
Найдем номер строки последней заполненной ячейки в столбце и списке. По номеру строки найдем и само значение.
Рассмотрим диапазон значений, в который регулярно заносятся новые данные.
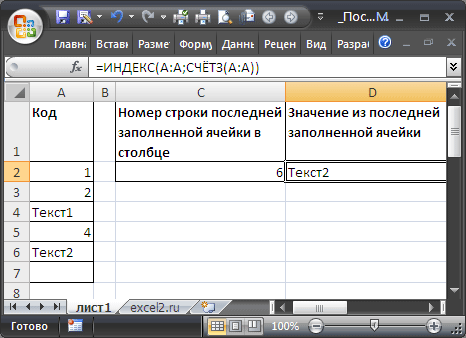
Диапазон без пропусков и начиная с первой строки
В случае, если в столбце значения вводятся, начиная с первой строки и без пропусков, то определить номер строки последней заполненной ячейки можно формулой:
=СЧЁТЗ(A:A))
Формула работает для числовых и текстовых диапазонов (см.
Файл примера
)
Значение из последней заполненной ячейки в столбце выведем с помощью функции
ИНДЕКС()
:
=ИНДЕКС(A:A;СЧЁТЗ(A:A))
Ссылки на целые столбцы и строки достаточно ресурсоемки и могут замедлить пересчет листа. Если есть уверенность, что при вводе значений пользователь не выйдет за границы определенного диапазона, то лучше указать ссылку на диапазон, а не на столбец. В этом случае формула будет выглядеть так:
=ИНДЕКС(A1:A20;СЧЁТЗ(A1:A20))
Диапазон без пропусков в любом месте листа
Если список, в который вводятся значения расположен в диапазоне
E8:E30
(т.е. не начинается с первой строки), то формулу для определения номера строки последней заполненной ячейки можно записать следующим образом:
=СЧЁТЗ(E9:E30)+СТРОКА(E8)
Формула
СТРОКА(E8)
возвращает номер строки заголовка списка. Значение из последней заполненной ячейки списка выведем с помощью функции
ИНДЕКС()
:
=ИНДЕКС(E9:E30;СЧЁТЗ(E9:E30))
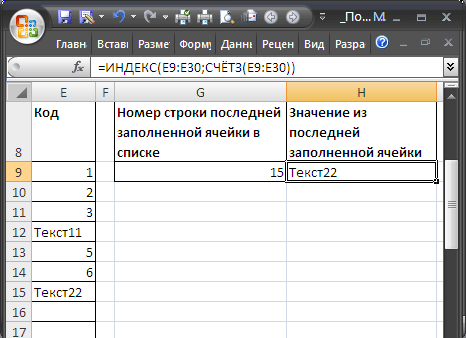
Диапазон с пропусками (числа)
В случае
наличия пропусков
(пустых строк) в столбце, функция
СЧЕТЗ()
будет возвращать неправильный (уменьшенный) номер строки: оно и понятно, ведь эта функция подсчитывает только значения и не учитывает
пустые
ячейки.
Если диапазон заполняется
числовыми
значениями, то для определения номера строки последней заполненной ячейки можно использовать формулу
=ПОИСКПОЗ(1E+306;A:A;1)
. Пустые ячейки и текстовые значения игнорируются.
Так как в качестве просматриваемого массива указан целый столбец (
A:A
), то функция
ПОИСКПОЗ()
вернет номер последней заполненной строки. Функция
ПОИСКПОЗ()
(с третьим параметром =1) находит позицию наибольшего значения, которое меньше или равно значению первого аргумента (1E+306). Правда, для этого требуется, чтобы массив был
отсортирован
по возрастанию. Если он не отсортирован, то эта функция возвращает позицию последней заполненной строки столбца, т.е. то, что нам нужно.
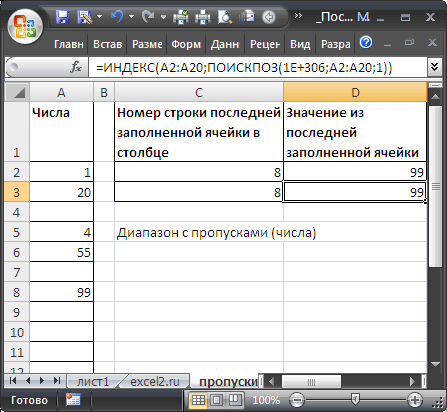
Чтобы вернуть значение в последней заполненной ячейке списка, расположенного в диапазоне
A2:A20
, можно использовать формулу:
=ИНДЕКС(A2:A20;ПОИСКПОЗ(1E+306;A2:A20;1))
Диапазон с пропусками (текст)
В случае необходимости определения номера строки последнего
текстового
значения (также при наличии пропусков), формулу нужно переделать:
=ПОИСКПОЗ(«*»;$A:$A;-1)
Пустые ячейки, числа и текстовое значение
Пустой текст
(«») игнорируются.
Диапазон с пропусками (текст и числа)
Если столбец содержит и
текстовые и числовые значения
, то для определения номера строки последней заполненной ячейки можно предложить универсальное решение:
=МАКС(ЕСЛИОШИБКА(ПОИСКПОЗ(«*»;$A:$A;-1);0); ЕСЛИОШИБКА(ПОИСКПОЗ(1E+306;$A:$A;1);0))
Функция
ЕСЛИОШИБКА()
нужна для подавления ошибки возникающей, если столбец
A
содержит только текстовые или только числовые значения.
Другим универсальным решением является
формула массива
:
=МАКС(СТРОКА(A1:A20)*(A1:A20<>»»))
Или
=МАКС(СТРОКА(A1:A20)*НЕ(ЕПУСТО(A1:A20)))
После ввода
формулы массива
нужно нажать
CTRL + SHIFT + ENTER
. Предполагается, что значения вводятся в диапазон
A1:A20
. Лучше задать фиксированный диапазон для поиска, т.к. использование в
формулах массива
ссылок на целые строки или столбцы является достаточно ресурсоемкой задачей.
Значение из последней заполненной ячейки, в этом случае, выведем с помощью функции
ДВССЫЛ()
:
=ДВССЫЛ(«A»&МАКС(СТРОКА(A1:A20)*(A1:A20<>»»)))
Или
=ДВССЫЛ(«A»&МАКС(СТРОКА(A1:A20)*НЕ(ЕПУСТО(A1:A20))))
Как обычно, после ввода
формулы массива
нужно нажать
CTRL + SHIFT + ENTER
вместо
ENTER
.
СОВЕТ:
Как видно, наличие пропусков в диапазоне существенно усложняет подсчет. Поэтому имеет смысл при заполнении и проектировании таблиц придерживаться правил приведенных в статье
Советы по построению таблиц
.
При составлении формул в Excel часто возникает необходимость найти последнюю строку или получить последнее значение в столбце таблицы с данными. Здесь следует учитывать несколько условий, поставленных перед поиском: будет ли список значений в столбце неразрывным или содержать пустые ячейки? Какие это значения: текст, числа? От этих факторов зависит тип используемых формул.
Как найти последнюю заполненную строку в столбце таблицы Excel
Ниже на рисунке представлен неотсортированный список фактур. Допустим нам необходимо найти последнюю строку с фактурой в списке номеров фактур. Простым способом поиска последней позиции в столбце является использование функции ИНДЕКС и подсчет всех позиций списка с целью определения номера последней строки.
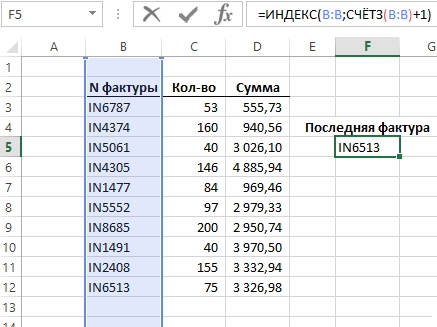
Функция ИНДЕКС использована с одним столбцом требует лишь указать один аргумент с номером строки. Третий необязательный для заполнения аргумент в данной ситуации не используется. Функция СЧЁТЗ используется с целью подсчитывания непустых ячеек в столбце B. Ее итоговый результат вычисления следует увеличить на число +1, так как в первой строке пустая ячейка. Функция ИНДЕКС в данном примере возвращает 12-ую строку в столбце B.
Функция СЧЁТЗ подсчитывает ячейки содержащие значения: числа, текстовые строки, даты и все любые другие значения за исключением пустых ячеек. Если ваши данные содержат пустые ячейки, которые разрывают целостность списков, тогда эта формула не будет возвращать правильных результатов вычисления.
Поиск последнего числа в столбце с пустыми ячейками Excel
Функции ИНДЕКС и СЧЁТЗ прекрасно используются для поиска значений в случае, когда диапазон исходных данных не содержит пустых ячеек и является неразрывным. Если же исходных диапазон ячеек содержит пустые ячейки, а искомыми значениями являются числа, можно воспользоваться функцией ПРОСМОТР с очень большим числовым значением в аргументах. Данная техника применяется с помощью составления следующей формулы:
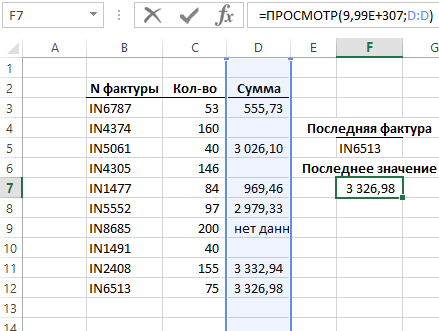
Искомое значение в данной формуле (единица с 308 знаками) – это самое большое число доступное в программе Excel. Так как функция ПРОСМОТР не имела шансов найти большего значения чем искомое, она прекратила свое вычисление на последнем найденном числовом значении, которую и вернула в результат.
Что значит число с буквой E в Excel?
Число такое как, например, 9,99E+307 записано в экспоненциальном формате. Число перед буквой E имеет одну цифру 0-9 и только две цифры после запятой. Число после буквы E значит количество разрядов, на которые следует сместить запятую (307 в данном примере), чтобы получить числовое значение, записанное традиционным способом. Плюс значит, что запятую следует смещать в право, а минус – влево. Например, запись 4,32E-02 означает число, записанное в десятичной дроби 0,0432.
Функция ПРОСМОТР имеет преимущество перед другими функциями в том, что она возвращает последнее число даже тогда, когда ячейки в просматриваемом диапазоне могут быть не только пустыми, но и содержать текстовые строки, коды ошибок или даты.
Поиск последнего вхождения (инвертированный ВПР)
Все классические функции поиска и подстановки типа ВПР (VLOOKUP), ГПР (HLOOKUP), ПОИСКПОЗ (MATCH) и им подобные имеют одну важную особенность — они ищут от начала к концу, т.е. слева-направо или сверху-вниз по исходным данным. Как только находится первое подходящее совпадение — поиск останавливается и найденным оказывается только первое вхождение нужного нам элемента.
Что же делать, если нам требуется найти не первое, а последнее вхождение? Например, последнюю сделку по клиенту, последний платёж, самую свежую заявку и т.д.?
Способ 1. Поиск последней строки формулой массива
Если в исходной таблице нет столбца с датой или порядковым номером строки (заказа, платежа…), то наша задача сводится, по сути, к поиску последней строки, удовлетворяющей заданному условию. Реализовать подобное можно вот такой формулой массива:

Здесь:
- Функция ЕСЛИ (IF) проверяет по очереди все ячейки в столбце Клиент и выводит номер строки, если в ней лежит нужное нам имя. Номер строки на листе нам даёт функция СТРОКА (ROW), но поскольку нам нужен номер строки в таблице, то дополнительно приходится вычитать 1, т.к. у нас в таблице есть шапка.
- Затем функция МАКС (MAX) выбирает из сформированного набора номеров строк максимальное значение, т.е. номер самой последней строки клиента.
- Функция ИНДЕКС (INDEX) выдаёт содержимое ячейки с найденным последним номером из любого другого требуемого столбца таблицы (Код заказа).
Всё это нужно вводить как формулу массива, т.е.:
- В Office 365 с последними установленными обновлениями и поддержкой динамических массивов — можно просто жать Enter.
- Во всех остальных версиях после ввода формулы придется нажимать сочетание клавиш Ctrl+Shift+Enter, что автоматически добавит к ней фигурные скобки в строке формул.
Способ 2. Обратный поиск новой функцией ПРОСМОТРХ
Я уже писал большую статью с видео про новую функцию ПРОСМОТРХ (XLOOKUP), которая появилась в последних версиях Office на замену старушке ВПР (VLOOKUP). При помощи ПРОСМОТРХ наша задача решается совершенно элементарно, т.к. для этой функции (в отличие от ВПР) можно явно задавать направление поиска: сверху-вниз или снизу-вверх — за это отвечает её последний аргумент (-1):

Способ 3. Поиск строки с последней датой
Если в исходных данных у нас есть столбец с порядковым номером или датой, играющей аналогичную роль, то задача видоизменяется — нам требуется найти уже не последнюю (самую нижнюю) строку с совпадением, а строку с самой поздней (максимальной) датой.
Как это сделать с помощью классических функций я уже подробно разбирал, а теперь давайте попробуем использовать мощь новых функций динамических массивов. Исходную таблицу для пущей красоты и удобства тоже заранее преобразуем в «умную» с помощью сочетания клавиш Ctrl+T или команды Главная — Форматировать как таблицу (Home — Format as Table).
С их помощью этой «убойной парочки» наша задача решается весьма изящно:

Здесь:
- Сначала функция ФИЛЬТР (FILTER) отбирает только те строки из нашей таблицы, где в столбце Клиент — нужное нам имя.
- Потом функция СОРТ (SORT) сортирует отобранные строки по убыванию даты, чтобы самая последняя сделка оказалась сверху.
- Функция ИНДЕКС (INDEX) извлекает первую строку, т.е. выдает нужную нам последнюю сделку.
- И, наконец, внешняя функция ФИЛЬТР убирает из результатов лишние 1-й и 3-й столбцы (Код заказа и Клиент) и оставляет только дату и сумму. Для этого используется массив констант {0;1;0;1}, определяющий какие именно столбцы мы хотим (1) или не хотим (0) выводить.
Способ 4. Поиск последнего совпадения в Power Query
Ну, и для полноты картины, давайте рассмотрим вариант решения нашей задачи обратного поиска с помощью надстройки Power Query. С её помощью всё решается очень быстро и красиво.
1. Преобразуем нашу исходную таблицу в «умную» с помощью сочетания клавиш Ctrl+T или команды Главная — Форматировать как таблицу (Home — Format as Table).
2. Загружаем её в Power Query кнопкой Из таблицы/диапазона на вкладке Данные (Data — From Table/Range).
3. Сортируем (через выпадающий список фильтра в шапке) нашу таблицу по убыванию даты, чтобы самые последние сделки оказались сверху.
4. На вкладке Преобразование выбираем команду Группировать по (Transform — Group By) и задаем группировку по клиентам, а в качестве агрегирующей функции выбираем вариант Все строки (All rows). Назвать новый столбец можно как угодно — например Подробности.

После группировки получим список уникальных имен наших клиентов и в столбце Подробности — таблицы со всеми сделками каждого из них, где первой строкой будет идти самая последняя сделка, которая нам и нужна:

5. Добавляем новый вычисляемый столбец кнопкой Настраиваемый столбец на вкладке Добавить столбец (Add column — Add custom column) и вводим следующую формулу:

Здесь Подробности — это столбец, откуда мы берем таблицы по клиентам, а {0} — это номер строки, которую мы хотим извлечь (нумерация строк в Power Query начинается с нуля). Получаем столбец с записями (Record), где каждая запись — первая строка из каждой таблицы:

Осталось развернуть содержимое всех записей кнопкой с двойными стрелками в шапке столбца Последняя сделка, выбрав нужные столбцы:

… и удалить потом ненужный более столбец Подробности щёлкнув по его заголовку правой кнопкой мыши — Удалить столбцы (Remove columns).
После выгрузки результатов на лист через Главная — Закрыть и загрузить — Закрыть и загрузить в (Home — Close & Load — Close & Load to…) получим вот такую симпатичную таблицу со списком последних сделок, как и хотели:

При изменении исходных данных результаты нужно не забыть обновить, щёлкнув по ним правой кнопкой мыши — команда Обновить (Refresh) или сочетанием клавиш Ctrl+Alt+F5.
Ссылки по теме
- Функция ПРОСМОТРХ — наследник ВПР
- Как использовать новые функции динамических массивов СОРТ, ФИЛЬТР и УНИК
- Поиск последней непустой ячейки в строке или столбце функцией ПРОСМОТР
Последняя заполненная ячейка в MS EXCEL
Найдем номер строки последней заполненной ячейки в столбце и списке. По номеру строки найдем и само значение.
Рассмотрим диапазон значений, в который регулярно заносятся новые данные.
Диапазон без пропусков и начиная с первой строки
В случае, если в столбце значения вводятся, начиная с первой строки и без пропусков, то определить номер строки последней заполненной ячейки можно формулой:
=СЧЁТЗ(A:A))
Формула работает для числовых и текстовых диапазонов (см. Файл примера )
Значение из последней заполненной ячейки в столбце выведем с помощью функции ИНДЕКС() :
=ИНДЕКС(A:A;СЧЁТЗ(A:A))
Ссылки на целые столбцы и строки достаточно ресурсоемки и могут замедлить пересчет листа. Если есть уверенность, что при вводе значений пользователь не выйдет за границы определенного диапазона, то лучше указать ссылку на диапазон, а не на столбец. В этом случае формула будет выглядеть так:
=ИНДЕКС(A1:A20;СЧЁТЗ(A1:A20))
Диапазон без пропусков в любом месте листа
Если список, в который вводятся значения расположен в диапазоне E8:E30 (т.е. не начинается с первой строки), то формулу для определения номера строки последней заполненной ячейки можно записать следующим образом:
=СЧЁТЗ(E9:E30)+СТРОКА(E8)
Формула СТРОКА(E8) возвращает номер строки заголовка списка. Значение из последней заполненной ячейки списка выведем с помощью функции ИНДЕКС() :
=ИНДЕКС(E9:E30;СЧЁТЗ(E9:E30))
Диапазон с пропусками (числа)
В случае наличия пропусков (пустых строк) в столбце, функция СЧЕТЗ() будет возвращать неправильный (уменьшенный) номер строки: оно и понятно, ведь эта функция подсчитывает только значения и не учитывает пустые ячейки.
Если диапазон заполняется числовыми значениями, то для определения номера строки последней заполненной ячейки можно использовать формулу =ПОИСКПОЗ(1E+306;A:A;1) . Пустые ячейки и текстовые значения игнорируются.
Так как в качестве просматриваемого массива указан целый столбец (A:A), то функция ПОИСКПОЗ() вернет номер последней заполненной строки. Функция ПОИСКПОЗ() (с третьим параметром =1) находит позицию наибольшего значения, которое меньше или равно значению первого аргумента (1E+306). Правда, для этого требуется, чтобы массив был отсортирован по возрастанию. Если он не отсортирован, то эта функция возвращает позицию последней заполненной строки столбца, т.е. то, что нам нужно.
Чтобы вернуть значение в последней заполненной ячейке списка, расположенного в диапазоне A2:A20, можно использовать формулу:
=ИНДЕКС(A2:A20;ПОИСКПОЗ(1E+306;A2:A20;1))
Диапазон с пропусками (текст)
В случае необходимости определения номера строки последнего текстового значения (также при наличии пропусков), формулу нужно переделать:
=ПОИСКПОЗ(«*»;$A:$A;-1)
Пустые ячейки, числа и текстовое значение Пустой текст («») игнорируются.
Диапазон с пропусками (текст и числа)
Если столбец содержит и текстовые и числовые значения, то для определения номера строки последней заполненной ячейки можно предложить универсальное решение:
=МАКС(ЕСЛИОШИБКА(ПОИСКПОЗ(«*»;$A:$A;-1);0);
ЕСЛИОШИБКА(ПОИСКПОЗ(1E+306;$A:$A;1);0))
Функция ЕСЛИОШИБКА() нужна для подавления ошибки возникающей, если столбец A содержит только текстовые или только числовые значения.
Другим универсальным решением является формула массива:
=МАКС(СТРОКА(A1:A20)*(A1:A20<>«»))
После ввода формулы массива нужно нажать CTRL + SHIFT + ENTER. Предполагается, что значения вводятся в диапазон A1:A20. Лучше задать фиксированный диапазон для поиска, т.к. использование в формулах массива ссылок на целые строки или столбцы является достаточно ресурсоемкой задачей.
Значение из последней заполненной ячейки, в этом случае, выведем с помощью функции ДВССЫЛ() :
=ДВССЫЛ(«A»&МАКС(СТРОКА(A1:A20)*(A1:A20<>«»)))
Как обычно, после ввода формулы массива нужно нажать CTRL + SHIFT + ENTER вместо ENTER.
СОВЕТ:
Как видно, наличие пропусков в диапазоне существенно усложняет подсчет. Поэтому имеет смысл при заполнении и проектировании таблиц придерживаться правил приведенных в статье Советы по построению таблиц.
Поиск последнего значения последней строки в столбце Excel
При составлении формул в Excel часто возникает необходимость найти последнюю строку или получить последнее значение в столбце таблицы с данными. Здесь следует учитывать несколько условий, поставленных перед поиском: будет ли список значений в столбце неразрывным или содержать пустые ячейки? Какие это значения: текст, числа? От этих факторов зависит тип используемых формул.
Как найти последнюю заполненную строку в столбце таблицы Excel
Ниже на рисунке представлен неотсортированный список фактур. Допустим нам необходимо найти последнюю строку с фактурой в списке номеров фактур. Простым способом поиска последней позиции в столбце является использование функции ИНДЕКС и подсчет всех позиций списка с целью определения номера последней строки.
Функция ИНДЕКС использована с одним столбцом требует лишь указать один аргумент с номером строки. Третий необязательный для заполнения аргумент в данной ситуации не используется. Функция СЧЁТЗ используется с целью подсчитывания непустых ячеек в столбце B. Ее итоговый результат вычисления следует увеличить на число +1, так как в первой строке пустая ячейка. Функция ИНДЕКС в данном примере возвращает 12-ую строку в столбце B.
Функция СЧЁТЗ подсчитывает ячейки содержащие значения: числа, текстовые строки, даты и все любые другие значения за исключением пустых ячеек. Если ваши данные содержат пустые ячейки, которые разрывают целостность списков, тогда эта формула не будет возвращать правильных результатов вычисления.
Поиск последнего числа в столбце с пустыми ячейками Excel
Функции ИНДЕКС и СЧЁТЗ прекрасно используются для поиска значений в случае, когда диапазон исходных данных не содержит пустых ячеек и является неразрывным. Если же исходных диапазон ячеек содержит пустые ячейки, а искомыми значениями являются числа, можно воспользоваться функцией ПРОСМОТР с очень большим числовым значением в аргументах. Данная техника применяется с помощью составления следующей формулы:
Искомое значение в данной формуле (единица с 308 знаками) – это самое большое число доступное в программе Excel. Так как функция ПРОСМОТР не имела шансов найти большего значения чем искомое, она прекратила свое вычисление на последнем найденном числовом значении, которую и вернула в результат.
Что значит число с буквой E в Excel?
Число такое как, например, 9,99E+307 записано в экспоненциальном формате. Число перед буквой E имеет одну цифру 0-9 и только две цифры после запятой. Число после буквы E значит количество разрядов, на которые следует сместить запятую (307 в данном примере), чтобы получить числовое значение, записанное традиционным способом. Плюс значит, что запятую следует смещать в право, а минус – влево. Например, запись 4,32E-02 означает число, записанное в десятичной дроби 0,0432.
Функция ПРОСМОТР имеет преимущество перед другими функциями в том, что она возвращает последнее число даже тогда, когда ячейки в просматриваемом диапазоне могут быть не только пустыми, но и содержать текстовые строки, коды ошибок или даты.
Поиск значений в списке данных
Примечание: Мы стараемся как можно оперативнее обеспечивать вас актуальными справочными материалами на вашем языке. Эта страница переведена автоматически, поэтому ее текст может содержать неточности и грамматические ошибки. Для нас важно, чтобы эта статья была вам полезна. Просим вас уделить пару секунд и сообщить, помогла ли она вам, с помощью кнопок внизу страницы. Для удобства также приводим ссылку на оригинал (на английском языке).
Предположим, вам нужно найти расширение телефона сотрудника с помощью его номера, а также правильно оценить коэффициент Комиссии для суммы продажи. Вы ищете данные, чтобы быстро и эффективно находить определенные данные в списке и автоматически проверять, правильно ли используются данные. После того как вы просмотрит данные, вы можете выполнить вычисления и отобразить результаты, указав возвращаемые значения. Есть несколько способов поиска значений в списке данных и отображения результатов.
В этой статье
Поиск значений в списке по вертикали по точному совпадению
Для выполнения этой задачи можно использовать функцию ВПР или сочетание функций индекс и ПОИСКПОЗ.
Примеры использования функции ВПР

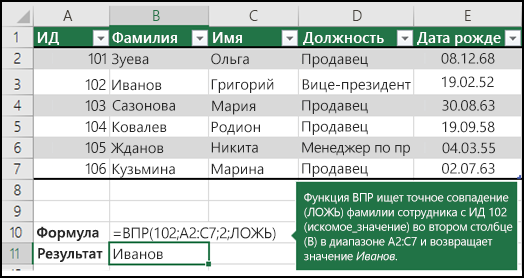
Дополнительные сведения можно найти в разделе функция ВПР.
Примеры ИНДЕКСов и СОВПАДЕНИй
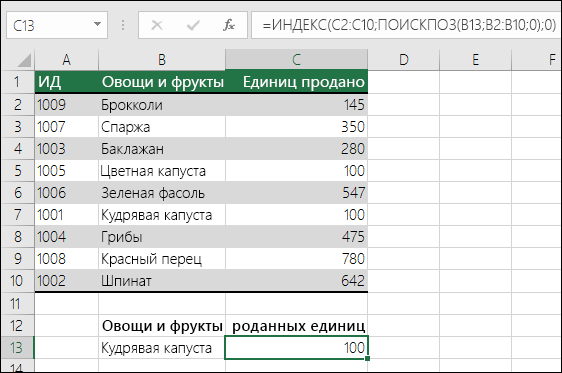
=ИНДЕКС(нужно вернуть значение из C2:C10, которое будет соответствовать ПОИСКПОЗ(первое значение «Капуста» в массиве B2:B10))
Формула ищет первое значение в ячейке C2: C10, соответствующее капусты (в B7), и возвращает значение в C7 (100) — первое значение, соответствующее капусты.
Дополнительные сведения можно найти в разделе Функция индекс и функция ПОИСКПОЗ.
Поиск значений в списке по вертикали по приблизительному совпадению
Для этого используйте функцию ВПР.
Важно: Убедитесь, что значения в первой строке отсортированы в возрастающем порядке.
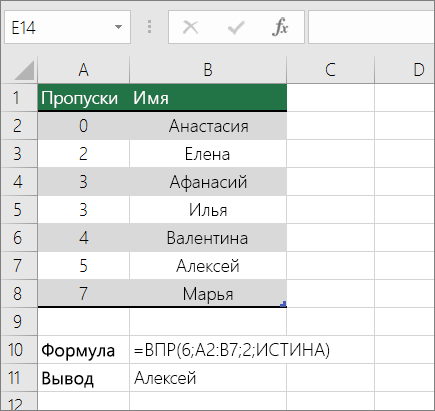
В приведенном выше примере функция ВПР ищет имя учащегося, у которого есть 6 тардиес в диапазоне A2: B7. В таблице нет записи для 6 тардиес, поэтому функция ВПР ищет следующее самое высокое соответствие ниже 6 и находит значение 5, связанное с первым именем Дэйв, и, следовательно, возвращает Дэйв.
Дополнительные сведения можно найти в разделе функция ВПР.
Поиск значений по вертикали в списке неизвестного размера с точным соответствием
Для выполнения этой задачи используйте функции СМЕЩ и ПОИСКПОЗ.
Примечание: Этот подход используется, если данные находятся в диапазоне внешних данных, который вы обновляете каждый день. Вы знаете, что в столбце B есть Цена, но вы не знаете, сколько строк данных возвращает сервер, а первый столбец не отсортирован по алфавиту.
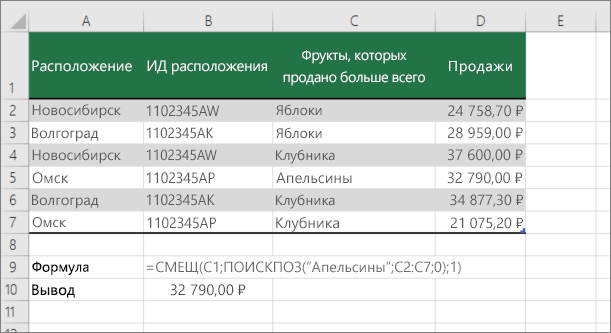
C1 — это верхняя левая ячейка диапазона (также называемая начальной ячейкой).
Match («апельсины»; C2: C7; 0) ищет оранжевый цвет в диапазоне C2: C7. Не следует включать начальную ячейку в диапазон.
1 — количество столбцов справа от начальной ячейки, для которых должно быть возвращено возвращаемое значение. В нашем примере возвращаемое значение находится в столбце D, Sales.
Поиск значений в списке по горизонтали по точному совпадению
Для выполнения этой задачи используется функция ГПР. Ниже приведен пример.
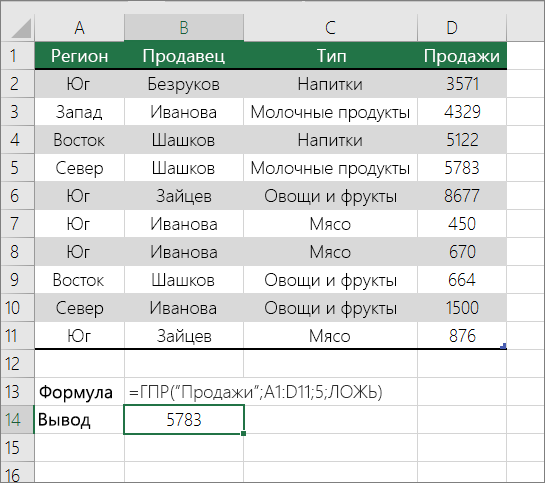
Функция ГПР выполняет поиск по столбцу Sales и возвращает значение из строки 5 в указанном диапазоне.
Дополнительные сведения можно найти в разделе функции ГПР.
Поиск значений в списке по горизонтали с использованием приблизительного совпадения
Для выполнения этой задачи используется функция ГПР.
Важно: Убедитесь, что значения в первой строке отсортированы в возрастающем порядке.
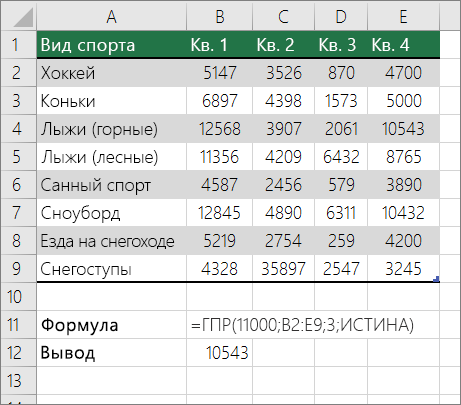
В приведенном выше примере функция ГПР ищет значение 11000 в строке 3 в указанном диапазоне. Он не находит 11000 и, следовательно, ищет следующее наибольшее значение, которое меньше 1100 и возвращает число 10543.
Дополнительные сведения можно найти в разделе функции ГПР.
Создание формулы подстановки с помощью мастера подстановок (толькоExcel 2007 )
Примечание: Надстройка «Мастер подстановок» прекращена в Excel 2010. Эти функциональные возможности заменены мастером функций и доступными функциями поиска и работы со ссылками (ссылками).
В Excel 2007 мастер подстановок создает формулу подстановки на основе данных листа, имеющих заголовки строк и столбцов. Мастер подстановок помогает находить другие значения в строке, когда вы знаете значение в одном столбце, и наоборот. Мастер подстановок использует индекс и СОВПАДЕНИе в создаваемых формулах.
Щелкните ячейку в диапазоне.
На вкладке формулы в группе решения нажмите кнопку Подстановка .
Если команда подстановка недоступна, необходимо загрузить мастер подстановок надстройка программу.
Загрузка программы-надстройки «Мастер подстановок»
Нажмите кнопку Microsoft Office  , щелкните Параметры Excelи выберите категорию надстройки.
, щелкните Параметры Excelи выберите категорию надстройки.
В поле Управление выберите элемент Надстройки Excel и нажмите кнопку Перейти.
В диалоговом окне надстройки установите флажок Мастер подстановоки нажмите кнопку ОК.
Excel поиск последнего значения в строке
Последнее непустое значение в строке

Для того, чтобы «вытащить» последнее непустое значение в строке, содержащей как пустые, так и непустые ячейки, можно воспользоваться функцией ПРОСМОТР с определенными «настройками» диапазонов.
Такая задача может возникнуть при поиске последней цены закупки в хронологическом порядке, последних данных транзакции и т.п.
-
В столбце с нашими будущими результатами вводим =ПРОСМОТР( и нажимаем fx.



Вводя конструкцию 1/(ДИАПАЗОН<>””) (диапазон, не равный пустым ячейкам), мы получим последовательность <1; #ДЕЛ/0…..>. Это даст нам возможность исключить из поиска пустые ячейки. Т.к. в просматриваемом векторе теперь заведомо будут отсутствовать любые искомые значения (кроме «1», ее вводить нельзя), то в искомое значение вводим любое число – например «1111».

=ПРОСМОТР(1111111111;1/(B3:F3<>«»);B3:F3), ее можно скопировать в строку формул и перенастроить под первую строку вашей таблицы, изменяя диапазон B3:F3 в векторах.
Если материал Вам понравился или даже пригодился, Вы можете поблагодарить автора, переведя определенную сумму по кнопке ниже:
(для перевода по карте нажмите на VISA и далее «перевести»)
Excel поиск последнего значения в строке
Если Вам необходимо в таблицах, которые имеют неодинаковое количество ячеек в строках и/или столбцах, например таких:
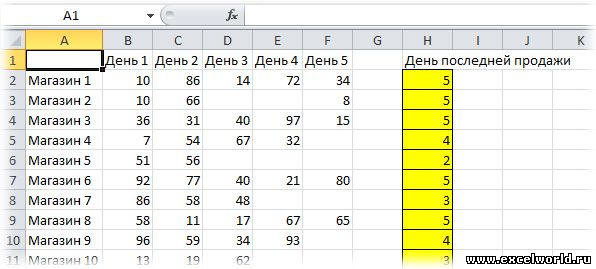
находить последние заполненные ячейки и извлекать из них значения, то в Excel Вы, к сожалению, не найдёте функции типа ВЕРНУТЬ.ПОСЛЕДНЮЮ.ЯЧЕЙКУ()
Вот как это сделать имеющейся в стандартном наборе функций функцией ПРОСМОТР().
1. Для текстовых значений:
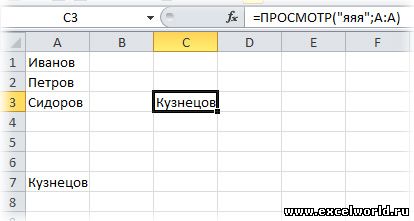
В английской версии:
Как это работает: Функция ПРОСМОТР() ищет сверху вниз в указанном столбце текст «яяя» и не найдя его, останавливается на последней ячейке в которой есть хоть какой-то текст. Так как мы не указали третий аргумент этой функции «Вектор_результатов», то функция возвращает значение из второго аргумента «Вектор_просмотра».
Пояснение: Почему именно «яяя«? Во-первых, потому что функция сравнивает при поиске текст посимвольно, а символ «я» в русском языке последний и все предыдущие при сравнении отбрасываются, во-вторых, потому что в русском языке нет такого слова.
Примечание: Вообще-то достаточно использовать и «яя«, но тогда возникает мизерная возможность попасть на таблицу, в которой будет такое слово. Так называются город и река в Кемеровской области. В детстве я был в этом городе и даже купался в этой реке 🙂
2. Для числовых значений:
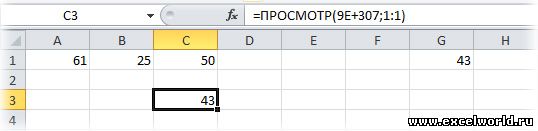
В английской версии:
Как это работает: Функция ПРОСМОТР() ищет слева направо в указанной строке число «9E+307» и не найдя его, останавливается на последней ячейке в которой есть хоть какое-то число. Так как мы не указали третий аргумент этой функции «Вектор_результатов», то функция возвращает значение из второго аргумента «Вектор_просмотра».
Пояснение: Почему именно «9E+307«? Потому что это максимально возможное число в Excel. Поэтому функция найти его может только в каком-то невероятном случае, в реальной жизни пользователь такими числами просто не оперирует.
3. Для смешанных (текстово-числовых) значений:
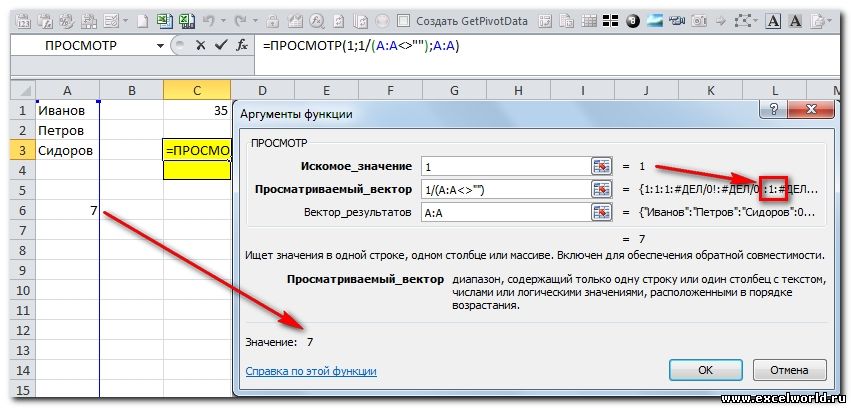
В английской версии:
Как это работает: Функция ПРОСМОТР() ищет слева направо в указанной строке число «1» и найдя его, останавливается на последней ячейке в которой есть это число. Так как мы указали третий аргумент этой функции «Вектор_результатов», то функция возвращает значение из него, соответствующее позиции последнего вхождения искомого в просматриваемый массив.
Пояснение: Почему именно «1«? Да просто так 🙂 С таким же успехом можно использовать число 2 или 3 или 100500, например. Главное что бы первый аргумент функции был не менее делимого в выражении 1/Диапазон. Вот пример применения другого числа в первом аргументе, при делимом отличном от единицы:
На чтение 7 мин. Просмотров 29.7k.
Содержание
- Получить первое не пустое значение в списке
- Получить первое текстовое значение в списке
- Получить первое текстовое значение с ГПР
- Получить позицию последнего совпадения
- Получить последнее совпадение содержимого ячейки
- Получить n-е совпадение
- Получить n-ое совпадение с ИНДЕКС/ПОИСКПОЗ
- Получить n-ое совпадение с ВПР
- Если ячейка содержит одну из многих вещей
- Поиск первой ошибки
- Поиск следующего наибольшего значения
- Несколько совпадений в списке, разделенных запятой
- Частичное совпадение чисел с шаблоном
- Частичное совпадение с ВПР
- Положение первого частичного совпадения
Получить первое не пустое значение в списке
{ = ИНДЕКС( диапазон ; ПОИСКПОЗ( ЛОЖЬ; ЕПУСТО ( диапазон ); 0 )) }

Если вам нужно получить первое не пустое значение (текст или число) в диапазоне в одной колонке вы можете использовать формулу массива на основе функций ИНДЕКС, ПОИСКПОЗ и ЕПУСТО.
В данном примере мы используем эту формулу:
{ = ИНДЕКС( B3: B11; ПОИСКПОЗ( ЛОЖЬ; ЕПУСТО ( B3: B11 ); 0 )) }
Таким образом, суть проблемы заключается в следующем: мы хотим получить первую не пустую ячейку, но для этого нет конкретной формулы в Excel. Мы могли бы использовать ВПР с шаблоном *, но это будет работать только для текста, а не для чисел.
Таким образом, нам нужно строить функциональные возможности для нужных нам формул. Способ сделать это состоит в использовании функции массива, которая «тестирует» ячейки и возвращает массив истина/ложь значения, которые мы можем сопрягать с ПОИСКПОЗ.
Работая изнутри, ЕПУСТО оценивает ячейки в диапазоне В3: В11 и возвращает результат и массив, который выглядит следующим образом:
{ИСТИНА; ЛОЖЬ; ИСТИНА; ЛОЖЬ; ЛОЖЬ; ИСТИНА; ИСТИНА; ИСТИНА; ИСТИНА}
Каждая ЛОЖЬ представляет собой ячейку в диапазоне, который не является пустой.
Далее, ПОИСКПОЗ ищет ЛОЖЬ внутри массива и возвращает позицию первого наденного совпадения, в этом случае 2. На данный момент, формула в примере теперь выглядит следующим образом:
{ = ИНДЕКС( B3: B11; 2; 0 )) }
И, наконец, функция ИНДЕКС выводит значение в положении 2 в массиве, в этом случае число 10.
Получить первое текстовое значение в списке
= ВПР ( «*»; диапазон; 1; ЛОЖЬ)
Если вам нужно получить первое текстовое значение в списке (диапазон один столбец), вы можете использовать функцию ВПР, чтобы установить точное соответствие, с шаблонным символом для поиска.

В данном примере формула в D7 является:
= ВПР ( «*» ; B5: B11 ; 1 ; ЛОЖЬ)
Групповой символ звездочка (*) соответствует любому текстовому значению.
Получить первое текстовое значение с ГПР
= ГПР ( «*»; диапазон; 1; ЛОЖЬ)

Для поиска и получения первого текстового значения во всем диапазоне столбцов, вы можете использовать функцию ГПР с групповым символом. В примере формула в F5 является:
= ГПР ( «*»; С5: Е5; 1; 0 )
Значение поиска является «*», групповым символом, который соответствует одному или более текстовому значению.
Получить позицию последнего совпадения
{ = МАКС( ЕСЛИ ( Величины = знач ; СТРОКА(величина) — СТРОКА(ИНДЕКС( Величины; 1 ; 1 )) + 1 )) }
Для того, чтобы получить позицию последнего совпадения (т.е. последнего вхождения) от значения поиска, вы можете использовать формулу, основанную на ЕСЛИ, СТРОКА, ИНДЕКС, ПОИСКПОЗ и MAКС функций.

В примере формула в G6:
=МАКС(ЕСЛИ(B4:B11=G5;СТРОКА(B4:B11)-СТРОКА(ИНДЕКС(B4:B11;1;1))+1))
Суть этой формулы состоит в том, что мы строим список номеров строк для данного диапазона, соответствующие по значению, а затем используем функцию MAКС, чтобы получить наибольшее количество строк, что соответствует последнему значению соответствия.
Получить последнее совпадение содержимого ячейки
= ПРОСМОТР( 2 ; 1 / ПОИСК ( вещи ; А1 ); вещи )
Чтобы проверить ячейку для одной из нескольких вещей, и вернуть последнее совпадение, найденное в списке, вы можете использовать формулу, основанную на ПРОСМОТР и ПОИСК функций. В случае нескольких найденных совпадений, формула вернет последнее совпадение из списка «вещей».

В примере формула в С5:
=ПРОСМОТР(2;1/ПОИСК($E$4:$E$7;B4);$E$4:$E$7)
Получить n-е совпадение
= НАИМЕНЬШИЙ( ЕСЛИ( логический тест; СТРОКА( список ) — МИН( СТРОКА( список )) + 1 ); n )
Для того, чтобы получить позицию n-го совпадения (например, второе значение соответствия заданному, третье значение соответствия и т.д.), вы можете использовать формулу, основанную на функции НАИМЕНЬШИЙ.
= НАИМЕНЬШИЙ( ЕСЛИ( список = E5 ; СТРОКА( список ) — МИН( СТРОКА( список )) + 1 ); F5 )
Эта формула возвращает позицию второго появления «красных» в списке.
Сутью этой формулы является функция НАИМЕНЬШИЙ, которая просто возвращает n-е наименьшее значение в списке значений, которое соответствует номеру строки. Номера строк были «отфильтрованы» функцией ЕСЛИ, которая применяет логику для совпадения.
Получить n-ое совпадение с ИНДЕКС/ПОИСКПОЗ
{ = ИНДЕКС( массив; НАИМЕНЬШИЙ( ЕСЛИ( величины = знач ; СТРОКА ( величины ) — СТРОКА ( ИНДЕКС( величины; 1 ; 1 )) + 1 ); n-й )) }

Чтобы получить n-ое совпадение, используя ИНДЕКС и ПОИСКПОЗ, вы можете использовать формулу массива с функциями ЕСЛИ и НАИМЕНЬШИЙ, чтобы выяснить номер строки совпадения.
Получить n-ое совпадение с ВПР
= ВПР( id_формулы; стол; 4; 0 )
Чтобы получить n-ое совпадение с ВПР, вам необходимо добавить вспомогательный столбец в таблицу , которая строит уникальный идентификатор , который включает счетчик.

Эта формула зависит от вспомогательного столбца, который добавляется в качестве первого столбца таблицы исходных данных. Вспомогательный столбец содержит формулу, которая строит уникальное значение взгляда вверх от существующего идентификатора и счетчика. Счетчик подсчитывает сколько раз уникальный идентификатор появился в таблице данных.
В примере, формула ячейки J6 вспомогательного столбца выглядит следующим образом:
=ВПР(J3&»-«&I6;B4:G11;4;0)
Если ячейка содержит одну из многих вещей
{ = ИНДЕКС( результаты ;ПОИСКПОЗ( ИСТИНА ; ЕЧИСЛО( ПОИСК( вещи ; A1 )); 0 )) }
Чтобы проверить ячейку для одной из нескольких вещей, и вернуть пользовательский результат для первого найденного совпадения, вы можете использовать формулу ИНДЕКС/ПОИСКПОЗ, основанную на функции поиска.
{ = ИНДЕКС( результаты ; ПОИСКПОЗ( ИСТИНА ; ЕЧИСЛО( ПОИСК ( вещи ; B5 )); 0 )) }
Эта формула использует два названных диапазона: E5: E8 называется «вещи» и F5: F8 называется «Результаты». Убедитесь, что вы используете диапазоны имен с одинаковыми именами (на основе ваших данных). Если вы не хотите использовать именованные диапазоны, используйте абсолютные ссылки вместо этого.
Поиск первой ошибки
{ = ПОИСКПОЗ( ИСТИНА ; ЕОШИБКА(диап ); 0 ) }
Если вам нужно найти первую ошибку в диапазоне ячеек, вы можете использовать формулу массива, основанную на ПОИСКПОЗ и ЕОШИБКА функциях.

В приведенном примере формула:
{ = ПОИСКПОЗ( ИСТИНА ; ЕОШИБКА( B4: B11 ); 0 ) }
Работая изнутри, функция ЕОШИБКА возвращает значение ИСТИНА, если значение является признанной ошибкой, и ЛОЖЬ, если нет.
Когда дается диапазон ячеек (массив ячеек) функция ЕОШИБКА будет возвращать массив истина/ложь значений. В примере, это результирующий массив выглядит следующим образом:
{ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ИСТИНА; ЛОЖЬ; ЛОЖЬ}
Обратите внимание, что 6-е значение (что соответствует 6-й ячейке в диапазоне) истинно, так как ячейка В9 содержит #Н/A.
Поиск следующего наибольшего значения
=ИНДЕКС ( данные; ПОИСКПОЗ( поиск ; значения ) + 1 )

Для того, чтобы найти «следующее наибольшее» значение в справочной таблице, можно использовать формулу, основанную на ИНДЕКС и ПОИСКПОЗ. В примере формула в F6 является:
=ИНДЕКС(C5:C9;ПОИСКПОЗ(F4;B5:B9)+1)
Несколько совпадений в списке, разделенных запятой
{ = ОБЪЕДИНИТЬ ( «;» ; ИСТИНА ; ЕСЛИ( диапазон1 = E5 ; диапазон2 ; «» )) }
Для поиска и извлечения нескольких совпадений, разделенных запятыми (в одной ячейке), вы можете использовать функцию ЕСЛИ с функцией ОБЪЕДИНИТЬ.
{ = ОБЪЕДИНИТЬ( «;» ; ИСТИНА ; ЕСЛИ( группа = E5 ; имя ; «» )) }
Эта формула использует «имя» — именованный диапазон (B5: B11) и «группа» — (C5: C11).
Частичное совпадение чисел с шаблоном
{ = ПОИСКПОЗ( «*» & номер & «*» ; ТЕКСТ( диапазон ; «0» ); 0 ) }
Для того, чтобы выполнить частичное совпадение (подстроки) против чисел, вы можете использовать формулу массива, основанную на ПОИСКПОЗ и ТЕКСТ.

Excel поддерживает символы подстановки «*» и «?». Тем не менее, если вы используете специальные символы с номером, вы будете преобразовывать числовое значение в текстовое значение. Другими словами, «*» & 99 & «*» = «* 99 *» (текстовая строка).
Если попытаться найти текстовое значение в диапазоне чисел, совпадение завершится неудачно.
Решение
Одно из решений заключается в преобразовании чисел в диапазоне поиска для текстовых значений, а затем сделать нормальный поиск с ПОИСКПОЗ, ВПР и т.д.
Другой вариант
Другой способ, чтобы преобразовать числа в текст, чтобы сцепить пустую строку. Эта формула работает так же, как выше формуле:
= ПОИСКПОЗ ( «*» & Е5 & «*» ; В5: В10 & «» ; 0 )
Частичное совпадение с ВПР
Если вы хотите получить информацию из таблицы на основе частичного совпадения, вы можете сделать это с помощью ВПР в режиме точного соответствия, и групповые символы.

В примере формула ВПР выглядит следующим образом:
=ВПР($H$2&»*»;$B$3:$E$12;2;0)
В этой формуле, значение представляет собой именованный диапазон, который относится к Н2, а также данные , представляет собой именованный диапазон , который относится к B3: E102. Без названных диапазонов, формула может быть записана следующим образом:
Положение первого частичного совпадения
= ПОИСКПОЗ ( «* текст *» ; диапазон; 0 )
Для того, чтобы получить позицию первого частичного совпадения (то есть ячейку, которая содержит текст, который вы ищете), вы можете использовать функцию ПОИСКПОЗ со специальными символами.

В примере формула в Е7:
=ПОИСКПОЗ(«*»&E6&»*»;B5:B10;0)
Функция ПОИСКПОЗ возвращает позицию или «индекс» в первом совпадении на основании значения поиска в диапазоне.
ПОИСКПОЗ поддерживает подстановочное согласование со звездочкой «*» (один или несколько символов) или знаком вопроса «?» (один символ), но только тогда, когда третий аргумент, тип_сопоставления, установлен в ЛОЖЬ или ноль.
Here’s a solution for finding the last row, last column, or last cell. It addresses the A1 R1C1 Reference Style dilemma for the column it finds. Wish I could give credit, but can’t find/remember where I got it from, so «Thanks!» to whoever it was that posted the original code somewhere out there.
Sub Macro1
Sheets("Sheet1").Select
MsgBox "The last row found is: " & Last(1, ActiveSheet.Cells)
MsgBox "The last column (R1C1) found is: " & Last(2, ActiveSheet.Cells)
MsgBox "The last cell found is: " & Last(3, ActiveSheet.Cells)
MsgBox "The last column (A1) found is: " & Last(4, ActiveSheet.Cells)
End Sub
Function Last(choice As Integer, rng As Range)
' 1 = last row
' 2 = last column (R1C1)
' 3 = last cell
' 4 = last column (A1)
Dim lrw As Long
Dim lcol As Integer
Select Case choice
Case 1:
On Error Resume Next
Last = rng.Find(What:="*", _
After:=rng.Cells(1), _
LookAt:=xlPart, _
LookIn:=xlFormulas, _
SearchOrder:=xlByRows, _
SearchDirection:=xlPrevious, _
MatchCase:=False).Row
On Error GoTo 0
Case 2:
On Error Resume Next
Last = rng.Find(What:="*", _
After:=rng.Cells(1), _
LookAt:=xlPart, _
LookIn:=xlFormulas, _
SearchOrder:=xlByColumns, _
SearchDirection:=xlPrevious, _
MatchCase:=False).Column
On Error GoTo 0
Case 3:
On Error Resume Next
lrw = rng.Find(What:="*", _
After:=rng.Cells(1), _
LookAt:=xlPart, _
LookIn:=xlFormulas, _
SearchOrder:=xlByRows, _
SearchDirection:=xlPrevious, _
MatchCase:=False).Row
lcol = rng.Find(What:="*", _
After:=rng.Cells(1), _
LookAt:=xlPart, _
LookIn:=xlFormulas, _
SearchOrder:=xlByColumns, _
SearchDirection:=xlPrevious, _
MatchCase:=False).Column
Last = Cells(lrw, lcol).Address(False, False)
If Err.Number > 0 Then
Last = rng.Cells(1).Address(False, False)
Err.Clear
End If
On Error GoTo 0
Case 4:
On Error Resume Next
Last = rng.Find(What:="*", _
After:=rng.Cells(1), _
LookAt:=xlPart, _
LookIn:=xlFormulas, _
SearchOrder:=xlByColumns, _
SearchDirection:=xlPrevious, _
MatchCase:=False).Column
On Error GoTo 0
Last = R1C1converter("R1C" & Last, 1)
For i = 1 To Len(Last)
s = Mid(Last, i, 1)
If Not s Like "#" Then s1 = s1 & s
Next i
Last = s1
End Select
End Function
Function R1C1converter(Address As String, Optional R1C1_output As Integer, Optional RefCell As Range) As String
'Converts input address to either A1 or R1C1 style reference relative to RefCell
'If R1C1_output is xlR1C1, then result is R1C1 style reference.
'If R1C1_output is xlA1 (or missing), then return A1 style reference.
'If RefCell is missing, then the address is relative to the active cell
'If there is an error in conversion, the function returns the input Address string
Dim x As Variant
If RefCell Is Nothing Then Set RefCell = ActiveCell
If R1C1_output = xlR1C1 Then
x = Application.ConvertFormula(Address, xlA1, xlR1C1, , RefCell) 'Convert A1 to R1C1
Else
x = Application.ConvertFormula(Address, xlR1C1, xlA1, , RefCell) 'Convert R1C1 to A1
End If
If IsError(x) Then
R1C1converter = Address
Else
'If input address is A1 reference and A1 is requested output, then Application.ConvertFormula
'surrounds the address in single quotes.
If Right(x, 1) = "'" Then
R1C1converter = Mid(x, 2, Len(x) - 2)
Else
x = Application.Substitute(x, "$", "")
R1C1converter = x
End If
End If
End Function
Хитрости »
1 Май 2011 43427 просмотров
Как получить последннюю заполненную ячейку формулой?
Очень часто при работе с большими таблицами возникает вопрос: как узнать последнюю заполненную ячейку в столбце? Обычно это необходимо для того, чтобы суммировать или вычислять среднее только в пределах заданной таблицы, без учета пустых строк, т.к. в случае с вычислением среднего пустые строки могут повлиять на расчеты. Так же определить последнюю ячейку формулой бывает необходимо, если в отдельную ячейку в начале таблицы надо выводить последнее записанное в таблицу значение.
По сути способов узнать последнюю заполненную ячейку формулами не так много. Я в этой статье покажу два варианта: в первом формула проще для понимания, но менее универсальна в использовании — она требует точно знать данные какого типа хранятся в столбце: числа или текст, т.к. ориентируется исключительно на тип данных. Вторая формула более универсальна, но может дольше работать.
Формула ниже по сути будет отбирать только числа и вернет номер самой нижней строки, в которой расположено любое число, даже если это нуль:
=ПОИСКПОЗ(3E+307;A1:A100)
=MATCH(3E+307,A1:A100)
А эта формула вернет номер строки с последней ячейкой, в которой записан любой текст
=ПОИСКПОЗ(«яяя»;A1:A100)
=MATCH(«яяя»,A1:A100)
Принцип работы этих формул основан на последнем аргументе функции ПОИСКПОЗ(MATCH) — интервальный просмотр(подробнее про этот аргумент можно узнать из этой статьи — ВПР и интервальный просмотр(range_lookup)). Если его не указывать, то принимается значения по умолчанию для этого аргумента. По умолчанию он равен 1, что означает искать наибольшее значение, которое меньше или равно искомому. Для «правильной» работы с этим параметром справка Excel рекомендует отсортировать по возрастанию массив значений, в которых осуществляется поиск искомого значения. Но в нашем случае сортировка как раз не нужна. Происходит следующее: в случае с числом мы задает максимально возможное число(3E+307), которого заведомо в искомых значениях быть не может. ПОИСКПОЗ сверяет каждое значение с этим числом. Определяет, что значение в массиве меньше искомого(но не равно ему!) и запоминает его позицию. Но т.к. ПОИСКПОЗ стремится найти самый подходящий вариант — то просматривает значения дальше, предполагая, что массив отсортирован по возрастанию и дальше пойдут значения ЕЩЕ БОЛЬШЕ предыдущего и там возможно есть значение, равное искомому. Но наш массив не отсортирован и значения там расположены абы как. Да и значения там все меньше указанного. В результате ПОИСКПОЗ доходит до последнего числа в указанном массиве и возвращает именно его позицию, т.к. дальше искать нечего и ПОИСКПОЗ считает, что это максимально подходящее число. Опять же потому, что считает, что значения у нас отсортированы.
Тоже самое и с текстом, только тут мы задаем текст «яяя», который в бинарной сетке будет в самом низу, т.к. буква «я» имеет самый большой числовой код. А три этих буквы подряд дают по сути «самый большой текст».
Но чаще всего как раз заранее неизвестно, какие именно данные будут в ячейках: текстовые или числовые. Т.е. по факту в столбце могут быть абсолютно любые данные. В таких случаях можно применить один из следующих вариантов формулы:
- =МАКС(ПОИСКПОЗ({«яяя»;3E+307};A1:A100))
=MAX(MATCH({«яяя»,3E+307},A1:A100)) - =ПРОСМОТР(2;1/(A1:A100<>»»);СТРОКА(A1:A100))
=LOOKUP(2,1/(A1:A100<>»»),ROW(A1:A100))
Первая формула вводится как формула массива(ввод формулы в ячейку завершается нажатием не просто Enter, а сочетанием клавиш Ctrl+Shift+Enter). Но есть и еще один недостаток: если в столбце нет какого-либо типа данных — формула вернет #Н/Д. Обхитрить можно, если захватить в расчет заголовок, в котором будет текст или число, в зависимости от того, какие данные предположительно могут отсутствовать. Или сделать двойной заголовок — в одном число, в другом текст. Основной принцип работы ПОИСКПОЗ в данном случае описан выше. Могу лишь добавить, что ввод её как формулу массива заставляет формулу искать как позицию самого дальнего числа, так и позицию самого дальнего текста. А функция МАКС(MAX) отбирает из найденных двух позиций максимальное значение.
Вторая формула вводится в ячейку обычным методом и вроде как не имеет никаких подводных камней. Кроме одного: не стоит указывать в качестве диапазона ВЕСЬ СТОЛБЕЦ с данными — формула может очень долго пересчитываться. Особенно это сказывается в файлах версии 2007 Excel, где строк больше миллиона. Предыдущие формулы лишены этого недостатка. Хотя я в любом случае советовал бы указывать явно диапазон «с запасом».
Принцип её работы похож на ПОИСКПОЗ с небольшими дополнениями:
- A1:A100<>»» — здесь идет сравнение каждого значения в указанном диапазоне и если ячейка не пустая — возвращается ИСТИНА(TRUE).
- 1/(A1:A100<>»») — здесь единица делится на полученные значения ИСТИНА(TRUE). Звучит как бред, но. Для Excel ИСТИНА это 1, а ЛОЖЬ — 0. Таким образом мы получаем массив значений 1 и #ДЕЛ/0(#DIV/0). Т.е. максимальное число в массиве у нас — 1. А принцип работы функции ПРОСМОТР(LOOKUP) очень похож на ПОИСКПОЗ, только она всегда стремиться найти наибольшее подходящее значение, меньшее или равное искомому. А в качестве искомого мы задаем 2, т.е. оно заведомо больше любого значения в массиве для поиска: =ПРОСМОТР(2;1/(A1:A100<>»»)
Таким образом ПРОСМОТР всегда будет нам возвращать позицию последней заполненной ячейки. Последний аргумент функции ПРОСМОТР — массив, равный по размеру просматриваемому(A1:A100), из которого будет возвращено значение. Мы задаем в качестве этого массива значений для возврата массив номеров строк: СТРОКА(A1:A100). Т.е. если в массиве A1:A100 последнее значение будет в ячейке A9, то ПРОСМОТР вернет значение для СТРОКА(A9).
Как видно, недостатки есть в любой из приведенных формул, так что выбор в любом случае за Вами и зависеть он будет напрямую от поставленной задачи.
Вот один из примеров, как можно применить определение последней ячейки в реальных формулах. Например, вычисление среднего значения:
=СРЗНАЧ(A2:ИНДЕКС(A1:A100;ПОИСКПОЗ(9E+307;A1:A100)))
Числовые данные начинаются с ячейки
A2
. В A1 заголовок, а где заканчиваются данные неизвестно — они постоянно изменяются: удаляются, дополняются.
В данном случае мы первой ячейкой указываем
A2
— начало числовых данных. А вот далее уже идет вычисление последней ячейки:
ПОИСКПОЗ(9E+307;A1:A100)
В данном случае можно применить поиск последней ячейки именно с числом, т.к. СРЗНАЧ(AVERAGE) в любом случае игнорирует текст и лишние ячейки нам ни к чему. ПОИСКПОЗ(MATCH) возвращает номер последней ячейки в диапазоне
A1:A100
. Но чтобы получить именно ссылку на эту ячейку, а не просто её строку мы используем ИНДЕКС(INDEX):
ИНДЕКС(A1:A100;ПОИСКПОЗ(9E+307;A1:A100))
Т.е. по шагам формулу можно представить так:
=СРЗНАЧ(A2:ИНДЕКС(A1:A100;ПОИСКПОЗ(9E+307;A1:A100))) =>
=СРЗНАЧ(A2:ИНДЕКС(A1:A100;9)) =>
=СРЗНАЧ(A2:A9) =>
4,5
В приложенном к теме примере записаны все приведенные формулы, а так же пара примеров того, как эти формулы можно использовать в других формулах для определения конца диапазона.
Скачать пример
 Tips_General_Last_Cell_Formula.xls (38,5 KiB, 3 350 скачиваний)
Tips_General_Last_Cell_Formula.xls (38,5 KiB, 3 350 скачиваний)
Также см.:
Как определить последнюю ячейку на листе через VBA?
Что такое формула массива
Статья помогла? Поделись ссылкой с друзьями!
![]() Видеоуроки
Видеоуроки
Поиск по меткам
Access
apple watch
Multex
Power Query и Power BI
VBA управление кодами
Бесплатные надстройки
Дата и время
Записки
ИП
Надстройки
Печать
Политика Конфиденциальности
Почта
Программы
Работа с приложениями
Разработка приложений
Росстат
Тренинги и вебинары
Финансовые
Форматирование
Функции Excel
акции MulTEx
ссылки
статистика
Поиск номера последней заполненной строки с помощью кода VBA Excel для таблиц, расположенных как в верхнем левом углу, так и в любом месте рабочего листа.
Номер последней заполненной строки в таблице Excel обычно используется в коде VBA для определения следующей за ней первой пустой строки для добавления новой записи. А также для задания интервала для поиска и обработки информации с помощью цикла For… Next (указание границ обрабатываемого диапазона).
Переменную, которой присваивается номер последней строки, следует объявлять как Long или Variant, например: Dim PosStr As Long. В современных версиях Excel количество строк на рабочем листе превышает максимальное значение типа данных Integer.
Таблица в верхнем левом углу
В первую очередь рассмотрим все доступные варианты поиска номера последней заполненной строки для таблиц, расположенных в верхнем левом углу рабочего листа. Такие таблицы обычно представляют собой простые базы данных в Excel, или, как их еще называют, наборы записей.

Пример таблицы с набором данных в Excel
Вариант 1
Основная формула для поиска последней строки в такой таблице, не требующая соблюдения каких-либо условий:
PosStr = Cells(1, 1).CurrentRegion.Rows.Count
Вариант 2
Ниже таблицы не должно быть никаких записей, в том числе ранее удаленных:
PosStr = ActiveSheet.UsedRange.Rows.Count
Вариант 3
В первом столбце таблицы не должно быть пропусков, а также в таблице должно быть не менее двух заполненных строк, включая строку заголовков:
PosStr = Cells(1, 1).End(xlDown).Row
Вариант 4
В первой колонке рабочего листа внутри таблицы не должно быть пропусков, а ниже таблицы в первой колонке не должно быть других заполненных ячеек:
PosStr = WorksheetFunction.CountA(Range("A:A"))
Вариант 5
Ниже таблицы не должно быть никаких записей:
PosStr = Cells.SpecialCells(xlLastCell).Row
Последняя строка любой таблицы
Последнюю заполненную строку для любой таблицы будем искать, отталкиваясь от ее верхней левой ячейки: Cells(a, b).
Вариант 1
Основная формула для поиска последней строки в любой таблице, не требующая соблюдения каких-либо условий:
PosStr = Cells(a, b).CurrentRegion.Cells(Cells(a, b).CurrentRegion.Cells.Count).Row
Вариант 2
Дополнительная формула с условием, что в первом столбце таблицы нет пустых ячеек:
PosStr = Cells(a, b).End(xlDown).Row
Если у вас на рабочем листе Excel есть записи вне таблиц, следите за тем, чтобы таблицы были окружены пустыми ячейками или пустыми ячейками и границами листа. Тогда не будет случайно внесенных заметок, примыкающих к таблицам, которые могут отрицательно повлиять на точность вычисления номера последней строки из кода VBA.
Ссылка на это место страницы:
#title
- Получить первое не пустое значение в списке
- Получить первое текстовое значение в списке
- Получить первое текстовое значение с ГПР
- Получить позицию последнего совпадения
- Получить последнее совпадение содержимого ячейки
- Получить n-е совпадение
- Получить n-ое совпадение с ИНДЕКС/ПОИСКПОЗ
- Получить n-ое совпадение с ВПР
- Если ячейка содержит одну из многих вещей
- Поиск первой ошибки
- Поиск следующего наибольшего значения
- Несколько совпадений в списке, разделенных запятой
- Частичное совпадение чисел с шаблоном
- Частичное совпадение с ВПР
- Положение первого частичного совпадения
- Скачать файл
Ссылка на это место страницы:
#punk01
{ = ИНДЕКС( диапазон ; ПОИСКПОЗ( ЛОЖЬ; ЕПУСТО ( диапазон ); 0 )) }
{ = INDEX( диапазон ; MATCH( FALSE; ISBLANK ( диапазон ); 0 )) }

Если вам нужно получить первое не пустое значение (текст или число) в диапазоне в одной колонке вы можете использовать формулу массива на основе функций ИНДЕКС, ПОИСКПОЗ и ЕПУСТО.
В данном примере мы используем эту формулу:
{ = ИНДЕКС( B3: B11; ПОИСКПОЗ( ЛОЖЬ; ЕПУСТО ( B3: B11 ); 0 )) }
{ = INDEX( B3:B11; MATCH( FALSE; ISBLANK ( B3:B11 ); 0 )) }
Таким образом, суть проблемы заключается в следующем: мы хотим получить первую не пустую ячейку, но для этого нет конкретной формулы в Excel. Мы могли бы использовать ВПР с шаблоном *, но это будет работать только для текста, а не для чисел.
Таким образом, нам нужно строить функциональные возможности для нужных нам формул. Способ сделать это состоит в использовании функции массива, которая «тестирует» ячейки и возвращает массив истина/ложь значения, которые мы можем сопрягать с ПОИСКПОЗ.
Работая изнутри, ЕПУСТО оценивает ячейки в диапазоне В3: В11 и возвращает результат и массив, который выглядит следующим образом:
{ИСТИНА; ЛОЖЬ; ИСТИНА; ЛОЖЬ; ЛОЖЬ; ИСТИНА; ИСТИНА; ИСТИНА; ИСТИНА}
Каждая ЛОЖЬ представляет собой ячейку в диапазоне, который не является пустой.
Далее, ПОИСКПОЗ ищет ЛОЖЬ внутри массива и возвращает позицию первого наденного совпадения, в этом случае 2. На данный момент, формула в примере теперь выглядит следующим образом:
{ = ИНДЕКС( B3: B11; 2; 0 )) }
{ = INDEX( B3:B11; 2; 0 )) }
И, наконец, функция ИНДЕКС выводит значение в положении 2 в массиве, в этом случае число 10.
Ссылка на это место страницы:
#punk02
= ВПР ( «*»; диапазон; 1; ЛОЖЬ)
= VLOOKUP ( «*»; диапазон; 1; FALSE)
Если вам нужно получить первое текстовое значение в списке (диапазон один столбец), вы можете использовать функцию ВПР, чтобы установить точное соответствие, с шаблонным символом для поиска.

В данном примере формула в D7 является:
= ВПР ( «*» ; B5: B11 ; 1 ; ЛОЖЬ)
= VLOOKUP ( «*» ; B5:B11 ; 1 ; FALSE)
Групповой символ звездочка (*) соответствует любому текстовому значению.
Ссылка на это место страницы:
#punk03
= ГПР ( «*»; диапазон; 1; ЛОЖЬ)
= HLOOKUP ( «*»; диапазон; 1; FALSE)

Для поиска и получения первого текстового значения во всем диапазоне столбцов, вы можете использовать функцию ГПР с групповым символом. В примере формула в F5 является:
= ГПР ( «*»; диапазон; 1; ЛОЖЬ)
= HLOOKUP ( «*»; диапазон; 1; FALSE)
Значение поиска является «*», групповым символом, который соответствует одному или более текстовому значению.
Ссылка на это место страницы:
#punk04
= ГПР ( «*»; диапазон; 1; ЛОЖЬ)
= HLOOKUP ( «*»; диапазон; 1; FALSE)
Для того, чтобы получить позицию последнего совпадения (т.е. последнего вхождения) от значения поиска, вы можете использовать формулу, основанную на ЕСЛИ, СТРОКА, ИНДЕКС, ПОИСКПОЗ и MAКС функций.

=МАКС(ЕСЛИ(B4:B11=G5;СТРОКА(B4:B11)-СТРОКА(ИНДЕКС(B4:B11;1;1))+1))
=MAX(IF(B4:B11=G5;ROW(B4:B11)-ROW(INDEX(B4:B11;1;1))+1))
Суть этой формулы состоит в том, что мы строим список номеров строк для данного диапазона, соответствующие по значению, а затем используем функцию MAКС, чтобы получить наибольшее количество строк, что соответствует последнему значению соответствия.
Ссылка на это место страницы:
#punk05
=МАКС(ЕСЛИ(B4:B11=G5;СТРОКА(B4:B11)-СТРОКА(ИНДЕКС(B4:B11;1;1))+1))
=MAX(IF(B4:B11=G5;ROW(B4:B11)-ROW(INDEX(B4:B11;1;1))+1))
Чтобы проверить ячейку для одной из нескольких вещей, и вернуть последнее совпадение, найденное в списке, вы можете использовать формулу, основанную на ПРОСМОТР и ПОИСК функций. В случае нескольких найденных совпадений, формула вернет последнее совпадение из списка «вещей».

=ПРОСМОТР(2;1/ПОИСК($E$4:$E$7;B4);$E$4:$E$7)
=LOOKUP(2;1/SEARCH($E$4:$E$7;B4);$E$4:$E$7)
Ссылка на это место страницы:
#punk06
= НАИМЕНЬШИЙ( ЕСЛИ( логический тест; СТРОКА( список ) — МИН( СТРОКА( список )) + 1 ); n )
= SMALL( IF( логический тест; СТРОКА( список ) — MIN( ROW( список )) + 1 ); n )
Для того, чтобы получить позицию n-го совпадения (например, второе значение соответствия заданному, третье значение соответствия и т.д.), вы можете использовать формулу, основанную на функции НАИМЕНЬШИЙ.
= НАИМЕНЬШИЙ( ЕСЛИ( список = E5 ; СТРОКА( список ) — МИН( СТРОКА( список )) + 1 ); F5 )
= SMALL( IF( список = E5 ; ROW( список ) — MIN( ROW( список )) + 1 ); F5 )
Эта формула возвращает позицию второго появления «красных» в списке.
Сутью этой формулы является функция НАИМЕНЬШИЙ, которая просто возвращает n-е наименьшее значение в списке значений, которое соответствует номеру строки. Номера строк были «отфильтрованы» функцией ЕСЛИ, которая применяет логику для совпадения.
Ссылка на это место страницы:
#punk07
{ = ИНДЕКС( массив; НАИМЕНЬШИЙ( ЕСЛИ( величины = знач ; СТРОКА ( величины ) — СТРОКА ( ИНДЕКС( величины; 1 ; 1 )) + 1 ); n-й )) }
{ = INDEX( массив; SMALL( IF( величины = знач ; ROW ( величины ) — ROW ( INDEX( величины; 1 ; 1 )) + 1 ); n-й )) }

Эта формула возвращает позицию второго появления «красных» в списке.
Сутью этой формулы является функция НАИМЕНЬШИЙ, которая просто возвращает n-е наименьшее значение в списке значений, которое соответствует номеру строки. Номера строк были «отфильтрованы» функцией ЕСЛИ, которая применяет логику для совпадения.
Ссылка на это место страницы:
#punk08
= ВПР( id_формулы; стол; 4; 0 )
= VLOOKUP( id_формулы; стол; 4; 0 )
Чтобы получить n-ое совпадение с ВПР, вам необходимо добавить вспомогательный столбец в таблицу , которая строит уникальный идентификатор , который включает счетчик.

Эта формула зависит от вспомогательного столбца, который добавляется в качестве первого столбца таблицы исходных данных.
Вспомогательный столбец содержит формулу, которая строит уникальное значение взгляда вверх от существующего идентификатора и счетчика. Счетчик подсчитывает сколько раз уникальный идентификатор появился в таблице данных.
В примере, формула ячейки J6 вспомогательного столбца выглядит следующим образом:
=ВПР(J3&»-«&I6;B4:G11;4;0)
=VLOOKUP(J3&»-«&I6;B4:G11;4;0)
Ссылка на это место страницы:
#punk09
{ = ИНДЕКС( результаты ;ПОИСКПОЗ( ИСТИНА ; ЕЧИСЛО( ПОИСК( вещи ; A1 )); 0 )) }
{ = INDEX( результаты ;MATCH( TRUE ; ISNUMBER( SEARCH( вещи ; A1 )); 0 )) }
Чтобы проверить ячейку для одной из нескольких вещей, и вернуть пользовательский результат для первого найденного совпадения, вы можете использовать формулу ИНДЕКС/ПОИСКПОЗ, основанную на функции поиска.
{ = ИНДЕКС( результаты ; ПОИСКПОЗ( ИСТИНА ; ЕЧИСЛО( ПОИСК ( вещи ; B5 )); 0 )) }
= INDEX( результаты ; MATCH( TRUE ; ISNUMBER( SEARCH ( вещи ; B5 )); 0 ))
Эта формула использует два названных диапазона: E5: E8 называется «вещи» и F5: F8 называется «Результаты». Убедитесь, что вы используете диапазоны имен с одинаковыми именами (на основе ваших данных). Если вы не хотите использовать именованные диапазоны, используйте абсолютные ссылки вместо этого.
Ссылка на это место страницы:
#punk10
{ = ПОИСКПОЗ( ИСТИНА ; ЕОШИБКА(диап ); 0 ) }
{ = MATCH( TRUE ; ISERROR(диап ); 0 ) }
Если вам нужно найти первую ошибку в диапазоне ячеек, вы можете использовать формулу массива, основанную на ПОИСКПОЗ и ЕОШИБКА функциях.

В приведенном примере формула:
{ = ПОИСКПОЗ( ИСТИНА ; ЕОШИБКА( B4: B11 ); 0 ) }
{ = MATCH( TRUE ; ISERROR( B4:B11 ); 0 ) }
Работая изнутри, функция ЕОШИБКА возвращает значение ИСТИНА, если значение является признанной ошибкой, и ЛОЖЬ, если нет.
Когда дается диапазон ячеек (массив ячеек) функция ЕОШИБКА будет возвращать массив истина/ложь значений. В примере, это результирующий массив выглядит следующим образом:
{ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ИСТИНА; ЛОЖЬ; ЛОЖЬ}
Обратите внимание, что 6-е значение (что соответствует 6-й ячейке в диапазоне) истинно, так как ячейка В9 содержит #Н/A.
Ссылка на это место страницы:
#punk11
=ИНДЕКС ( данные; ПОИСКПОЗ( поиск ; значения ) + 1 )
=INDEX ( данные; MATCH( поиск ; значения ) + 1 )

Для того, чтобы найти «следующее наибольшее» значение в справочной таблице, можно использовать формулу, основанную на ИНДЕКС и ПОИСКПОЗ. В примере формула в F6 является:
=ИНДЕКС ( данные; ПОИСКПОЗ( поиск ; значения ) + 1 )
=INDEX ( данные; MATCH( поиск ; значения ) + 1 )
Ссылка на это место страницы:
#punk12
{ = ОБЪЕДИНИТЬ ( «;» ; ИСТИНА ; ЕСЛИ( диапазон1 = E5 ; диапазон2 ; «» )) }
{ = ОБЪЕДИНИТЬ ( «;» ; TRUE ; IF( диапазон1 = E5 ; диапазон2 ; «» )) }
Для поиска и извлечения нескольких совпадений, разделенных запятыми (в одной ячейке), вы можете использовать функцию ЕСЛИ с функцией ОБЪЕДИНИТЬ.
{ = ОБЪЕДИНИТЬ( «;» ; ИСТИНА ; ЕСЛИ( группа = E5 ; имя ; «» )) }
Эта формула использует «имя» — именованный диапазон (B5: B11) и «группа» — (C5: C11).
Ссылка на это место страницы:
#punk13
{ = ПОИСКПОЗ( «*» & номер & «*» ; ТЕКСТ( диапазон ; «0» ); 0 ) }
{ = MATCH( «*» & номер & «*» ; TEXT( диапазон ; «0» ); 0 ) }
Для того, чтобы выполнить частичное совпадение (подстроки) против чисел, вы можете использовать формулу массива, основанную на ПОИСКПОЗ и ТЕКСТ.

Excel поддерживает символы подстановки «*» и «?». Тем не менее, если вы используете специальные символы с номером, вы будете преобразовывать числовое значение в текстовое значение. Другими словами, «*» & 99 & «*» = «* 99 *» (текстовая строка).
Если попытаться найти текстовое значение в диапазоне чисел, совпадение завершится неудачно.
Одно из решений заключается в преобразовании чисел в диапазоне поиска для текстовых значений, а затем сделать нормальный поиск с ПОИСКПОЗ, ВПР и т.д.
Другой способ, чтобы преобразовать числа в текст, чтобы сцепить пустую строку. Эта формула работает так же, как выше формуле:
= ПОИСКПОЗ ( «*» & Е5 & «*» ; В5: В10 & «» ; 0 )
= MATCH ( «*» & Е5 & «*» ; В5: В10 & «» ; 0 )
Ссылка на это место страницы:
#punk14
Если вы хотите получить информацию из таблицы на основе частичного совпадения, вы можете сделать это с помощью ВПР в режиме точного соответствия, и групповые символы.

В примере формула ВПР выглядит следующим образом:
=ВПР($H$2&»*»;$B$3:$E$12;2;0)
=VLOOKUP($H$2&»*»;$B$3:$E$12;2;0)
В этой формуле, значение представляет собой именованный диапазон, который относится к Н2, а также данные , представляет собой именованный диапазон , который относится к B3: E102. Без названных диапазонов, формула может быть записана следующим образом:
Ссылка на это место страницы:
#punk15
= ПОИСКПОЗ ( «* текст *» ; диапазон; 0 )
= MATCH ( «* текст *» ; диапазон; 0 )
Для того, чтобы получить позицию первого частичного совпадения (то есть ячейку, которая содержит текст, который вы ищете), вы можете использовать функцию ПОИСКПОЗ со специальными символами.

=ПОИСКПОЗ(«*»&E6&»*»;B5:B10;0)
=MATCH(«*»&E6&»*»;B5:B10;0)
Функция ПОИСКПОЗ возвращает позицию или «индекс» в первом совпадении на основании значения поиска в диапазоне.
ПОИСКПОЗ поддерживает подстановочное согласование со звездочкой «*» (один или несколько символов) или знаком вопроса «?» (один символ), но только тогда, когда третий аргумент, тип_сопоставления, установлен в ЛОЖЬ или ноль.
Ссылка на это место страницы:
#punk16
Файлы статей доступны только зарегистрированным пользователям.
1. Введите свою почту
2. Нажмите Зарегистрироваться
3. Обновите страницу
Вместо этого блока появится ссылка для скачивания материалов.

Привет! Меня зовут Дмитрий. С 2014 года Microsoft Cretified Trainer. Вместе с командой управляем этим сайтом. Наша цель — помочь вам эффективнее работать в Excel.
Изучайте наши статьи с примерами формул, сводных таблиц, условного форматирования, диаграмм и макросов. Записывайтесь на наши курсы или заказывайте обучение в корпоративном формате.

Подписывайтесь на нас в соц.сетях: