
Это глава из книги: Майкл Гирвин. Ctrl+Shift+Enter. Освоение формул массива в Excel. [1]
Предыдущая глава Оглавление Следующая глава
Извлечение данных (записей) из таблицы, списка или базы данных
Извлечение данных из набора данных на основе критериев И, ИЛИ – типичная задача для Excel. Вы можете решить ее, используя один из следующих методов:
- Фильтр
- Расширенный фильтр
- Обычная формула в специально добавленном столбце
- Формула массива на основе функций НАИМЕНЬШИЙ и ИНДЕКС
- Формулу массива на основе функций АГРЕГАТ и ИНДЕКС

Рис. 15.1. Аккуратный набор данных
Скачать заметку в формате Word или pdf, примеры в формате Excel
Учитывайте следующие важные моменты в отношении этих методов:
- Фильтр и расширенный фильтр, как правило, легче использовать, чем формулы, но они не дают моментального обновления, в отличие от формул.
- Формулы обновляются моментально, как только в ячейке изменился критерий.
- Обычная формула в специально добавленном столбце работает быстрее формулы массива
- Мы не рассматриваем решения на основе кода VBA, хотя они могут быть весьма эффективными.
Использование Фильтра (Автофильтра) для извлечения данных
Опция Фильтр (также известная как Автофильтр) наиболее проста в использовании. Если у вас аккуратный набор данных с заголовками столбцов (рис. 15.1), вы можете включить фильтр, встав на любую ячейку области, и пройдя по меню ДАННЫЕ –> Фильтр, или нажав Ctrl+Shift+L. Теперь можно использовать стрелочки вверху каждого столбца для фильтрации данных. Как только набор данных фильтруется, можно выделить и скопировать видимые ячейки в другое место того же или нового листа (рис. 15.2–15.4), или в новую книгу.
На рис. 15.2 данные извлечены по следующим критериям: Дата >=01.06.12, Дата <=31.05.13, Регион = West. Для того чтобы выполнить фильтрацию:
- Щелкните стрелку на поле Дата, выберите Фильтр по дате –> Между…, введите или выберите из календаря требуемые даты.
- Щелкните стрелку на поле Регион и оставьте галку только напротив West.

Рис. 15.2. Результат фильтрации по трем И критериям
На рис. 15.3 показан результат извлечения записей по критерии ИЛИ: регион = West либо регион = Est.

Рис. 15.3. Результат фильтрации по ИЛИ критерию
На рис. 15.4 показаны записи, извлеченные с помощью нескольких И критериев и одного ИЛИ: Дата >=01.06.12 И Дата <=31.05.13 И (регион = West ИЛИ регион = Est). Обратите внимание, что ИЛИ критерий относится к одному и тому же столбцу.

Рис. 15.4 Результат фильтрации с тремя И критериями, где третий И критерий включает в себя ИЛИ
Если ИЛИ критерий должен относится к разным столбцам, опция Фильтр не поможет. Используйте вспомогательный столбец с формулой. Примените фильтр к вспомогательному столбцу, чтобы показать только значения ИСТИНА (рис. 15.5).

Рис. 15.5 Вспомогательный столбец помогает отфильтровать по критерию ИЛИ, относящемуся к двум столбцам
Эти примеры показывают, насколько легко и быстро можно применить опцию Фильтр. Если вам не нужно мгновенное обновление извлеченных данных при смени критериев отбора, Фильтр является предпочтительным инструментом.
Использование Расширенного фильтра для извлечения записей
Расширенный фильтр в отличии от Фильтра требует введения критериев в ячейки. Кроме того, вы должны использовать диалоговое окно, вместо выпадающих меню в верхней части каждого столбца для фильтрации данных. Расширенный фильтр также может выполнить несколько задач, которые не под силу Фильтру.
Чтобы применить Расширенный фильтр:
- Для Расширенного фильтра, столбцы должны быть озаглавлены, а область критериев – содержать те же заголовки и сами критерии. При этом, И критерии должны располагаться в одной строке, а ИЛИ критерии – в различных (рис. 15.6-а).
- Чтобы открыть диалоговое окно Расширенный фильтр, пройдите по меню ДАННЫЕ –> Сортировка и фильтр –> Дополнительно, или нажмите Alt, и не отпуская нажмите последовательно Ы, Л
- Заполните диалоговое окно Расширенный фильтр, как показано на рис. 15.6-б.
- Кликните Ok. Имена полей и записи извлекаются, и записываются в указанное место. При это создаются два имени, которые можно увидеть в Диспетчере имен. Последний можно открыть, нажав Ctrl+F3 (рис. 15.6-в). Благодаря созданию имен, при последующих запусках диалогового окна Расширенный фильтр, параметры сохраняются. Поэтому вы можете просто изменить критерии и повторно запустить Расширенный фильтр.
- Если вы хотите сохранить предыдущие результаты, при каждом новом запуске Расширенного фильтра просто измените ячейку в поле Поместить результат в диапазон.

Рис. 15.6. Расширенный фильтр для извлечения данных с И критериями; при запуске Расширенного фильтра определяются два имени: Извлечь, Критерии
На рис. 15.8–15.12 приведены примеры использования Расширенного фильтра.

Рис. 15.7. Расширенный фильтр для извлечения данных с ИЛИ критерием

Рис. 15.8. Расширенный фильтр для извлечения данных с И и ИЛИ критериями; ИЛИ критерий применен к одному столбцу

Рис. 15.9. Расширенный фильтр для извлечения данных с И и ИЛИ критериями; ИЛИ критерий применен к двум столбцам

Рис. 15.10. Расширенный фильтр может использовать логические формулы в качестве критерия. Обратите внимание, что критерии в поле Диапазон условий указан В6:В7. Обычно этот диапазон включает в себя имя поля из набора данных и критерий. Но только не в этом случае. Используя логическую формулу, ячейку В6 следует оставить пустой или поместить текст, не совпадающий ни с одним из имен полей. В ячейке В7 следует разместить логическую формулу. Это пример извлекает те же данные, как и на рис. 15.9.
Рис. 15.11. Если вы хотите извлечь уникальный список из одного столбца, вы можете это сделать с помощью Расширенного фильтра. Отметьте флажок Только уникальные записи. Этот трюк всегда требует, чтобы, во-первых, имя поля было включены в Исходный диапазон, и во-вторых, чтобы имя извлекаемых данных (ячейка F3) называлось также. Поэкспериментируйте с извлечением уникальных регионов.
Примеры показывают, что Расширенный фильтр дает вам больше возможностей фильтрации чем Фильтр:
- Вы можете видеть критерии в ячейках (в Фильтре они скрываются за выпадающими стрелками Автофильтра).
- Вы можете обрабатывать сложные И и ИЛИ критерии.
- Вы можете использовать формулы в качестве критерия.
- Вы можете получить уникальный список.
Фильтр и Расширенный фильтр очень просты в использовании, и будут использоваться довольно часто. Но иногда требуется немедленное обновление формул. К сожалению, за оперативность приходится расплачиваться сложностью.
Формулы для извлечения записей
При извлечении данных из таблицы, вы фактически осуществляете поиск. Стандартные функции поиска в Excel, такие как ИНДЕКС, ПОИСКПОЗ и ВПР прекрасно себя зарекомендовали, но они не справляются с дублями. Как показано на рис. 15.12, если цель состоит в извлечении записей по трем критериям, итогом должны стать две выделенные записи. Для вертикальной таблицы, формулы подстановки легко извлекают данные из нескольких столбцов; но не справляются с извлечением данных из нескольких строк.
Если вам нужна формула, чтобы извлечь записи, у вас есть два основных варианта:
- Использовать стандартную функцию поиска на основе вспомогательного столбца. Последний содержит формулу, которая, например, выдает числа: 1, 2, 3, … для «правильных» записей. Как только критерии поменяются, формула тут же отработает изменения, и снова находит записи, соответствующие критериям. Эти последовательные цифры решают проблему дублей, потому что есть уникальный идентификатор для каждой найденной записи. Вспомогательный столбец служит в качестве столбца подстановки, что позволяет стандартным функциям поиска выполнять свою работу.
- Использовать формулы массива на основе полного набора данных. Эти формулы являются автономными и не требуют дополнительного столбца. Для этих формул, вы должны создать внутри формулы массив относительных позиций для записей, которые соответствуют критериям. Эти формулы позволяют извлекать записи при наличии дублей.

Рис. 15.12. Должны быть извлечены две записи; стандартные функции поиска замучаются с дублями (строки раскрашены с помощью условного форматирования, что можно подробнее изучить на соответствующем листе приложенного Excel-файла)
Использование вспомогательного столбца, И критерия и функций ИНДЕКС / ПОИСКПОЗ
На рис. 15.13 представлены три критерия, собранные во вспомогательном столбце с помощью функции И. Этот столбец будет служить в качестве столбца подстановки для функции ИНДЕКС.

Рис. 15.13. Первая часть формулы вспомогательного столбца включает функцию И; чтобы увеличить картинку, кликните на ней правой кнопкой мыши и выберите опцию Открыть картинку в новой вкладке
Проблема с использованием функции И заключается в том, что она возвращает лишь два значения: ИСТИНА и ЛОЖЬ. Т.е., вы вернулись к проблеме дублей в столбце подстановки. Вы бы хотели, чтобы первая ИСТИНА (в ячейке E14) имела номер 1, а вторая (в ячейке Е17) – номер 2. Этого можно достичь путем внесения изменений в формулу. Как показано на рис. 15.14, вы помещаете функцию И в качестве аргумента число1 функции СУММ, а в качестве аргумента число2 вы помещаете относительную ссылка на одну ячейку выше.

Рис. 15.14. Финальный вид формулы вспомогательного столбца
Вот как работает эта формула:
- Булевы (логические) значения ИСТИНА и ЛОЖЬ, возвращаемые функцией И, будут преобразованы соответственно в единицы и нули, внутри функции СУММ.
- Функция СУММ игнорирует текст, и поэтому относительная ссылка на ячейку Е7 в аргументе число2, обнаружив текст Вспомогательный, вернет ноль.
- Когда формула дойдет до ячейки E14, значение на одну ячейки выше будет 0, а значение в самой ячейке Е14 будет 1. Итого = 1.
- В ячейках E15 и E16, формула будет добавлять 0 к предыдущему значению, и по-прежнему возвращать 1.
- В ячейке E17, формула сложит 1 (из предыдущей ячейки) и 1 (ИСТИНА). Итого = 2.
- Дубли не составят проблемы при использовании стандартной функции поиска, т.к., вы можете задать Точное совпадение и, следовательно, все повторяющиеся значения кроме первого будут проигнорированы.
- Выполнив Точное совпадение, вы не только игнорируете дубли, вы также косвенно создаете столбец с уникальными идентификаторами: 1, 2 и т.д., который позволит функции ВПР извлечь нужные данные.
Вы можете добавить вспомогательную ячейку для подсчета общего числа записей, которые требуется извлечь (рис. 15.15). Это можно сделать, например, используя функцию МАКС в ячейке Н6. Вспомогательная ячейка добавляет наглядности и ускоряет работу Excel (если вы поместите фрагмент МАСК($Е$8:$Е$17) внутрь окончательной формулы поиска для извлечения данных, этот расчет будет выполняться много раз). Вы можете использовать вспомогательную ячейку (строку или столбец) всякий раз, когда у вас есть элемент формулы, многократно используемый в другой формуле.

Рис. 15.15. Ячейка Н6 с помощью функции МАКС вычисляет количество записей; это еще один пример вспомогательной ячейки
Вы можете начать основную формулу с функции ЕСЛИ (рис. 15.16). Поскольку формула должна предусматривать различное число извлекаемых записей, аргумент лог_выражение проверяет, не превышает ли номер записи (1 в ячейке $G12) общее число «правильных» записей в ячейке $Н$6. Если аргумент лог_выражение принимает значение ИСТИНА, в ячейку помещается пустая текстовая строка. Если лог_выражение принимает значение ЛОЖЬ, используется стандартная функция поиска.

Рис. 15.16. Функция ЕСЛИ предпочтительнее для запуска формулы поиска, по сравнению с функцией ЕСЛИОШИБКА (первая функция работает быстрее; подробнее об этом см. Глава 9. Знакомство с функциями массива. ТРАНСП, МОДА.НСК и ТЕНДЕНЦИЯ)
На рис. 15.17 формула извлечения данных приведена в финальном виде. Обратите внимание:
- Диапазон изменения аргумента массив функции ИНДЕКС представлен смешанной ссылкой – А$8:A$17; заблокирована только ссылка на строки (представлена в виде абсолютной ссылки), что позволяет скопировать формулу право вдоль строки; формула в ячейке I12 будет ссылаться на диапазон В$8:В$17. А при копировании формулы вниз вдоль столбца ссылка заблокирована. Так что в ячейке Н13 формула по-прежнему будет ссылаться на диапазон А$8:A$17.
- Аргумент искомое_значение функции ПОИСКПОЗ содержит искомое значение – номер 1, в ячейке $G Аналогично, смешанная ссылка позволяет при копировании по строке сохранять ссылку на ячейку $G12, а при копировании по столбцу перейти к ссылке на ячейку $G13, то есть, перейти к номеру 2.
- Аргумент просматриваемый_массив функции ПОИСКПОЗ включает абсолютную ссылку, так что из любой ячейки мы обратимся к одному и тому же диапазону $E$8:$E$17.
- Аргумент тип_сопоставления функции ПОИСКПОЗ равен нулю, так что выполняется поиск точного совпадения.

Рис. 15.17. Окончательная формула поиска
Формула, введенная в ячейку Н12 копируется в диапазоне Н12:К17.
Примечание: когда вы копируете ячейку, копируются и формулы, и форматирование. Чтобы избежать копирования форматирования чисел, после копирования воспользуйтесь опцией смарт-тега Заполнить только значения:

Вы скопировали формулу вниз до строки 17. Но как далеко вниз вы должны скопировать формулу извлечения данных? Скопируйте с запасом, чтобы предусмотреть потенциально большое число извлеченных записей.

Рис. 15.18 показывает, в чем прелесть использования формул вместо Фильтра или Расширенного фильтра: при изменении критериев (дат), формулы отработали мгновенно. Рис. 5.19 показывает, как можно изменить формулу, если вы не хотите использовать столбец номеров (G). Дважды замените ссылку $G12 на фрагмент ЧСТРОК(H$12:H12).
Рис. 15.18. При изменении критериев формулы отработали мгновенно
![]()
Рис. 15.19. Эта формула будет работать без столбца с номерами
В следующих разделах мы рассмотрим еще три примера того, как использовать вспомогательные столбцы для извлечения данных.
Использование вспомогательного столбца, ИЛИ критерия и ВПР в качестве функции поиска
На рис. 15.20 вспомогательный столбец расположен первым, так что вы можете использовать функцию ВПР. Обратите внимание на использование функции ЧИСЛОСТОЛБ в аргументе номер_столбца функция ВПР для увеличения номера 1, 2, 3, …, при копировании формулы вправо вдоль строки.

Рис. 15.20. Использование вспомогательного столбца, ИЛИ критерия и ВПР в качестве функции поиска; формула в ячейке G10 показана в строке формул
Примечание: если все критерии ИЛИ расположены в одном столбце (в примере выше – в столбце В, в диапазоне В3:В4), вы можете использовать одну из двух конструкций: (1) функции ЕЧИСЛО + ПОИСКПОЗ; (2) функцию ИЛИ. Если критериев больше двух, первый вариант предпочтительнее. Если критериев ровна два, второй вариант может быть более наглядным. Во втором случае формула в А10 имеет вид:
=СУММ(ИЛИ(D10=$B$3;D10=$B$4);А9)
Использование вспомогательного столбца, критериев И и ИЛИ, функций ИНДЕКС и ПОИСКПОЗ для извлечения части столбцов данных
На рис. 15.21 показан пример использования вспомогательного столбца для извлечения данных из столбцов Дата и Штуки. Заметьте, что функция ИНДЕКС выполняет поиск (с помощью функции ПОИСКПОЗ), как по строкам, так и по столбцам.

Рис. 15.21. Критерии И и ИЛИ, в двух-координатном поиске для извлечения части столбцов по их названию; формула в ячейке G10 показана в строке формул
Использование вспомогательного столбца, критериев И и ИЛИ для извлечения данных и представления их в горизонтальном виде
На рис. 15.22 показано, как преодолеть несоответствие между текстовым названием месяца, как критерия (ячейка С3), и порядковым номером даты в поле Дата (например, в ячейке А10 хранится значение 41484). Также показано, что данные могут быть извлечены из вертикальной таблицы и отображаться горизонтально. Это выполняется с помощью функции ЧИСЛСТОЛБ в аргументе лог_выражение функции ЕСЛИ и в аргументе искомое_значение функции ПОИСКПОЗ.

Рис. 15.22. Критерии И и ИЛИ, и несоответствие между текстовым названием месяца, как критерия, и порядковым номером даты в поле Дата. Данные извлекаются из вертикальной таблицы и отображается горизонтально с помощью двух-координатного поиска и функции ЧИСЛСТОЛБ. Формула в ячейке G10 показана в строке формул
Мы рассмотрели, как применять вспомогательные столбцы. Однако, если вспомогательные столбцы не могут быть использованы, нужно переходить к формулам массива.
Создание массива относительных позиций отобранных записей внутри формулы
Извлечение данных с помощью формулы массива основано на создании массива относительных позиций отобранных записей внутри формулы. На рис. 15.23 видно, что на основе критериев И установлено соответствие записей критериям в относительных позициях 7 и 10 (внутри 10 строк массива данных; выделены желтым). Поскольку вы не можете использовать вспомогательный столбец, вы должны рассчитать эти номера 7 и 10 внутри формулы. Затем номера 7 и 10 будут использованы в аргументе номер_строки функции ИНДЕКС. Ранее, вы уже сталкивались с элементами, необходимыми для создания относительной позиции внутри массива:
- В главах 4 и 11 вы узнали об использовании Булевой алгебры и функции ЕСЛИ для фильтрации элементов внутри формулы (см. Глава 4. Сравнение массивов и выборки по одному или нескольким условиям и Глава 11. Булева логика: критерии И, ИЛИ).
- В главе 8 вы узнали о фрагменте формулы, который создает массив последовательных чисел, или относительных позиций: СТРОКА(диапазон) – СТРОКА(первая_ячейка_в_ диапазоне) + 1 (см. Глава 8. Формулы массива, возвращающие более одного значения).
Если вы используете Excel 2007 или более раннюю версию, вы можете создать массив с помощью функций НАИМЕНЬШИЙ и ЕСЛИ, что потребует нажатия Ctrl+Shift+Enter для ввода формулы. Если вы используете Excel 2010 или более позднюю версию, вы можете использовать функцию АГРЕГАТ и логическое деление, а значит формула не потребует нажатия Ctrl+Shift+Enter.

Рис. 15.23. Искомые записи находятся в относительных позициях 7 и 10
Формулы массива для извлечения данных с И критерием и функциями НАИМЕНЬШИЙ, ЕСЛИ, ИНДЕКС
Как показано на рис. 15.24, вы начинаете написание формулы в ячейке F12 с трех функций ЕСЛИ (вложенных друг в друга) в аргументе массив функции НАИМЕНЬШИЙ. Аргументы лог_выражение трех функций ЕСЛИ являются фильтром для отбора относительно позиций строк, отвечающих всем критериям. Как показано на рис. 15.25, вы помещаете элемент формулы для создания массива относительных позиций отобранных записей в аргумент значение_если_истина функции ЕСЛИ и затем закрываете три ЕСЛИ тремя закрывающими скобками, оставляя все аргументы значение_если_ложь пустыми.
Примечание: элемент формулы для создания массива относительных позиций, может использовать любой из столбцов в наборе данных. В нашем примере используется столбец Дата: СТРОКА($A$11:$A$20)-СТРОКА($A$11)+1 – но вы так же можете использовать столбец Регион, Клиент или Штук. Например, СТРОКА($В$11:$В$20)-СТРОКА($В$11)+1.

Рис. 15.24. Три ЕСЛИ внутри функции НАИМЕНЬШИЙ, чтобы обработать три критерия

Рис. 15.25. Элемент формулы для создания массива относительных позиций отобранных записей располагается в аргументе значение_если_истина функции ЕСЛИ
Если, находясь в ячейке F12, вы в строке формул кликните внутри функции НАИМЕНЬШИЙ, то появится подсказка НАИМЕНЬШИЙ(массив; k). Если теперь кликнуть на первом аргументе функции – массив, то выделится весь первый аргумент (рис. 15.26 а). Нажмите F9, и вы увидите значения массива относительных позиций отобранных записей на фоне значений ЛОЖЬ (рис. 15.26 б). Чтобы отменить перевод формулы в значения, нажмите Ctrl+Z.

Рис. 15.26. Выделите фрагмент формулы, нажмите F9 и вы увидите значения массива относительных позиций отобранных записей на фоне значений ЛОЖЬ
Зачем мы помещаем массив относительных позиций отобранных записей внутрь функции НАИМЕНЬШИЙ? Дело в том, что НАИМЕНЬШИЙ извлекает сначала 7, а затем 10, а скопировав формулу вниз по столбцу, можно подставить эти цифры в аргумент номер_строки функции ИНДЕКС. Когда мы помещаем нумератор ЧСТРОК(F$12:F12) в аргумент k (рис. 15.27), функция НАИМЕНЬШИЙ возвращает правильное относительное положение в аргумент номер_строки функции ИНДЕКС. Не забудьте, что для ввода этой формулы (точнее фрагмента) требуется нажать Ctrl+Shift+Enter. Результат копирования этой формулы в диапазон F12:I17 показан на рис. 15.28.

Рис. 15.27. Фрагмент формулы, последовательно извлекающий номера строк, отвечающих критериям

Рис. 15.28. Только две записи соответствуют критериям, протягивание формулы далее вниз выдает ошибку
Как показано на рис. 15.29, функция НАИМЕНЬШИЙ, возвращающая относительную позицию отобранных строк, располагается в аргументе номер_строки функции ИНДЕКС.

Рис. 15.29. Функция НАИМЕНЬШИЙ располагается в аргументе номер_строки функции ИНДЕКС
Как показано на рис. 15.30, если ввести этот фрагмент формулы с помощью Ctrl+Shift+Enter в ячейку F12 и затем скопировать на весь диапазон, вы получите извлеченные записи. Ошибка #ЧИСЛО! вызвана тем, что только две записи соответствуют критериям отбора. Для третей и четвертой строк не нашлось данных.

Рис. 15.30. Только две записи являются релевантными
Рис. 15.31 показывает, как можно использовать функцию ЕСЛИ для замены ошибочного значения на нулевую текстовую строку. В целом формула выполняет большую работу, поэтому, чтобы не делать ее зря (и не замедлять расчеты), начните с проверки и подстановки нулевой текстовой строки.

Рис. 15.31. Используйте функцию ЕСЛИ для скрытия значений ошибок
Вы можете ввести построенную формулу в ячейку F12 нажав Ctrl+Shift+Enter (рис. 15.32), а затем скопировать ее на весь диапазон.

Рис. 15.32. Извлечены две записи

Рис. 15.33. Если критерии отбора изменились, формула мгновенно обновится; изменились даты
Формулы массива для извлечения данных с использованием функции АГРЕГАТ
Если у вас Excel 2010 или более поздняя версия, можно использовать функцию АГРЕГАТ, что позволит избежать использования Ctrl+Shift+Enter для ввода формулы. Как вы узнали в главах 4 и 11, можно использовать булеву алгебру для фильтрации значений внутри аргумента массив функции АГРЕГАТ. В этом примере отфильтрованным значениям будут сопоставлены относительные позиции.
Как показано на рис. 15.37, функция АГРЕГАТ расположена в аргументе номер_строки функции ИНДЕКС. Вы используете 15 в аргументе номер_функции АГРЕГАТ, что соответствует функции НАИМЕНЬШИЙ. Вы используете 6 в аргументе параметры, поручая функции АГРЕГАТ игнорировать ошибки. Вы строите массива булевых значений в аргументе массив функции АГРЕГАТ. Обратите внимание, что в числителе выражение в скобках создает массив относительных позиций – СТРОКА($A$11:$A$20)-СТРОКА($A$11)+1. В знаменателе размещены перемноженные три критерия – ($A$11:$A$20>=$B$3)*($A$11:$A$20<=$C$3)*($B$11:$B$20=$D$3).

Рис. 15.37. Функция АГРЕГАТ в аргументе номер_строки функции ИНДЕКС
Как показано на рис. 15.38, если вычислить числитель, вы получите ряд натуральных чисел, а в знаменателе – последовательность нулей и единиц. Знаменатель вернет единицу только если все три критерия выполнены.

Рис. 15.38. Аргумент массив функции Агрегат
Если продолжить вычисления (рис. 15.39), вы получить массив, включающий номера отобранных записей и значений ошибок #ДЕЛ/0! Ошибки фильтруются (игнорируются) аргументом 6 функции АГРГЕГАТ.

Рис. 15.39. Ошибки #ДЕЛ/0! соответствуют записям, не удовлетворяющим критериям
Как показано на рис. 15.40, вы можете закончить формулу, поместив счетчик – ЧСТРОК(F$12:F12) в качестве аргумента k функции АГРЕГАТ (не забывайте, что в данном примере она работает как функция НАИМЕНЬШИЙ). В диапазоне F12:I12 k принимает значение 1, в диапазоне F12:I12 – 2, далее не актуально, так как k становится больше значения в ячейке А7.

Рис. 15.40. Счетчик в аргументе k функции АГРЕГАТ
Финальная формула не требует ввода с помощью Ctrl+Shift+Enter. На рис. 15.41 и 15.42 показано, что вы можете изменить критерии и формулы мгновенно обновятся.

Рис. 15.41. Извлечены две записи

Рис. 15.42. Если критерии отбора изменились, формула мгновенно обновится; изменились даты
Возврат нескольких элементов на основе одного значением поиска
Стандартные функции поиска в Excel – ВПР, ПОИСКПОЗ и ИНДЕКС – если вы строите формулу массива, не могут возвращать несколько элементов с одним значением поиска. Как показано на рис. 15.44, вам необходимо выбрать название группы (Cascade в ячейки D3), найти все вхождения в базу данных (А2:В52), соответствующие выбранной группе, и вернуть связанные фамилии в поле Сотрудники (D5:D25). Можно использовать формулу на основе функций АГРЕГАТ (не требует ввода Ctrl+Shift+Enter) или НАИМЕНЬШИЙ (требует ввода Ctrl+Shift+Enter):
=ЕСЛИ(ЧСТРОК(D$6:D6)>E$3;"";ИНДЕКС($A$3:$A$52;АГРЕГАТ(15;6;(СТРОКА($A$3:$A$52)-СТРОКА(A$3)+1)/($B$3:$B$52=D$3);ЧСТРОК(D$6:D6))))
{=ЕСЛИ(ЧСТРОК(D$6:D7)>E$3;"";ИНДЕКС($A$3:$A$52;НАИМЕНЬШИЙ (ЕСЛИ($B$3:$B$52=D$3;СТРОКА($A$3:$A$52)-СТРОКА(D$3)+1);ЧСТРОК(D$6:D7))))}
Рис. 15.44 показан пример формулы на основе функции АГРЕГАТ. Формулу на основе НАИМЕНЬШИЙ можно найти во вложенном Excel-файле.

Рис. 15.44. Можно использовать функции НАИМЕНЬШИЙ или АГРЕГАТ в аргументе номер_строки функции ИНДЕКС
В качестве альтернативы использованию формулы массива для извлечения сотрудников по имени группы можно воспользоваться обычной ВПР, предварительно создав вспомогательный столбец (рис. 15.45). Обратите внимание на формулу в А3, а также на то, как представлено ее описание в ячейке А1 (его можно видеть в строке формул).

Рис. 15.45. Используя вспомогательный столбец можно извлечь данные обычной ВПР
Извлечение данных с ИЛИ критерием из одного столбца: Булева алгебра или ПОИСКПОЗ?
Этот пример является продолжением предыдущего примера. После извлечения всех имен сотрудников выбранной группы, вы можете использовать их в ИЛИ критерии, для извлечения части записей из набора данных. На рис. 15.46 обратите внимание на следующие:
- Критерии ИЛИ находятся в диапазоне I6:I
- Для каждой записи в наборе данных, формула должна задать вопрос, входит ли имя в диапазон критериев.
- Вы используете ЕЧИСЛО/ПОИСКПОЗ вместо 16 булевых проверок.

Рис. 15.46. Для извлечения данных с большим числом ИЛИ критериев в одном столбце используйте комбинацию функций ЕЧИСЛО/ПОИСКПОЗ; формула в ячейке F8 показана в строке формул
Вы также можете использовать альтернативную формулу в ячейке F8 которая не требует ввода Ctrl+Shift+Enter, так как основана на функции АГРЕГАТ):
=ЕСЛИ(ЧСТРОК(F$8:F8)>$G$5;"";ИНДЕКС(B$5:B$936;АГРЕГАТ(15;6;(СТРОКА($B$5:$B$936)-СТРОКА($B$5)+1)/ЕЧИСЛО(ПОИСКПОЗ($B$5:$B$936;$I$6:$I$21;0));ЧСТРОК(F$8:F8))))
Извлечение данных с ИЛИ критериями в более чем одном столбце
На рис. 15.49 задача – извлечь записи, либо региона West, либо клиентов K с числом штук от 400 до 1300. Обратите внимание: (1) это двух-координатный поиск, где функция НАИМЕНЬШИЙ возвращает массив относительных позиций строк в аргумент номер_строки функции ИНДЕКС, а ПОИСКПОЗ возвращает относительную позицию столбцов в аргумент номер_столбца функции ИНДЕКС; (2) совокупность ИЛИ критериев может вернуть 1 или 2, но это не вызовет проблем, поскольку аргумент лог_выражение любое ненулевое число, интерпретирует как ИСТИНА.

Рис. 15.49. Критерии ИЛИ, работающие на разных столбцах + И критерии
Извлечение данных с И и ИЛИ критериями, и чисел, делящихся на 5
На рис. 15.51 задача – извлечь записи, либо региона West, либо клиентов K, с числом штук кратным 5. Обратите внимание на две особенности использования Булевой алгебры: (1) функция ОСТАТ возвращает 0 для значений кратных 5. Если ОСТАТ равен нулю, фрагмент формулы ОСТАТ($D$11:$D$20;$C$5)=0 вернет ИСТИНА; (2) Булево ИЛИ отвечает на вопрос: «Больше нуля?»: ($B$11:$B$20=$B$5)+($C$11:$C$20=$B$7)>0. Нельзя просто сравнить с 1, так как вы можете получить два значения ИСТИНА из двух столбцов.

Рис. 15.51. Формула массива на основе функции АГРЕГАТ для извлечения данных с И и ИЛИ критериями; использует функцию ОСТАТ для извлечения только количеств, делящихся на 5; формула в ячейке G11 отражена в строке формул
Сравнение двух списков
На рис. 15.53 задача – извлечь имена из Списка 2, которых нет в Списке 1. Функция ПОИСКПОЗ сравнивает два списка и возвращает ошибку #Н/Д, когда не находит нужного имени. С помощью функции ЕНД инвертируйте значение, чтобы получить ИСТИНУ, когда возвращается ошибка.

Рис. 15.53. Классическая формула сравнения двух списков; формула в ячейке Е9 отражена в строке формул
На рис. 15.54 решается обратная задача – извлечь имена, имеющиеся в обоих списках. Вместо ЕНД используется функция ЕЧИСЛО.

Рис. 15.54. Извлечение имен, имеющихся в обоих списках
Вспомогательные столбцы в области извлеченных данных
На рис. 15.55 задача – извлечения все записи, относящиеся к регионам West и Est. Допустим вам нельзя создать вспомогательный столбец в области данных, но вы хотите уменьшить время расчета формулы, так что решаете создать вспомогательный столбце в области извлечения данных. Как обсуждалось выше, всякий раз, когда один и тот же элемент формулы многократно повторяется, вы можете удалить его из формулы и поместить в отдельную ячейку, так что он будет вычисляться только один раз (столбец L). В этом случае функция АГРЕГАТ (или НАИМЕНЬШИЙ) возвращает одну и ту же относительную позицию для всего ряда.

Рис. 15.55. Наиболее сложный и повторяющийся элемент формулы, вычисляющий относительную позицию удаляется из формулы и помещается во вспомогательный столбец; это ускоряет работу формулы; формула в ячейке L10 приведена в строке формул
Динамический диапазон внутри формулы массива для извлечения записей
Иногда при извлечении данных требуется, чтобы формула искала в новых записях, которые вносятся в таблицу позже. Для этих целей подойдет задание имени диапазона, и определение его на основе формулы динамического диапазона (подробнее см. Глава 13. Динамические диапазоны на основе функций ИНДЕКС и СМЕЩ). Рис. 15.56 показывает два динамических диапазона, созданных с помощью функции ИНДЕКС и «большого числа». На рис. 15.57 при извлечении данных в формуле используются эти два имени. Всего извлечено четыре записи. При добавлении двух новых записей (А13:С14), размер динамического диапазона увеличивается, и число извлеченных записей автоматически увеличивается до шести (рис. 15.59).

Рис. 15.56. Используйте функцию ИНДЕКС и «большое число», чтобы создать два динамических диапазона

Рис. 15.57. Извлечение данных использует имена двух динамически определенных диапазонов

Рис. 15.59. При добавлении двух новых записей (А13:С14), размер динамического диапазона увеличивается, и число извлеченных записей автоматически увеличивается до шести
Сравнение методов извлечения данных
В таблице сравниваются различные методы извлечения данных, описанные в этой главе.

Некоторые ключевые понятия для формул извлечения данных
- Используйте функцию ЕСЛИ вместо ЕСЛИОШИБКА; это сократит время расчетов.
- Критерии И и ИЛИ могут быть созданы с помощью функции ЕСЛИ или Булевой алгебры.
- Используя ИЛИ критерии помните: (1) для критериев в одном столбце функции ЕЧИСЛО + ПОИСКПОЗ предпочтительнее, чем Булевы операторы, так как работают быстрее и более наглядны; (2) для критериев в нескольких столбцах, не забудьте, что их таки несколько.
- Есть два полезных способа думать о формулах извлечения данных: (1) извлекайте записи на основе набора критериев; (2) возвращайте нескольких элементов с помощью одного поиска.
[1] В 2013 г. я перевел 13 глав книги Гирвина, и остановился, так как статистика посещений показала, что тема не очень интересна читателям сайта (правда, были и положительные отзывы). Я возобновил перевод в связи любопытным вопросом в одном из комментариев.
|
0 / 0 / 0 Регистрация: 02.03.2015 Сообщений: 3 |
|
|
02.03.2015, 10:46 [ТС] |
3 |
|
задачу я конечно решил, но криво …. скопировал ячейки и вставил их в опен офис потом обратно, получил текст ощего формата, хотя бы можно работать, но все же любопытство осталось))) Добавлено через 3 минуты Кликните здесь для просмотра всего текста
21,00 USD Добавлено через 2 минуты Кликните здесь для просмотра всего текста
21,00 USD Добавлено через 1 минуту
0 |
Russian (Pусский) translation by Alexey Malyutin (you can also view the original English article)
Когда вам нужно найти и извлечь столбец данных из одной таблицы и поместить ее в другую, используйте функцию VLOOKUP. Эта функция работает в любой версии Excel под Windows и на Mac, а также в Google Sheets. Она позволит вам найти данные в одной таблице используя некоторый идентификатор в ней, общий с другой таблицей. Обе таблицы могут находиться на разных листах или даже в в разных книгах. Есть также функция HLOOKUP, которая делает то же самое, но с данными, расположенными горизонтально, по строкам.
Функции MATCH и INDEX полезны, когда вас интересует местоположение конкретных данных, таких как столбец или строка, которая содержит имя человека.
Лучшие варианты
Перед тем, как мы погрузимся в функции Excel, вы в курсе, что Envato Market содержит массу скриптов и плагинов Excel, которые позволят вам выполнять продвинутые функции?
Например, вы можете:
- экспортировать данные WordPress в Excel
- синтаксически анализировать и извлекать данные из Excel с помощью PHP класса
- конвертировать таблицу Excel в соответствующую HTML таблицу
- конвертировать файлы Excel в объект .NET DataTable
- и многое другое


Скринкаст
Если вы хотите следовать инструкциям этого руководства, используя свой файл Excel, вы можете это сделать. Или, если хотите, скачайте zip файл, прилагаемый к этому руководству, который содержит электронную таблицу с примером, она называется vlookup example.xlsx.
Использование VLOOKUP
Когда VLOOKUP находит идентификатор, который вы задали в исходных данных, она может найти любую ячейку в этой строке и вернуть вам эту информацию. Имейте в виду, что в исходных данных идентификатор должен находиться в первом столбце таблицы.
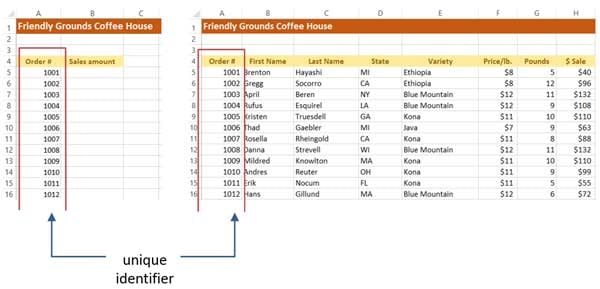

Синтаксис
Синтаксис функции VLOOKUP:
=VLOOKUP(искомое значение, диапазон таблицы, номер столбца, [true/false])
Вот что означают эти аргументы:
- Искомое значение. Ячейка, в которой находится уникальный идентификатор.
- Диапазон таблицы. Диапазон ячеек, которые содержат идентификатор в первом столбце, а в последующих столбцах располагаются остальные данные.
- Номер столбца. Номер столбца, в котором находятся данные, которые вам нужны. Не путайте его с буквой столбца. На рисунке выше, штаты находятся в столбце 4.
- True/False. Этот аргумент необязателен. True означает, что приемлемо приблизительное совпадение, а False означает, что допустимо только точное совпадение.
Мы хотим найти количество продаж из таблицы на рисунке ниже, поэтому используем такие аргументы:


Определение имени диапазона для создания абсолютной ссылки
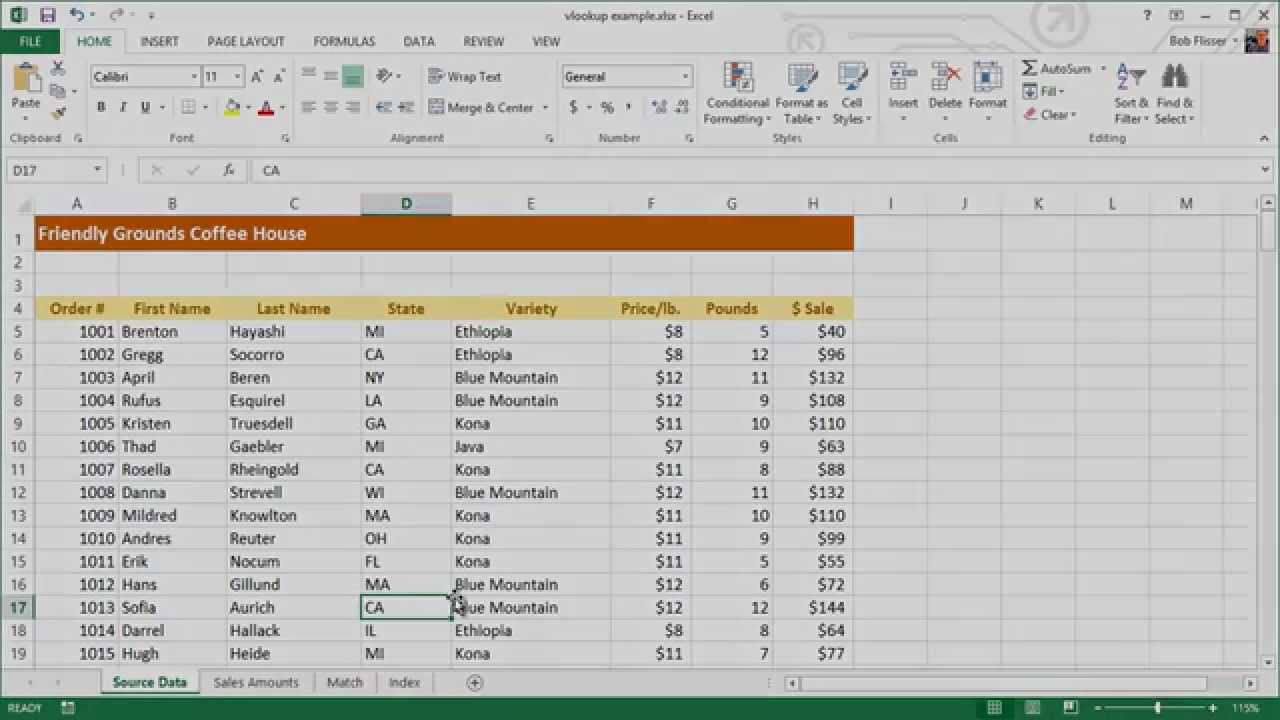
В Vlookup example.xlsx посмотрите на лист Sales Amounts. Мы введем формула в ячейку B5, затем используем возможность автозаполнения, чтобы скопировать формула в ячейки ниже нее. Это значит, что диапазон ячеек в формуле должен быть абсолютной ссылкой. Хороший способ сделать это — это задать имя для диапазона ячеек.
Задание имени диапазона в Excel
- Перед тем, как вводить формулу, перейдите на лист source data.
- Выделите ячейки от A4 (заголовок для столбца Order #) до H203. Быстрый способ это сделать — это кликнуть по A4, затем нажать Ctrl-Shift-End (Command-Shift-End на Маке).
- Кликните внутри поля Name Box (Имя) над столбцом A (сейчас в поле Name Box отображается A4).
- Напечатайте data, затем нажмите Enter.
- Теперь вы можете использовать в формуле имя data вместо $A$4:$H$203.


Задание имени диапазона в Google Sheets.
В Google Sheets имя задается немного по другому.
- Кликните по заголовку первого столбца ваших исходных данных, затем нажмите Ctrl-Shift-Стрелка вправо (Command-Shift-Стрелка вправо на Маках). Затем выберите строку заголовков столбцов.
- Нажмите Ctrl-Shift-Стрелка вниз (Command-Shift-Стрелка вниз на Маке). Затем выберите актуальные данные.
- Кликните в меню Data (Данные), затем выберите Named and protected ranges (Именованные и защищенные диапазоны).
- В поле Name and protected ranges box справа напечатайте data, затем кликните Done.


Ввод формулы
Чтобы ввести формулу, перейдите на лист Sales Amounts и кликните по ячейке B5.
Введите формулу:
=VLOOKUP(A5,data,8,FALSE)
Нажмите Enter.


Результат должен быть равен 40. Чтобы заполнить значения ниже по столбцу, снова кликните на B5, если необходимо. Поместите курсор мыши на точку автозаполнения в правом нижнем углу ячейки, так, чтобы курсор изменил свою форму на перекрестие.


Кликните дважды, чтобы заполнить значения ниже по столбцу.


Если хотите, вы можете запустить функцию VLOOKUP в следующих нескольких столбцах, чтобы извлечь другие поля, такие как фамилия или штат.
Использование MATCH
Функция MATCH не возвращает вам значение из данных; вы задаете значение, которое вы ищете и функция возвращает позицию этого значения. Это как спросить, где находится Мейн стрит, 135, и получить ответ, что это четвертое здание вниз по улице.
Синтаксис
Синтаксис функции MATCH:
=MATCH(искомое значение, диапазон таблицы, [тип совпадения])
Аргументы:
- Искомое значение. Ячейка, содержащая уникальный идентификатор.
- Диапазон таблицы. Диапазон ячеек, в котором мы ищем.
- Тип совпадения. Необязательный. Определяет, насколько точным должно быть совпадение, согласно:
|
Следующее большее значение |
-1 |
Значения должны располагаться в убывающем порядке. |
|
Целевое значение |
0 |
Значения могут идти в любом порядке. |
|
Следующее меньшее значение |
1 |
Тип по умолчанию. Значения должны располагаться в возрастающем порядке. |
Как и в случае с функцией VLOOKUP, возможно, вы найдете использование функции MATCH более простым, если назначите имя диапазону. Перейдите на лист Source Data, выделите диапазон от B4 (заголовок столбца c номером заказа) до низа, кликните в поле Name box (Имя), расположенное над столбцом A, и назовите его order_number. Обратите внимание, что значения расположены в возрастающем порядке.
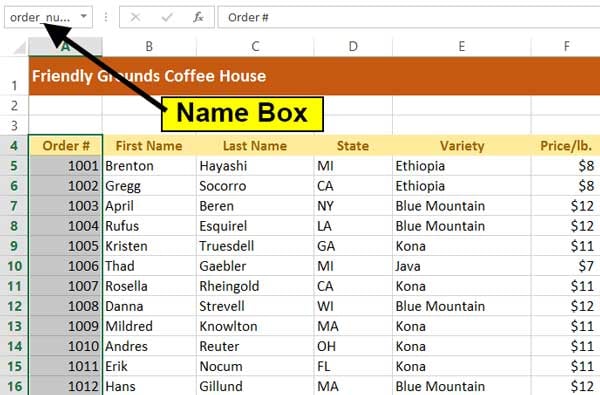

Перейдите на вкладку Match листа. В ячейку B5 введите функцию MATCH:
=MATCH(A5,order_number,1)


Если вы не задавали имя диапазону, вам надо написать функцию так:
=MATCH(A5,'Source Data'!A5:A203,0)
В любом случае вы увидите, что значение находится в 14й позиции (что делает его 13м по порядку).


Использование INDEX
Функция INDEX противоположна функции MATCH и похожа на VLOOKUP. Вы сообщаете функции, какая строка и столбец данных вам нужны, и она сообщает вам значение, которое находится в ячейке.
Синтаксис
Синтаксис функции INDEX следующий:
=INDEX(диапазон данных, номер строки, [номер столбца])
Аргументы:
- Диапазон данных. Как и в остальных двух функциях, это таблица с данными.
- Номер строки. Номер строки с данными, которая необязательно является строкой листа. Если диапазон начинается на 10-й строке листа, тогда это строка №1.
- Номер столбца. Номер столбца диапазона данных. Если диапазон начинается в столбце E, тогда номер столбца — 1.
Документация Excel говорит нам, что номер столбца это необязательный аргумент, но номер строки тоже является своего рода необязательным. Если диапазон таблицы состоит только из одной строки или одного столбца, вам не нужно использовать другой аргумент.
Перейдите на лист Index и кликните на ячейке C6. Сначала мы хотим найти, что содержится в строке 9, столбце 3 таблицы. В формуле мы используем имя диапазона, которое мы создали ранее.
Введите формулу:
=INDEX(data,A6,B6)


Она возвращает фамилию покупателя: Strevell. Изменяйте значения в ячейках A6 и B6, и ячейка C6 будет показывать разные результаты (обратите внимание, что многие строки содержат одинаковые штаты и названия продуктов).
Заключение
Способность рабочего листа заглядывать в другой рабочий лист и извлекать оттуда данные — это отличный инструмент. Таким образом, у вас может быть один лист, который содержит все данные, необходимые вам для различных целей, и вы можете извлекать оттуда то, что вам нужно для конкретных случаев.

Этот макрос предназначен для сбора (загрузки) информации из файлов Excel, расположенных в одной папке.
Для работы этого макроса, помимо него самого, вам понадобится добавить в свой файл:
- функцию FilenamesCollection для получения списка файлов в папке
- функцию GetFolder для вывода диалогового окна выбора папки с запоминанием выбранной папки
- прогресс-бар для отображения процесса обработки файлов (модуль класса и форму)
Если при тестировании макроса у вас возникает ошибка, что не найдена та или иная функция,
— проверьте, все ли необходимые компоненты (которые перечислены выше) вы добавили в свой файл.
Этот макрос я публикую прежде всего для себя (поскольку использую этот код чуть ли ни в каждой третьей своей программе),
поэтому я не буду помогать вам в настройке этого макроса, если у вас он вдруг не заработает.
Макрос при запуске выдает диалоговое окно для выбора папки, в которой расположены обрабатываемые файлы,
после чего открывает каждый из файлов, считывает из него данные, помещает их в текущую книгу (из которой запущен макрос),
и закрывает обработанный файл без сохранения изменений.
После того, как очередной файл обработан, он перемещается во вторую папку («архив»).
Код макроса:
Sub ИмпортДанныхИзЗаявок() On Error Resume Next: Err.Clear ' запрашиваем пути к папкам с файлами InvoiceFolder$ = GetFolder(1, , "Выберите папку с файлами заявок (из Outlook)") If InvoiceFolder$ = "" Then MsgBox "Не задана папка с заявками", vbCritical, "Обработка заявок невозможна": Exit Sub ArchieveFolder$ = GetFolder(2, , "Выберите папку, куда будут помещаться обработанные файлы заявок") If ArchieveFolder$ = "" Then MsgBox "Не задана папка для архива заявок", vbCritical, "Обработка заявок невозможна": Exit Sub Dim coll As Collection ' загружаем список файлов по маске имени файла Set coll = FilenamesCollection(InvoiceFolder$, "Заявка №*от*.xls*", 1) If coll.Count = 0 Then MsgBox "Не найдено ни одной заявки для обработки в папке" & vbNewLine & InvoiceFolder$, _ vbExclamation, "Нет необработанных заявок" Exit Sub End If Dim pi As New ProgressIndicator: pi.Show "Обработка заявок", , 2 pi.StartNewAction , , , , , coll.Count ' отображаем прогресс-бар Dim WB As Workbook, sh As Worksheet, ra As Range Application.ScreenUpdating = False ' отключаем обновление экрана (чтобы процесс открытия файлов не был виден) ' перебираем все найденные в папке файлы For Each Filename In coll ' обновляем информацию на прогресс-баре pi.SubAction "Обрабатывается заявка $index из $count", "Файл заявки: " & Dir(Filename), "$time" pi.Log "Файл: " & Dir(Filename) ' открываем очередной файл в режиме «только чтение» Set WB = Nothing: Set WB = Workbooks.Open(Filename, False, True) If WB Is Nothing Then ' не удалось открыть файл pi.Log vbTab & "ОШИБКА при загрузке файла. Файл не обработан." Else ' файл успешно открыт Set sh = WB.Worksheets(1) ' будем брать данные с первого листа ' берем диапазон ячеек с ячейки B1 до последней заполненной в столбце B Set ra = sh.Range(sh.Range("b1"), sh.Range("b" & sh.Rows.Count).End(xlUp)) ' ==== переносим данные в наш файл (shb - кодовое имя листа, куда помещаем данные) shb.Range("a" & shb.Rows.Count).End(xlUp).Offset(1).Resize(, ra.Rows.Count).Value = _ Application.WorksheetFunction.Transpose(ra.Value) ' ==== конец обработки данных из очередного файла WB.Close False: DoEvents ' закрываем обработанный файл без сохранения изменений pi.Log vbTab & "Файл успешно обработан." ' перемещаем обработанный файл из папки InvoiceFolder$ в папку ArchieveFolder$ Name Filename As ArchieveFolder$ & Dir(Filename, vbNormal) End If Next ' закрываем прогресс-бар, включаем обновление экрана pi.Hide: DoEvents: Application.ScreenUpdating = True MsgBox "Обработка заявок завершена", vbInformation End Sub
Во вложении — файл со всеми необходимыми макросами для сбора данных из других файлов Excel
Парсинг нетабличных данных с сайтов
Проблема с нетабличными данными
С загрузкой в Excel табличных данных из интернета проблем нет. Надстройка Power Query в Excel легко позволяет реализовать эту задачу буквально за секунды. Достаточно выбрать на вкладке Данные команду Из интернета (Data — From internet), вставить адрес нужной веб-страницы (например, ключевых показателей ЦБ) и нажать ОК:

Power Query автоматически распознает все имеющиеся на веб-странице таблицы и выведет их список в окне Навигатора:

Дальше останется выбрать нужную таблицу методом тыка и загрузить её в Power Query для дальнейшей обработки (кнопка Преобразовать данные) или сразу на лист Excel (кнопка Загрузить).
Если с нужного вам сайта данные грузятся по вышеописанному сценарию — считайте, что вам повезло.
К сожалению, сплошь и рядом встречаются сайты, где при попытке такой загрузки Power Query «не видит» таблиц с нужными данными, т.е. в окне Навигатора попросту нет этих Table 0,1,2… или же среди них нет таблицы с нужной нам информацией. Причин для этого может быть несколько, но чаще всего это происходит потому, что веб-дизайнер при создании таблицы использовал в HTML-коде страницы не стандартную конструкцию с тегом <TABLE>, а её аналог — вложенные друг в друга теги-контейнеры <DIV>. Это весьма распространённая техника при вёрстке веб-сайтов, но, к сожалению, Power Query пока не умеет распознавать такую разметку и загружать такие данные в Excel.
Тем не менее, есть способ обойти это ограничение 
В качестве тренировки, давайте попробуем загрузить цены и описания товаров с маркетплейса Wildberries — например, книг из раздела Детективы:

Загружаем HTML-код вместо веб-страницы
Сначала используем всё тот же подход — выбираем команду Из интернета на вкладке Данные (Data — From internet) и вводим адрес нужной нам страницы:
https://www.wildberries.ru/catalog/knigi/hudozhestvennaya-literatura/detektivy
После нажатия на ОК появится окно Навигатора, где мы уже не увидим никаких полезных таблиц, кроме непонятной Document:

Дальше начинается самое интересное. Жмём на кнопку Преобразовать данные (Transform Data), чтобы всё-таки загрузить содержимое таблицы Document в редактор запросов Power Query. В открывшемся окне удаляем шаг Навигация (Navigation) красным крестом:

… и затем щёлкаем по значку шестерёнки справа от шага Источник (Source), чтобы открыть его параметры:

В выпадающием списке Открыть файл как (Open file as) вместо выбранной там по-умолчанию HTML-страницы выбираем Текстовый файл (Text file). Это заставит Power Query интерпретировать загружаемые данные не как веб-страницу, а как простой текст, т.е. Power Query не будет пытаться распознавать HTML-теги и их атрибуты, ссылки, картинки, таблицы, а просто обработает исходный код страницы как текст.
После нажатия на ОК мы этот HTML-код как раз и увидим (он может быть весьма объемным — не пугайтесь):

Ищем за что зацепиться
Теперь нужно понять на какие теги, атрибуты или метки в коде мы можем ориентироваться, чтобы извлечь из этой кучи текста нужные нам данные о товарах. Само-собой, тут всё зависит от конкретного сайта и веб-программиста, который его писал и вам придётся уже импровизировать.
В случае с Wildberries, промотав этот код вниз до товаров, можно легко нащупать простую логику:

- Строчки с ценами всегда содержат метку lower-price
- Строчки с названием бренда — всегда с меткой brand-name c-text-sm
- Название товара можно найти по метке goods-name c-text-sm
Иногда процесс поиска можно существенно упростить, если воспользоваться инструментами отладки кода, которые сейчас есть в любом современном браузере. Щёлкнув правой кнопкой мыши по любому элементу веб-страницы (например, цене или описанию товара) можно выбрать из контекстного меню команду Инспектировать (Inspect) и затем просматривать код в удобном окошке непосредственно рядом с содержимым сайта:

Фильтруем нужные данные
Теперь совершенно стандартным образом давайте отфильтруем в коде страницы нужные нам строки по обнаруженным меткам. Для этого выбираем в окне Power Query в фильтре [1] опцию Текстовые фильтры — Содержит (Text filters — Contains), переключаемся в режим Подробнее (Advanced) [2] и вводим наши критерии:

Добавление условий выполняется кнопкой со смешным названием Добавить предложение [3]. И не забудьте для всех условий выставить логическую связку Или (OR) вместо И (And) в выпадающих списках слева [4] — иначе фильтрация просто не сработает.
После нажатия на ОК на экране останутся только строки с нужной нам информацией:

Чистим мусор
Останется почистить всё это от мусора любым подходящим и удобным лично вам способом (их много). Например, так:
- Удалить заменой на пустоту начальный тег: <span class=»price»> через команду Главная — Замена значений (Home — Replace values).
- Разделить получившийся столбец по первому разделителю «>» слева командой Главная — Разделить столбец — По разделителю (Home — Split column — By delimiter) и затем ещё раз разделить получившийся столбец по первому вхождению разделителя «<» слева, чтобы отделить полезные данные от тегов:

- Удалить лишние столбцы, а в оставшемся заменить стандартную HTML-конструкцию " на нормальные кавычки.

В итоге получим наши данные в уже гораздо более презентабельном виде:

Разбираем блоки по столбцам
Если присмотреться, то информация о каждом отдельном товаре в получившемся списке сгруппирована в блоки по три ячейки. Само-собой, нам было бы гораздо удобнее работать с этой таблицей, если бы эти блоки превратились в отдельные столбцы: цена, бренд (издательство) и наименование.
Выполнить такое преобразование можно очень легко — с помощью, буквально, одной строчки кода на встроенном в Power Query языке М. Для этого щёлкаем по кнопке fx в строке формул (если у вас её не видно, то включите её на вкладке Просмотр (View)) и вводим следующую конструкцию:
= Table.FromRows(List.Split(#»Замененное значение1″[Column1.2.1],3))
Здесь функция List.Split разбивает столбец с именем Column1.2.1 из нашей таблицы с предыдущего шага #»Замененное значение1″ на кусочки по 3 ячейки, а потом функция Table.FromRows конвертирует получившиеся вложенные списки обратно в таблицу — уже из трёх столбцов:

Ну, а дальше уже дело техники — настроить числовые форматы столбцов, переименовать их и разместить в нужном порядке. И выгрузить получившуюся красоту обратно на лист Excel командой Главная — Закрыть и загрузить (Home — Close & Load…)

Вот и все хитрости 
Ссылки по теме
- Импорт курса биткойна с сайта через Power Query
- Парсинг текста регулярными выражениями (RegExp) в Power Query
- Параметризация путей к данным в Power Query