Ctrl+T), чтобы потом не думать про ее размеры и дополнять справочник новыми именами в любое время. На появившейся вкладке Конструктор (Design) умной таблице лучше дать отдельное имя (например жен), чтобы потом использовать его в формулах:
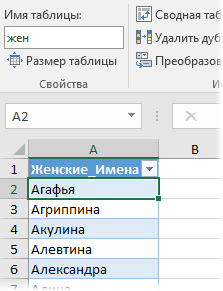
Нужная нам формула для определения пола будет выглядеть так:
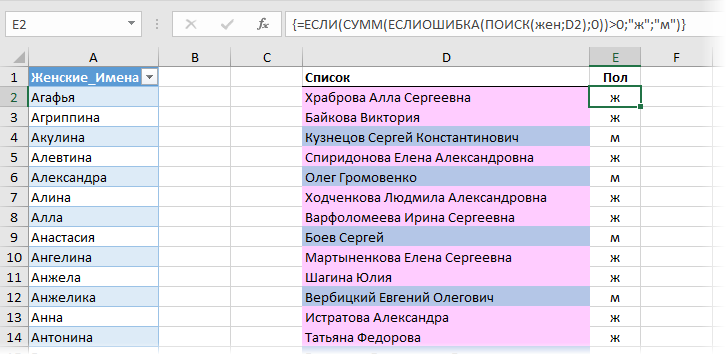
Давайте разберем ее по шагам на примере первого человека:
Функция ПОИСК (SEARCH) ищет вхождения по очереди каждого женского имени из умной таблицы жен в строку «Храброва Алла Сергеевна» и выдает на выходе либо ошибку #ЗНАЧ (если не нашла), либо порядковый номер символа, начиная с которого имя входит в ФИО. На выходе мы получаем массив:
<#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!: 10 :#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!: #ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:
#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!: #ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:
#ЗНАЧ!: #ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!: #ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:
#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!: #ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:
#ЗНАЧ!: #ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!:#ЗНАЧ!>
Число 10 на седьмой позиции в этом массиве фактически означает, что седьмое женское имя Алла из умной таблицы-справочника входит в первое ФИО Храброва Алла Сергеевна начиная с 10 символа.
Затем функция ЕСЛИОШИБКА (IFERROR) заменяет ошибки #ЗНАЧ! на нули. В результате получаем:
Функция СУММ (SUM) суммирует все числа в получившемся массиве и если получается число больше нуля, то функция ЕСЛИ (IF) выводит «ж», в противном случае «м».
Не забудьте после ввода формулы нажать сочетание клавиш Ctrl+Shift+Enter, т.к. ее нужно ввести как формулу массива.
Вариант 4. Неполные ФИО, есть «экспаты»
Если в списке могут встречаться экспаты или нестандартные имена, которых нет в справочнике, то предыдущая формула будет автоматом относить человека к мужчинам, что не есть хорошо. Поэтому для полной универсальности можно добавить справочник мужских имен и еще одну проверку, как мы уже делали в варианте-2:
Источник
Как в excel определить пол по фио
Как отсортировать мужчин и женщин в Excel?
В списке Excel, содержащем имена, отчества и фамилии, отсортировать мужчин от женщин можно довольно просто. Достаточно определить последнюю букву в отчестве человека, чтобы узнать его пол.
Как правило, если отчество заканчивается буквой «ч», это означает, что владелец этого отчества — мужчина, например, Иванович, Петрович, Альбертович. Конечно, возможны и исключения, например, отчество Талгатулы не заканчивается буквой «ч», хотя и является мужским. Для быстрого определения половой принадлежности воспользуемся одной из двух функций.
Определить пол по отчеству
Если исходным значением для определения пола является отчество, то есть отчество записано в отдельной ячейке, можно прибегнуть к помощи функции:
По мере появления исключений из правила, можно внести изменения в программный код функции, например, чтобы отчество Талгатулы определялось как мужское, в строке 04 после буквы «ч» через запятую добавлена буква «ы».
Представленные функции возвращают «М» либо «Ж» в зависимости от последней буквы в отчестве.
Определить пол по ФИО
Если исходным значением для определения пола является полное ФИО, то предварительно ФИО нужно разделить на части, вычленить из него отчество и далее действовать по аналогии с уже рассмотренным выше примером.
Когда во всем списке Excel пол определен, отсортировать мужчин от женщин при помощи стандартной сортировки Excel не составит никакого труда. Надстройку, которая добавляет рассмотренные функции в категорию «Определенные пользователем» можно скачать бесплатно.
Как определить пол по отчеству в excel
 Группировка массива по возрасту, имени или фамилии
Группировка массива по возрасту, имени или фамилии
Нужно написать функцию, которая будет группировать массив по возрасту, имени или фамилии. Функция.
Изменение введённой фамилии при выборе пола
Всем привет, встала задача организовать изменение введённой фамилии при выборе пола в моей БД: .
Как определить пол подписчика для email-рассылки
Сегментация по полу является базовой в постоянной коммуникации с подписчиками. Оправка релевантных предложений мужчинам и женщинам стимулирует продажи и сокращает затраты за счет исключения отправки писем не тем людям.
Когда форма подписки не предусматривает фиксацию пола клиента, подписчики намеренно не указывают его или есть любые другие обстоятельства, из-за которых у вас нет этой информации – воспользуйтесь Excel или Google-таблицами для определения пола. К сожалению, их возможности не безграничны. С ошибками из-за опечаток, неславянскими или редкими именами придется поработать вручную, но благодаря фильтрации и первичной проработке списка это будет гораздо быстрее.
Первый метод: определение пола по ФИО
Ситуация идеальная, но все-таки встречается. Речь идет о базе, где есть фамилия, имя, отчество и они записаны в правильном порядке. В нашем случае информацию о ФИО нужно разместить в одной колонке. Традиционно все славянские отчества женщин заканчиваются на “а”, а мужские – на “ч”.
Для получения правильного значения пола воспользуйтесь в таблице функцией, которая извлекает заданное количество символов, а если его не указать, то она извлечет один последний символ справа – ПРАВСИМВ (в английском интерфейсе – RIGHT). И для замены “а” на “Ж” и “ч” на “М”, чтобы сразу писалось правильное значение пола, а не окончания отечеств, применим функцию ЕСЛИ (IF).
Получится следующая формула: =ЕСЛИ(ПРАВСИМВ(A2)=»ч»;»М»;»Ж»):
.png)
Вставьте ее в первую ячейку столбца для пола. Нажмите Enter и протяните вниз до конца списка значение первой ячейки, чтобы напротив каждого имени появился пол:
.png)
Определение пола для базы с некорректными или нетипичными именами/отсутствующим отчеством
Описанная выше функция сработает некорректно, если в списке есть редкие, иностранные имена или отчества не указаны вовсе. Так как последняя буква в данных не “ч”, соответственно, контактам будет проставлен пол “Ж”, что часто не соответствует действительности.
.png)
Откорректируйте формулу, и укажите, что если последняя буква “ч”, то определяем контакт как мужчину, если “а” – как женщину, а если окончание ФИО не “а” и не “ч”, то выводим знаки вопроса “. ”, чтобы потом поработать с этими данными.
Функция будет выглядеть так: =ЕСЛИ(ПРАВСИМВ(A2)=«ч»;«М»;ЕСЛИ(ПРАВСИМВ(A2)=«а»;«Ж»;«. «))
Протяните формулу до конца списка.
.png)
В результате получим ряд строк с неизвестным значением пола, и можем поработать с ними отдельно. Чтобы выделить нужные строки, отфильтруйте их из основного массива. Выделите шапку с названием столбцов:
.png)
Откройте вкладку “Данные” и выберите пункт “Создать фильтр”:
.png)
При помощи фильтра выведите на странице только строки с неопределенным полом. Для этого нужно снять галочки с других значений:
.png)
В списке будут видны:
- имена с ошибками,
- иностранцы,
- контакты с неполными данными (например, только имя), для которых первый описанный метод не может правильно определить пол.
.png)
Проставьте, где знаете, пол вручную.
Второй метод: определение пола подписчика с опорой на базу имен
Этот способ определения пола больше приближен к реальной ситуации, так как подписчики часто оставляют только имена, меняют местами имя и фамилию, пишут выдуманные имена и т. д. Воспользуйтесь формулой массива для проверки каждого ФИО на вхождение в него мужских или женских имен.
Предварительно создайте 2 столбца: один – с женскими именами, второй – с мужскими. Список можно найти в любой доступной базе в интернете. Для автоматизации последующей работы сделайте списки с именами отдельными умными таблицами (функция доступна в Microsoft Excel после выделения ячеек и нажатия сочетания клавиш Ctrl+T). Это позволит вносить новые имена в конец таблицы и использовать их в формулах, не выделяя каждый раз нужный диапазон и не фиксируя ссылки.
.png)
Во вкладке “Конструктор” переименуйте таблицы в “жен” и “муж” для удобства дальнейшей работы и сокращения формулы.
.png)
Пропишите функцию: =ЕСЛИ(СУММ(ЕСЛИОШИБКА(ПОИСК(жен;E2);0))>0;»ж»;ЕСЛИ(СУММ(ЕСЛИОШИБКА(ПОИСК(муж;E2);0))>0;»м»;». «))
Формула включает в себя проверку на наличие имени в обоих списках имен. E2 – первая ячейка столбца с проверяемыми контактами.
Так как в данном случае мы работаем с массивом, то вместо Enter нажмите сочетание клавиш Ctrl+Shift+Enter. Протяните значение вниз.
Получаем наиболее точный результат:
.png)
Отфильтруйте поля со знаками вопросов и проставьте им пол вручную.
Фильтрация по полу и исправление данных в системе eSputnik
Работа с таблицами – достаточно трудоемкий процесс. Имея список с проставленным полом, можно переходить к его импорту в систему. Для полноценной работы с контактами создавайте сегменты по полу, используйте в письмах персонализацию по имени.
Вы можете автоматизировать работу с именами и создавать группы с учетом гендерной принадлежности подписчика прямо в системе eSputnik. Она будет анализировать ошибки в полном имени и определять пол. В вашу рассылку не попадут Колян, Саня, тем самым защитив вас от казуса. Для этого в “Лаборатории” (настройки аккаунта) нажмите кнопку “Добавить пол” и “Добавить точное имя”.
Определить пол подписчиков в eSputnik
.png)
Теперь, когда в каждой карточке контакте указан пол, создайте две условные группы: отдельно с мужчинами, отдельно с женщинами. Сегментированные рассылки дадут вам больше конверсий и сэкономят затраты за счет исключения отправки сообщений нецелевой аудитории. Отправляйте мужскую коллекцию мужчинам и женскую – женщинам, помогайте мужчинам сделать приятные подарки своим дамам к празднику.
.png)
Автоматизируйте работу с подписчиками – это экономически выгодно, а персональные предложения сделают ваших покупателей более удовлетворенными.
Источник
|
cobraN Пользователь Сообщений: 10 |
Привет. В экселе почти не разбираюсь. Как сделать, чтобы на листе «Прайс» в графе «Фамилия» я ввожу «Фамилию Имя» и должен появляться «Номер ID» из листа «База», присвоенный к этой фамилии. И как быть с повторами? Допустим, уже есть такая «Фамилия Имя», но номера у людей разные. Спасибо. Файл-пример прикрепил. Админы, не закрывайте тему, а лучше помогите! |
|
cobraN Пользователь Сообщений: 10 |
Хочу добавить, что некоторые люди не знают свой ИД, поэтому я хочу сделать такую базу по фамилии. Их номера записаны у меня в отдельном файле, но каждый раз просматривать их и искать очень долго. Там больше 1500 человек |
|
Alsu Пользователь Сообщений: 31 |
Можно сделать через ВПР, но для этого нужно, чтобы присутсвовал ещё один признак. Или связные выпадающие списки. |
|
cobraN Пользователь Сообщений: 10 |
{quote}{login=Мяу™}{date=06.08.2010 10:19}{thema=Автоматический поиск номера по фамилии в др. ячейке}{post}Можно сделать через ВПР, но для этого нужно, чтобы присутсвовал ещё один признак. Или связные выпадающие списки.{/post}{/quote} Не могли бы написать точную формулу? Я в них ничего не понимаю( |
|
VistaS Пользователь Сообщений: 33 |
{quote}{login=cobraN}{date=06.08.2010 10:30}{thema=Re: Автоматический поиск номера по фамилии в др. ячейке}{post}{quote}{login=Мяу™}{date=06.08.2010 10:19}{thema=Автоматический поиск номера по фамилии в др. ячейке}{post}Можно сделать через ВПР, но для этого нужно, чтобы присутсвовал ещё один признак. Или связные выпадающие списки.{/post}{/quote} Не могли бы написать точную формулу? Я в них ничего не понимаю({/post}{/quote} |
|
На листе База — скрытый дополнительный столбец С. |
|
|
cobraN Пользователь Сообщений: 10 |
{quote}{login=VistaS}{date=06.08.2010 10:54}{thema=Re: Re: Автоматический поиск номера по фамилии в др. ячейке}{post}{quote}{login=cobraN}{date=06.08.2010 10:30}{thema=Re: Автоматический поиск номера по фамилии в др. ячейке}{post}{quote}{login=Мяу™}{date=06.08.2010 10:19}{thema=Автоматический поиск номера по фамилии в др. ячейке}{post}Можно сделать через ВПР, но для этого нужно, чтобы присутсвовал ещё один признак. Или связные выпадающие списки.{/post}{/quote} Не могли бы написать точную формулу? Я в них ничего не понимаю({/post}{/quote} У нас американская компания и отчеств нет). Первая формула у меня не работает, а если ввожу вторую, то при пустом значении пишется Н.Д с ошибкой. Как устранить? П.С. кто-нибудь может доработать эту форуму до совершенства? |
|
cobraN Пользователь Сообщений: 10 |
|
|
VistaS Пользователь Сообщений: 33 |
=ЕСЛИ(C4>0;ИНДЕКС(База!A:B;ПОИСКПОЗ(Прайс!C4;База!B:B;0);1);»»)чтобы не было Н/Д |
|
{quote}{login=VistaS}{date=06.08.2010 11:17}{thema=}{post}=ЕСЛИ(C4>0;ИНДЕКС(База!A:B;ПОИСКПОЗ(Прайс!C4;База!B:B;0);1);»»)чтобы не было Н/Д Нет)) Если только попробовать сделать раскрывающийся список, когда будут вводить фамилию, на которой несколько номеров, где в списке будут появляться только те номера, которые присвоины той фамилии |
|
|
А в таком виде формула не будет выдавать Н/Д и когда введённой фамилии нет в базе |
|
|
vikttur Пользователь Сообщений: 47199 |
#12 09.08.2010 13:35:30 Вариант. Прикрепленные файлы
|
В списке Excel, содержащем имена, отчества и фамилии, отсортировать мужчин от женщин можно довольно просто. Достаточно определить последнюю букву в отчестве человека, чтобы узнать его пол.
Как правило, если отчество заканчивается буквой «ч», это означает, что владелец этого отчества — мужчина, например, Иванович, Петрович, Альбертович. Конечно, возможны и исключения, например, отчество Талгатулы не заканчивается буквой «ч», хотя и является мужским. Для быстрого определения половой принадлежности воспользуемся одной из двух функций.
Определить пол по отчеству
Если исходным значением для определения пола является отчество, то есть отчество записано в отдельной ячейке, можно прибегнуть к помощи функции:
По мере появления исключений из правила, можно внести изменения в программный код функции, например, чтобы отчество Талгатулы определялось как мужское, в строке 04 после буквы «ч» через запятую добавлена буква «ы».
Представленные функции возвращают «М» либо «Ж» в зависимости от последней буквы в отчестве.
Определить пол по ФИО
Если исходным значением для определения пола является полное ФИО, то предварительно ФИО нужно разделить на части, вычленить из него отчество и далее действовать по аналогии с уже рассмотренным выше примером.
Когда во всем списке Excel пол определен, отсортировать мужчин от женщин при помощи стандартной сортировки Excel не составит никакого труда. Надстройку, которая добавляет рассмотренные функции в категорию «Определенные пользователем» можно скачать бесплатно.
Как определить пол по отчеству в excel
Группировка массива по возрасту, имени или фамилии
Нужно написать функцию, которая будет группировать массив по возрасту, имени или фамилии. Функция.
Изменение введённой фамилии при выборе пола
Всем привет, встала задача организовать изменение введённой фамилии при выборе пола в моей БД: .
Как определить пол подписчика для email-рассылки
Сегментация по полу является базовой в постоянной коммуникации с подписчиками. Оправка релевантных предложений мужчинам и женщинам стимулирует продажи и сокращает затраты за счет исключения отправки писем не тем людям.
Когда форма подписки не предусматривает фиксацию пола клиента, подписчики намеренно не указывают его или есть любые другие обстоятельства, из-за которых у вас нет этой информации – воспользуйтесь Excel или Google-таблицами для определения пола. К сожалению, их возможности не безграничны. С ошибками из-за опечаток, неславянскими или редкими именами придется поработать вручную, но благодаря фильтрации и первичной проработке списка это будет гораздо быстрее.
Первый метод: определение пола по ФИО
Ситуация идеальная, но все-таки встречается. Речь идет о базе, где есть фамилия, имя, отчество и они записаны в правильном порядке. В нашем случае информацию о ФИО нужно разместить в одной колонке. Традиционно все славянские отчества женщин заканчиваются на “а”, а мужские – на “ч”.
Для получения правильного значения пола воспользуйтесь в таблице функцией, которая извлекает заданное количество символов, а если его не указать, то она извлечет один последний символ справа – ПРАВСИМВ (в английском интерфейсе – RIGHT). И для замены “а” на “Ж” и “ч” на “М”, чтобы сразу писалось правильное значение пола, а не окончания отечеств, применим функцию ЕСЛИ (IF).
Получится следующая формула: =ЕСЛИ(ПРАВСИМВ(A2)=»ч»;»М»;»Ж»):
Вставьте ее в первую ячейку столбца для пола. Нажмите Enter и протяните вниз до конца списка значение первой ячейки, чтобы напротив каждого имени появился пол:
Определение пола для базы с некорректными или нетипичными именами/отсутствующим отчеством
Описанная выше функция сработает некорректно, если в списке есть редкие, иностранные имена или отчества не указаны вовсе. Так как последняя буква в данных не “ч”, соответственно, контактам будет проставлен пол “Ж”, что часто не соответствует действительности.
Откорректируйте формулу, и укажите, что если последняя буква “ч”, то определяем контакт как мужчину, если “а” – как женщину, а если окончание ФИО не “а” и не “ч”, то выводим знаки вопроса “. ”, чтобы потом поработать с этими данными.
Функция будет выглядеть так: =ЕСЛИ(ПРАВСИМВ(A2)=«ч»;«М»;ЕСЛИ(ПРАВСИМВ(A2)=«а»;«Ж»;«. «))
Протяните формулу до конца списка.
В результате получим ряд строк с неизвестным значением пола, и можем поработать с ними отдельно. Чтобы выделить нужные строки, отфильтруйте их из основного массива. Выделите шапку с названием столбцов:
Откройте вкладку “Данные” и выберите пункт “Создать фильтр”:
При помощи фильтра выведите на странице только строки с неопределенным полом. Для этого нужно снять галочки с других значений:
В списке будут видны:
- имена с ошибками,
- иностранцы,
- контакты с неполными данными (например, только имя), для которых первый описанный метод не может правильно определить пол.
Проставьте, где знаете, пол вручную.
Второй метод: определение пола подписчика с опорой на базу имен
Этот способ определения пола больше приближен к реальной ситуации, так как подписчики часто оставляют только имена, меняют местами имя и фамилию, пишут выдуманные имена и т. д. Воспользуйтесь формулой массива для проверки каждого ФИО на вхождение в него мужских или женских имен.
Предварительно создайте 2 столбца: один – с женскими именами, второй – с мужскими. Список можно найти в любой доступной базе в интернете. Для автоматизации последующей работы сделайте списки с именами отдельными умными таблицами (функция доступна в Microsoft Excel после выделения ячеек и нажатия сочетания клавиш Ctrl+T). Это позволит вносить новые имена в конец таблицы и использовать их в формулах, не выделяя каждый раз нужный диапазон и не фиксируя ссылки.
Во вкладке “Конструктор” переименуйте таблицы в “жен” и “муж” для удобства дальнейшей работы и сокращения формулы.
Пропишите функцию: =ЕСЛИ(СУММ(ЕСЛИОШИБКА(ПОИСК(жен;E2);0))>0;»ж»;ЕСЛИ(СУММ(ЕСЛИОШИБКА(ПОИСК(муж;E2);0))>0;»м»;». «))
Формула включает в себя проверку на наличие имени в обоих списках имен. E2 – первая ячейка столбца с проверяемыми контактами.
Так как в данном случае мы работаем с массивом, то вместо Enter нажмите сочетание клавиш Ctrl+Shift+Enter. Протяните значение вниз.
Получаем наиболее точный результат:
Отфильтруйте поля со знаками вопросов и проставьте им пол вручную.
Фильтрация по полу и исправление данных в системе eSputnik
Работа с таблицами – достаточно трудоемкий процесс. Имея список с проставленным полом, можно переходить к его импорту в систему. Для полноценной работы с контактами создавайте сегменты по полу, используйте в письмах персонализацию по имени.
Вы можете автоматизировать работу с именами и создавать группы с учетом гендерной принадлежности подписчика прямо в системе eSputnik. Она будет анализировать ошибки в полном имени и определять пол. В вашу рассылку не попадут Колян, Саня, тем самым защитив вас от казуса. Для этого в “Лаборатории” (настройки аккаунта) нажмите кнопку “Добавить пол” и “Добавить точное имя”.
Определить пол подписчиков в eSputnik
Теперь, когда в каждой карточке контакте указан пол, создайте две условные группы: отдельно с мужчинами, отдельно с женщинами. Сегментированные рассылки дадут вам больше конверсий и сэкономят затраты за счет исключения отправки сообщений нецелевой аудитории. Отправляйте мужскую коллекцию мужчинам и женскую – женщинам, помогайте мужчинам сделать приятные подарки своим дамам к празднику.
Автоматизируйте работу с подписчиками – это экономически выгодно, а персональные предложения сделают ваших покупателей более удовлетворенными.
Содержание:
- Извлечь и отсортировать по фамилии с помощью функции поиска и замены
- Извлечь и расположить в алфавитном порядке по фамилии с помощью формулы
- Использование текста в столбцы
- Использование Flash Fill
Если вы работаете с наборами данных имен, сортировка — одна из распространенных задач, которые вам придется часто выполнять.
Сортировать данные в алфавитном порядке по полному имени довольно просто, а Excel использует первый символ имени для сортировки.
Но что, если ты хочешь сортировать данные по фамилии в Excel?
Хотя это не так просто, но все же можно сделать (многое также зависит от того, как структурированы данные об именах).
Независимо от того, какой метод вы используете, вам придется каким-то образом извлечь фамилию из полного имени и поместить ее в отдельный столбец. Затем вы можете использовать этот столбец для сортировки данных по фамилии в алфавитном порядке.
В этом руководстве по Excel я покажу вам, как отсортировать столбец с именами на основе фамилии.
Итак, приступим!
Извлечь и отсортировать по фамилии с помощью функции поиска и замены
Первый шаг к сортировке по фамилии — занести фамилию в отдельный столбец.
Вы можете сделать это, заменив все перед фамилией пробелом, чтобы у вас осталась только фамилия.
Предположим, у вас есть набор данных, показанный ниже, и вы хотите отсортировать эти данные в алфавитном порядке по фамилии.

Ниже приведены шаги для сортировки по фамилии:
- Выберите набор данных, включая заголовок (в этом примере это будет A1: A10)
- Скопируйте его в соседний столбец (если соседний столбец не пустой, вставьте новый столбец, а затем скопируйте эти имена)

- Переименуйте скопированный заголовок столбца. В этом примере я назову «Фамилия».
- Выделите все скопированные имена (не выбирайте заголовок)
- Удерживая клавишу Ctrl, нажмите клавишу H. Откроется диалоговое окно «Найти и заменить».
- В поле «Найти» введите * (символ звездочки, за которым следует пробел).
- Оставьте поле «Заменить на» пустым.
- Нажмите «Заменить все». Это мгновенно заменит все имя, и у вас останутся только фамилии.





Вышеупомянутые шаги сохранят фамилию и удалят все, что перед ней. Это хорошо работает, даже если у вас есть отчество или префиксы (например, Mr. или Ms).

Если у вас есть фамилии в соседнем столбце, вы можете легко отсортировать набор данных (включая полные имена) в алфавитном порядке по фамилии.
Ниже приведены шаги для сортировки по фамилии:
- Выберите весь набор данных с заголовками (включая полные имена и извлеченные фамилии). Вы также можете включить другие столбцы, которые хотите отсортировать, вместе с именами
- Перейдите на вкладку «Данные».
- Нажмите на Сортировать
- Убедитесь, что в диалоговом окне «Сортировка» выбрано «Мои данные имеют заголовки».
- В параметре «Сортировать по» выберите имя столбца, в котором есть только фамилия.
- В поле «Сортировка по» выберите «Значения ячеек».
- В разделе «Порядок» выберите «От А до Я».
- Нажмите ОК.





Вышеупомянутые шаги сортируют весь выбранный набор данных по фамилии.

После этого вы можете удалить столбец с фамилией.
Совет профессионала: В любой момент времени, если вы думаете, что вам может понадобиться вернуть исходные данные, вам нужно иметь способ распаковать этот набор данных. Для этого в соседнем столбце (левом или правом) укажите порядковые номера перед сортировкой. Теперь, если вам нужно вернуть исходные данные, вы получите их путем сортировки по числам.
Извлечь и расположить в алфавитном порядке по фамилии с помощью формулы
Хотя я предпочитаю получать все фамилии и сортировать на их основе метод, показанный выше (с использованием поиска и замены), одним из его ограничений является то, что результирующие данные статичны.
Это означает, что если я добавлю больше имен в свой список, мне придется повторить тот же процесс еще раз, чтобы получить фамилии.
Если вам это не нужно, вы можете использовать метод формулы для сортировки данных по фамилиям.
Предположим, у вас есть набор данных, как показано ниже.

Ниже приведена формула, которая извлечет фамилию из полного имени:= ВПРАВО (A2; LEN (A2) -FIND (""; A2))
Вышеупомянутая формула основана на шаблоне с полным именем (который в этом примере содержит только имя и фамилию). Шаблон состоит в том, что между именем и фамилией будет пробел.
Функция НАЙТИ используется для получения позиции символа пробела. Затем это значение вычитается из общей длины имени, чтобы получить общее количество символов в фамилии.
Это значение затем используется в функции ВПРАВО для получения фамилии.
Когда у вас есть столбец с фамилией, вы можете отсортировать эти данные (это подробно рассматривается в первом методе).
Приведенная выше формула будет работать, если у вас есть только имя и фамилия.
Но что, если у вас есть отчество? Или перед именем может стоять приветствие (например, г-н или г-жа).
В таком случае вам нужно использовать следующую формулу:= ПРАВО (A2; LEN (A2) -НАЙТИ ("@", ПОДСТАВИТЬ (A2, "", "@", LEN (A2) -LEN (ПОДСТАВИТЬ (A2, "", ""))))))
Приведенная выше формула находит позицию последнего символа пробела и затем использует ее для извлечения фамилии.
Я рекомендую вам использовать вторую формулу во всех случаях, она более надежна и может обрабатывать все случаи (если фамилия стоит в конце имени).
Примечание. Эти две формулы основаны на условии, что между каждым элементом имени есть только один пробел. Если есть двойные пробелы или начальные / конечные пробелы, эта формула даст неверные результаты. В таком случае лучше всего использовать функцию TRIM, чтобы сначала избавиться от любых начальных, конечных и двойных пробелов, а затем использовать приведенную выше формулу.
Хотя это может показаться сложным методом, преимущество использования формулы состоит в том, что она делает результаты динамичными. Если вы добавите больше имен в свой список, все, что вам нужно сделать, это скопировать формулу, и она даст вам фамилию.
Использование текста в столбцы
Текст в столбцы — это снова простой и легкий способ разбить ячейки в Excel.
Вы можете указать разделитель (например, запятую или пробел) и использовать его для разделения содержимого ячейки. После того, как у вас есть разделенные элементы в отдельных столбцах, вы можете использовать столбец с фамилией, чтобы расположить данные в алфавитном порядке.
Предположим, у вас есть набор данных, как показано ниже:
Ниже приведены шаги по использованию текста в столбец для сортировки по фамилии:
- Выберите столбец с именем (без заголовка)
- Перейдите на вкладку «Данные».
- В группе «Инструменты для работы с данными» выберите параметр «Преобразование текста в столбцы». Откроется мастер текста в столбцы.
- На шаге 1 «Мастера преобразования текста в столбцы» выберите «С разделителями» и нажмите «Далее».
- На шаге 2 выберите «Пробел» в качестве разделителя (и снимите все флажки, если они выбраны), а затем нажмите кнопку «Далее».
- На шаге 3 выберите первый столбец имени в окне предварительного просмотра данных, а затем выберите параметр «Не импортировать столбцы (пропустить)». Это гарантирует, что имя не будет частью результата, а вы получите только фамилию.
- Также на шаге 3 измените целевую ячейку на ту, которая находится рядом с исходными данными. Это гарантирует, что вы получите фамилию отдельно, а исходные данные об именах останутся нетронутыми.
- Нажмите Готово





Получив результат, вы можете отсортировать его по фамилии.

Вы также можете преобразовать текст в столбцы, чтобы разделить имя и фамилию, если у вас есть запятая в качестве разделителя.
Использование Flash Fill
Еще один быстрый способ получить фамилии — использовать функцию Flash Fill.
Flash Fill был представлен в Excel 2013 и помогает манипулировать данными путем выявления шаблонов. Чтобы это сработало, вам нужно пару раз показать ожидаемый результат Flash Fill.
Как только он определит шаблон, он быстро сделает остальную работу за вас.
Предположим, у вас есть набор данных с именами ниже.

Ниже приведены шаги по использованию Flash Fill для получения фамилии и последующей сортировки по ней:
- В ячейке B2 введите текст «Мори». Это результат, который вы ожидаете в ячейке.
- Перейдите в следующую ячейку и введите фамилию для имени в соседней ячейке (Эллиот в этом примере).
- Выберите обе ячейки
- Наведите курсор на правую нижнюю часть выделения. Вы заметите, что курсор изменится на значок плюса.
- Дважды щелкните по нему (или щелкните и перетащите его вниз). Это даст вам какой-то результат в ячейках (вряд ли это будет тот результат, который вам нужен)
- Щелкните значок «Параметры автозаполнения».
- Нажмите на Flash Fill.



Это даст вам результат, который, скорее всего, будет фамилиями во всех ячейках.
Я говорю «вероятно», поскольку в некоторых случаях Flash Fill может не работать. Поскольку это зависит от определения шаблона, это не всегда удается. Или иногда, шаблон, который он расшифровывает, может быть неправильным.
В таких случаях следует ввести ожидаемый результат еще в одну или две ячейки, а затем выполнить шаги 4-7.
Когда у вас есть все фамилии в столбце, вы можете отсортировать данные на основе этих фамилий.
Итак, это четыре разных способа сортировки данных по фамилии. Лучшим способом было бы использовать технику «Найти и заменить», но если вы хотите сделать свои результаты динамическими, лучше всего подойдет метод формул.
Надеюсь, вы нашли этот урок полезным.
А вы знали, что критерием поиска в ВПР или СУММЕСЛИ / СЧЁТЕСЛИ и т.д. может быть часть ячейки?
Покажу на примере.
Пример с функцией ВПР
Предположим, в желтую ячейку нужно вывести день рождения сотрудницы по имени Ирина. Критерий поиска — только имя.
Но ведь в таблице-источнике, в которой мы будем искать совпадение — нет столбца Имя. Только ФИО.
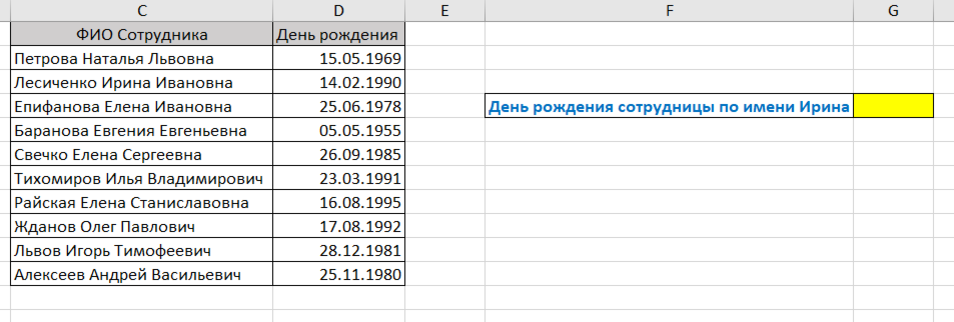
Если сразу хочется разделить столбец ФИО на Фамилию, имя и отчество и уже оттуда тянуть — не торопитесь.
Напишем в желтую ячейку формулу:
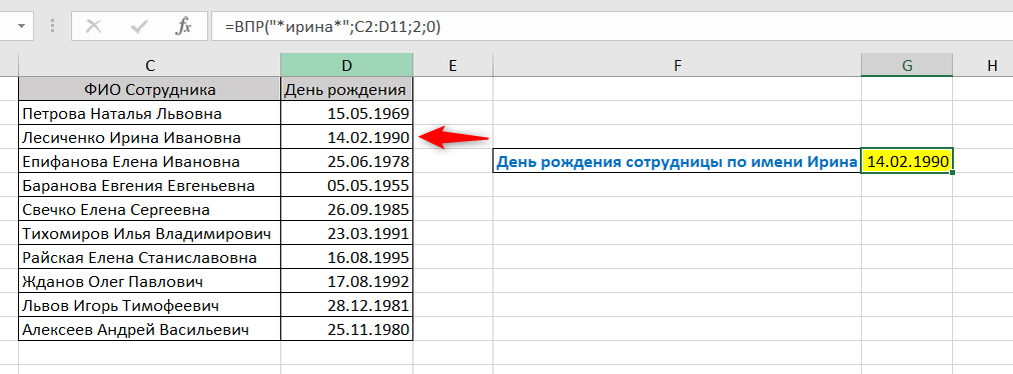
=ВПР(«*ирина*»;C2:D11;2;0)
где «*ирина*» — и есть тот самый критерий поиска по части ячейки.
Здесь используются два значка-оператора — кавычки и звездочка.
- звездочка * — заменяет любое количество символов. Т.е.перед и после слова ирина может находиться любое количество любых символов.
- кавычки «» — обязательно ставятся для текстового аргумента поиска в функциях excel.
Остальные аргументы стандартные для функции ВПР:
C2:D11 — таблица для поиска, здесь ее не закрепляем абсолютными ссылками, т.к. копировать формулу не будем.
2 — номер столбца в таблице, из которого будут возвращаться данные.
0 — аргумент интервальный просмотр.
Как видите, день рождения сотрудницы по имени Ирина (Лесиченко Ирина Ивановна) подтянулся правильно.
Пример с функцией СЧЁТЕСЛИ
На примере той же таблицы, найдем количество сотрудниц по имени Елена.
Напишем формулу:
=СЧЁТЕСЛИ(C2:C11;»*елена*»)
Где
C2:C11 — диапазон для поиска
«*елена*» — критерий поиска, образованный по тому же принципу, что и для предыдущего примера. Формула будет искать все ячейки, в которых содержится «елена» в любой части ячейки, и вернет их количество.
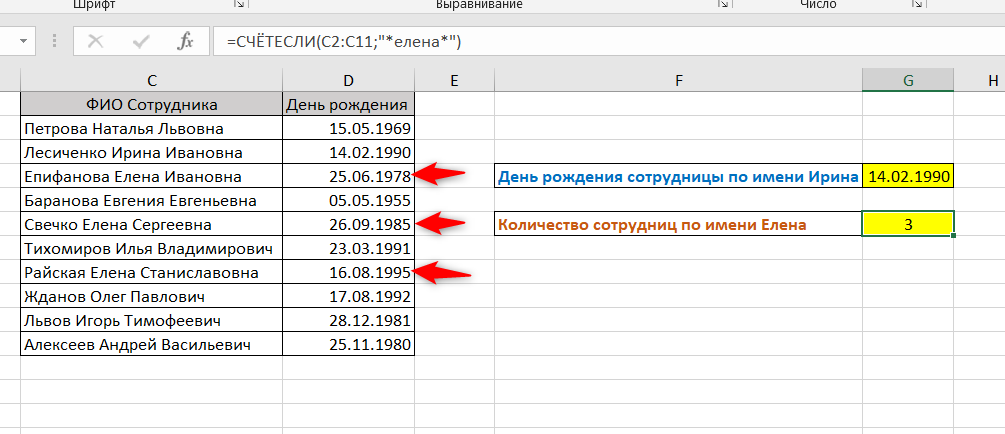
Формула посчитала значение 3 — и действительно, в списке три сотрудницы с таким именем.
Аналогично этот прием работает в функциях СУММЕСЛИ и СУММЕСЛИМН.
Ловушка этого способа
В эту ловушку я тоже попадала.
Будьте внимательны, если задаете в качестве критерия поиска слово, которое предположительно может быть частью другого слова.
Например, я считала количество сотрудников с именем Петр (буква ё не использовалась).
Критерием для функции СЧЁТЕСЛИ был «*петр*». И конечно, результатом расчета функции были не только все Петры, но и Петровы, Петровичи и Петровны, поскольку «Петр» является частью этих слов-отчеств.
В таком случае после слова-критерия (или перед ним) нужно поставить пробел. В данном случае, критерием поиска будет «*Петр *» (с пробелом перед второй звездочкой).
Вам может быть интересно:
Skip to content
Рассмотрим использование функции ЕСЛИ в Excel в том случае, если в ячейке находится текст.
- Проверяем условие для полного совпадения текста.
- ЕСЛИ + СОВПАД
- Использование функции ЕСЛИ с частичным совпадением текста.
- ЕСЛИ + ПОИСК
- ЕСЛИ + НАЙТИ
Будьте особо внимательны в том случае, если для вас важен регистр, в котором записаны ваши текстовые значения. Функция ЕСЛИ не проверяет регистр – это делают функции, которые вы в ней используете. Поясним на примере.
Проверяем условие для полного совпадения текста.
Проверку выполнения
доставки организуем при помощи обычного оператора сравнения «=».
=ЕСЛИ(G2=»выполнено»,ИСТИНА,ЛОЖЬ)
При этом будет не важно,
в каком регистре записаны значения в вашей таблице.

Если же вас интересует
именно точное совпадение текстовых значений с учетом регистра, то можно
рекомендовать вместо оператора «=» использовать функцию СОВПАД(). Она проверяет
идентичность двух текстовых значений с учетом регистра отдельных букв.
Вот как это может
выглядеть на примере.

Обратите внимание, что
если в качестве аргумента мы используем текст, то он обязательно должен быть
заключён в кавычки.
ЕСЛИ + СОВПАД
В случае, если нас интересует полное совпадение текста с заданным условием, включая и регистр его символов, то оператор «=» нам не сможет помочь.
Но мы можем использовать функцию СОВПАД (английский аналог — EXACT).
Функция СОВПАД сравнивает два текста и возвращает ИСТИНА в случае их полного совпадения, и ЛОЖЬ — если есть хотя бы одно отличие, включая регистр букв. Поясним возможность ее использования на примере.
Формула проверки выполнения заказа в столбце Н может выглядеть следующим образом:
=ЕСЛИ(СОВПАД(G2,»Выполнено»),»Да»,»Нет»)

Как видите, варианты «ВЫПОЛНЕНО» и «выполнено» не засчитываются как правильные. Засчитываются только полные совпадения. Будет полезно, если важно точное написание текста — например, в артикулах товаров.
Использование функции ЕСЛИ с частичным совпадением текста.
Выше мы с вами
рассмотрели, как использовать текстовые значения в функции ЕСЛИ. Но часто случается,
что необходимо определить не полное, а частичное совпадение текста с каким-то
эталоном. К примеру, нас интересует город, но при этом совершенно не важно его
название.
Первое, что приходит на
ум – использовать подстановочные знаки «?» и «*» (вопросительный знак и
звездочку). Однако, к сожалению, этот простой способ здесь не проходит.
ЕСЛИ + ПОИСК
Нам поможет функция ПОИСК (в английском варианте – SEARCH). Она позволяет определить позицию, начиная с которой искомые символы встречаются в тексте. Синтаксис ее таков:
=ПОИСК(что_ищем, где_ищем, начиная_с_какого_символа_ищем)
Если третий аргумент не
указан, то поиск начинаем с самого начала – с первого символа.
Функция ПОИСК возвращает либо номер позиции, начиная с которой искомые символы встречаются в тексте, либо ошибку.
Но нам для использования в функции ЕСЛИ нужны логические значения.
Здесь нам на помощь приходит еще одна функция EXCEL – ЕЧИСЛО. Если ее аргументом является число, она возвратит логическое значение ИСТИНА. Во всех остальных случаях, в том числе и в случае, если ее аргумент возвращает ошибку, ЕЧИСЛО возвратит ЛОЖЬ.
В итоге наше выражение в
ячейке G2
будет выглядеть следующим образом:
=ЕСЛИ(ЕЧИСЛО(ПОИСК(«город»,B2)),»Город»,»»)
Еще одно важное уточнение. Функция ПОИСК не различает регистр символов.

ЕСЛИ + НАЙТИ
В том случае, если для нас важны строчные и прописные буквы, то придется использовать вместо нее функцию НАЙТИ (в английском варианте – FIND).
Синтаксис ее совершенно аналогичен функции ПОИСК: что ищем, где ищем, начиная с какой позиции.
Изменим нашу формулу в
ячейке G2
=ЕСЛИ(ЕЧИСЛО(НАЙТИ(«город»,B2)),»Да»,»Нет»)

То есть, если регистр символов для вас важен, просто замените ПОИСК на НАЙТИ.
Итак, мы с вами убедились, что простая на первый взгляд функция ЕСЛИ дает нам на самом деле много возможностей для операций с текстом.
[the_ad_group id=»48″]
Примеры использования функции ЕСЛИ:
 Функция ЕСЛИОШИБКА – примеры формул — В статье описано, как использовать функцию ЕСЛИОШИБКА в Excel для обнаружения ошибок и замены их пустой ячейкой, другим значением или определённым сообщением. Покажем примеры, как использовать функцию ЕСЛИОШИБКА с функциями визуального…
Функция ЕСЛИОШИБКА – примеры формул — В статье описано, как использовать функцию ЕСЛИОШИБКА в Excel для обнаружения ошибок и замены их пустой ячейкой, другим значением или определённым сообщением. Покажем примеры, как использовать функцию ЕСЛИОШИБКА с функциями визуального…  Сравнение ячеек в Excel — Вы узнаете, как сравнивать значения в ячейках Excel на предмет точного совпадения или без учета регистра. Мы предложим вам несколько формул для сопоставления двух ячеек по их значениям, длине или количеству…
Сравнение ячеек в Excel — Вы узнаете, как сравнивать значения в ячейках Excel на предмет точного совпадения или без учета регистра. Мы предложим вам несколько формул для сопоставления двух ячеек по их значениям, длине или количеству… 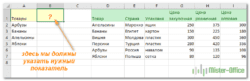 Вычисление номера столбца для извлечения данных в ВПР — Задача: Наиболее простым способом научиться указывать тот столбец, из которого функция ВПР будет извлекать данные. При этом мы не будем изменять саму формулу, поскольку это может привести в случайным ошибкам.…
Вычисление номера столбца для извлечения данных в ВПР — Задача: Наиболее простым способом научиться указывать тот столбец, из которого функция ВПР будет извлекать данные. При этом мы не будем изменять саму формулу, поскольку это может привести в случайным ошибкам.… 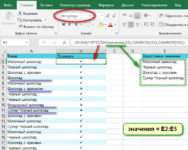 Как проверить правильность ввода данных в Excel? — Подтверждаем правильность ввода галочкой. Задача: При ручном вводе данных в ячейки таблицы проверять правильность ввода в соответствии с имеющимся списком допустимых значений. В случае правильного ввода в отдельном столбце ставить…
Как проверить правильность ввода данных в Excel? — Подтверждаем правильность ввода галочкой. Задача: При ручном вводе данных в ячейки таблицы проверять правильность ввода в соответствии с имеющимся списком допустимых значений. В случае правильного ввода в отдельном столбце ставить…  Визуализация данных при помощи функции ЕСЛИ — Функцию ЕСЛИ можно использовать для вставки в таблицу символов, которые наглядно показывают происходящие с данными изменения. К примеру, мы хотим показать в отдельной колонке таблицы, происходит рост или снижение продаж.…
Визуализация данных при помощи функции ЕСЛИ — Функцию ЕСЛИ можно использовать для вставки в таблицу символов, которые наглядно показывают происходящие с данными изменения. К примеру, мы хотим показать в отдельной колонке таблицы, происходит рост или снижение продаж.… 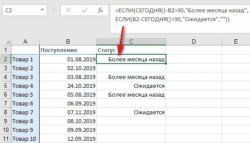 3 примера, как функция ЕСЛИ работает с датами. — На первый взгляд может показаться, что функцию ЕСЛИ для работы с датами можно применять так же, как для числовых и текстовых значений, которые мы только что обсудили. К сожалению, это…
3 примера, как функция ЕСЛИ работает с датами. — На первый взгляд может показаться, что функцию ЕСЛИ для работы с датами можно применять так же, как для числовых и текстовых значений, которые мы только что обсудили. К сожалению, это…
|
Поиск нескольких ФИО по фамилии. Возможен? |
||||||||
Ответить |
||||||||
| Ответить | ||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |




Преобразование имени и отчества в инициалы с помощью формул Excel и присоединение их к фамилии. Разделение фамилий, имен и отчеств, расположенных в одной ячейке, по разным ячейкам и наоборот.
Фамилия, имя и отчество в разных ячейках
Если фамилия, имя и отчество записываются в разные ячейки, работать с ними легче, чем при размещении их в одной ячейке. Перечислим преимущества:
- при заполнении таких ячеек в таблицах срабатывает автоподбор значений, так как имена и отчества часто повторяются;
- для заполнения таких ячеек можно использовать раскрывающиеся списки наиболее распространенных имен и отчеств;
- фамилия, имя и отчество, записанные в разные ячейки, легко объединить в одну, а имя и отчество заменить инициалами.
Итак, объединяем фамилию, имя и отчество полностью из разных ячеек в одну:

Здесь можно использовать формулу «СЦЕПИТЬ», как в примере =СЦЕПИТЬ(A1;" ";B1;" ";C1), или просто соединить строки с помощью & (амперсандов) =A1&" "&B1&" "&C1, не забыв добавить между словами пробелы.
В следующем примере мы также объединим фамилию, имя и отчество из разных ячеек в одну, при этом имя и отчество заменив на инициалы:

Здесь также можно использовать формулу «СЦЕПИТЬ», как в примере =СЦЕПИТЬ(A1;" ";ЛЕВСИМВ(B1;1);".";ЛЕВСИМВ(C1;1);".") или & (амперсанды) =A1&" "&ЛЕВСИМВ(B1;1)&"."&ЛЕВСИМВ(C1;1)&".", не забыв добавить между фамилией и инициалами пробел, а к инициалам точки. В этом примере мы извлекаем левые символы из имени и отчества для присоединения их к фамилии в виде инициалов.
Фамилия, имя и отчество в одной ячейке
Использование фамилии, имени и отчества в одной ячейке имеет тоже свои преимущества:
- уменьшается количество колонок в таблице;
- в большинство документов* требуется внесение фамилии, имени и отчества в полном написании.
*Если документы генерируются на основе этой таблицы, то вставка ФИО не потребует дополнительных преобразований.
Лично мне в работе не приходилось преобразовывать фамилию, имя и отчество из одной ячейки в разные, но могу предположить, что для кого-то это бывает необходимо:

Для этого преобразования используются следующие формулы в соответствующих ячейках:
- ячейка B1 —
=ЛЕВСИМВ(A1;НАЙТИ(" ";A1;1)-1) - ячейка C1 —
=ПСТР(A1;НАЙТИ(" ";A1;1)+1;НАЙТИ(" ";A1;НАЙТИ(" ";A1;1)+1)-НАЙТИ(" ";A1;1)-1) - ячейка D1 —
=ПРАВСИМВ(A1;ДЛСТР(A1)-НАЙТИ(" ";A1;НАЙТИ(" ";A1;1)+1))
Чтобы определить начало имени и начало отчества используются позиции первого и второго пробелов, найденных с помощью функции «НАЙТИ».
Необходимость следующего преобразования возникает чаще предыдущего, используется для заполнения различных документов наряду с полным именем:

Для этого преобразования используется следующая формула в ячейке B1 — =СЦЕПИТЬ(ЛЕВСИМВ(A1;НАЙТИ(" ";A1;1));" ";ПСТР(A1;НАЙТИ(" ";A1;1)+1;1);".";ПСТР(A1;НАЙТИ(" ";A1;НАЙТИ(" ";A1;1)+1)+1;1);".")
Здесь тоже функцию «СЦЕПИТЬ» можно заменить & (амперсандами) — =ЛЕВСИМВ(A1;НАЙТИ(" ";A1;1))&" "&ПСТР(A1;НАЙТИ(" ";A1;1)+1;1)&"."&ПСТР(A1;НАЙТИ(" ";A1;НАЙТИ(" ";A1;1)+1)+1;1)&"."
Вы можете копировать эти формулы в свои файлы, не забывая изменять адреса ячеек на фактические. Часто инициалы пишут перед фамилией, изменить формулы для такого отображения ФИО несложно.
Хитрости »
15 Май 2011 512231 просмотров
Как найти значение в другой таблице или сила ВПР
- Задача и её решение при помощи ВПР
- Описание аргументов ВПР
- Что важно всегда помнить при работе с ВПР
- Как избежать ошибки #Н/Д(#N/A) в ВПР?
- Как при помощи ВПР искать значение по строке, а не столбцу?
- Решение при помощи ПОИСКПОЗ
- Работа с критериями длиннее 255 символов
Если в двух словах, то ВПР позволяет сравнить данные двух таблиц на основании значений из одного столбца.
Чтобы чуть лучше понять принцип работы ВПР лучше начать с некоего практического примера. Возьмем две таблицы:

рис.1
На картинке выше для удобства они показаны рядом, но на самом деле могут быть расположены на разных листах и даже в разных книгах. Таблицы по сути одинаковые, но фамилии в них расположены в разном порядке, и к тому же в одной заполнены все столбцы, а во второй столбцы ФИО и Отдел. И из первой таблицы необходимо подставить во вторую дату для каждой фамилии. Для трех записей это не проблема и руками сделать — все очевидно. Но в жизни это таблицы на тысячи записей и поиск с подстановкой данных вручную может занять не один час. Вот где ВПР(VLOOKUP) будет весьма кстати. Все, что необходимо — записать в ячейку
C2
второй таблицы(туда, куда необходимо подставить даты из первой таблицы) такую формулу:
=ВПР($A2;Лист1!$A$1:$C$4;3;0)
=VLOOKUP($A2,Лист1!$A$1:$C$4,3,0)
Записать формулу можно либо непосредственно в ячейку, либо воспользовавшись диспетчером функций, выбрав в категории Ссылки и массивы(References & Arrays) функцию ВПР(VLOOKUP) и по отдельности указав нужные критерии. Теперь копируем(
Ctrl
+
C
) ячейку с формулой(С2), выделяем все ячейки столбца
С
до конца данных и вставляем(
Ctrl
+
V
).
Теперь разберем поподробнее саму функцию, её аргументы и некоторые особенности.
ВПР ищет заданное нами значение(аргумент искомое_значение) в первом столбце указанного диапазона(аргумент таблица). Поиск значения всегда происходит сверху вниз(собственно, поэтому функция и называется ВПР: Вертикальный ПРосмотр). Как только функция находит заданное значение — поиск прекращается, ВПР берет строку с найденным значением и смотрит на аргумент номер_столбца. Именно из этого столбца берётся значение, которое мы и видим как итог работы функции. Т.е. в нашем конкретном случае, для ячейки С2 второй таблицы, функция берет фамилию «Петров С.А.»(ячейка $A2 второй таблицы) и ищет её в первом столбце указанной таблицы(Лист1!$A$1:$C$4), т.е. в столбце А. Как только находит(это ячейка А3)
ВПР может вернуть только одно значений — первое, подходящее под критерий. Если искомое значение не найдено(отсутствует в таблице), то результатом функции будет ошибка #Н/Д(#N/A). Не надо этого бояться — это даже полезно. Вы точно будете знать, каких записей нет и таким образом можете сравнивать две таблицы друг с другом. Иногда получается так, что Вы видите: данные есть в обеих таблицах, но ВПР выдает #Н/Д. Значит данные в Ваших таблицах не идентичны. В какой-то из них есть лишние неприметные пробелы(обычно перед значением или после), либо знаки кириллицы перемешаны со знаками латиницы. Так же #Н/Д будет, если критерии числа и в искомой таблице они записаны как текст(как правило в левом верхнем углу такой ячейки появляется зеленый треугольничек), а в итоговой — как числа. Или наоборот.
Описание аргументов ВПР
- Искомое_значение($A2) — это то значение из одной таблицы, которые мы ищем в другой таблице. Т.е. для первой записи второй таблицы это будет Петров С.А.. Здесь можно указать либо непосредственно текст критерия(в этом случае он должен быть в кавычках — =ВПР(«Петров С.А»;Лист1!$A$1:$C$4;3;0), либо ссылку на ячейку, с данным текстом(как в примере функции). Есть небольшой нюанс: так же можно применять символы подстановки: «*» и «?». Это очень удобно, если необходимо найти значения лишь по части строки. Например, можно не вводить полностью «Петров С.А», а ввести лишь фамилию и знак звездочки — «Петров*». Тогда будет выведена любая запись, которая начинается на «Петров». Если же надо найти запись, в которой в любом месте строки встречается фамилия «Петров», то можно указать так: «*петров*». Если хотите найти фамилию Петров и неважно какие инициалы будут у имени-отчества(если ФИО записаны в виде Иванов И.И.), то здесь в самый раз такой вид: «Иванов ?.?.».
Часто необходимо для каждой строки указать свое значение(в столбце А Фамилии и надо их все найти). В таком случае всегда указываются ссылки на ячейки столбца А. Например, в ячейке A2 записано: Иванов. Так же известно, что Иванов есть в другой таблице, но после фамилии могут быть записаны и имя и отчество(или еще что-то). Но нам нужно найти только строку, которая начинается на фамилию. Тогда необходимо записать следующим образом: A2&»*». Эта запись будет равнозначна «Иванов*». В A2 записано Иванов, амперсанд(&) используется для объединения в одну строку двух текстовых значений. Звездочка в кавычках (как и положено быть тексту внутри формулы). Таким образом и получаем:
A2&»*» =>
«Иванов»&»*» =>
«Иванов*»
А полная формула в итоге будет выглядеть так: =ВПР(A2&»*»;Лист1!$A$1:$C$4;3;0)
Очень удобно, если значений для поиска много.
Если надо определить есть ли хоть где-то слово в строке, то звездочки ставим с обеих сторон: «*»&A1&»*» - Таблица(Лист1!$A$1:$C$4) — указывается диапазон ячеек, в первом столбце которых будет просматриваться аргумент Искомое_значение. Диапазон должен содержать данные от первой ячейки с данными до самой последней. Это не обязательно должен быть указанный в примере диапазон. Если строк 100, то Лист1!$A$2:$C$100. Диапазон в аргументе таблица всегда должен быть «закреплен», т.е. содержать знаки доллара($) перед названием столбцов и перед номерами строк(Лист1!$A$1:$C$4).
- Номер_столбца(3) — указывается номер столбца в аргументе Таблица, значения из которого нам необходимо записать в итоговую ячейку в качестве результата. В примере это Дата принятия — т.е. столбец №3. Если бы нужен был отдел, то необходимо было бы указать номер столбца 2, а если бы нам понадобилось просто сравнить есть ли фамилии одной таблицы в другой, то можно было бы указать и 1. Номер столбца всегда указывается числом и не должен быть больше числа столбцов в аргументе Таблица.
если аргумент Таблица имеет слишком большое кол-во столбцов и необходимо вернуть результат из последнего столбца, то совсем необязательно высчитывать их количество. Можно использовать формулу, которая подсчитывает количество столбцов в указанном диапазоне: =ВПР($A2;Лист1!$A$1:$C$4;ЧИСЛСТОЛБ(Лист1!$A$1:$C$4);0). К слову в данном случае Лист1! тоже можно убрать, т.к. функция ЧИСЛОСТОЛБ просто подсчитывает количество столбцов в переданном ей диапазоне и неважно на каком он листе: =ВПР($A2;Лист1!$A$1:$C$4;ЧИСЛСТОЛБ($A$1:$C$4);0).
- Интервальный_просмотр(0) — очень интересный аргумент. Может быть равен либо ИСТИНА либо ЛОЖЬ. Так же допускается указать 1 или 0. 1 = ИСТИНА, 0 = ЛОЖЬ. Если в ВПР указать данный параметр равный 0 или ЛОЖЬ, то будет происходить поиск точного соответствия заданному Искомому_значению. Это не имеет никакого отношения к знакам подстановки(«*» и «?»). Если же использовать 1 или ИСТИНА, то…Совсем в двух словах не объяснить. Если вкратце — ВПР будет искать наиболее похожее значение, подходящее под Искомомое_значение. Иногда очень полезно. Правда, если использовать данный параметр, то необходимо, чтобы список в аргументе Таблица был отсортирован по возрастанию. Обращаю внимание на то, что сортировка необходима только в том случае, если аргумент Интервальный_просмотр равен ИСТИНА или 1. Если же 0 или ЛОЖЬ — сортировка не нужна. Этот аргумент необходимо использовать осторожно — не стоит указывать 1 или ИСТИНА, если нужно найти точное соответствие и уж тем более не стоит использовать, если не понимаете принцип его работы.
Подробнее про работу ВПР с интервальным просмотром, равным 1 или ИСТИНА можно ознакомиться в статье ВПР и интервальный просмотр(range_lookup)
- Таблица всегда должна начинаться с того столбца, в котором ищем Искомое_значение. Т.е. ВПР не умеет искать значение во втором столбце таблицы, а значение возвращать из первого. В лучшем случае ничего найдено не будет и получим ошибку #Н/Д(#N/A), а в худшем результат будет совсем не тот, который должен быть
- аргумент Таблица должен быть «закреплен», т.е. содержать знаки доллара($) перед названием столбцов и перед номерами строк(Лист1!$A$1:$C$4). Это и есть закрепление(если точнее, то это называется абсолютной ссылкой на диапазон). Как это делается. Выделяете текст ссылки и жмете клавишу F4 до тех пор, пока не увидите, что и перед обозначением имени столбца и перед номером строки не появились доллары. Если этого не сделать, то при копировании формулы из одной ячейки в остальные аргумент Таблица будет «съезжать» и результат может быть совсем не таким, какой ожидался(в лучшем случае получите ошибку #Н/Д(#N/A)
- номер_столбца не должен превышать общее кол-во столбцов в аргументе таблица, а сама Таблица соответственно должна содержать столбцы от первого(в котором ищем) до последнего(из которого необходимо возвращать значения). В примере указана Лист1!$A$1:$C$4 — всего 3 столбца(A, B, C). Значит не получится вернуть значение из столбца D(4), т.к. в таблице только три столбца. Т.е. если мы запишем формулу так: =ВПР($A2;Лист1!$A$1:$C$4;4;0) — мы получим ошибку #ССЫЛКА!(#REF!).
Если аргументом Таблица указан диапазон $B$1:$C$4 и необходимо вернуть данные из столбца С, то правильно будет указать номер столбца 2. Т.к. аргумент Таблица($B$1:$C$4) содержит только два столбца — В и С. Если же попытаться указать номер столбца 3(каким по счету он является на листе), то получим ошибку #ССЫЛКА!(#REF!), т.к. третьего столбца в указанном диапазоне просто нет.
Многие наверняка заметили, что на картинке у меня попутаны отделы для ФИО(в обеих таблицах ФИО относятся к разным отделам). Это не ошибка записи. В прилагаемом к статье примере показано, как можно одной формулой подставить и отделы и даты, не меняя вручную аргумент Номер_столбца: =ВПР($A2;Лист1!$A$1:$C$4;СТОЛБЕЦ();0). Такой подход сработает, если в обеих таблицах одинаковый порядок столбцов.
Как избежать ошибки #Н/Д(#N/A) в ВПР?
Еще частая проблема — многие не хотят видеть #Н/Д результатом, если совпадение не найдено. Это можно обойти при помощи специальных функций.
Для пользователей Excel 2003 и старше:
=ЕСЛИ(ЕНД(ВПР($A2;Лист1!$A$1:$C$4;3;0));»»;ВПР($A2;Лист1!$A$1:$C$4;3;0))
=IF(ISNA(VLOOKUP($A2,Лист1!$A$1:$C$4,3,0)),»»,VLOOKUP($A2,Лист1!$A$1:$C$4,3,0))
Теперь если ВПР не найдет совпадения, то ячейка будет пустой.
А пользователям версий Excel 2007 и выше будет удобнее использовать функцию
ЕСЛИОШИБКА(IFERROR)
:
=ЕСЛИОШИБКА(ВПР($A2;Лист1!$A$1:$C$4;3;0);»»)
=IFERROR(VLOOKUP($A2,Лист1!$A$1:$C$4,3,0);»»)
Подробнее про различие между использованием ЕСЛИ(ЕНД и ЕСЛИОШИБКА я разбирал в статье: Как в ячейке с формулой вместо ошибки показать 0
Но я бы не рекомендовал использовать
ЕСЛИОШИБКА(IFERROR)
, не убедившись, что ошибки появляются только для реально отсутствующих значений. Иногда ВПР может вернуть #Н/Д и в других ситуациях:
- искомое значение состоит более чем из 255 символов(решение этой проблемы приведено ниже в этой статье: Работа с критериями длиннее 255 символов)
- искомое значение является числом с большим кол-вом знаков после запятой. Excel не может правильно воспринимать такие числа и в итоге ВПР может вернуть ошибку. Правильным решением здесь будет округлить искомое значение хотя бы до 4-х или 5-ти знаков после запятой(конечно, если это допустимо):
=ВПР(ОКРУГЛ($A2;5);Лист1!$A$1:$C$4;3;0)
=VLOOKUP(ROUND($A2,2),Лист1!$A$1:$C$4,3,0) - искомое значение содержит специальные или непечатаемые символы.
В этом случае придется либо избавиться от непечатаемых символов в искомом аргументе:
=ВПР(ПЕЧСИМВ($A2);Лист1!$A$1:$C$4;3;0)
=VLOOKUP(CLEAN($A2),Лист1!$A$1:$C$4,3,0)
либо добавить перед всеми специальными символами(такими как звездочка или вопр.знак) знак тильды(~), чтобы сделать эти знаки просто знаками, а не знаками специального значения(так же работа со специальными(служебными) символами описывалась в статье: Как заменить/удалить/найти звездочку). Добавить символ перед знаком той же тильды можно при помощи функции ПОДСТАВИТЬ(SUBSTITUTE):
=ВПР(ПОДСТАВИТЬ($A2;»~»;»~~»);Лист1!$A$1:$C$4;3;0)
=VLOOKUP(SUBSTITUTE(A2,»~»,»~~»),Лист1!$A$1:$C$4,3,0)
Если необходимо добавить тильду сразу перед несколькими знаками, то делает это обычно так(на примере подстановки одновременно для тильды и звездочки):
=ВПР(ПОДСТАВИТЬ(ПОДСТАВИТЬ($A2;»~»;»~~»);»*»;»~*»);Лист1!$A$1:$C$4;3;0)
=VLOOKUP(SUBSTITUTE(SUBSTITUTE(A2,»~»,»~~»),»*»,»~*»),Лист1!$A$1:$C$4,3,0)
На самом деле ответ будет коротким — ВПР всегда ищет сверху вниз. Слева направо она не умеет. Но зато слева направо умеет искать её сестра ГПР(HLookup) — Горизонтальный
ПР
осмотр.
ГПР ищет заданное значение(аргумент
искомое_значение
) в первой строке указанного диапазона(аргумент
таблица
) и возвращает для него значение из строки таблицы, указанной аргументом номер_строки. Поиск значения всегда происходит слева направо и заканчивается сразу, как только значение найдено. Если значение не найдено, функция возвращает значение ошибки
#Н/Д(#N/A)
.
Если надо найти значение «Иванов» в строке 2 и вернуть значение из строки 5 в таблице
A2:H10
, то формула будет выглядеть так:
=ГПР(«Иванов»;$A$2:$H$10;5;0)
=HLOOKUP(«Иванов»,$A$2:$H$10,5,0)
Все правила и синтаксис функции точно такие же, как у ВПР:
-в искомом значении можно применять символы астерикса(*) и вопр.знака(?) — «Иванов*»;
-таблица должна быть закреплена —
$A$2:$H$10
;
-интервальный просмотр работает по тому же принципу(0 или ЛОЖЬ точный просмотр слева-направо, 1 или ИСТИНА — интервальный).
Общий принцип работы
ПОИСКПОЗ(MATCH)
очень похож на ВПР — функция ищет заданное значение в массиве (в столбце или строке) и возвращает его позицию(порядковый номер в заданном массиве). Т.е. ищет
Искомое_значение
в аргументе
Просматриваемый_массив
и в качестве результата выдает номер позиции найденного значения в
Просматриваемом_массиве
. Именно номер позиции, а не само значение. Если бы мы хотели применить её для таблицы выше, то она была бы такой:
=ПОИСКПОЗ($A2;Лист1!$A$1:$A$4;0)
=MATCH($A2,Лист1!$A$1:$A$4,0)
- Искомое_значение($A2) — непосредственно значение или ссылка на ячейку с искомым значением. Если опираться на пример выше — то это ФИО. Здесь все ровно так же, как и с ВПР. Так же допустимы символы подстановки * и ? и ровно в таком же исполнении.
- Просматриваемый_массив(Лист1!$A$1:$A$4) — указывается ссылка на столбец, в котором необходимо найти искомое значение. В отличии от той же ВПР, где указывается целая таблица, это должен быть именно один столбец, в котором мы собираемся искать Искомое_значение. Если попытаться указать более одного столбца, то функция вернет ошибку.Справедливости ради надо отметить, что можно указать либо столбец, либо строку
- Тип_сопоставления(0) — то же самое, что и Интервальный_просмотр в ВПР. С теми же особенностями. Отличается разве что возможностью поиска наименьшего от искомого или наибольшего.
С основным разобрались. Но ведь нам надо вернуть не номер позиции, а само значение. Значит ПОИСКПОЗ в чистом виде нам не подходит. По крайней мере одна, сама по себе. Но если её использовать вместе с функцией ИНДЕКС(INDEX)(которая возвращает из указанного диапазона значение на пересечении заданных строки и столбца) — то это то, что нам нужно и даже больше.
=ИНДЕКС(Лист1!$A$1:$C$4;ПОИСКПОЗ($A2;Лист1!$A$1:$A$4;0);2)
Такая формула результатом вернет то же, что и ВПР.
Аргументы функции ИНДЕКС
Массив(Лист1!$A$2:$C$4). В качестве этого аргумента мы указываем диапазон, из которого хотим получить значения. Может быть как один столбец, так и несколько. В случае, если столбец один, то последний аргумент функции указывать не обязательно или он всегда будет равен 1(столбец-то всего один). К слову — данный аргумент может совершенно не совпадать с тем, который мы указываем в аргументе Просматриваемый_массив функции ПОИСКПОЗ.
Далее идут Номер_строки и Номер_столбца. Именно в качестве Номера_строки мы и подставляем ПОИСКПОЗ, которая возвращает нам номер позиции в массиве. На этом все и строится. ИНДЕКС возвращает значение из Массива, которое находится в указанной строке(Номер_строки) Массива и указанном столбце(Номер_столбца), если столбцов более одного. Важно знать, что в данной связке кол-во строк в аргументе Массив функции ИНДЕКС и кол-во строк в аргументе Просматриваемый_массив функции ПОИСКПОЗ должно совпадать. И начинаться с одной и той же строки. Это в обычных случаях, если не преследуются иные цели.
Так же как и в случае с ВПР, ИНДЕКС в случае не нахождения искомого значения возвращает #Н/Д. И обойти подобные ошибки можно так же:
Для всех версий Excel(включая 2003 и раньше):
=ЕСЛИ(ЕНД(ПОИСКПОЗ($A2;Лист1!$A$1:$A$4;0));»»;ИНДЕКС(Лист1!$A$1:$C$4;ПОИСКПОЗ($A2;Лист1!$A$2:$A$4;0);2))
Для версий 2007 и выше:
=ЕСЛИОШИБКА(ИНДЕКС(Лист1!$A$1:$C$4;ПОИСКПОЗ($A2;Лист1!$A$1:$A$4;0);2);»»)
Есть у ИНДЕКС-ПОИСКПОЗ и еще одно преимущество перед ВПР. Дело в том, что ВПР не может искать значения, длина строки которых содержит более 255 символов. Это случается редко, но случается. Можно, конечно, обмануть ВПР и урезать критерий:
=ВПР(ПСТР($A2;1;255);ПСТР(Лист1!$A$1:$C$4;1;255);3;0)
но это формула массива. Да и к тому же далеко не всегда такая формула вернет нужный результат. Если первые 255 символов идентичны первым 255 символам в таблице, а дальше знаки различаются — формула этого уже не увидит. Да и возвращает формула исключительно текстовые значения, что в случаях, когда возвращаться должны числа, не очень удобно.
Поэтому лучше использовать такую хитрую формулу:
=ИНДЕКС(Лист1!$A$1:$C$4;СУММПРОИЗВ(ПОИСКПОЗ(ИСТИНА;Лист1!$A$1:$A$4=$A2;0));2)
Здесь я в формулах использовал одинаковые диапазоны для удобочитаемости, но в примере для скачивания они различаются от указанных здесь.
Сама формула построена на возможности функции СУММПРОИЗВ преобразовывать в массивные вычисления некоторых функций внутри неё. В данном случае ПОИСКПОЗ ищет позицию строки, в которой критерий равен значению в строке. Подстановочные символы здесь применить уже не получится.
Ну и все же я рекомендовал бы Вам прочитать подробнее про данные функции в справке.
В прилагаемом к статье примере Вы найдете примеры использования всех описанных случаев и пример того, почему ИНДЕКС и ПОИСКПОЗ порой предпочтительнее ВПР.
Скачать пример
 Tips_All_VLookUp.xls (26,0 KiB, 17 437 скачиваний)
Tips_All_VLookUp.xls (26,0 KiB, 17 437 скачиваний)
Так же см.:
ВПР и интервальный просмотр(range_lookup)
ВПР по двум и более критериям
ВПР с возвратом всех значений
ВПР с поиском по нескольким листам
![]() ВПР_МН
ВПР_МН
![]() ВПР_ВСЕ_КНИГИ
ВПР_ВСЕ_КНИГИ
Как заменить/удалить/найти звездочку?
Статья помогла? Поделись ссылкой с друзьями!
![]() Видеоуроки
Видеоуроки
Поиск по меткам
Access
apple watch
Multex
Power Query и Power BI
VBA управление кодами
Бесплатные надстройки
Дата и время
Записки
ИП
Надстройки
Печать
Политика Конфиденциальности
Почта
Программы
Работа с приложениями
Разработка приложений
Росстат
Тренинги и вебинары
Финансовые
Форматирование
Функции Excel
акции MulTEx
ссылки
статистика