
Рассмотрим инструмент Описательная статистика, входящий в надстройку Пакет Анализа. Рассчитаем показатели выборки: среднее, медиана, мода, дисперсия, стандартное отклонение и др.
Задача
описательной статистики
(descriptive statistics) заключается в том, чтобы с использованием математических инструментов свести сотни значений
выборки
к нескольким итоговым показателям, которые дают представление о
выборке
.В качестве таких статистических показателей используются:
среднее
,
медиана
,
мода
,
дисперсия, стандартное отклонение
и др.
Опишем набор числовых данных с помощью определенных показателей. Для чего нужны эти показатели? Эти показатели позволят сделать определенные
статистические выводы о распределении
, из которого была взята
выборка
. Например, если у нас есть
выборка
значений толщины трубы, которая изготавливается на определенном оборудовании, то на основании анализа этой
выборки
мы сможем сделать, с некой определенной вероятностью, заключение о состоянии процесса изготовления.
Содержание статьи:
- Надстройка Пакет анализа;
-
Среднее выборки
;
-
Медиана выборки
;
-
Мода выборки
;
-
Мода и среднее значение
;
-
Дисперсия выборки
;
-
Стандартное отклонение выборки
;
-
Стандартная ошибка
;
-
Ассиметричность
;
-
Эксцесс выборки
;
-
Уровень надежности
.
Надстройка Пакет анализа
Для вычисления статистических показателей одномерных
выборок
, используем
надстройку Пакет анализа
. Затем, все показатели рассчитанные надстройкой, вычислим с помощью встроенных функций MS EXCEL.
СОВЕТ
: Подробнее о других инструментах надстройки
Пакет анализа
и ее подключении – читайте в статье
Надстройка Пакет анализа MS EXCEL
.
Выборку
разместим на
листе
Пример
в файле примера
в диапазоне
А6:А55
(50 значений).
Примечание
: Для удобства написания формул для диапазона
А6:А55
создан
Именованный диапазон
Выборка.
В диалоговом окне
Анализ данных
выберите инструмент
Описательная статистика
.

После нажатия кнопки
ОК
будет выведено другое диалоговое окно,
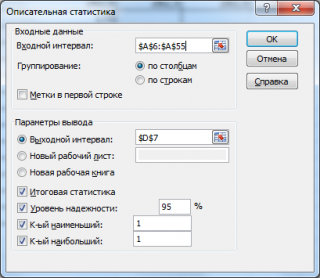
в котором нужно указать:
входной интервал
(Input Range) – это диапазон ячеек, в котором содержится массив данных. Если в указанный диапазон входит текстовый заголовок набора данных, то нужно поставить галочку в поле
Метки в первой строке (
Labels
in
first
row
).
В этом случае заголовок будет выведен в
Выходном интервале.
Пустые ячейки будут проигнорированы, поэтому нулевые значения необходимо обязательно указывать в ячейках, а не оставлять их пустыми;
выходной интервал
(Output Range). Здесь укажите адрес верхней левой ячейки диапазона, в который будут выведены статистические показатели;
Итоговая статистика (
Summary
Statistics
)
. Поставьте галочку напротив этого поля – будут выведены основные показатели выборки:
среднее, медиана, мода, стандартное отклонение
и др.;-
Также можно поставить галочки напротив полей
Уровень надежности (
Confidence
Level
for
Mean
)
,
К-й наименьший
(Kth Largest) и
К-й наибольший
(Kth Smallest).
В результате будут выведены следующие статистические показатели:
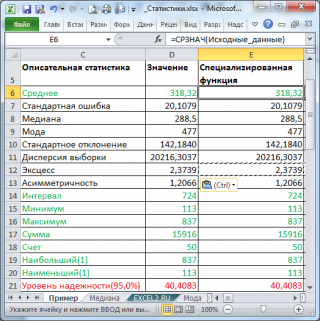
Все показатели выведены в виде значений, а не формул. Если массив данных изменился, то необходимо перезапустить расчет.
Если во
входном интервале
указать ссылку на несколько столбцов данных, то будет рассчитано соответствующее количество наборов показателей. Такой подход позволяет сравнить несколько наборов данных. При сравнении нескольких наборов данных используйте заголовки (включите их во
Входной интервал
и установите галочку в поле
Метки в первой строке
). Если наборы данных разной длины, то это не проблема — пустые ячейки будут проигнорированы.
Зеленым цветом на картинке выше и в
файле примера
выделены показатели, которые не требуют особого пояснения. Для большинства из них имеется специализированная функция:
Интервал
(Range) — разница между максимальным и минимальным значениями;
Минимум
(Minimum) – минимальное значение в диапазоне ячеек, указанном во
Входном интервале
(см.статью про функцию
МИН()
);
Максимум
(Maximum)– максимальное значение (см.статью про функцию
МАКС()
);
Сумма
(Sum) – сумма всех значений (см.статью про функцию
СУММ()
);
Счет
(Count) – количество значений во
Входном интервале
(пустые ячейки игнорируются, см.статью про функцию
СЧЁТ()
);
Наибольший
(Kth Largest) – выводится К-й наибольший. Например, 1-й наибольший – это максимальное значение (см.статью про функцию
НАИБОЛЬШИЙ()
);
Наименьший
(Kth Smallest) – выводится К-й наименьший. Например, 1-й наименьший – это минимальное значение (см.статью про функцию
НАИМЕНЬШИЙ()
).
Ниже даны подробные описания остальных показателей.
Среднее выборки
Среднее
(mean, average) или
выборочное среднее
или
среднее выборки
(sample average) представляет собой
арифметическое среднее
всех значений массива. В MS EXCEL для вычисления среднего выборки используется функция
СРЗНАЧ()
.
Выборочное среднее
является «хорошей» (несмещенной и эффективной) оценкой
математического ожидания
случайной величины (подробнее см. статью
Среднее и Математическое ожидание в MS EXCEL
).
Медиана выборки
Медиана
(Median) – это число, которое является серединой множества чисел (в данном случае выборки): половина чисел множества больше, чем
медиана
, а половина чисел меньше, чем
медиана
. Для определения
медианы
необходимо сначала
отсортировать множество чисел
. Например,
медианой
для чисел 2, 3, 3,
4
, 5, 7, 10 будет 4.
Если множество содержит четное количество чисел, то вычисляется
среднее
для двух чисел, находящихся в середине множества. Например,
медианой
для чисел 2, 3,
3
,
5
, 7, 10 будет 4, т.к. (3+5)/2.
Если имеется длинный хвост распределения, то
Медиана
лучше, чем
среднее значение
, отражает «типичное» или «центральное» значение. Например, рассмотрим несправедливое распределение зарплат в компании, в которой руководство получает существенно больше, чем основная масса сотрудников.
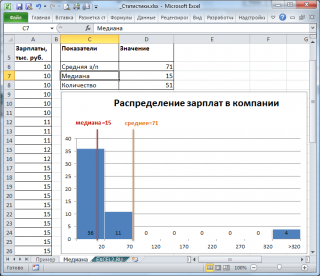
Очевидно, что средняя зарплата (71 тыс. руб.) не отражает тот факт, что 86% сотрудников получает не более 30 тыс. руб. (т.е. 86% сотрудников получает зарплату в более, чем в 2 раза меньше средней!). В то же время медиана (15 тыс. руб.) показывает, что
как минимум
у 50% сотрудников зарплата меньше или равна 15 тыс. руб.
Для определения
медианы
в MS EXCEL существует одноименная функция
МЕДИАНА()
, английский вариант — MEDIAN().
Медиану
также можно вычислить с помощью формул
=КВАРТИЛЬ.ВКЛ(Выборка;2) =ПРОЦЕНТИЛЬ.ВКЛ(Выборка;0,5).
Подробнее о
медиане
см. специальную статью
Медиана в MS EXCEL
.
СОВЕТ
: Подробнее про
квартили
см. статью, про
перцентили (процентили)
см. статью.
Мода выборки
Мода
(Mode) – это наиболее часто встречающееся (повторяющееся) значение в
выборке
. Например, в массиве (1; 1;
2
;
2
;
2
; 3; 4; 5) число 2 встречается чаще всего – 3 раза. Значит, число 2 – это
мода
. Для вычисления
моды
используется функция
МОДА()
, английский вариант MODE().
Примечание
: Если в массиве нет повторяющихся значений, то функция вернет значение ошибки #Н/Д. Это свойство использовано в статье
Есть ли повторы в списке?
Начиная с
MS EXCEL 2010
вместо функции
МОДА()
рекомендуется использовать функцию
МОДА.ОДН()
, которая является ее полным аналогом. Кроме того, в MS EXCEL 2010 появилась новая функция
МОДА.НСК()
, которая возвращает несколько наиболее часто повторяющихся значений (если количество их повторов совпадает). НСК – это сокращение от слова НеСКолько.
Например, в массиве (1; 1;
2
;
2
;
2
; 3;
4
;
4
;
4
; 5) числа 2 и 4 встречаются наиболее часто – по 3 раза. Значит, оба числа являются
модами
. Функции
МОДА.ОДН()
и
МОДА()
вернут значение 2, т.к. 2 встречается первым, среди наиболее повторяющихся значений (см.
файл примера
, лист
Мода
).
Чтобы исправить эту несправедливость и была введена функция
МОДА.НСК()
, которая выводит все
моды
. Для этого ее нужно ввести как
формулу массива
.
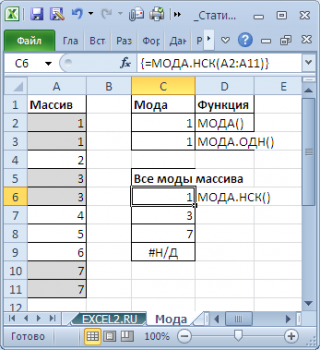
Как видно из картинки выше, функция
МОДА.НСК()
вернула все три
моды
из массива чисел в диапазоне
A2:A11
: 1; 3 и 7. Для этого, выделите диапазон
C6:C9
, в
Строку формул
введите формулу
=МОДА.НСК(A2:A11)
и нажмите
CTRL+SHIFT+ENTER
. Диапазон
C
6:
C
9
охватывает 4 ячейки, т.е. количество выделяемых ячеек должно быть больше или равно количеству
мод
. Если ячеек больше чем м
о
д, то избыточные ячейки будут заполнены значениями ошибки #Н/Д. Если
мода
только одна, то все выделенные ячейки будут заполнены значением этой
моды
.
Теперь вспомним, что мы определили
моду
для выборки, т.е. для конечного множества значений, взятых из
генеральной совокупности
. Для
непрерывных случайных величин
вполне может оказаться, что выборка состоит из массива на подобие этого (0,935; 1,211; 2,430; 3,668; 3,874; …), в котором может не оказаться повторов и функция
МОДА()
вернет ошибку.
Даже в нашем массиве с
модой
, которая была определена с помощью
надстройки Пакет анализа
, творится, что-то не то. Действительно,
модой
нашего массива значений является число 477, т.к. оно встречается 2 раза, остальные значения не повторяются. Но, если мы посмотрим на
гистограмму распределения
, построенную для нашего массива, то увидим, что 477 не принадлежит интервалу наиболее часто встречающихся значений (от 150 до 250).
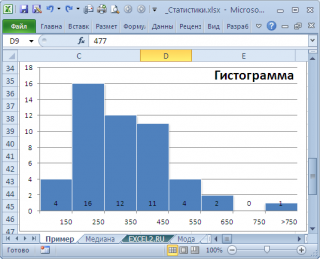
Проблема в том, что мы определили
моду
как наиболее часто встречающееся значение, а не как наиболее вероятное. Поэтому,
моду
в учебниках статистики часто определяют не для выборки (массива), а для функции распределения. Например, для
логнормального распределения
мода
(наиболее вероятное значение непрерывной случайной величины х), вычисляется как
exp
(
m
—
s
2
)
, где m и s параметры этого распределения.
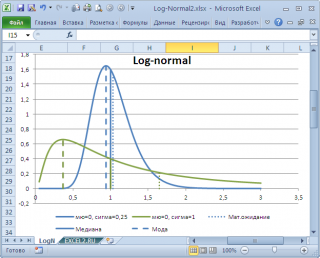
Понятно, что для нашего массива число 477, хотя и является наиболее часто повторяющимся значением, но все же является плохой оценкой для
моды
распределения, из которого взята
выборка
(наиболее вероятного значения или для которого плотность вероятности распределения максимальна).
Для того, чтобы получить оценку
моды
распределения, из
генеральной совокупности
которого взята
выборка
, можно, например, построить
гистограмму
. Оценкой для
моды
может служить интервал наиболее часто встречающихся значений (самого высокого столбца). Как было сказано выше, в нашем случае это интервал от 150 до 250.
Вывод
: Значение
моды
для
выборки
, рассчитанное с помощью функции
МОДА()
, может ввести в заблуждение, особенно для небольших выборок. Эта функция эффективна, когда случайная величина может принимать лишь несколько дискретных значений, а размер
выборки
существенно превышает количество этих значений.
Например, в рассмотренном примере о распределении заработных плат (см. раздел статьи выше, о Медиане),
модой
является число 15 (17 значений из 51, т.е. 33%). В этом случае функция
МОДА()
дает хорошую оценку «наиболее вероятного» значения зарплаты.
Примечание
: Строго говоря, в примере с зарплатой мы имеем дело скорее с
генеральной совокупностью
, чем с
выборкой
. Т.к. других зарплат в компании просто нет.
О вычислении
моды
для распределения
непрерывной случайной величины
читайте статью
Мода в MS EXCEL
.
Мода и среднее значение
Не смотря на то, что
мода
– это наиболее вероятное значение случайной величины (вероятность выбрать это значение из
Генеральной совокупности
максимальна), не следует ожидать, что
среднее значение
обязательно будет близко к
моде
.
Примечание
:
Мода
и
среднее
симметричных распределений совпадает (имеется ввиду симметричность
плотности распределения
).
Представим, что мы бросаем некий «неправильный» кубик, у которого на гранях имеются значения (1; 2; 3; 4; 6; 6), т.е. значения 5 нет, а есть вторая 6.
Модой
является 6, а среднее значение – 3,6666.
Другой пример. Для
Логнормального распределения
LnN(0;1)
мода
равна =EXP(m-s2)= EXP(0-1*1)=0,368, а
среднее значение
1,649.
Дисперсия выборки
Дисперсия выборки
или
выборочная дисперсия (
sample
variance
) характеризует разброс значений в массиве, отклонение от
среднего
.
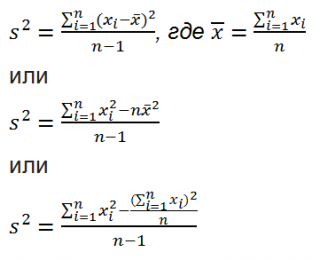
Из формулы №1 видно, что
дисперсия выборки
это сумма квадратов отклонений каждого значения в массиве
от среднего
, деленная на размер выборки минус 1.
В MS EXCEL 2007 и более ранних версиях для вычисления
дисперсии выборки
используется функция
ДИСП()
. С версии MS EXCEL 2010 рекомендуется использовать ее аналог — функцию
ДИСП.В()
.
Дисперсию
можно также вычислить непосредственно по нижеуказанным формулам (см.
файл примера
):
=КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1) =(СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/ (СЧЁТ(Выборка)-1)
– обычная формула
=СУММ((Выборка -СРЗНАЧ(Выборка))^2)/ (СЧЁТ(Выборка)-1)
–
формула массива
Дисперсия выборки
равна 0, только в том случае, если все значения равны между собой и, соответственно, равны
среднему значению
.
Чем больше величина
дисперсии
, тем больше разброс значений в массиве относительно
среднего
.
Размерность
дисперсии
соответствует квадрату единицы измерения исходных значений. Например, если значения в выборке представляют собой измерения веса детали (в кг), то размерность
дисперсии
будет кг
2
. Это бывает сложно интерпретировать, поэтому для характеристики разброса значений чаще используют величину равную квадратному корню из
дисперсии – стандартное отклонение
.
Подробнее о
дисперсии
см. статью
Дисперсия и стандартное отклонение в MS EXCEL
.
Стандартное отклонение выборки
Стандартное отклонение выборки
(Standard Deviation), как и
дисперсия
, — это мера того, насколько широко разбросаны значения в выборке
относительно их среднего
.
По определению,
стандартное отклонение
равно квадратному корню из
дисперсии
:
![]()
Стандартное отклонение
не учитывает величину значений в
выборке
, а только степень рассеивания значений вокруг их
среднего
. Чтобы проиллюстрировать это приведем пример.
Вычислим стандартное отклонение для 2-х
выборок
: (1; 5; 9) и (1001; 1005; 1009). В обоих случаях, s=4. Очевидно, что отношение величины стандартного отклонения к значениям массива у
выборок
существенно отличается.
В MS EXCEL 2007 и более ранних версиях для вычисления
Стандартного отклонения выборки
используется функция
СТАНДОТКЛОН()
. С версии MS EXCEL 2010 рекомендуется использовать ее аналог
СТАНДОТКЛОН.В()
.
Стандартное отклонение
можно также вычислить непосредственно по нижеуказанным формулам (см.
файл примера
):
=КОРЕНЬ(КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1)) =КОРЕНЬ((СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/(СЧЁТ(Выборка)-1))
Подробнее о
стандартном отклонении
см. статью
Дисперсия и стандартное отклонение в MS EXCEL
.
Стандартная ошибка
В
Пакете анализа
под термином
стандартная ошибка
имеется ввиду
Стандартная ошибка среднего
(Standard Error of the Mean, SEM).
Стандартная ошибка среднего
— это оценка
стандартного отклонения
распределения
выборочного среднего
.
Примечание
: Чтобы разобраться с понятием
Стандартная ошибка среднего
необходимо прочитать о
выборочном распределении
(см. статью
Статистики, их выборочные распределения и точечные оценки параметров распределений в MS EXCEL
) и статью про
Центральную предельную теорему
.
Стандартное отклонение распределения выборочного среднего
вычисляется по формуле σ/√n, где n — объём
выборки, σ — стандартное отклонение исходного
распределения, из которого взята
выборка
. Т.к. обычно
стандартное отклонение
исходного распределения неизвестно, то в расчетах вместо
σ
используют ее оценку
s
—
стандартное отклонение выборки
. А соответствующая величина s/√n имеет специальное название —
Стандартная ошибка среднего.
Именно эта величина вычисляется в
Пакете анализа.
В MS EXCEL
стандартную ошибку среднего
можно также вычислить по формуле
=СТАНДОТКЛОН.В(Выборка)/ КОРЕНЬ(СЧЁТ(Выборка))
Асимметричность
Асимметричность
или
коэффициент асимметрии
(skewness) характеризует степень несимметричности распределения (
плотности распределения
) относительно его
среднего
.
Положительное значение
коэффициента асимметрии
указывает, что размер правого «хвоста» распределения больше, чем левого (относительно среднего). Отрицательная асимметрия, наоборот, указывает на то, что левый хвост распределения больше правого.
Коэффициент асимметрии
идеально симметричного распределения или выборки равно 0.

Примечание
:
Асимметрия выборки
может отличаться расчетного значения асимметрии теоретического распределения. Например,
Нормальное распределение
является симметричным распределением (
плотность его распределения
симметрична относительно
среднего
) и, поэтому имеет асимметрию равную 0. Понятно, что при этом значения в
выборке
из соответствующей
генеральной совокупности
не обязательно должны располагаться совершенно симметрично относительно
среднего
. Поэтому,
асимметрия выборки
, являющейся оценкой
асимметрии распределения
, может отличаться от 0.
Функция
СКОС()
, английский вариант SKEW(), возвращает коэффициент
асимметрии выборки
, являющейся оценкой
асимметрии
соответствующего распределения, и определяется следующим образом:
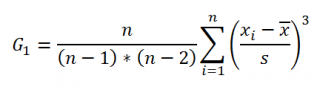
где n – размер
выборки
, s –
стандартное отклонение выборки
.
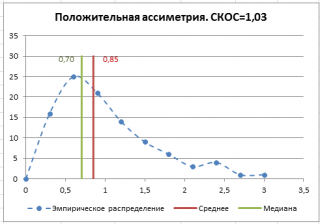
В
файле примера на листе СКОС
приведен расчет коэффициента
асимметрии
на примере случайной выборки из
распределения Вейбулла
, которое имеет значительную положительную
асимметрию
при параметрах распределения W(1,5; 1).
Эксцесс выборки
Эксцесс
показывает относительный вес «хвостов» распределения относительно его центральной части.
Для того чтобы определить, что относится к хвостам распределения, а что к его центральной части, можно использовать границы μ +/-
σ
.
Примечание
: Не смотря на старания профессиональных статистиков, в литературе еще попадается определение
Эксцесса
как меры «остроконечности» (peakedness) или сглаженности распределения. Но, на самом деле, значение
Эксцесса
ничего не говорит о форме пика распределения.
Согласно определения,
Эксцесс
равен четвертому
стандартизированному моменту:
![]()
Для
нормального распределения
четвертый момент равен 3*σ
4
, следовательно,
Эксцесс
равен 3. Многие компьютерные программы используют для расчетов не сам
Эксцесс
, а так называемый Kurtosis excess, который меньше на 3. Т.е. для
нормального распределения
Kurtosis excess равен 0. Необходимо быть внимательным, т.к. часто не очевидно, какая формула лежит в основе расчетов.
Примечание
: Еще большую путаницу вносит перевод этих терминов на русский язык. Термин Kurtosis происходит от греческого слова «изогнутый», «имеющий арку». Так сложилось, что на русский язык оба термина Kurtosis и Kurtosis excess переводятся как
Эксцесс
(от англ. excess — «излишек»). Например, функция MS EXCEL
ЭКСЦЕСС()
на самом деле вычисляет Kurtosis excess.
Функция
ЭКСЦЕСС()
, английский вариант KURT(), вычисляет на основе значений выборки несмещенную оценку
эксцесса распределения
случайной величины и определяется следующим образом:
![]()
Как видно из формулы MS EXCEL использует именно Kurtosis excess, т.е. для выборки из
нормального распределения
формула вернет близкое к 0 значение.
Если задано менее четырех точек данных, то функция
ЭКСЦЕСС()
возвращает значение ошибки #ДЕЛ/0!
Вернемся к
распределениям случайной величины
.
Эксцесс
(Kurtosis excess) для
нормального распределения
всегда равен 0, т.е. не зависит от параметров распределения μ и σ. Для большинства других распределений
Эксцесс
зависит от параметров распределения: см., например,
распределение Вейбулла
или
распределение Пуассона
, для котрого
Эксцесс
= 1/λ.
Уровень надежности
Уровень
надежности
— означает вероятность того, что
доверительный интервал
содержит истинное значение оцениваемого параметра распределения.
Вместо термина
Уровень
надежности
часто используется термин
Уровень доверия
. Про
Уровень надежности
(Confidence Level for Mean) читайте статью
Уровень значимости и уровень надежности в MS EXCEL
.
Задав значение
Уровня
надежности
в окне
надстройки Пакет анализа
, MS EXCEL вычислит половину ширины
доверительного интервала для оценки среднего (дисперсия неизвестна)
.
Тот же результат можно получить по формуле (см.
файл примера
):
=ДОВЕРИТ.СТЬЮДЕНТ(1-0,95;s;n)
s —
стандартное отклонение выборки
, n – объем
выборки
.
Подробнее см. статью про
построение доверительного интервала для оценки среднего (дисперсия неизвестна)
.
Если вам по работе или учёбе приходится погружаться в океан цифр и искать в них подтверждение своих гипотез, вам определённо пригодятся эти техники работы в Microsoft Excel. Как их применять — показываем с помощью гифок.

Юлия Перминова
Тренер Учебного центра Softline с 2008 года.
1. Сводные таблицы
Базовый инструмент для работы с огромным количеством неструктурированных данных, из которых можно быстро сделать выводы и не возиться с фильтрацией и сортировкой вручную. Сводные таблицы можно создать с помощью нескольких действий и быстро настроить в зависимости от того, как именно вы хотите отобразить результаты.
Полезное дополнение. Вы также можете создавать сводные диаграммы на основе сводных таблиц, которые будут автоматически обновляться при их изменении. Это полезно, если вам, например, нужно регулярно создавать отчёты по одним и тем же параметрам.
Как работать
Исходные данные могут быть любыми: данные по продажам, отгрузкам, доставкам и так далее.
- Откройте файл с таблицей, данные которой надо проанализировать.
- Выделите диапазон данных для анализа.
- Перейдите на вкладку «Вставка» → «Таблица» → «Сводная таблица» (для macOS на вкладке «Данные» в группе «Анализ»).
- Должно появиться диалоговое окно «Создание сводной таблицы».
- Настройте отображение данных, которые есть у вас в таблице.
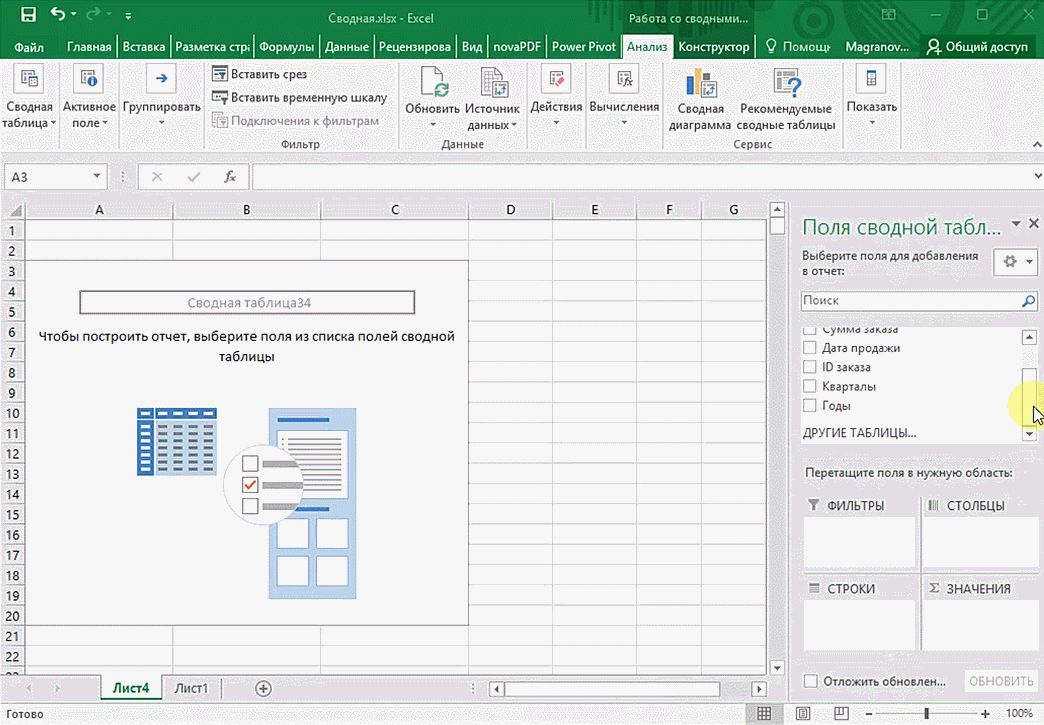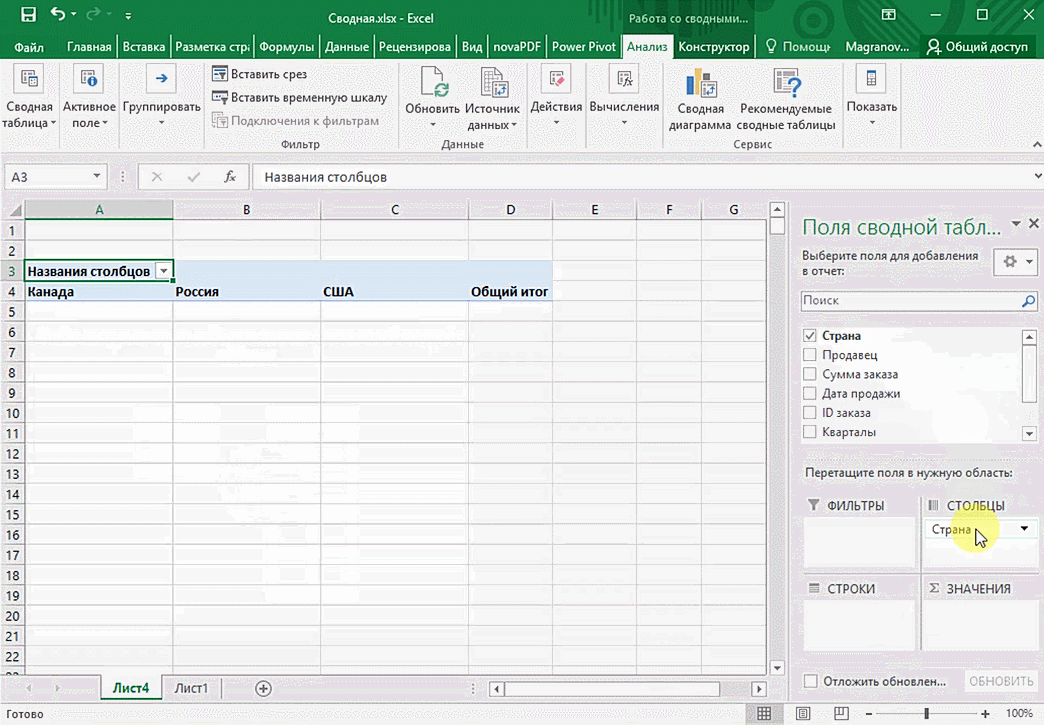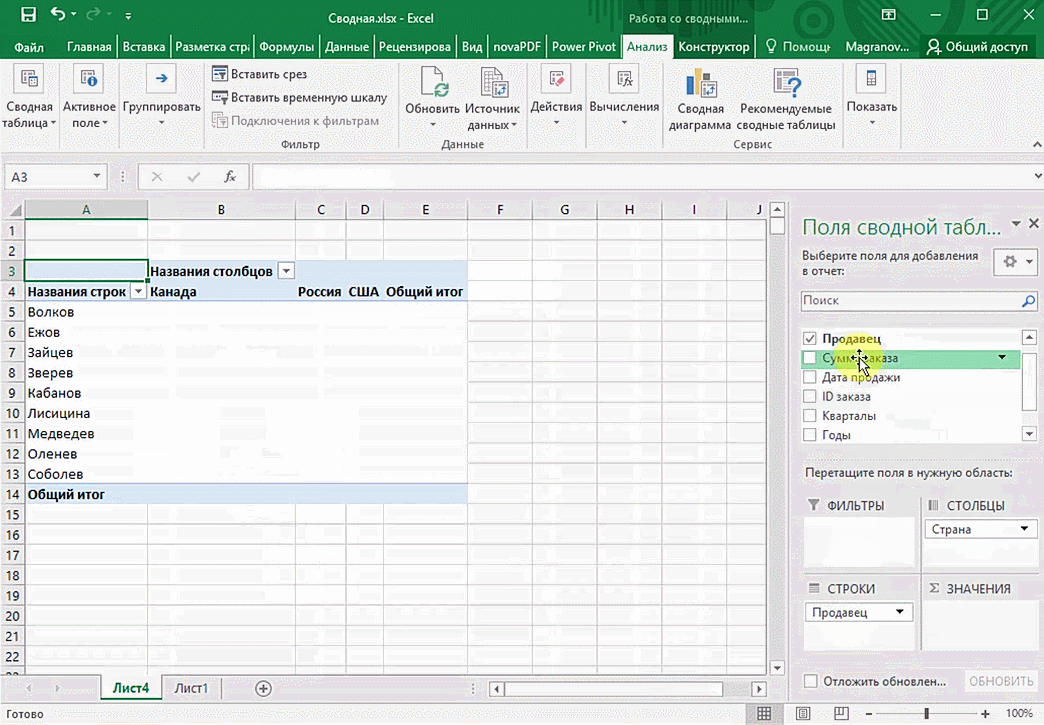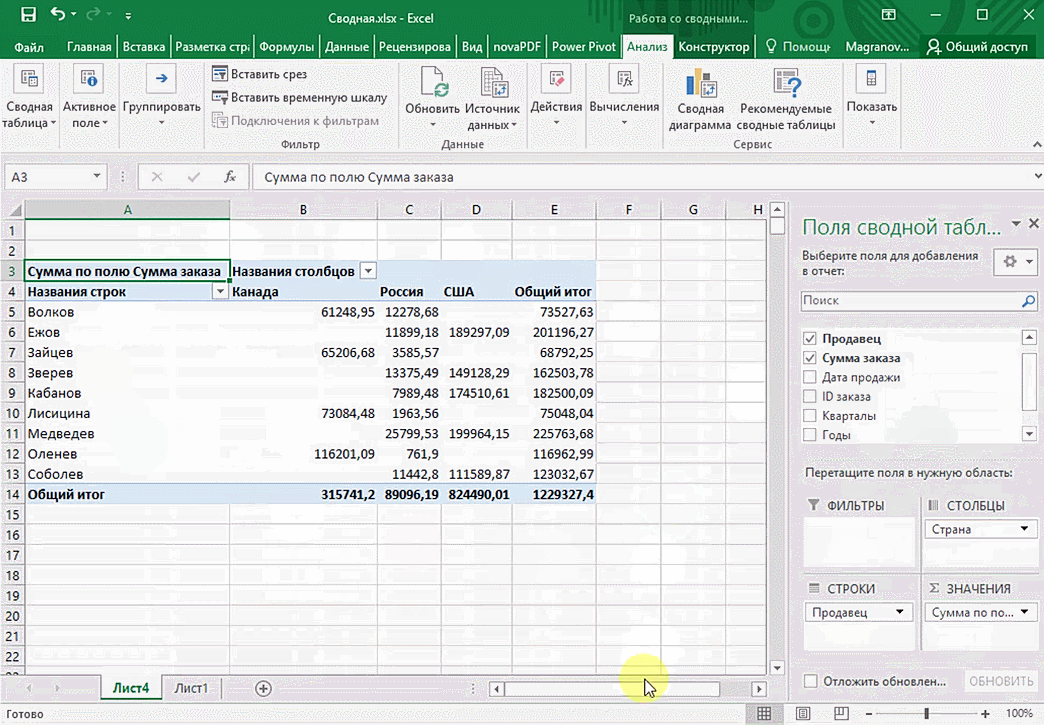
Перед нами таблица с неструктурированными данными. Мы можем их систематизировать и настроить отображение тех данных, которые есть у нас в таблице. «Сумму заказов» отправляем в «Значения», а «Продавцов», «Дату продажи» — в «Строки». По данным разных продавцов за разные годы тут же посчитались суммы. При необходимости можно развернуть каждый год, квартал или месяц — получим более детальную информацию за конкретный период.
Набор опций будет зависеть от количества столбцов. Например, у нас пять столбцов. Их нужно просто правильно расположить и выбрать, что мы хотим показать. Скажем, сумму.
Можно её детализировать, например, по странам. Переносим «Страны».
Можно посмотреть результаты по продавцам. Меняем «Страну» на «Продавцов». По продавцам результаты будут такие.
2. 3D-карты
Этот способ визуализации данных с географической привязкой позволяет анализировать данные, находить закономерности, имеющие региональное происхождение.
Полезное дополнение. Координаты нигде прописывать не нужно — достаточно лишь корректно указать географическое название в таблице.
Как работать
- Откройте файл с таблицей, данные которой нужно визуализировать. Например, с информацией по разным городам и странам.
- Подготовьте данные для отображения на карте: «Главная» → «Форматировать как таблицу».
- Выделите диапазон данных для анализа.
- На вкладке «Вставка» есть кнопка 3D-карта.
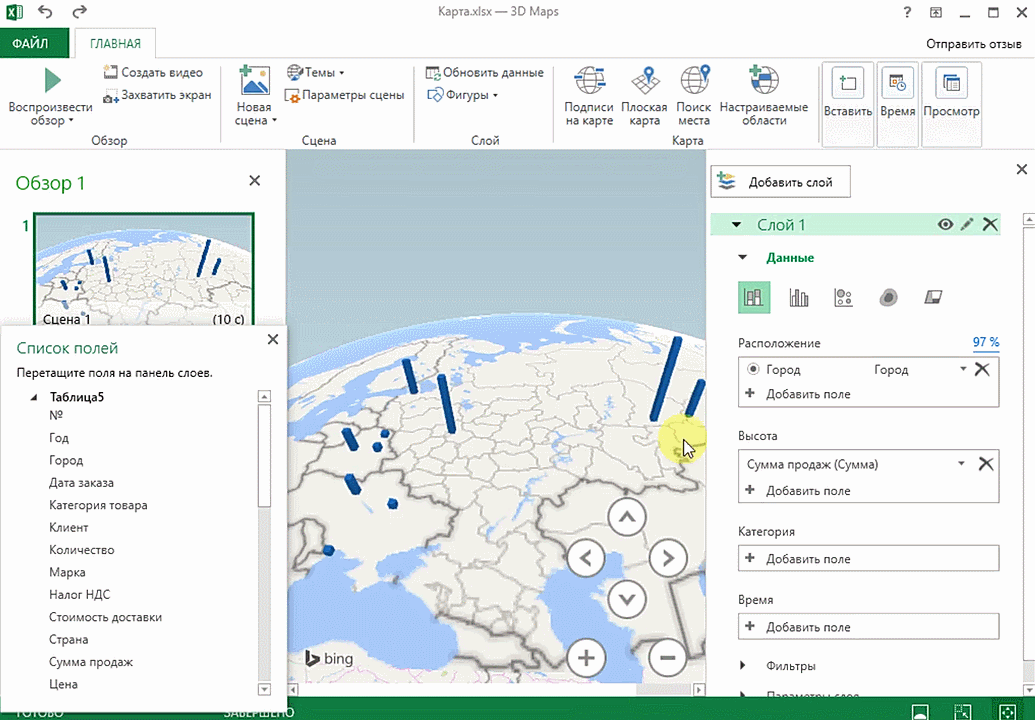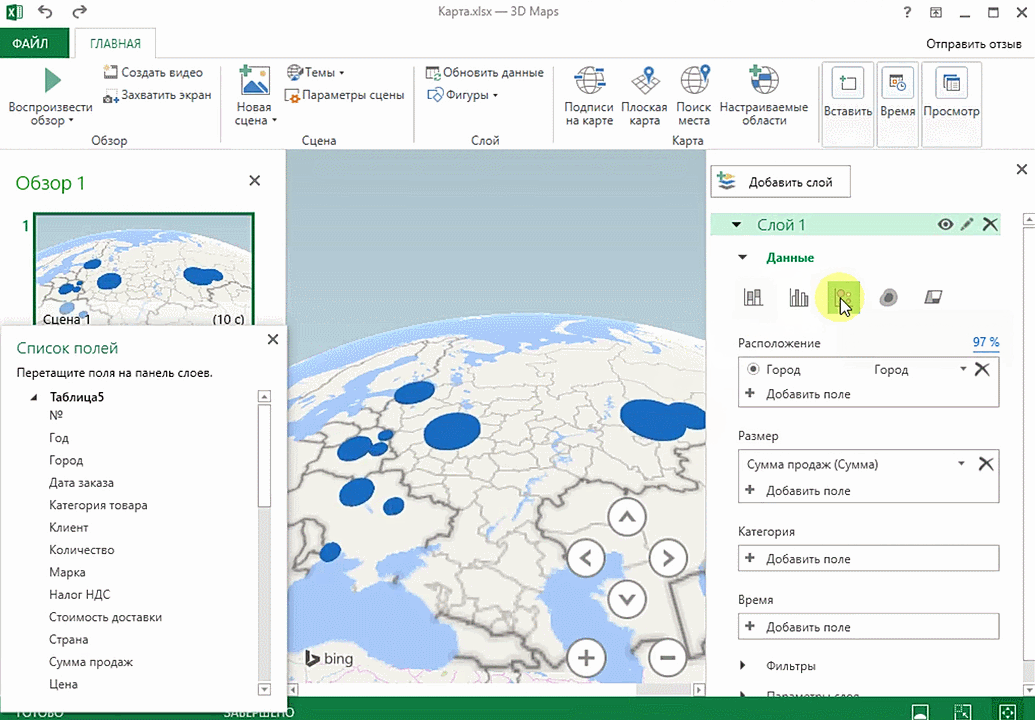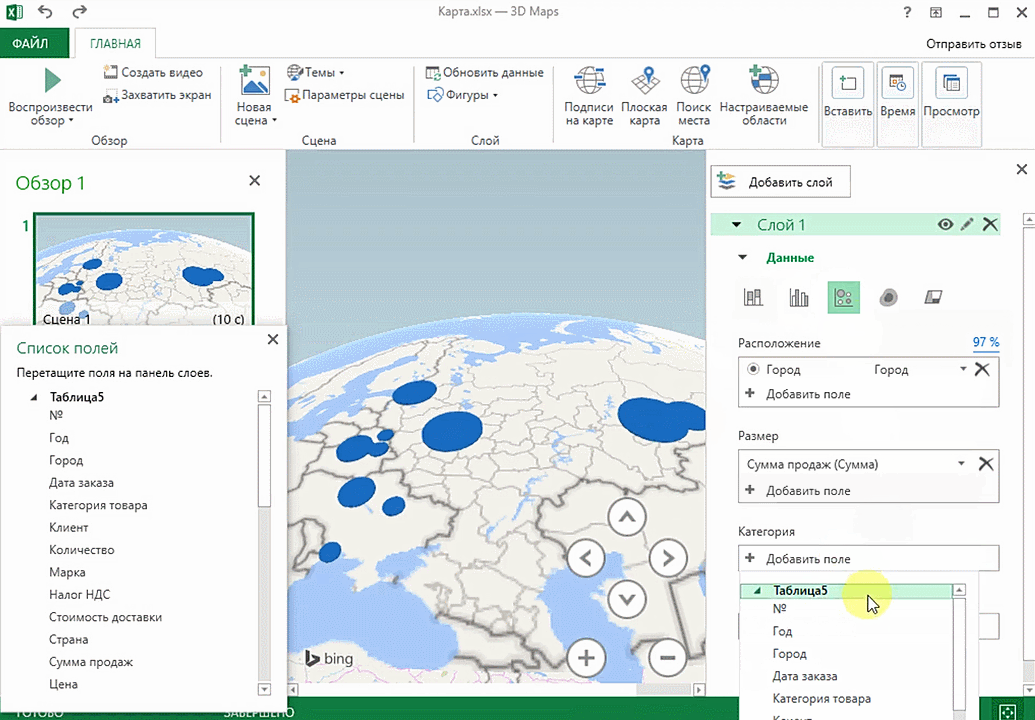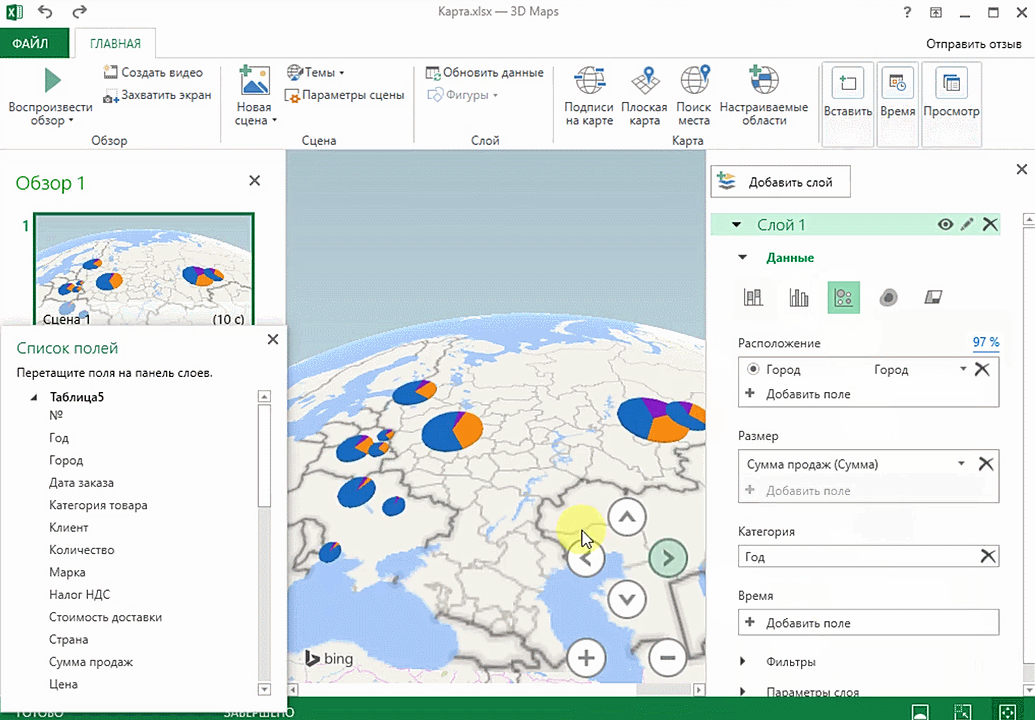
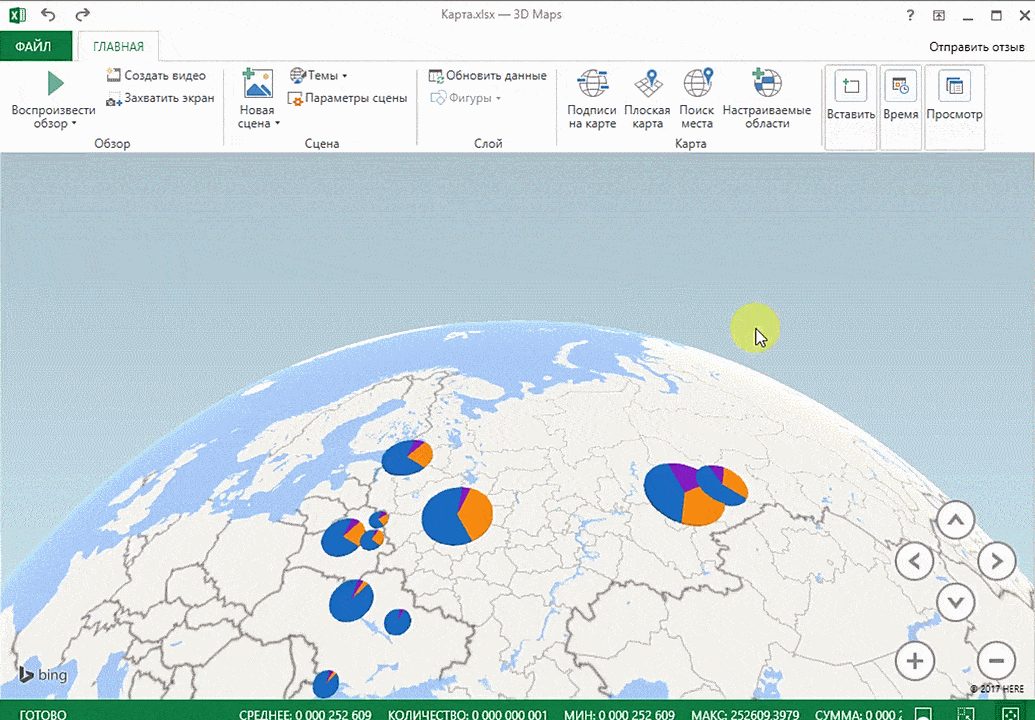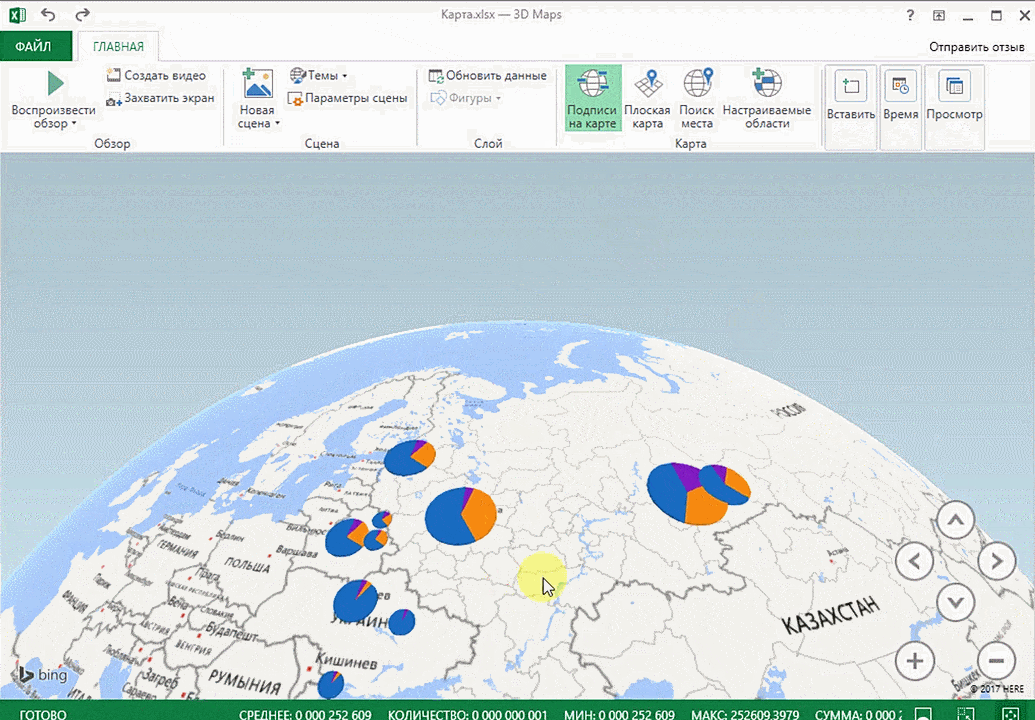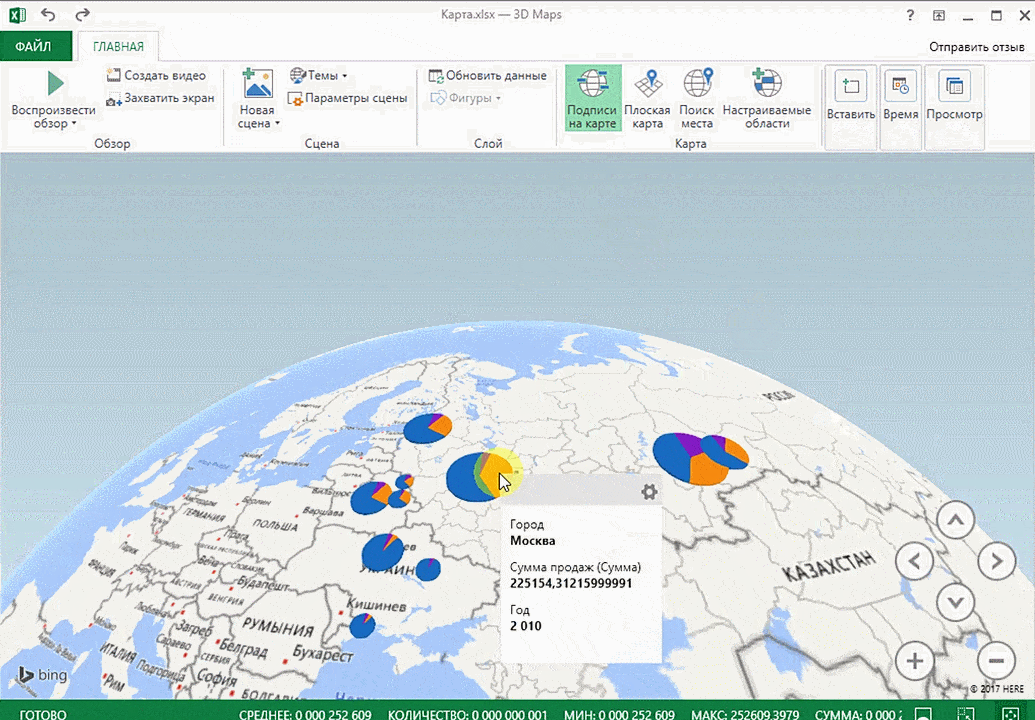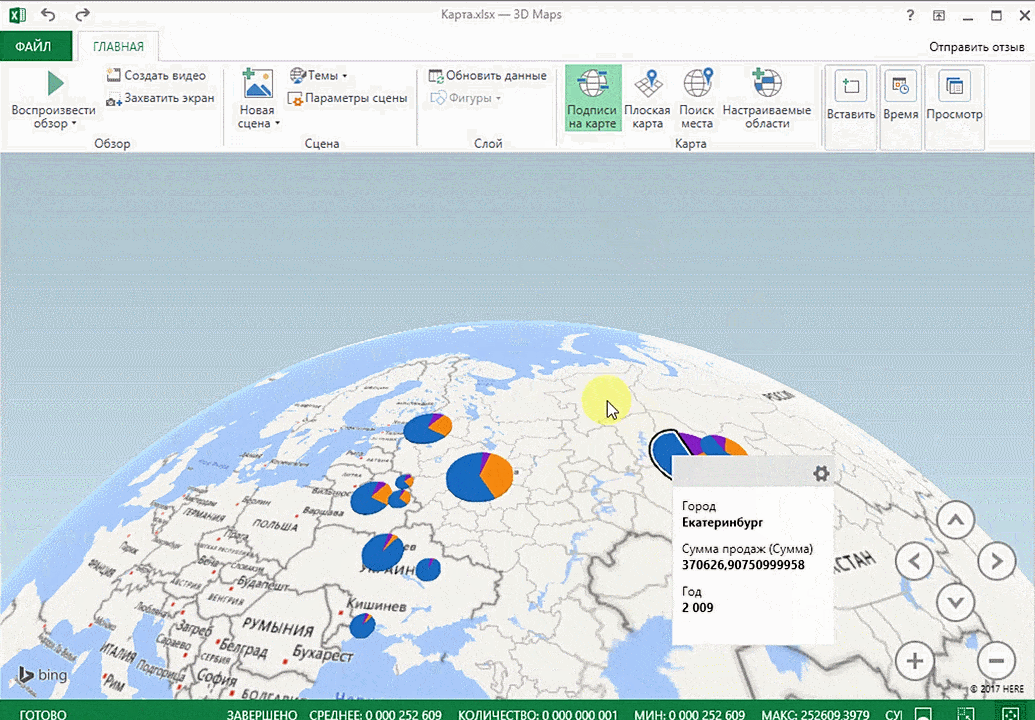
Точки на карте — это наши города. Но просто города нам не очень интересны — интересно увидеть информацию, привязанную к этим городам. Например, суммы, которые можно отобразить через высоту столбика. При наведении курсора на столбик показывается сумма.
Также достаточно информативной является круговая диаграмма по годам. Размер круга задаётся суммой.
3. Лист прогнозов
Зачастую в бизнес-процессах наблюдаются сезонные закономерности, которые необходимо учитывать при планировании. Лист прогноза — наиболее точный инструмент для прогнозирования в Excel, чем все функции, которые были до этого и есть сейчас. Его можно использовать для планирования деятельности коммерческих, финансовых, маркетинговых и других служб.
Полезное дополнение. Для расчёта прогноза потребуются данные за более ранние периоды. Точность прогнозирования зависит от количества данных по периодам — лучше не меньше, чем за год. Вам требуются одинаковые интервалы между точками данных (например, месяц или равное количество дней).
Как работать
- Откройте таблицу с данными за период и соответствующими ему показателями, например, от года.
- Выделите два ряда данных.
- На вкладке «Данные» в группе нажмите кнопку «Лист прогноза».
- В окне «Создание листа прогноза» выберите график или гистограмму для визуального представления прогноза.
- Выберите дату окончания прогноза.
В примере ниже у нас есть данные за 2011, 2012 и 2013 годы. Важно указывать не числа, а именно временные периоды (то есть не 5 марта 2013 года, а март 2013-го).
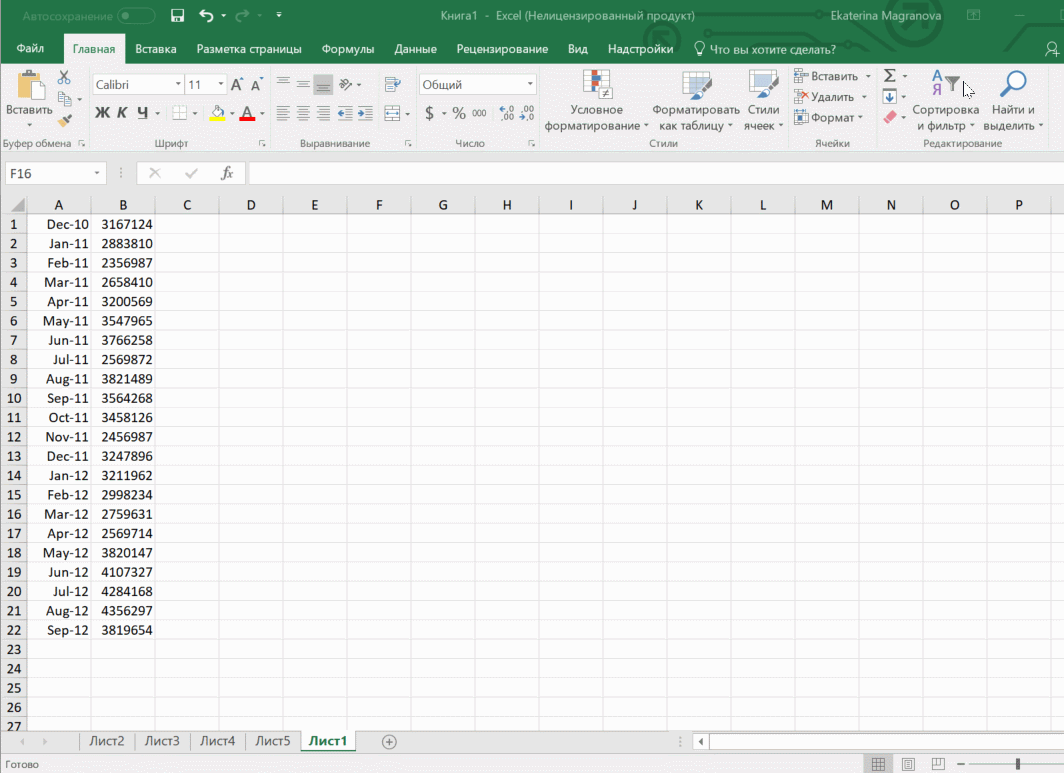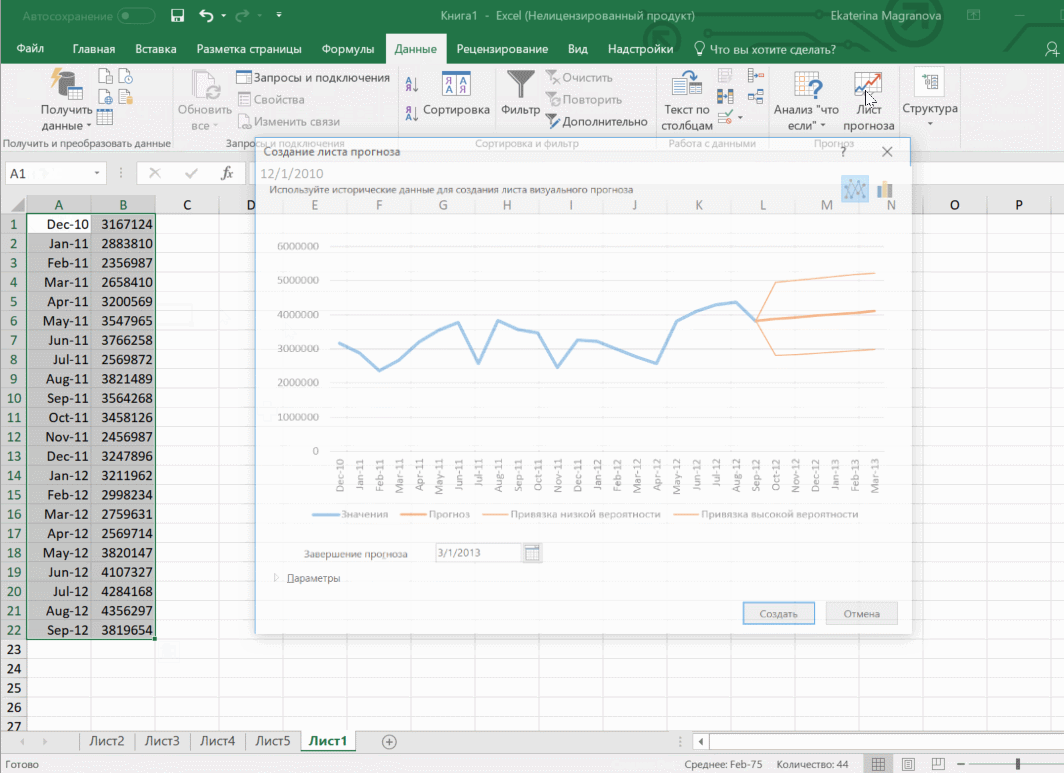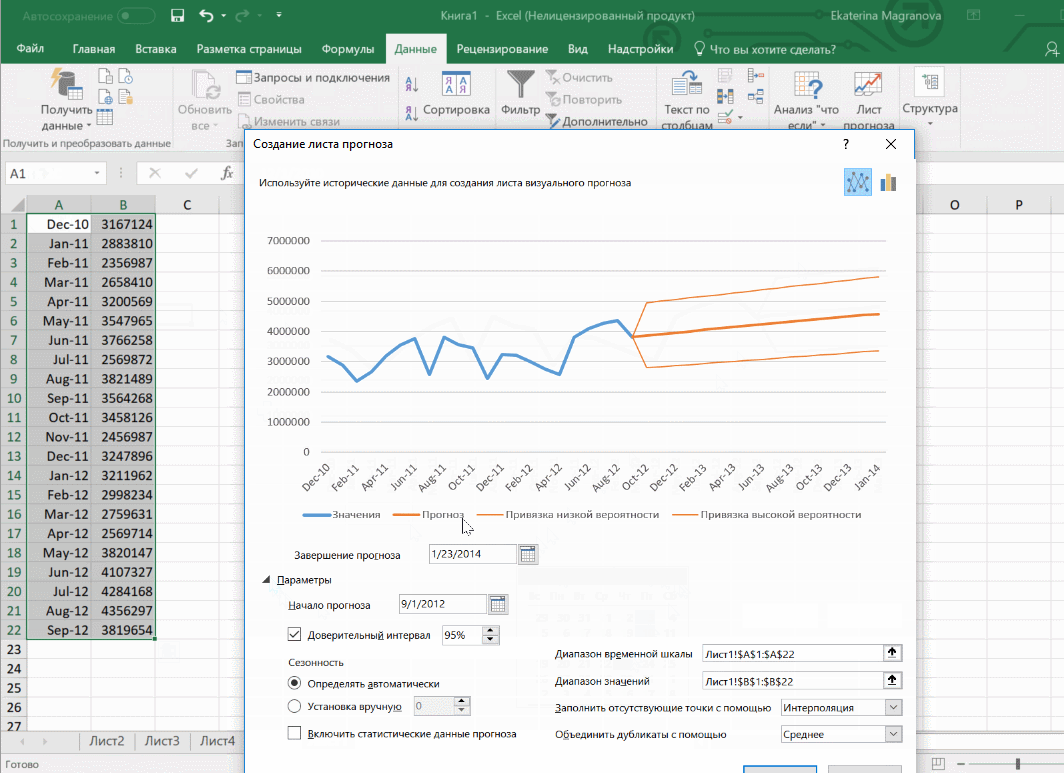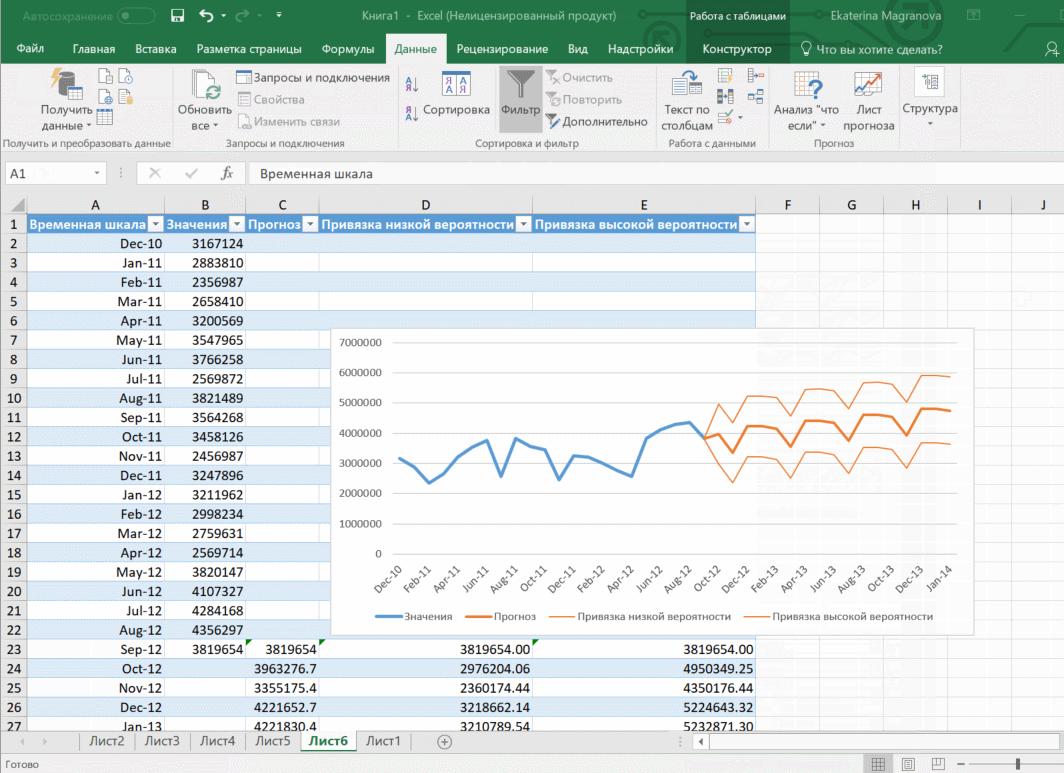
Для прогноза на 2014 год вам потребуются два ряда данных: даты и соответствующие им значения показателей. Выделяем оба ряда данных.
На вкладке «Данные» в группе «Прогноз» нажимаем на «Лист прогноза». В появившемся окне «Создание листа прогноза» выбираем формат представления прогноза — график или гистограмму. В поле «Завершение прогноза» выбираем дату окончания, а затем нажимаем кнопку «Создать». Оранжевая линия — это и есть прогноз.
4. Быстрый анализ
Эта функциональность, пожалуй, первый шаг к тому, что можно назвать бизнес-анализом. Приятно, что эта функциональность реализована наиболее дружественным по отношению к пользователю способом: желаемый результат достигается буквально в несколько кликов. Ничего не нужно считать, не надо записывать никаких формул. Достаточно выделить нужный диапазон и выбрать, какой результат вы хотите получить.
Полезное дополнение. Мгновенно можно создавать различные типы диаграмм или спарклайны (микрографики прямо в ячейке).
Как работать
- Откройте таблицу с данными для анализа.
- Выделите нужный для анализа диапазон.
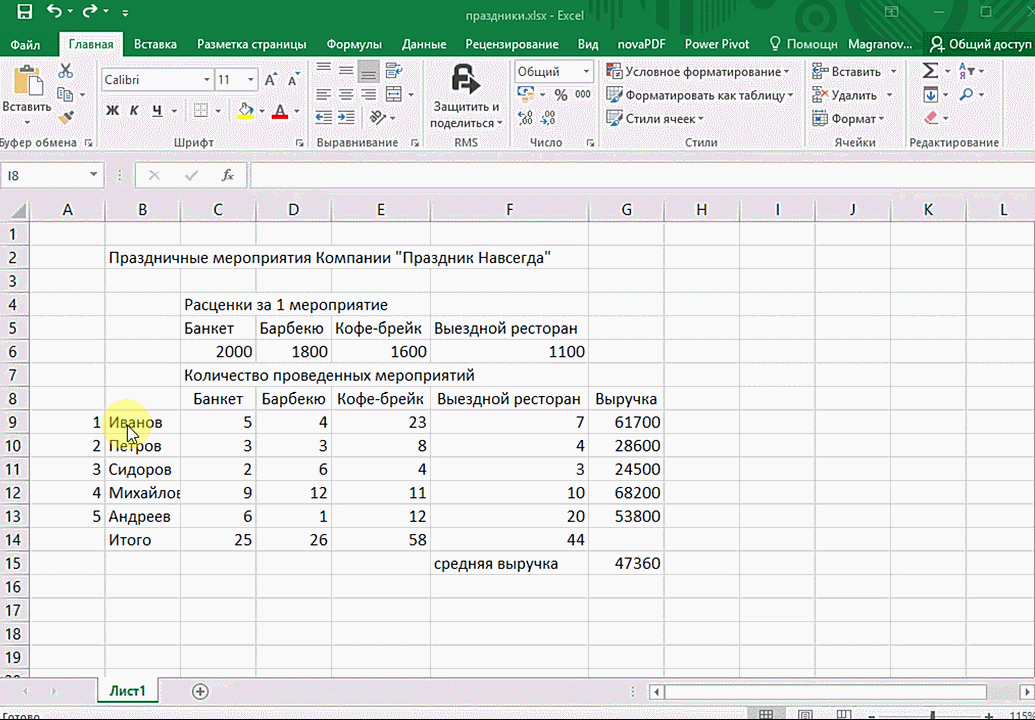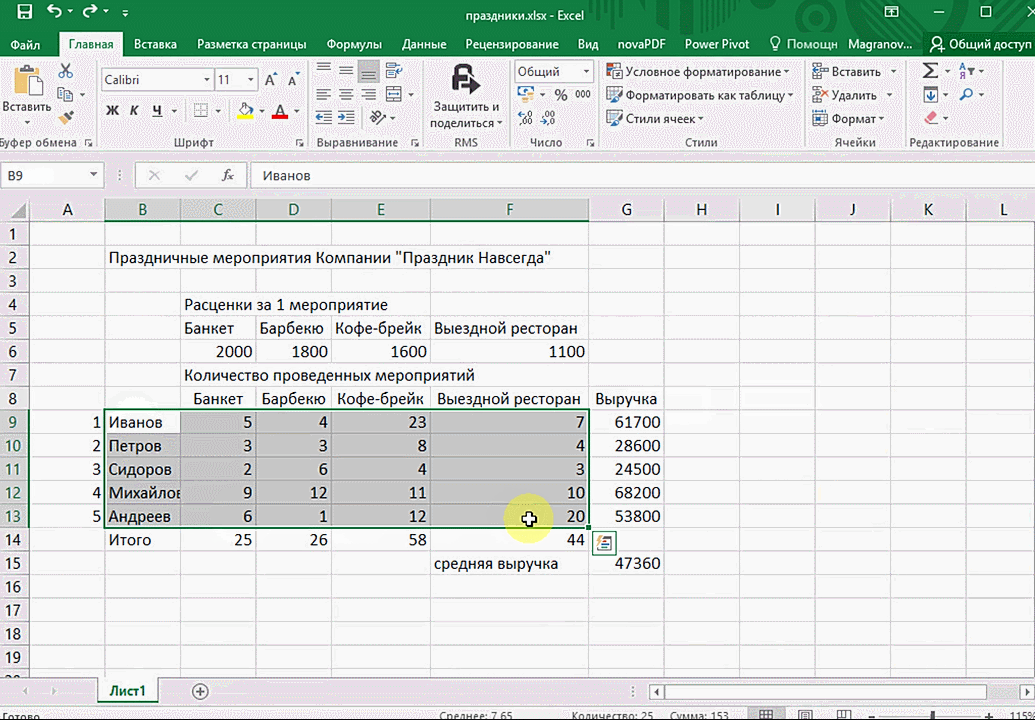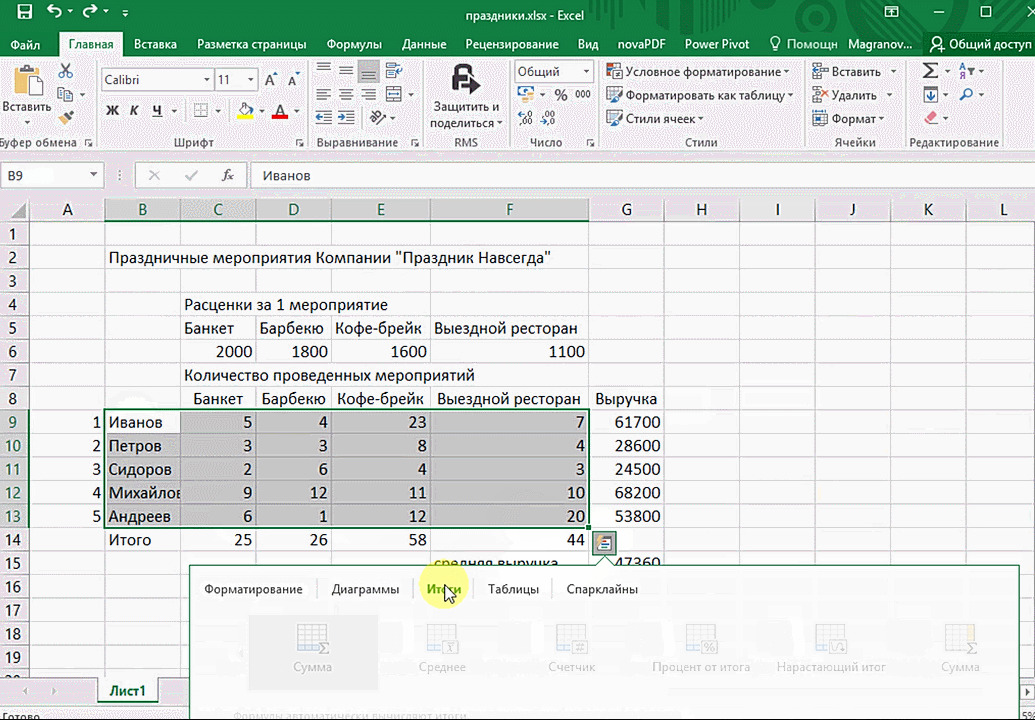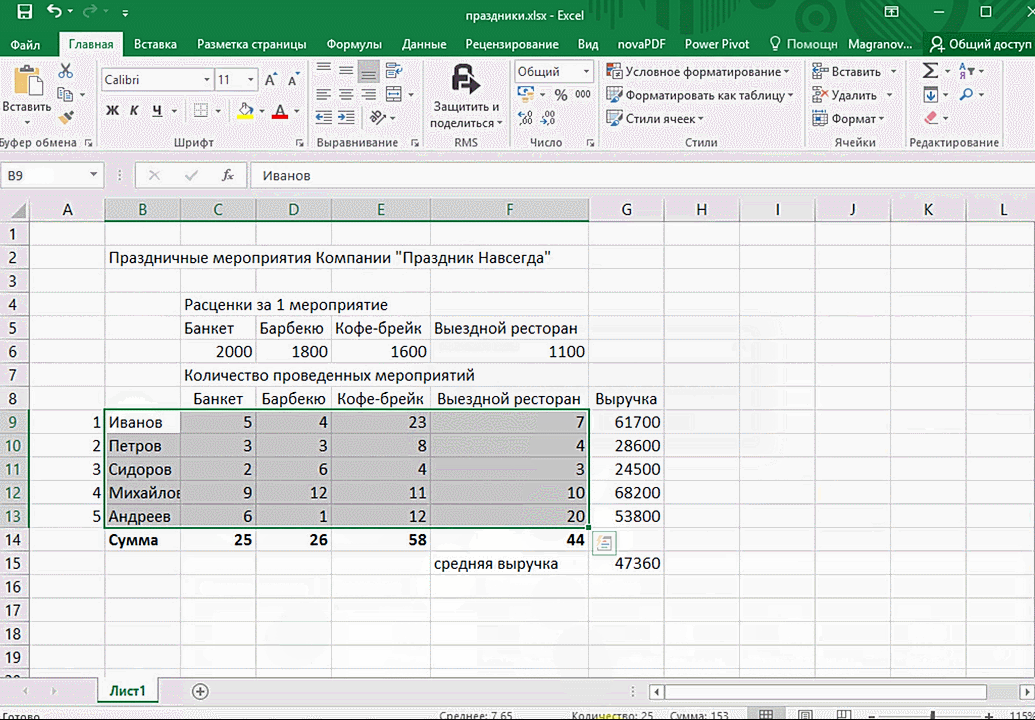
- При выделении диапазона внизу всегда появляется кнопка «Быстрый анализ». Она сразу предлагает совершить с данными несколько возможных действий. Например, найти итоги. Мы можем узнать суммы, они проставляются внизу.
В быстром анализе также есть несколько вариантов форматирования. Посмотреть, какие значения больше, а какие меньше, можно в самих ячейках гистограммы.
Также можно проставить в ячейках разноцветные значки: зелёные — наибольшие значения, красные — наименьшие.
Надеемся, что эти приёмы помогут ускорить работу с анализом данных в Microsoft Excel и быстрее покорить вершины этого сложного, но такого полезного с точки зрения работы с цифрами приложения.
Читайте также:
- 10 быстрых трюков с Excel →
- 20 секретов Excel, которые помогут упростить работу →
- 10 шаблонов Excel, которые будут полезны в повседневной жизни →
Excel – одна из лучших программ для аналитика данных. А почти каждому человеку на том или ином этапе жизни приходилось иметь дело с цифрами и текстовыми данными и обрабатывать их в условиях жестких дедлайнов. Если вам и сейчас нужно это делать, то мы опишем техники, которые помогут существенно улучшить вам жизнь. А чтобы было более наглядно, покажем, как их воплощать, с помощью анимаций.
Содержание
- Анализ данных через сводные таблицы Excel
- Как работать со сводными таблицами
- Анализ данных с помощью 3D-карт
- Как работать с 3D-картами в Excel
- Лист прогноза в Excel
- Как работать с листом прогноза
- Быстрый анализ в Excel
- Как работать
Анализ данных через сводные таблицы Excel
Сводные таблицы – один из самых простых способов автоматизировать обработку информации. Он позволяет свести в кучу огромный массив данных, которые абсолютно не структурированы. Если его использовать, можно почти навсегда забыть о том, что такое фильтр и ручная сортировка. А чтобы их создать, достаточно нажать буквально пару кнопок и внести несколько несложных параметров в зависимости от того, какой способ представления результатов нужен конкретно вам в определенной ситуации.
Существует множество способов автоматизации анализа данных в Excel. Это как встроенные инструменты, так и дополнения, которые можно скачать на просторах интернета. Также есть дополнение «Пакет анализа», которое было разработано компанией Майкрософт. Она имеет все необходимые возможности, чтобы вы могли получать все необходимые результаты в одном файле Excel.
Пакет анализа данных, разработанный Майкрософт, можно использовать исключительно на едином листе в одну единицу времени. Если он будет обрабатывать информацию, расположенную на нескольких, то итоговая информация будет отображаться исключительно на одном. В других же будут показываться диапазоны без какой-либо значений, в которых есть исключительно форматы. Чтобы осуществить проанализировать информацию на нескольких листах, нужно использовать этот инструмент по отдельности. Это очень большой модуль, который поддерживает огромное количество возможностей, в частности, позволяет выполнять следующие типы обработки:
- Дисперсионный анализ.
- Корреляционный анализ.
- Ковариация.
- Вычисление скользящего среднего. Очень популярный метод в статистике и в трейдинге.
- Получать случайные числа.
- Выполнять операции с выборкой.
Эта надстройка не активирована по умолчанию, но входит в стандартный пакет. Чтобы ею воспользоваться, необходимо ее включить. Для этого сделайте следующие шаги:
- Перейдите в меню «Файл», и там найдите кнопку «Параметры». После этого перейдите в «Надстройки». Если же вы установили 2007 версию Эксель, то нужно нажать на кнопку «Параметры Excel», которая находится в меню Office.
- Далее появляется всплывающее меню, озаглавленное словом «Управление». Там находим пункт «Надстройки Excel», нажимаем на него, а потом – на кнопку «Перейти». Если же вы используете компьютер Apple, то достаточно открыть вкладку «Средства» в меню, а потом в раскрывающемся перечне найти пункт «Надстройки для Excel».
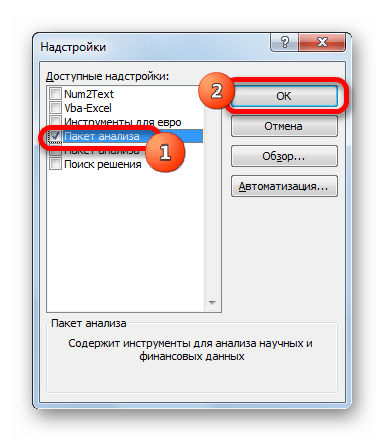
- В том диалоге, который появился после этого, нужно поставить галочку возле пункта «Пакет анализа», после чего подтвердить свои действия, нажав кнопку «ОК».
В некоторых ситуациях может оказаться так, что этого дополнения найти не удалось. В этом случае его не будет в перечне аддонов. Для этого надо нажать на кнопку «Обзор». Может также появиться информация о том, что пакет полностью отсутствует на этом компьютере. В этом случае необходимо его установить. Для этого нужно нажать на кнопку «Да».
Перед тем, как включить пакет анализа, необходимо сначала активировать VBA. Для этого его нужно загрузить таким же способом, как и саму надстройку.
Как работать со сводными таблицами
Первоначальная информация может быть какой-угодно. Это могут быть сведения о продажах, доставке, отгрузках продукции и так далее. Независимо от этого, последовательность шагов будет всегда одинаковой:
- Откройте файл, в котором содержится таблица.
- Выделите диапазон ячеек, которые мы будем анализировать с помощью сводной таблицы.
- Откройте вкладку «Вставка, и там надо найти группу «Таблицы», где есть кнопка «Сводная таблица». Если же используется компьютер под операционной системой Mac OS, то нужно открыть вкладку «Данные», и эта кнопка будет находиться во вкладке «Анализ».
- После этого откроется диалог с заголовком «Создание сводной таблицы».
- Затем выставите такое отображение данных, которое соответствует выделенному диапазону.
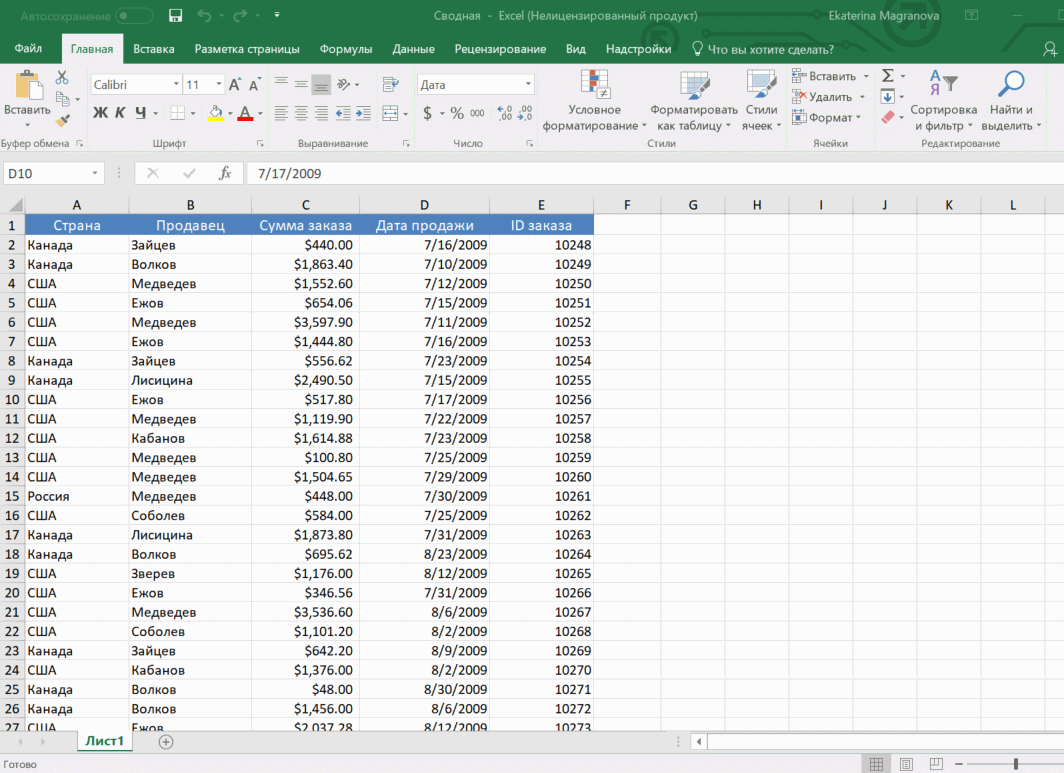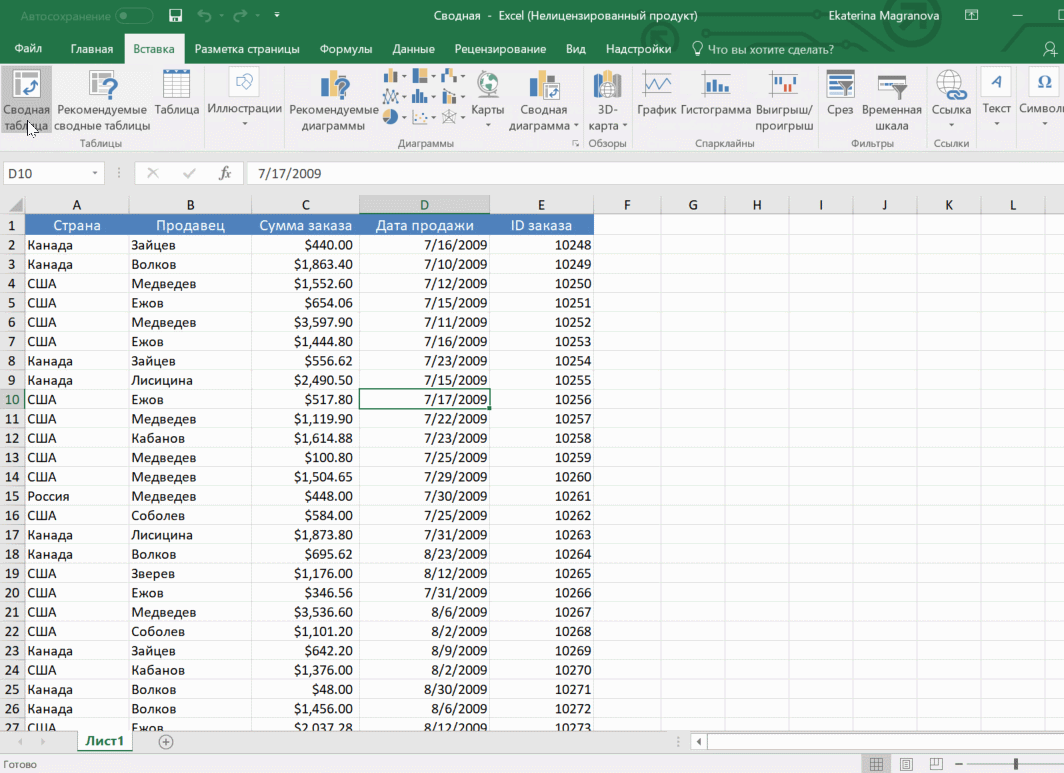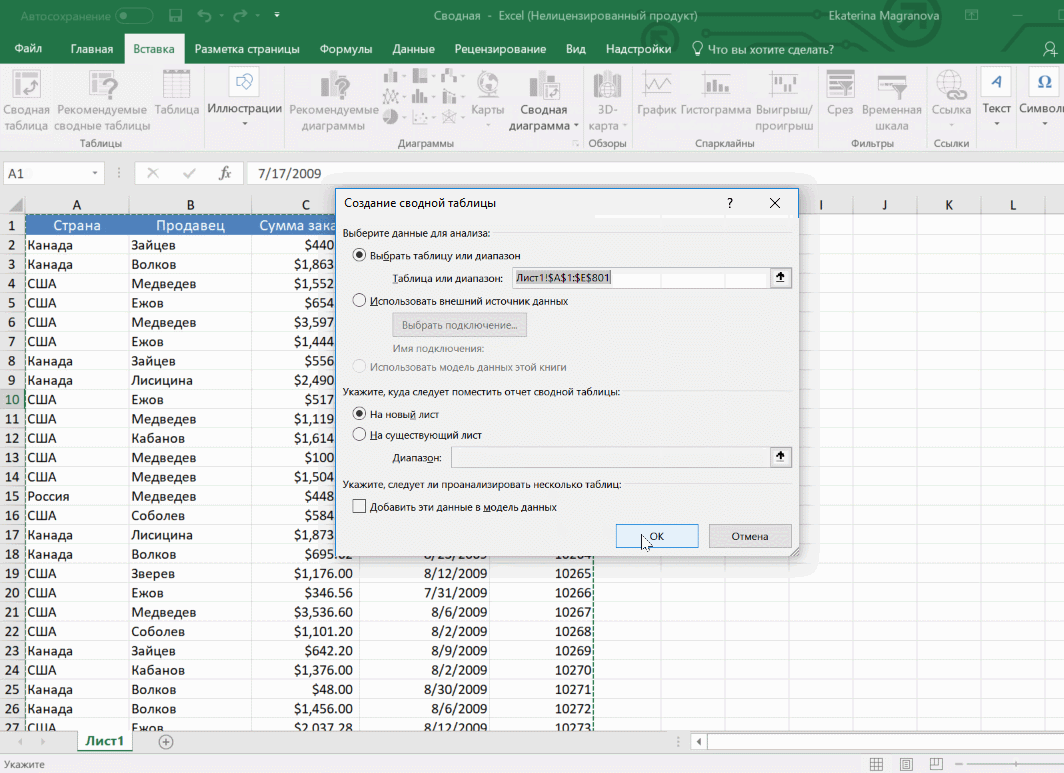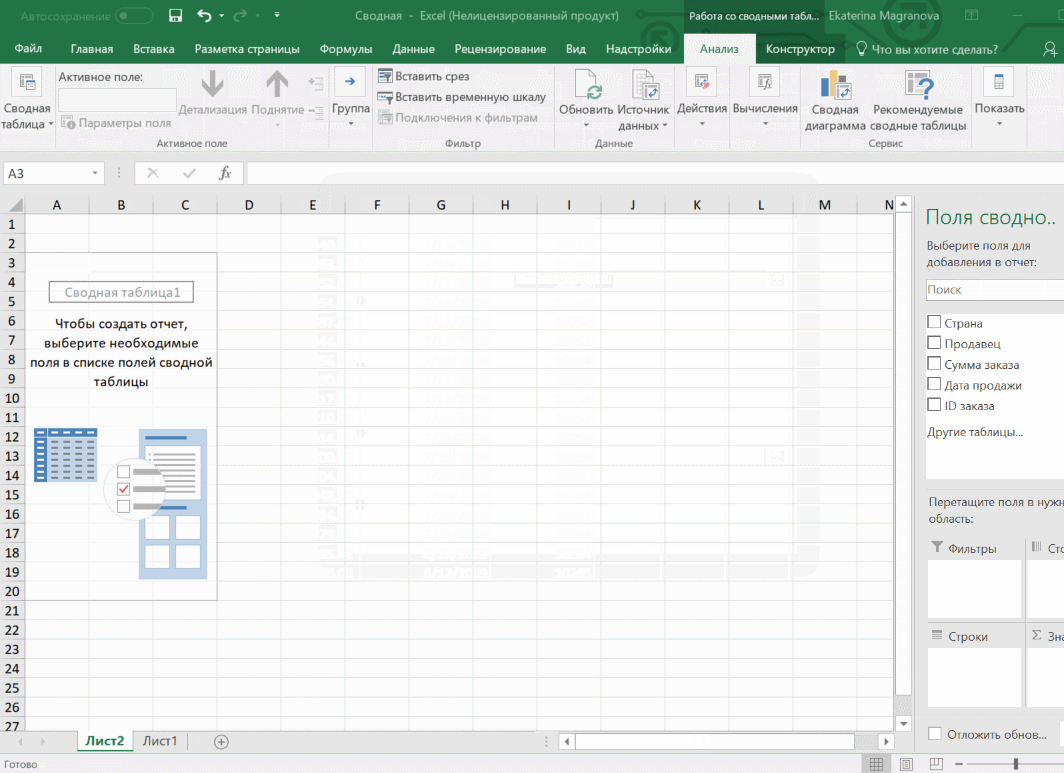
Мы открыли таблицу, информация в которой никоим образом не структурирована. Чтобы это сделать, можно воспользоваться настройками полей сводной таблицы в правой стороне экрана. Например, отправим в поле «Значения» «Сумму заказов», а информацию про продавцов и дату продажи – в строки таблицы. Исходя из данных, которые содержатся в этой таблице, автоматически определились суммы. Если есть необходимость, можно открыть информацию по каждому году, кварталу или месяцу. Это позволит получить детальную информацию, которая надо в конкретный момент.
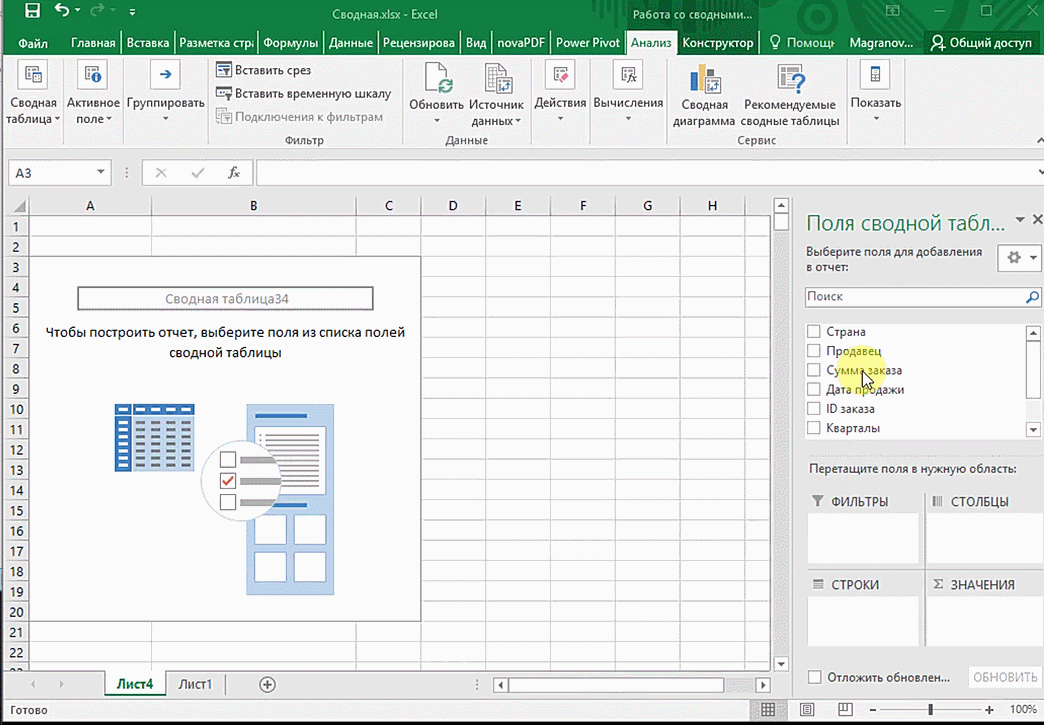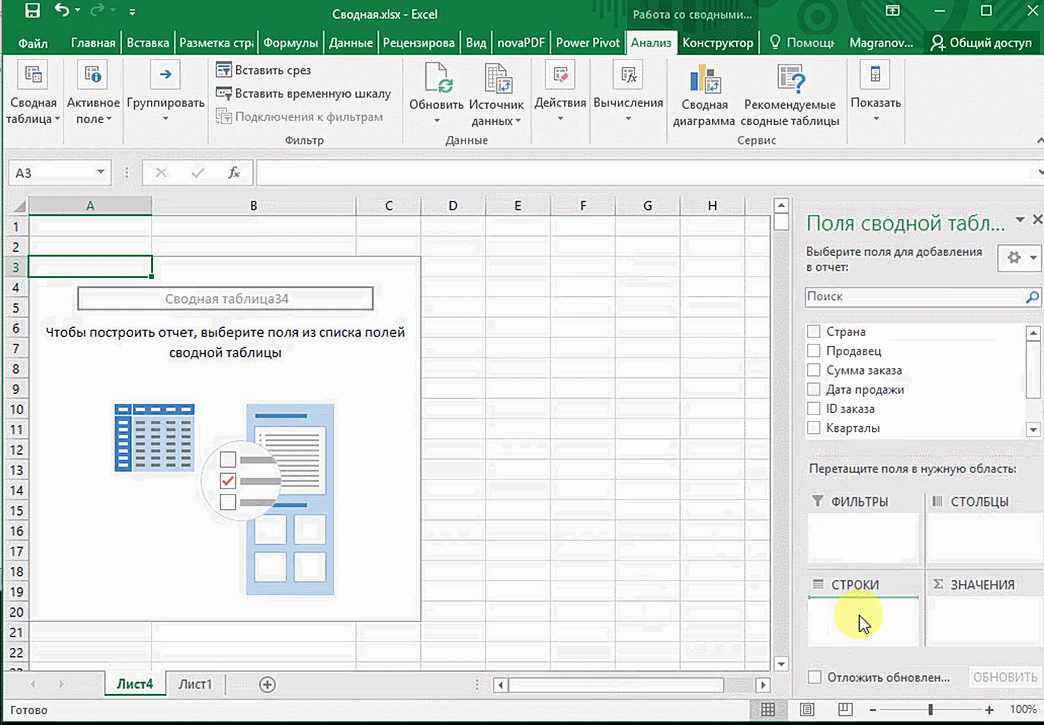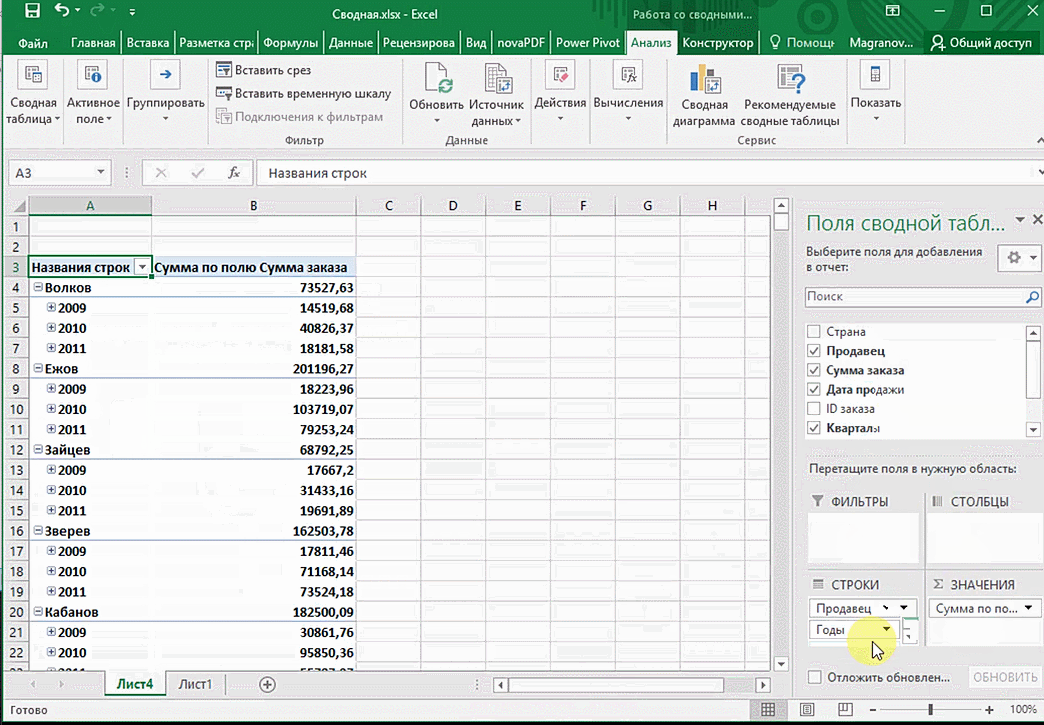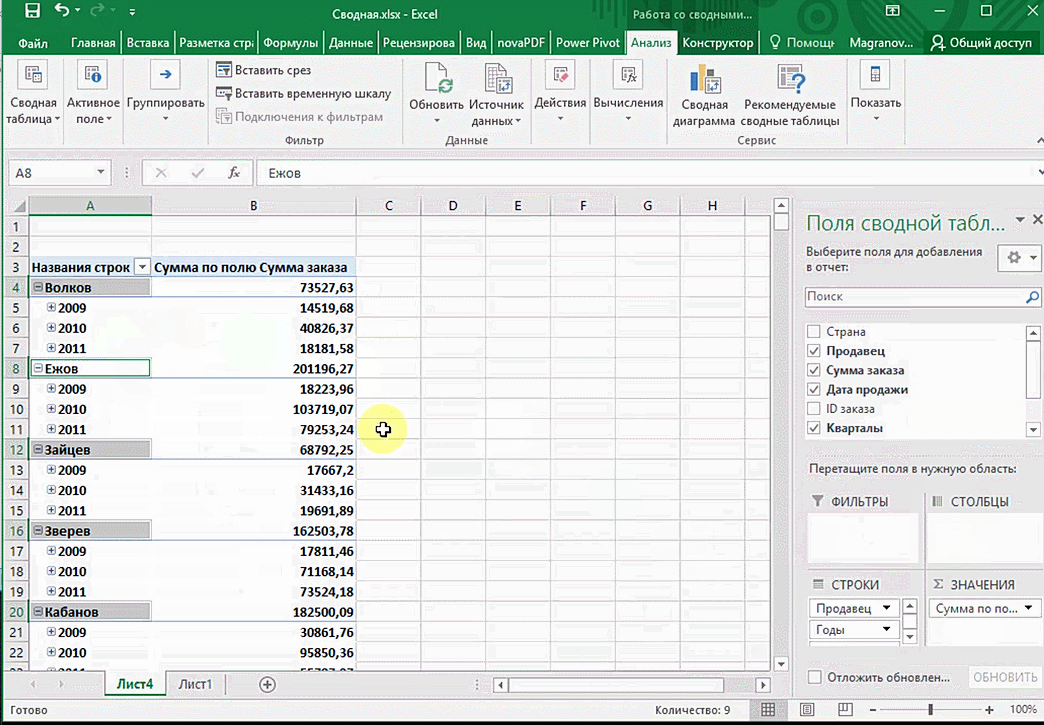
От того, сколько колонок есть, будет отличаться и набор имеющихся параметров. Например, общее число столбцов – 5. И нам надо просто разместить и выбрать их верным образом, а показать сумму. В таком случае выполняем действия, показанные на этой анимации.
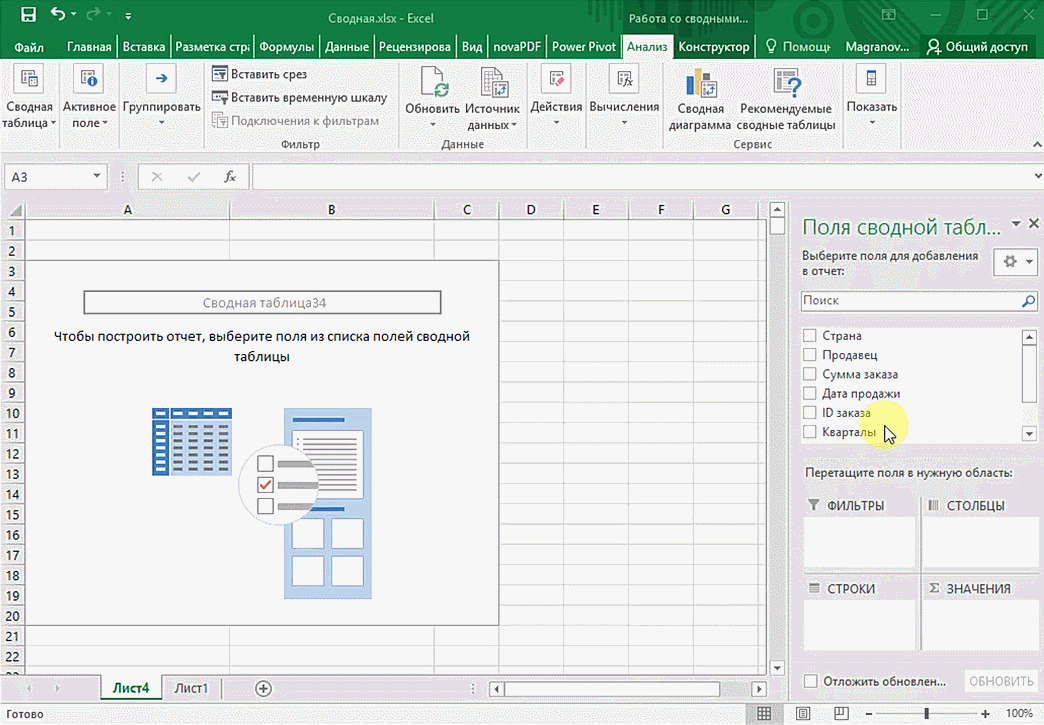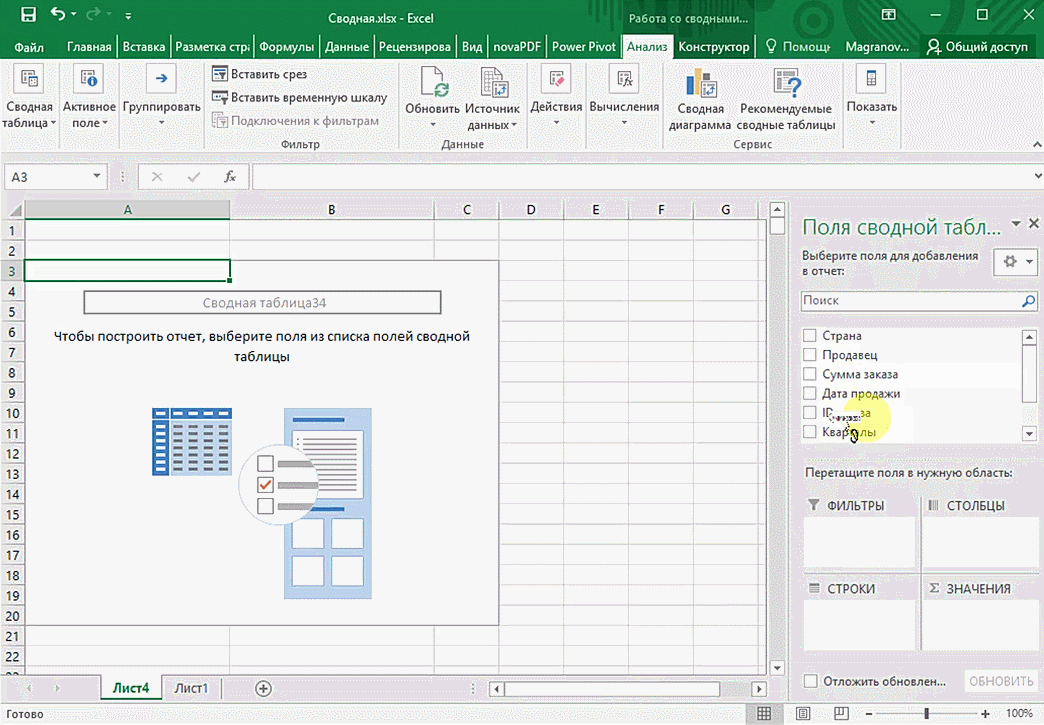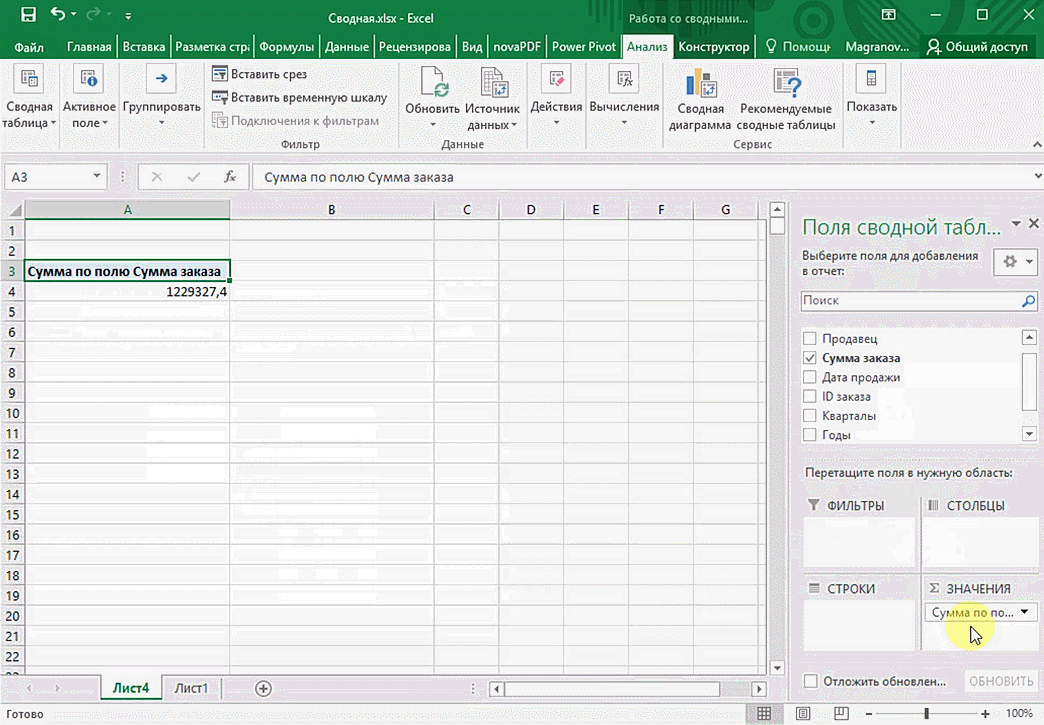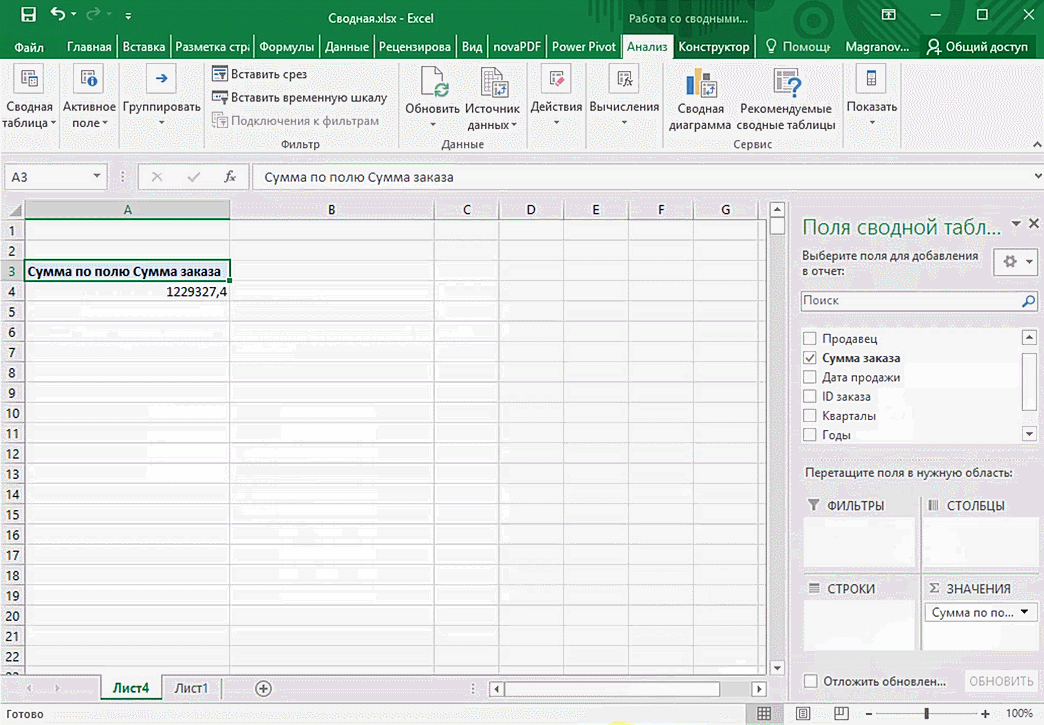
Можно сводную таблицу конкретизировать, указав, например, страну. Для этого мы включаем пункт «Страна».
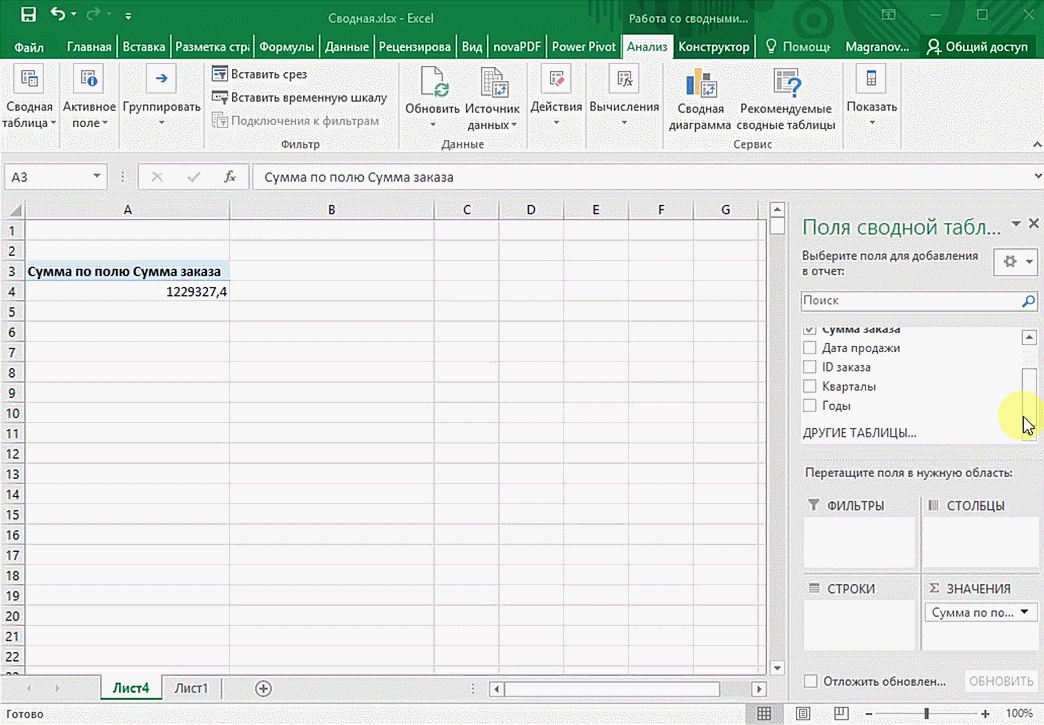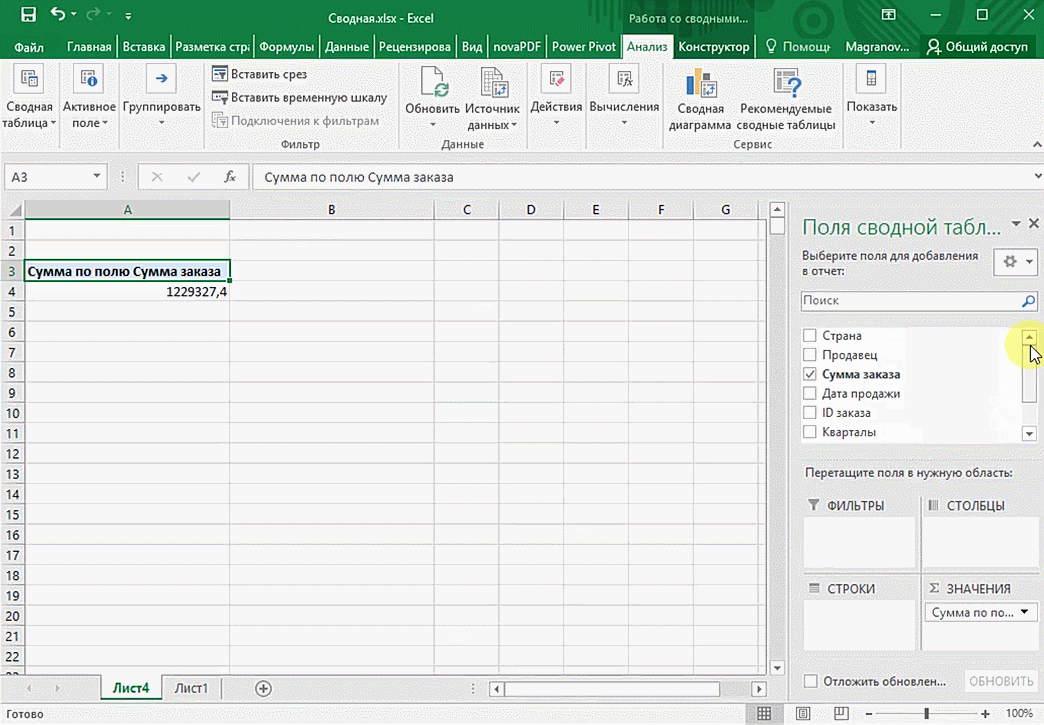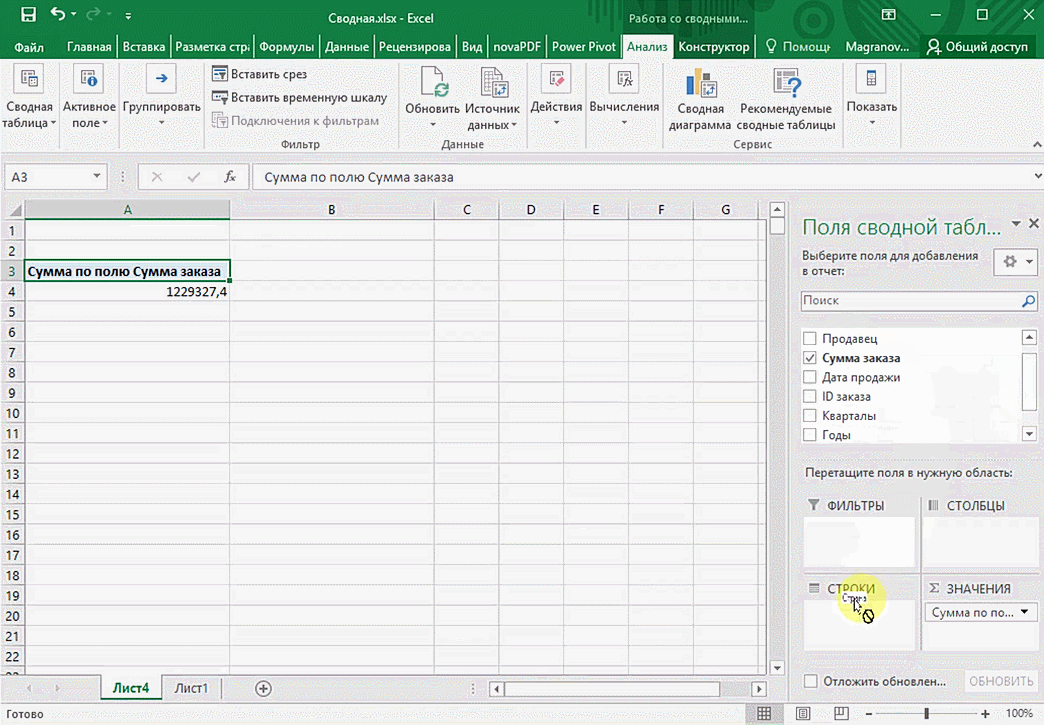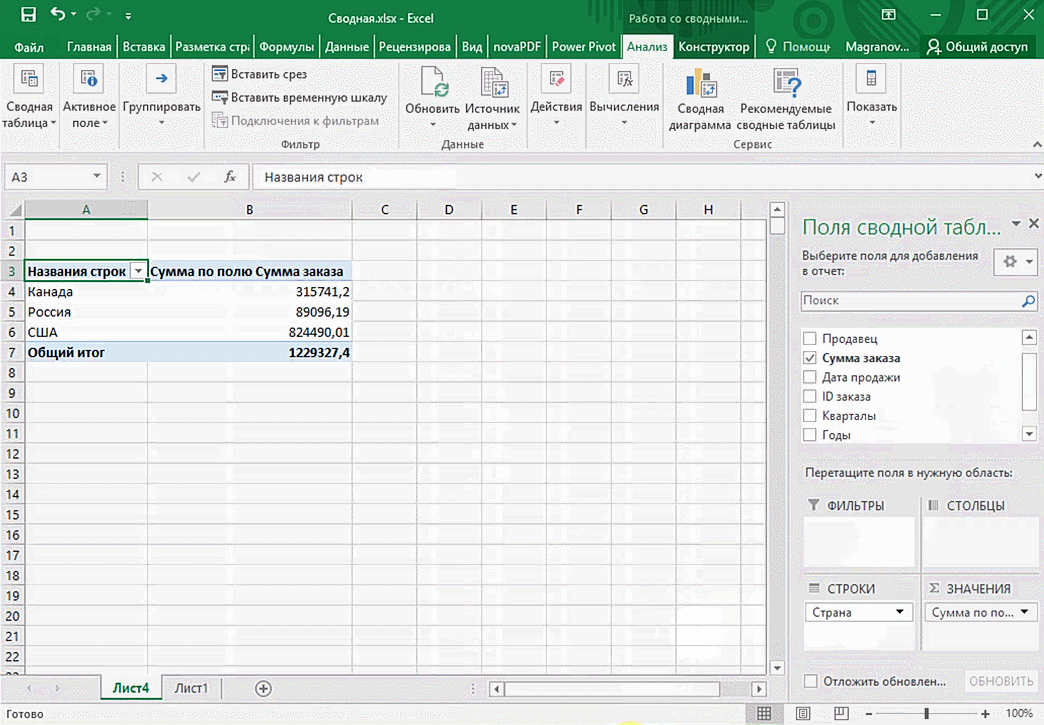
Можно также посмотреть информацию про продавцов. Для этого мы заменяем колонку «Страна» на «Продавец». Результат получится следующий.
Анализ данных с помощью 3D-карт
Данный метод визуального представления с географической привязкой дает возможность искать закономерности, привязанные к регионам, а также анализировать информацию этого типа.
Преимущество этого способа в том, что нет необходимости отдельно прописывать координаты. Необходимо просто правильно написать географическое положение в таблице.
Как работать с 3D-картами в Excel
Последовательность действий, которую вам необходимо выполнить, чтобы работать с 3Д-картами, следующая:
- Откройте файл, в котором есть интересующий диапазон данных. Например, таблица, где есть колонка «Страна» или «Город».
- Информацию, которая будет показываться на карте, нужно сначала отформатировать, как таблицу. Для этого надо найти соответствующий пункт на вкладке «Главная».
- Выделите те ячейки, которые будут анализироваться.
- После этого переходим на вкладку «Вставка», и там находим кнопку «3Д-карта».
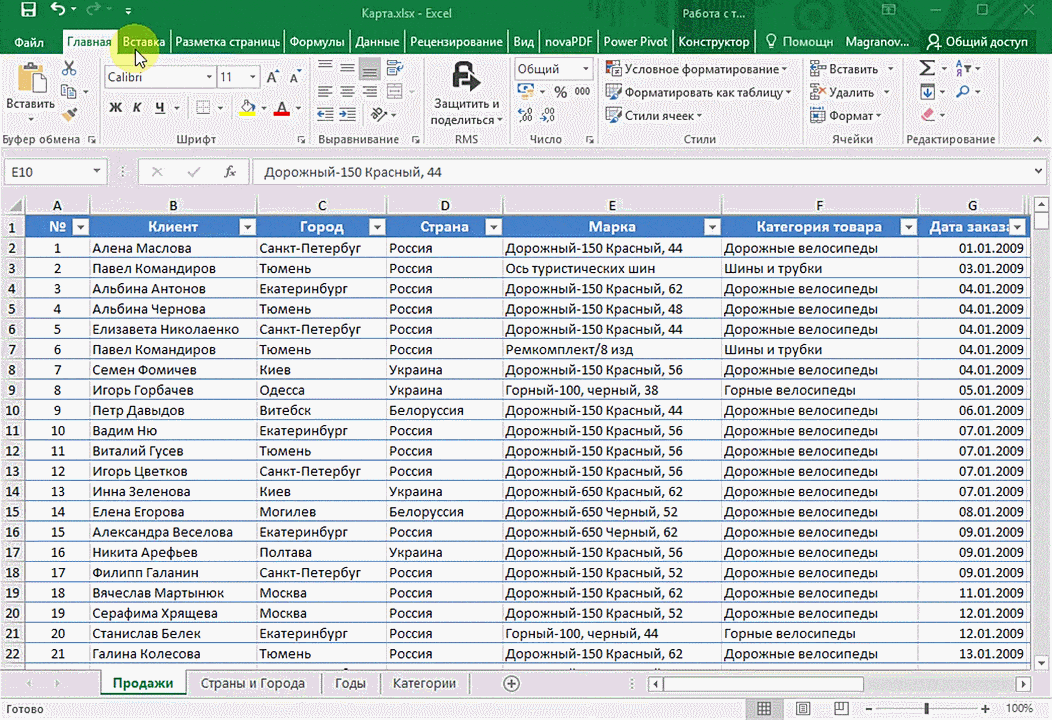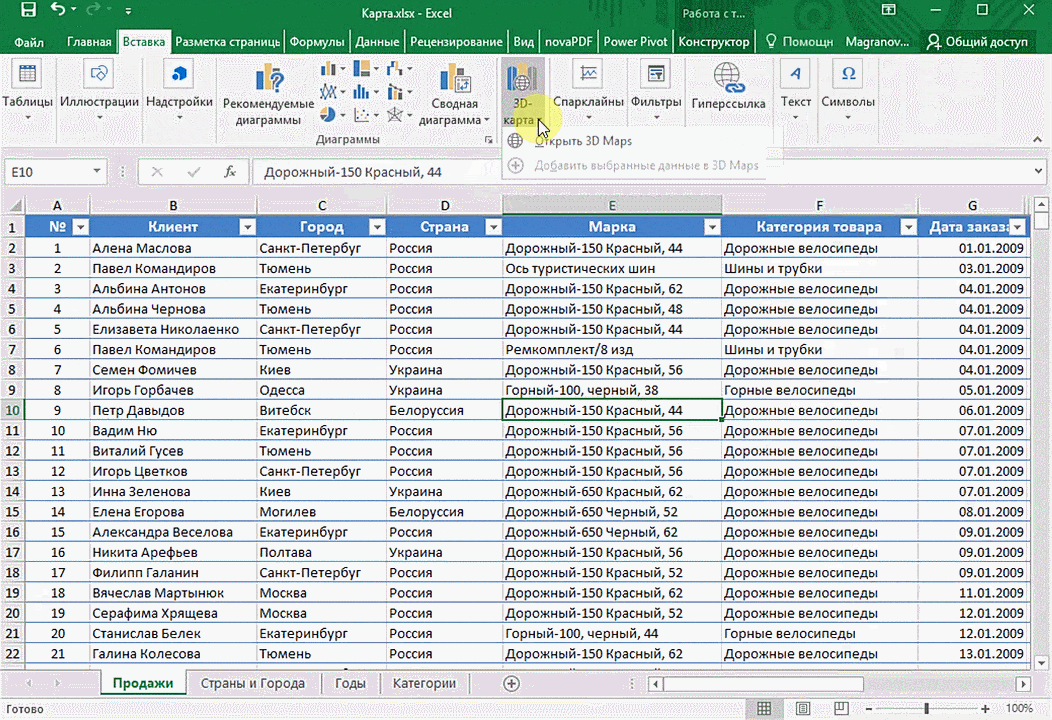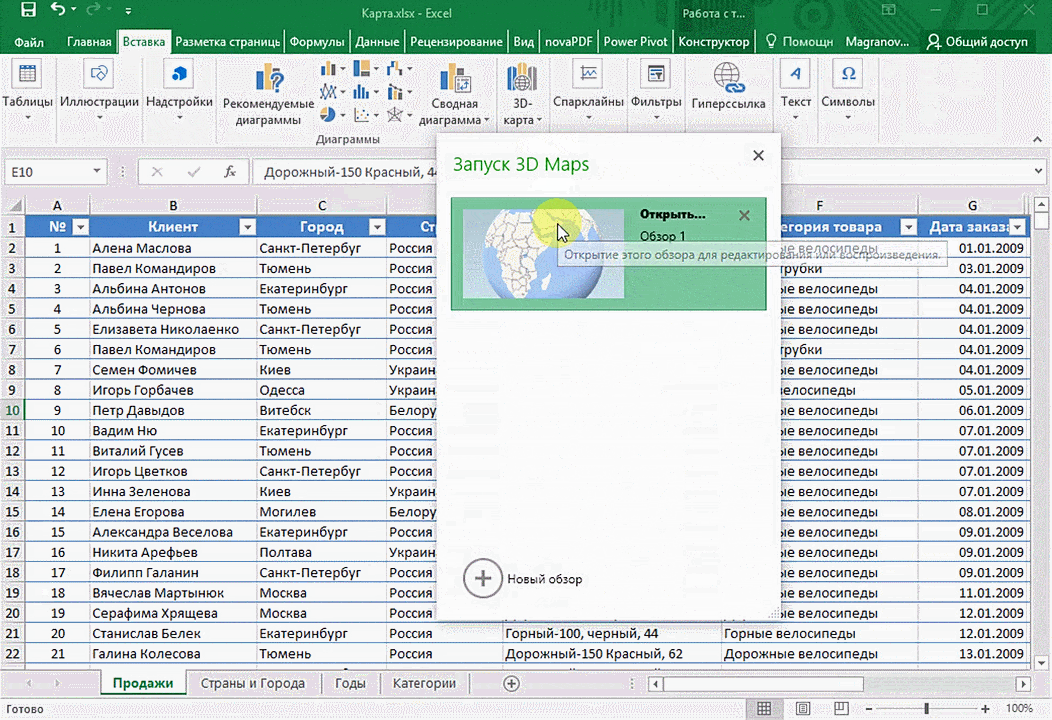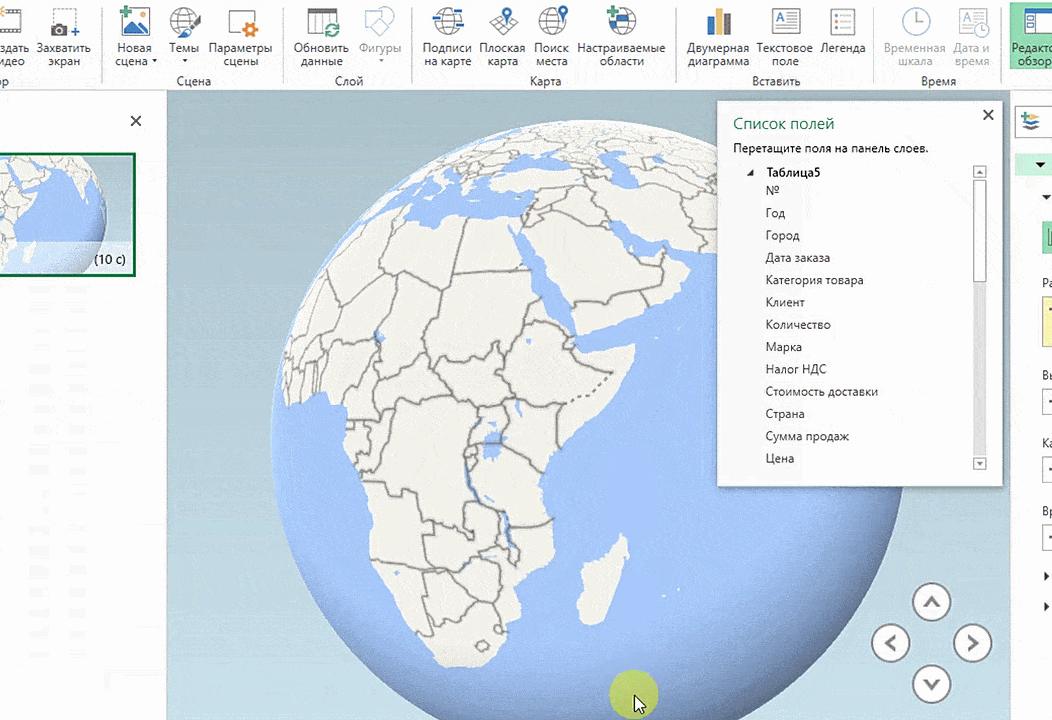
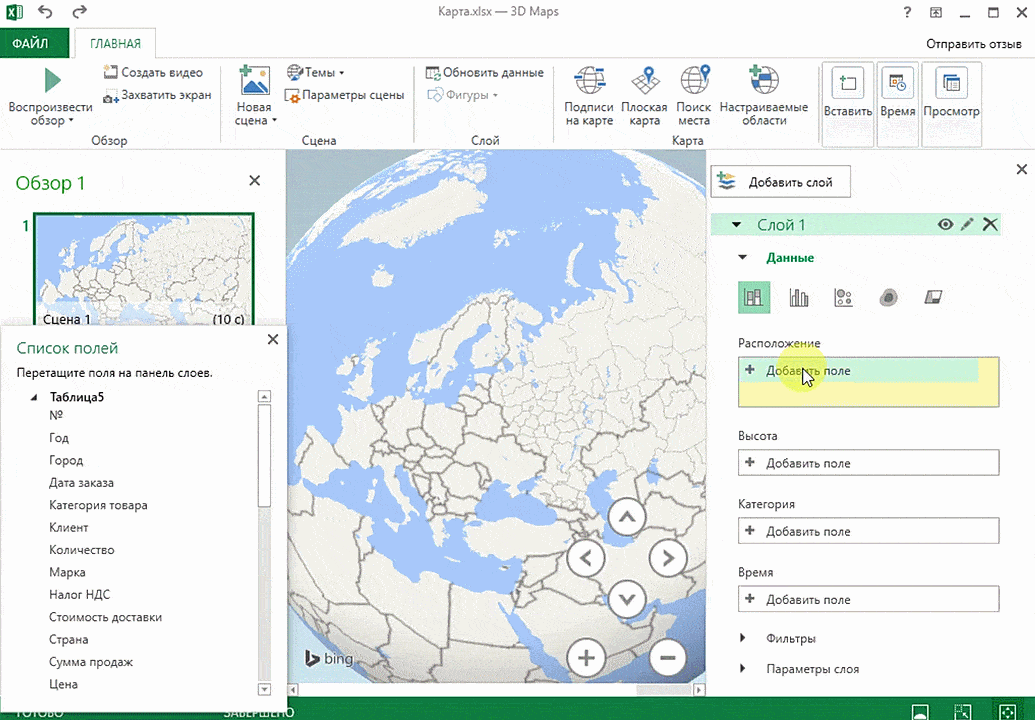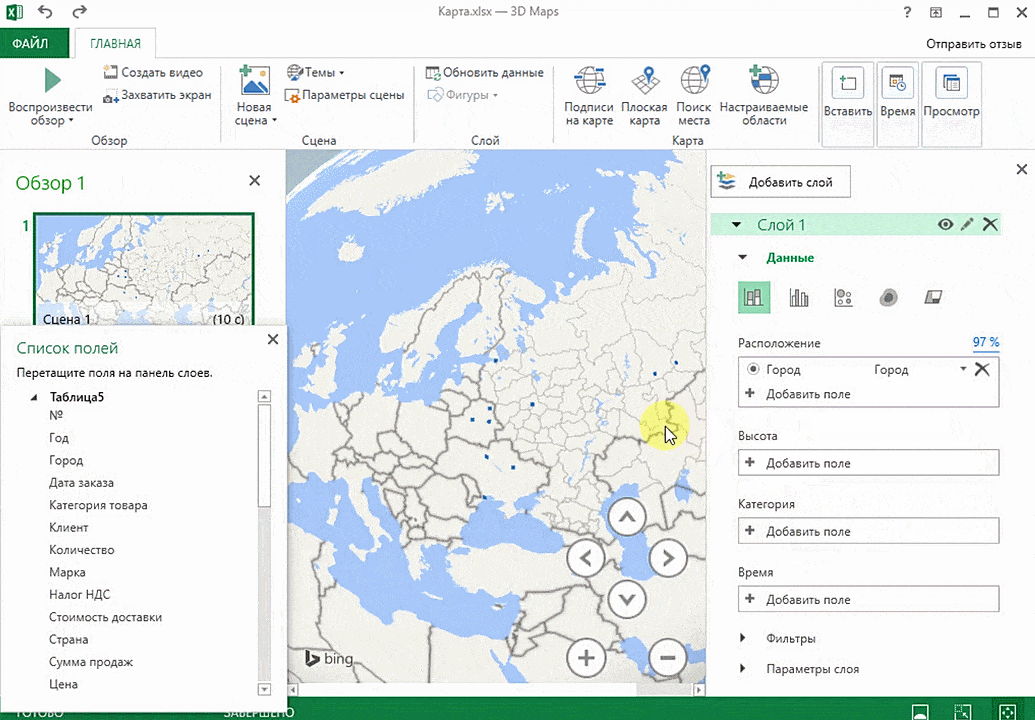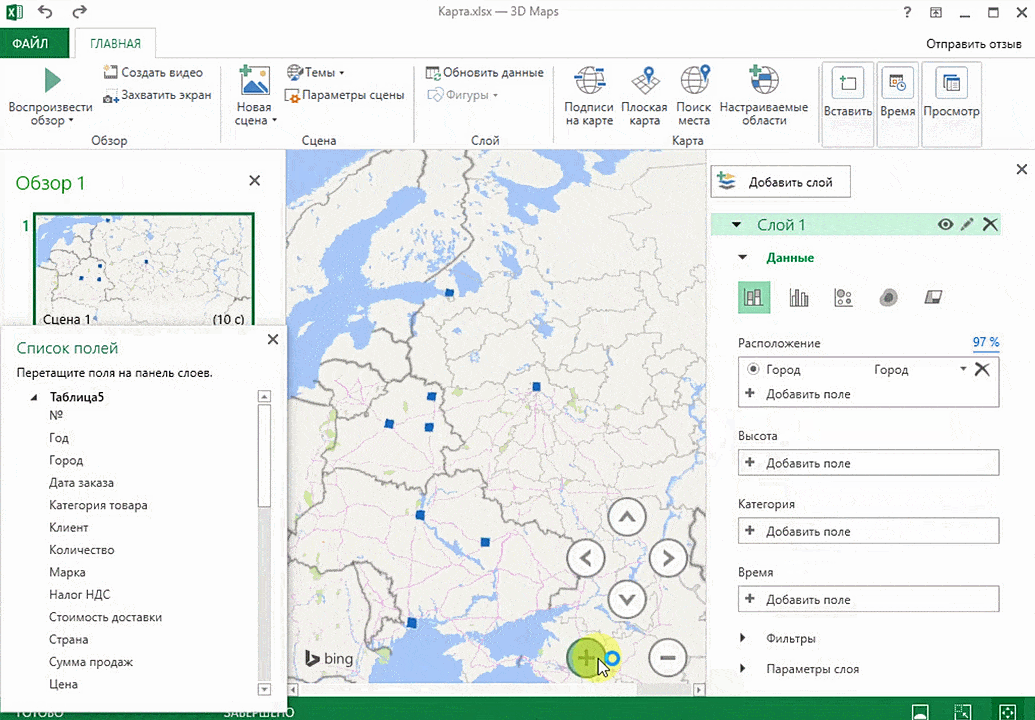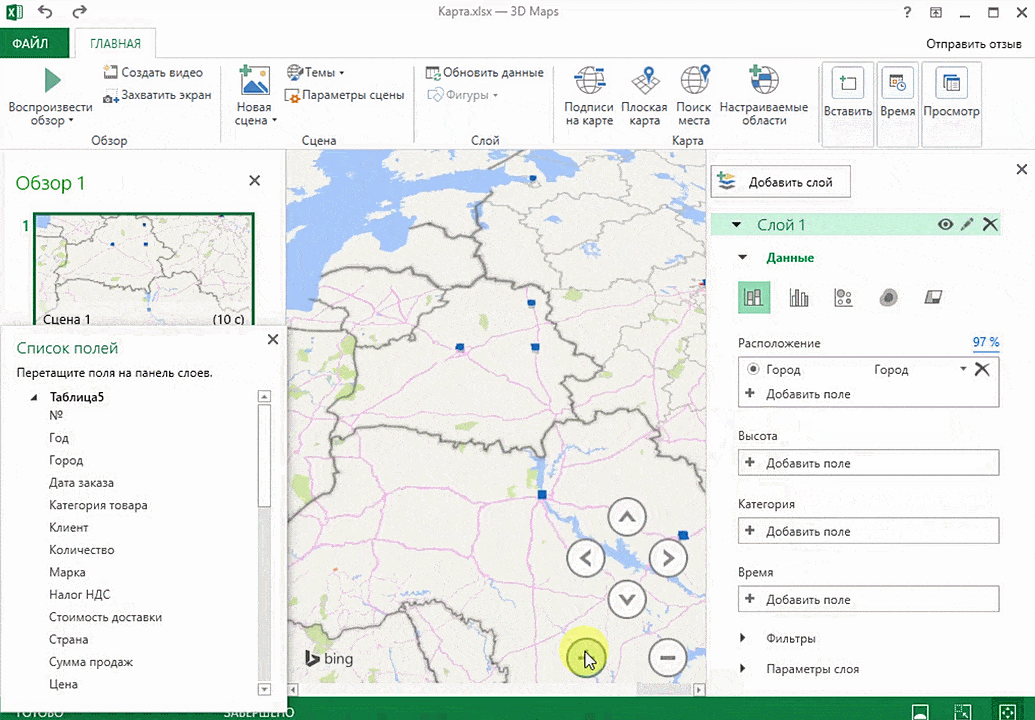
Затем показывается наша карта, где города в таблице представлены в виде точек. Но нам не особо нужно просто наличие информации о населенных пунктах на карте. Нам гораздо важнее видеть ту информацию, которая привязана к ним. Например, те суммы, которые можно показать, как высоту столбика. После того, как мы выполним действия, указанные на этой анимации, при наведении курсора на соответствующий столбик будут отображаться привязанные к нему данные.
Также можно воспользоваться круговой диаграммой, которая является намного более информативной в некоторых случаях. От того, какая общая сумма по величине, зависит размер круга.
Лист прогноза в Excel
Нередко бизнес-процессы зависят от сезонных особенностей. И такие факторы надо обязательно принимать в учет на этапе планирования. Для этого существует специальный инструмент Excel, который понравится вам своей высокой точностью. Он значительно более функциональный, чем все описанные выше методы, какими бы отличными они ни были. Точно так же, очень широкой является сфера его использования – коммерческие, финансовые, маркетинговые и даже государственные структуры.
Важно: чтобы рассчитать прогноз, необходимо получить информацию за предыдущее время. От того, насколько долгосрочные данные, зависит качество прогнозирования. Рекомендуется иметь данные, которые разбиты по одинаковым интервалам (например, поквартально или помесячно).
Как работать с листом прогноза
Чтобы работать с листом прогноза, необходимо выполнять следующие действия:
- Откройте файл, в котором содержится большой объем информации по тем показателям, которые нам надо проанализировать. Например, в течение прошлого года (хотя чем больше, тем лучше).
- Выделите две строки с информацией.
- Перейдите в меню «Данные», и там кликните по кнопке «Лист прогноза».
- После этого откроется диалог, в котором можно выбрать тип визуального представления прогноза: график или гистограмма. Выберите тот, который подходит под вашу ситуацию.
- Установите дату, когда прогноз должен закончиться.
В приводимом нами ниже примере даются сведения за три года – 2011-2013. При этом рекомендуется указывать временные промежутки, а не конкретные числа. То есть, лучше писать март 2013, а не конкретное число типа 7 марта 2013 года. Чтобы исходя из этих данных получить прогноз на 2014 год необходимо получить данных, расположенные в рядах с датой и показателями, которые были на этот момент. Выделяем эти строки.
Затем переходим на вкладку «Данные» и ищем группу «Прогноз». После этого переходим в меню «Лист прогноза». После этого появится окно, в котором снова выбираем способ представления прогноза, а затем устанавливаем дату, к которой прогноз должен быть закончен. После этого нажимаем на «Создать», после чего получаем три варианта прогноза (показываются оранжевой линией).
Быстрый анализ в Excel
Предыдущий способ действительно хорош, потому что позволяет составлять реальные прогнозы, основываясь на статистических показателях. Но этот метод позволяет фактически проводить полноценную бизнес-аналитику. Очень классно, что эта возможность создана максимально эргономичной, поскольку для достижения желаемого результата необходимо совершить буквально несколько действий. Никаких ручных подсчетов, записи каких-либо формул. Достаточно просто выбрать диапазон, который будет анализироваться и задать конечную цель.
Есть возможность прямо в ячейке создавать самые разные диаграммы и микрографики.
Как работать
Итак, чтобы работать, нам надо надо открыть файл, в котором содержится тот набор данных, который надо анализировать и выделить соответствующий диапазон. После того, как мы его выделим, у нас автоматически появится кнопка, дающая возможность составить итоги или же выполнить набор других действий. Называется она быстрым анализом. Также мы можем определить суммы, которые автоматически будут проставлены внизу. Более наглядно посмотреть, как это работает, можете на этой анимации.
Функция быстрого анализа позволяет также по-разному форматировать получившиеся данные. А определить, какие значения больше или меньше, можно непосредственно в ячейках гистограммы, которая появляется после того, как мы настроим этот инструмент. 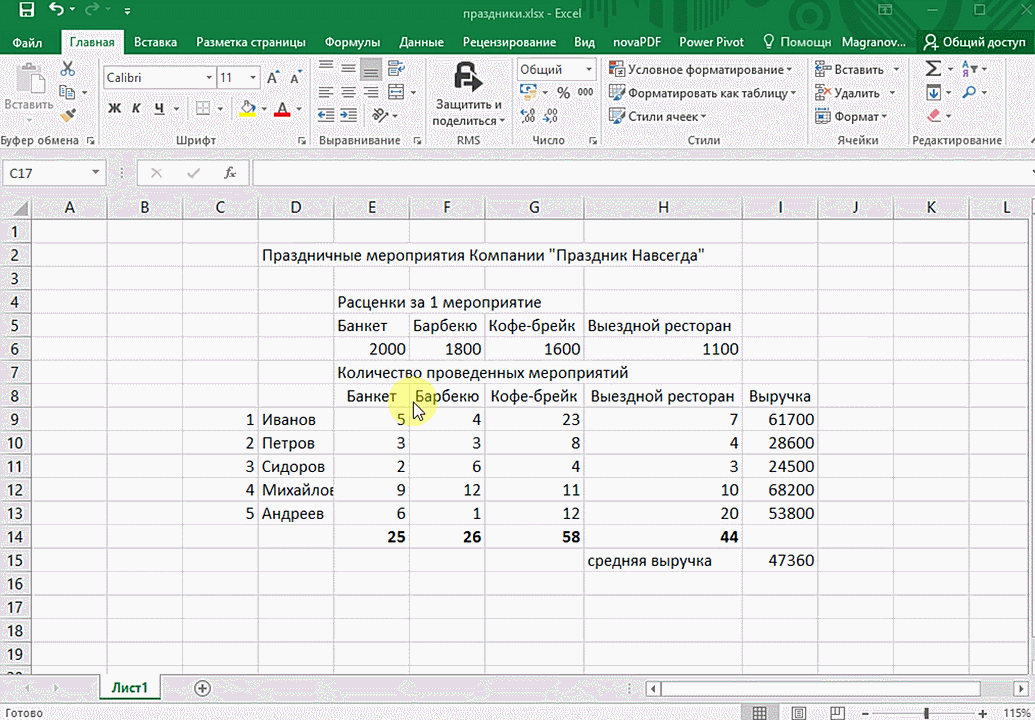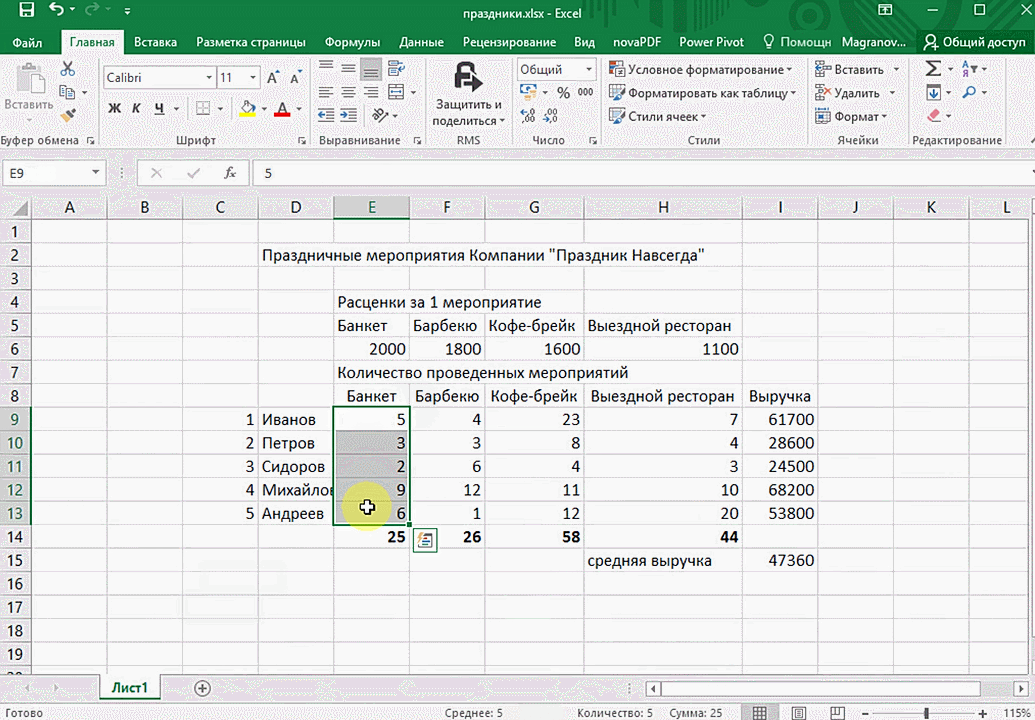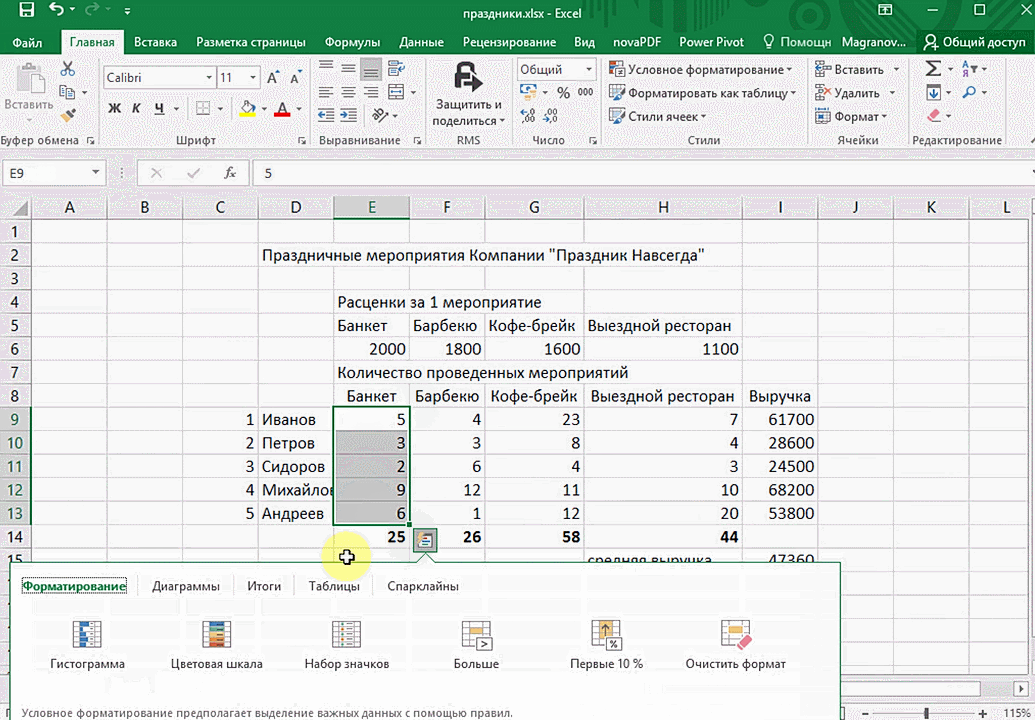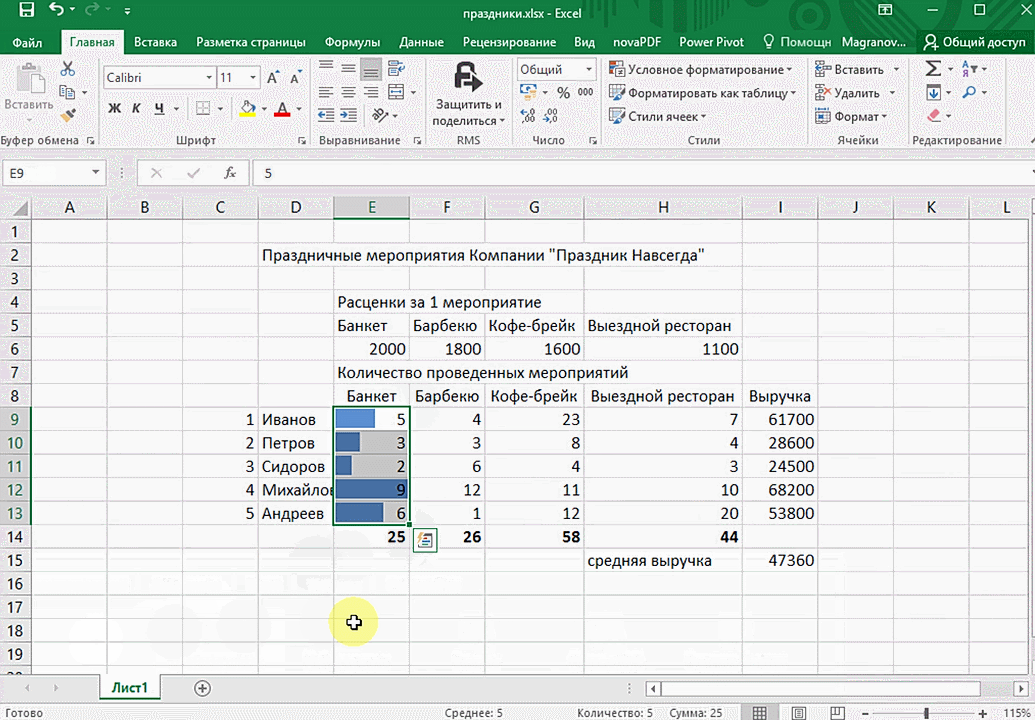
Также пользователь может поставить самые разные маркеры, которые обозначают большие и меньшие значения относительно тех, которые есть в выборке. Так, зеленым цветом будут показываться самые большие значения, а красным – наиболее маленькие.
Очень хочется верить, что эти приемы позволят вам значительно повысить эффективность вашей работы с электронными таблицами и максимально быстро добиться всего, что вы желаете. Как видим, эта программа для работы с электронными таблицами дает очень широкие возможности даже в стандартном функционале. А что уже говорить про дополнения, которых очень много на просторах интернета. Важно только обратить внимание, что все аддоны должны быть тщательно проверены на вирусы, потому что модули, написанные другими людьми, могут содержать вредоносный код. Если же надстройки разработаны компанией Майкрософт, то ее можно использовать смело.
Пакет анализа от Майкрософт – очень функциональная надстройка, которая делает пользователя настоящим профессионалом. Она позволяет выполнить почти любую обработку количественных данных, но она довольно сложная для начинающего пользователя. На официальном сайте справки Майкрософт есть детальная инструкция по тому, как использовать разные виды анализа с помощью этого пакета.
Оцените качество статьи. Нам важно ваше мнение:
Анализ данных в Excel предполагает сама конструкция табличного процессора. Очень многие средства программы подходят для реализации этой задачи.
Excel позиционирует себя как лучший универсальный программный продукт в мире по обработке аналитической информации. От маленького предприятия до крупных корпораций, руководители тратят значительную часть своего рабочего времени для анализа жизнедеятельности их бизнеса. Рассмотрим основные аналитические инструменты в Excel и примеры применения их в практике.
Инструменты анализа Excel
Одним из самых привлекательных анализов данных является «Что-если». Он находится: «Данные»-«Работа с данными»-«Что-если».
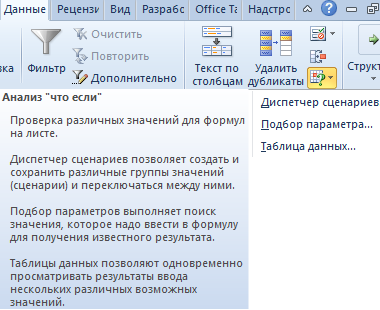
Средства анализа «Что-если»:
- «Подбор параметра». Применяется, когда пользователю известен результат формулы, но неизвестны входные данные для этого результата.
- «Таблица данных». Используется в ситуациях, когда нужно показать в виде таблицы влияние переменных значений на формулы.
- «Диспетчер сценариев». Применяется для формирования, изменения и сохранения разных наборов входных данных и итогов вычислений по группе формул.
- «Поиск решения». Это надстройка программы Excel. Помогает найти наилучшее решение определенной задачи.
Практический пример использования «Что-если» для поиска оптимальных скидок по таблице данных.
Другие инструменты для анализа данных:
Анализировать данные в Excel можно с помощью встроенных функций (математических, финансовых, логических, статистических и т.д.).
Сводные таблицы в анализе данных
Чтобы упростить просмотр, обработку и обобщение данных, в Excel применяются сводные таблицы.
Программа будет воспринимать введенную/вводимую информацию как таблицу, а не простой набор данных, если списки со значениями отформатировать соответствующим образом:
- Перейти на вкладку «Вставка» и щелкнуть по кнопке «Таблица».
- Откроется диалоговое окно «Создание таблицы».
- Указать диапазон данных (если они уже внесены) или предполагаемый диапазон (в какие ячейки будет помещена таблица). Установить флажок напротив «Таблица с заголовками». Нажать Enter.
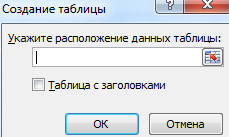
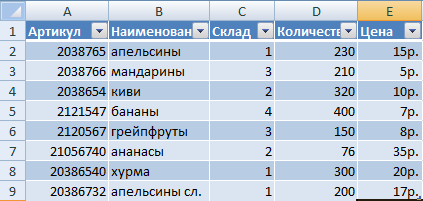
К указанному диапазону применится заданный по умолчанию стиль форматирования. Станет активным инструмент «Работа с таблицами» (вкладка «Конструктор»).
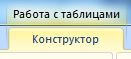
Составить отчет можно с помощью «Сводной таблицы».
- Активизируем любую из ячеек диапазона данных. Щелкаем кнопку «Сводная таблица» («Вставка» — «Таблицы» — «Сводная таблица»).
- В диалоговом окне прописываем диапазон и место, куда поместить сводный отчет (новый лист).
- Открывается «Мастер сводных таблиц». Левая часть листа – изображение отчета, правая часть – инструменты создания сводного отчета.
- Выбираем необходимые поля из списка. Определяемся со значениями для названий строк и столбцов. В левой части листа будет «строиться» отчет.
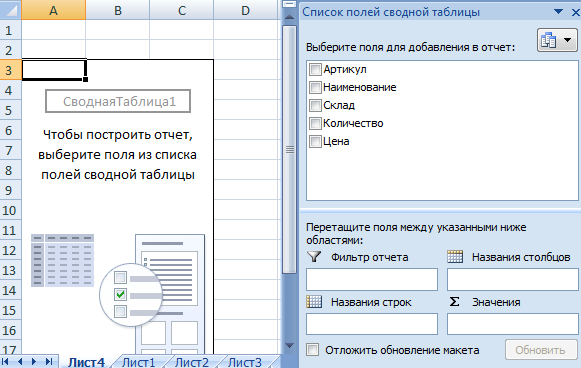
Создание сводной таблицы – это уже способ анализа данных. Более того, пользователь выбирает нужную ему в конкретный момент информацию для отображения. Он может в дальнейшем применять другие инструменты.
Анализ «Что-если» в Excel: «Таблица данных»
Мощное средство анализа данных. Рассмотрим организацию информации с помощью инструмента «Что-если» — «Таблица данных».
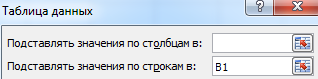
Важные условия:
- данные должны находиться в одном столбце или одной строке;
- формула ссылается на одну входную ячейку.
Процедура создания «Таблицы данных»:
- Заносим входные значения в столбец, а формулу – в соседний столбец на одну строку выше.
- Выделяем диапазон значений, включающий столбец с входными данными и формулой. Переходим на вкладку «Данные». Открываем инструмент «Что-если». Щелкаем кнопку «Таблица данных».
- В открывшемся диалоговом окне есть два поля. Так как мы создаем таблицу с одним входом, то вводим адрес только в поле «Подставлять значения по строкам в». Если входные значения располагаются в строках (а не в столбцах), то адрес будем вписывать в поле «Подставлять значения по столбцам в» и нажимаем ОК.
Анализ предприятия в Excel: примеры
Для анализа деятельности предприятия берутся данные из бухгалтерского баланса, отчета о прибылях и убытках. Каждый пользователь создает свою форму, в которой отражаются особенности фирмы, важная для принятия решений информация.
- скачать систему анализа предприятий;
- скачать аналитическую таблицу финансов;
- таблица рентабельности бизнеса;
- отчет по движению денежных средств;
- пример балльного метода в финансово-экономической аналитике.
Для примера предлагаем скачать финансовый анализ предприятий в таблицах и графиках составленные профессиональными специалистами в области финансово-экономической аналитике. Здесь используются формы бухгалтерской отчетности, формулы и таблицы для расчета и анализа платежеспособности, финансового состояния, рентабельности, деловой активности и т.д.
Содержание
- Использование описательной статистики
- Подключение «Пакета анализа»
- Применение инструмента «Описательная статистика»
- Вопросы и ответы

Пользователи Эксель знают, что данная программа имеет очень широкий набор статистических функций, по уровню которых она вполне может потягаться со специализированными приложениями. Но кроме того, у Excel имеется инструмент, с помощью которого производится обработка данных по целому ряду основных статистических показателей буквально в один клик.
Этот инструмент называется «Описательная статистика». С его помощью можно в очень короткие сроки, использовав ресурсы программы, обработать массив данных и получить о нем информацию по целому ряду статистических критериев. Давайте взглянем, как работает данный инструмент, и остановимся на некоторых нюансах работы с ним.
Использование описательной статистики
Под описательной статистикой понимают систематизацию эмпирических данных по целому ряду основных статистических критериев. Причем на основе полученного результата из этих итоговых показателей можно сформировать общие выводы об изучаемом массиве данных.
В Экселе существует отдельный инструмент, входящий в «Пакет анализа», с помощью которого можно провести данный вид обработки данных. Он так и называется «Описательная статистика». Среди критериев, которые высчитывает данный инструмент следующие показатели:
- Медиана;
- Мода;
- Дисперсия;
- Среднее;
- Стандартное отклонение;
- Стандартная ошибка;
- Асимметричность и др.
Рассмотрим, как работает данный инструмент на примере Excel 2010, хотя данный алгоритм применим также в Excel 2007 и в более поздних версиях данной программы.
Подключение «Пакета анализа»
Как уже было сказано выше, инструмент «Описательная статистика» входит в более широкий набор функций, который принято называть Пакет анализа. Но дело в том, что по умолчанию данная надстройка в Экселе отключена. Поэтому, если вы до сих пор её не включили, то для использования возможностей описательной статистики, придется это сделать.
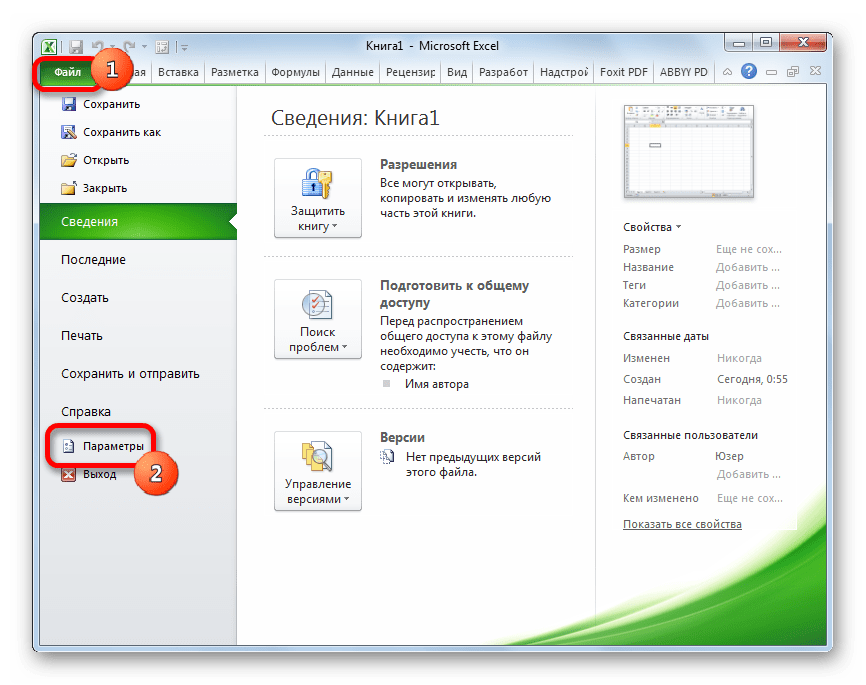
- Переходим во вкладку «Файл». Далее производим перемещение в пункт «Параметры».
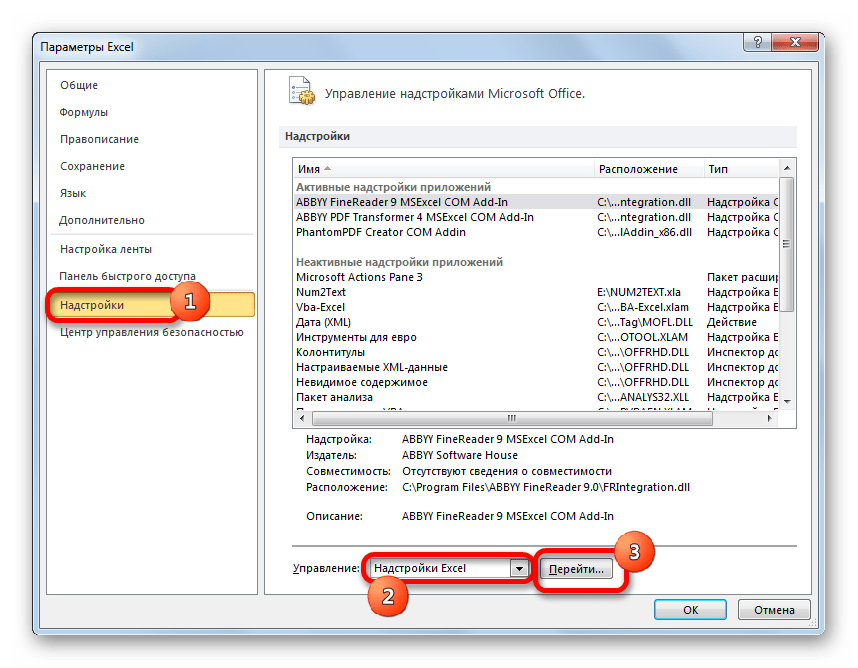
- В активировавшемся окне параметров перемещаемся в подраздел «Надстройки». В самой нижней части окна находится поле «Управление». Нужно в нем переставить переключатель в позицию «Надстройки Excel», если он находится в другом положении. Вслед за этим жмем на кнопку «Перейти…».
- Запускается окно стандартных надстроек Excel. Около наименования «Пакет анализа» ставим флажок. Затем жмем на кнопку «OK».
После вышеуказанных действий надстройка Пакет анализа будет активирована и станет доступной во вкладке «Данные» Эксель. Теперь мы сможем использовать на практике инструменты описательной статистики.
Применение инструмента «Описательная статистика»
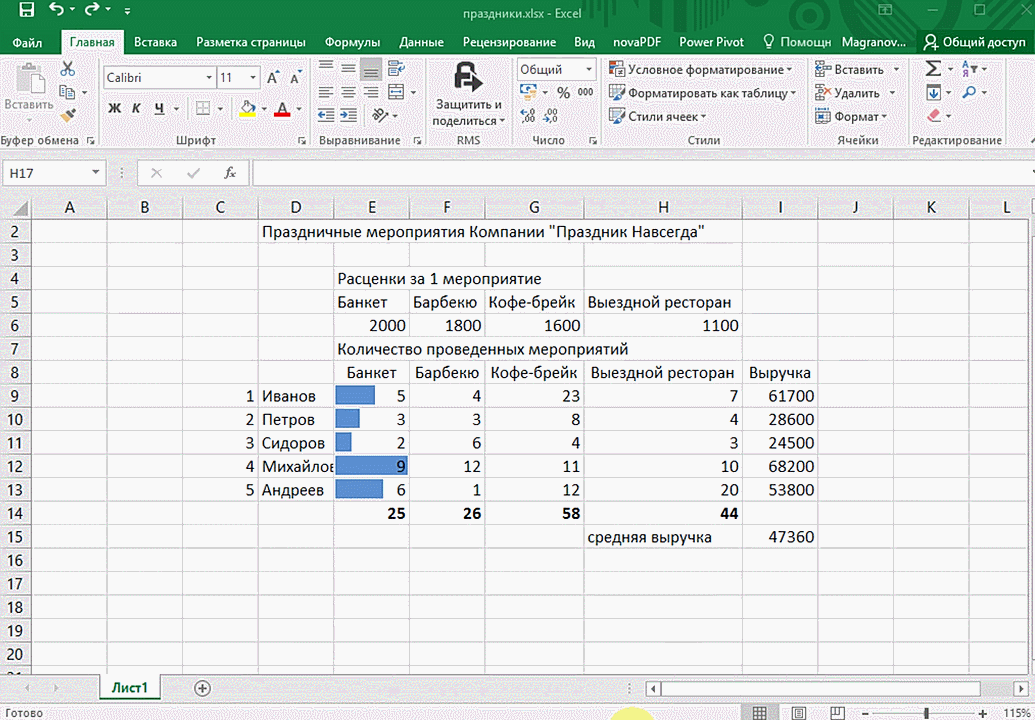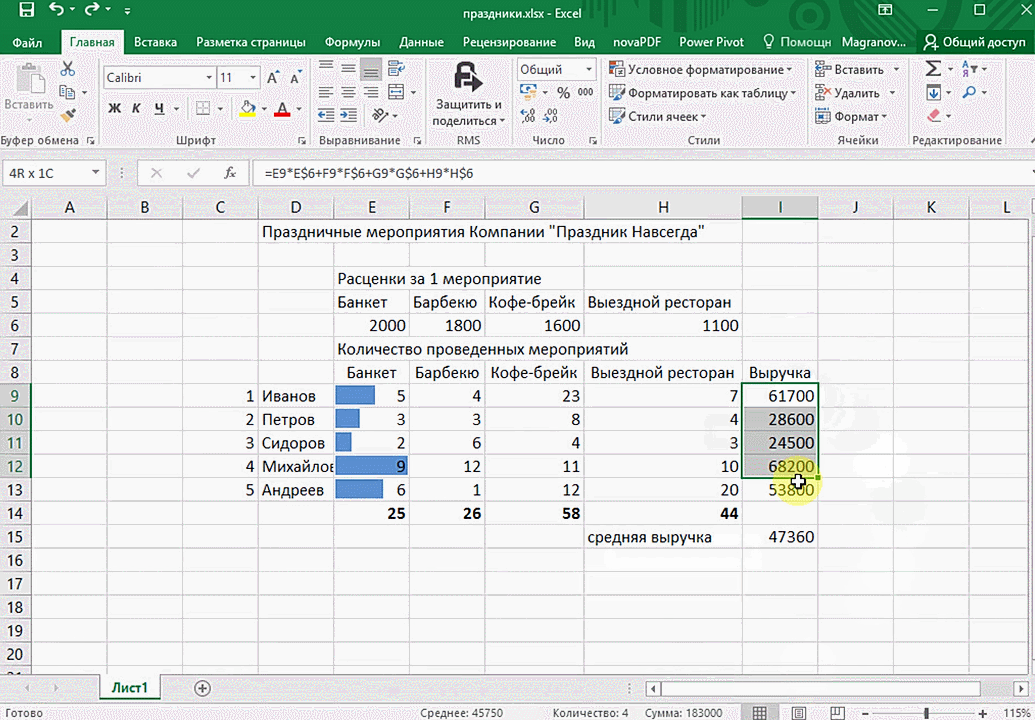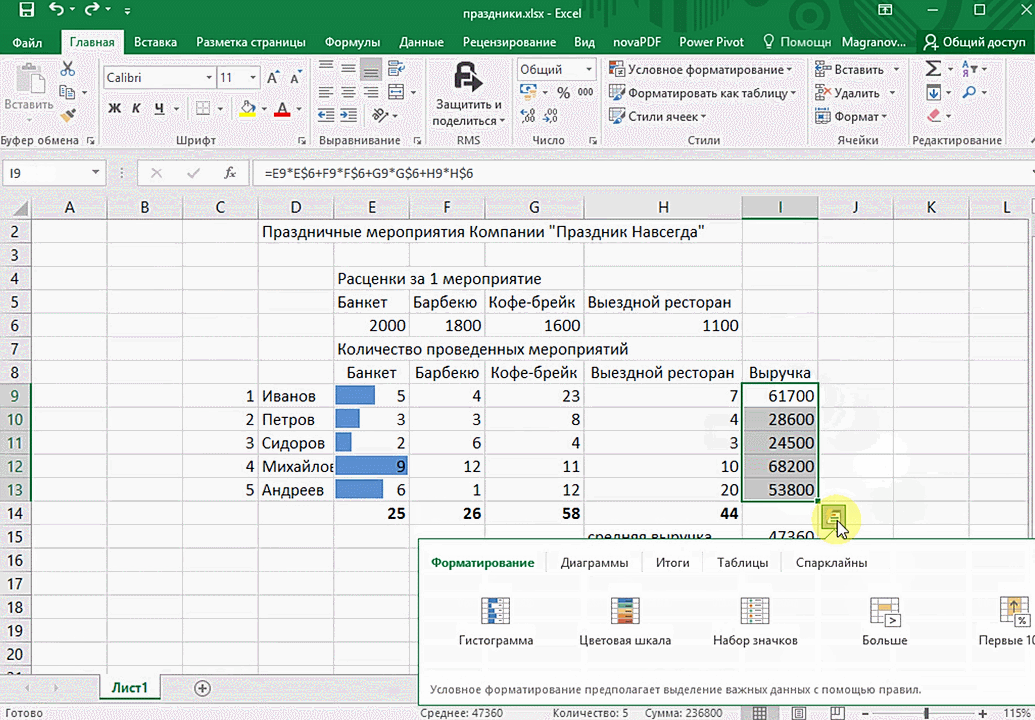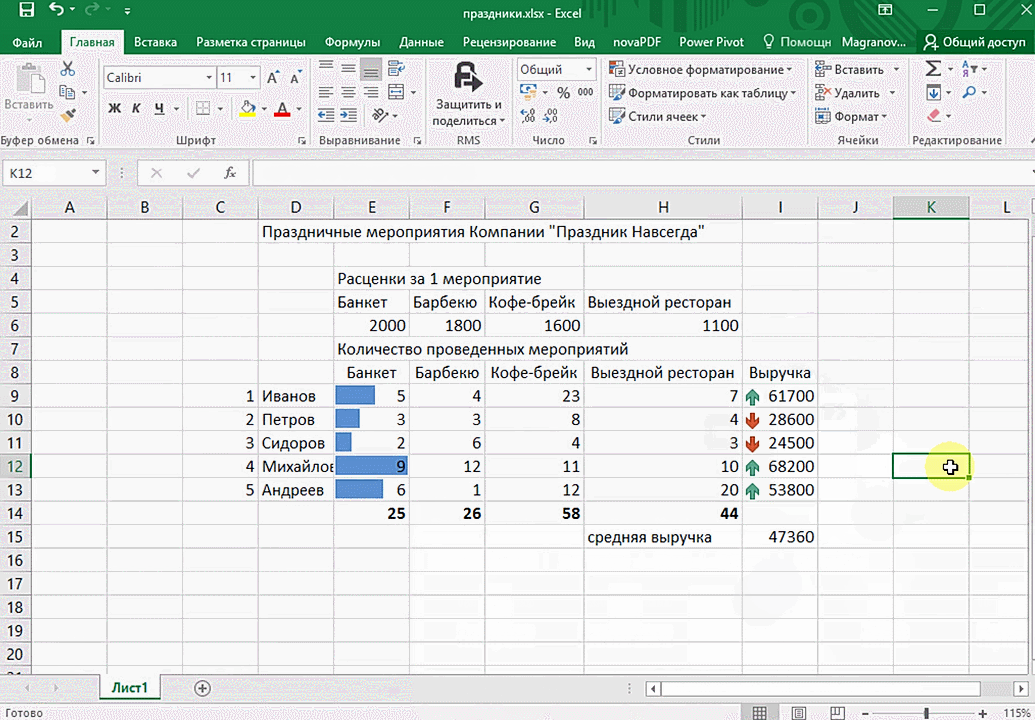
Теперь посмотрим, как инструмент описательная статистика можно применить на практике. Для этих целей используем готовую таблицу.
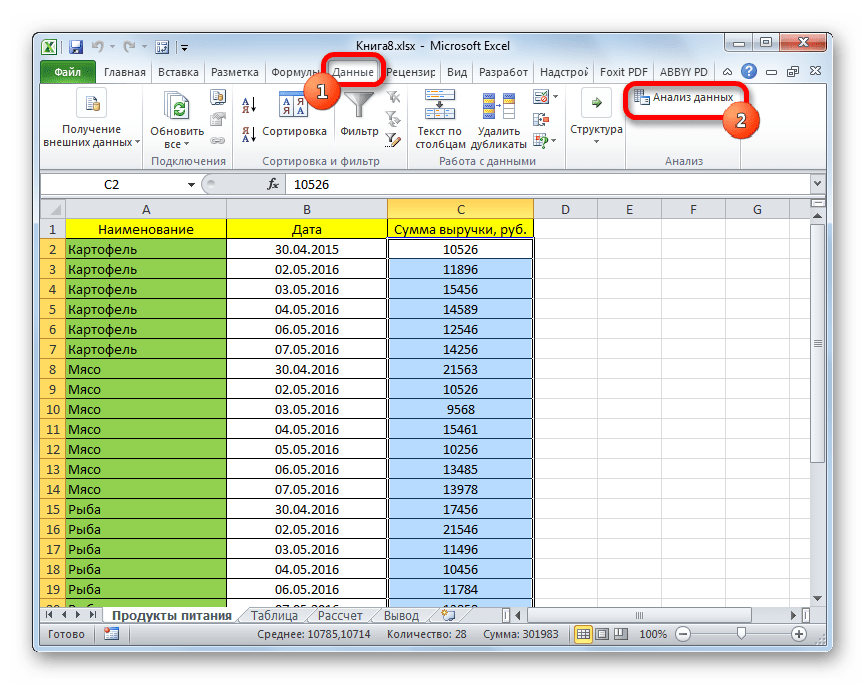
- Переходим во вкладку «Данные» и выполняем щелчок по кнопке «Анализ данных», которая размещена на ленте в блоке инструментов «Анализ».
- Открывается список инструментов, представленных в Пакете анализа. Ищем наименование «Описательная статистика», выделяем его и щелкаем по кнопке «OK».
- После выполнения данных действий непосредственно запускается окно «Описательная статистика».
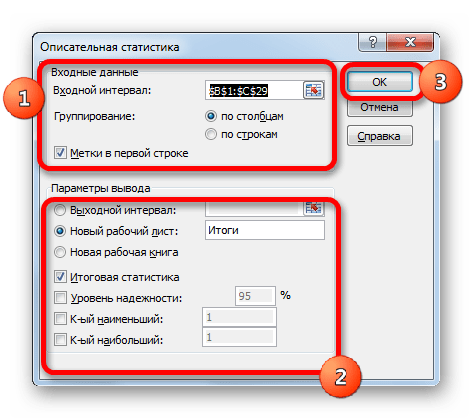
В поле «Входной интервал» указываем адрес диапазона, который будет подвергаться обработке этим инструментом. Причем указываем его вместе с шапкой таблицы. Для того, чтобы внести нужные нам координаты, устанавливаем курсор в указанное поле. Затем, зажав левую кнопку мыши, выделяем на листе соответствующую табличную область. Как видим, её координаты тут же отобразятся в поле. Так как мы захватили данные вместе с шапкой, то около параметра «Метки в первой строке» следует установить флажок. Тут же выбираем тип группирования, переставив переключатель в позицию «По столбцам» или «По строкам». В нашем случае подходит вариант «По столбцам», но в других случаях, возможно, придется выставить переключатель иначе.

Выше мы говорили исключительно о входных данных. Теперь переходим к разбору настроек параметров вывода, которые расположены в этом же окне формирования описательной статистики. Прежде всего, нам нужно определиться, куда именно будут выводиться обработанные данные:
- Выходной интервал;
- Новый рабочий лист;
- Новая рабочая книга.
В первом случае нужно указать конкретный диапазон на текущем листе или его верхнюю левую ячейку, куда будет выводиться обработанная информация. Во втором случае следует указать название конкретного листа данной книги, где будет отображаться результат обработки. Если листа с таким наименованием в данный момент нет, то он будет создан автоматически после того, как вы нажмете на кнопку «OK». В третьем случае никаких дополнительных параметров указывать не нужно, так как данные будут выводиться в отдельном файле Excel (книге). Мы выбираем вывод результатов на новом рабочем листе под названием «Итоги».
Далее, если вы хотите чтобы выводилась также итоговая статистика, то нужно установить флажок около соответствующего пункта. Также можно установить уровень надежности, поставив галочку около соответствующего значения. По умолчанию он будет равен 95%, но его можно изменить, внеся другие числа в поле справа.
Кроме этого, можно установить галочки в пунктах «K-ый наименьший» и «K-ый наибольший», установив значения в соответствующих полях. Но в нашем случае этот параметр так же, как и предыдущий, не является обязательным, поэтому флажки мы не ставим.
После того, как все указанные данные внесены, жмем на кнопку «OK».
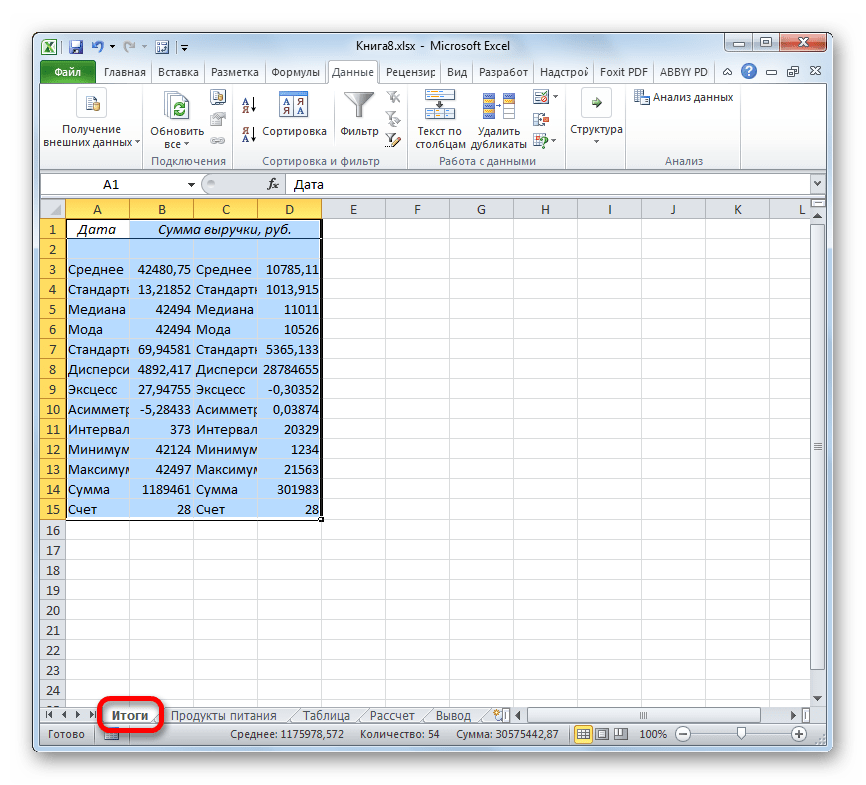
- После выполнения этих действий таблица с описательной статистикой выводится на отдельном листе, который был нами назван «Итоги». Как видим, данные представлены сумбурно, поэтому их следует отредактировать, расширив соответствующие колонки для более удобного просмотра.
- После того, как данные «причесаны» можно приступать к их непосредственному анализу. Как видим, при помощи инструмента описательной статистики были рассчитаны следующие показатели:
- Асимметричность;
- Интервал;
- Минимум;
- Стандартное отклонение;
- Дисперсия выборки;
- Максимум;
- Сумма;
- Эксцесс;
- Среднее;
- Стандартная ошибка;
- Медиана;
- Мода;
- Счет.


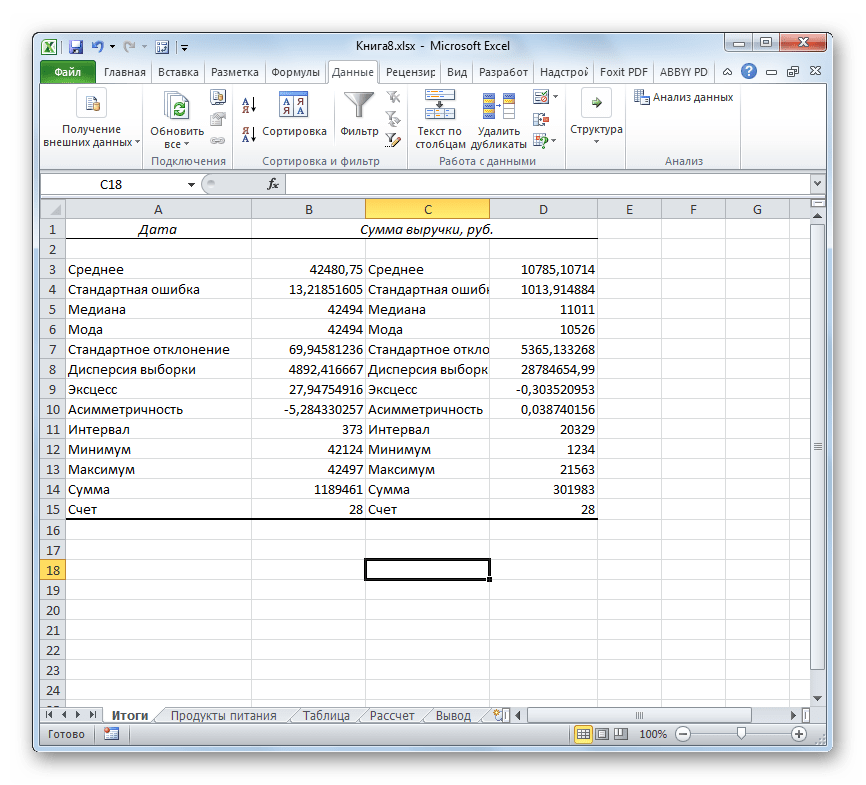
Если какие-то из вышеуказанных данных для конкретного вида анализа не нужны, то их можно удалить, чтобы они не мешали. Далее производится анализ с учетом статистических закономерностей.
Урок: Статистические функции в Excel
Как видим, с помощью инструмента «Описательная статистика» можно сразу получить результат по целому ряду критериев, которые в ином случае рассчитывались с применением отдельно предназначенной для каждого расчета функцией, что заняло бы значительное время у пользователя. А так, все эти расчеты можно получить практически в один клик, использовав соответствующий инструмент — Пакета анализа.
Еще статьи по данной теме:
Помогла ли Вам статья?
Инфоурок
›
Другое
›Презентации›Статистический анализ данных в MS Excel
Скачать материал

Скачать материал




- Сейчас обучается 396 человек из 63 регионов


- Сейчас обучается 268 человек из 64 регионов


Описание презентации по отдельным слайдам:
-

1 слайд
Статистический анализ данных в MS Excel
1. Обзор и характеристика основных статистических функций, входящих в MS Excel.
2. Работа с пакетом анализа данных в MS Excel.
Литература:
1. Г.И. Просветов Анализ данных с помощью Excel. Задачи и решения. М: 2009
2. А.Ю. Козлов, В.С. Мхитарян, В.Ф. Шишов Статистический анализ данных в MS Excel М: 2012 -
2 слайд
Понятие анализа данных
Анализ данных – область математики и информатики, занимающая построением и исследованием наиболее общих математических методов и вычислительных алгоритмов извлечения знаний из экспериментальных данных.
Анализ данных – это процесс исследования, фильтрации, преобразования и моделирования данных с целью извлечения полезной информации и принятия решения. -
3 слайд
Статистические функции MS Excel
Все статистические функции, входящие в MS Excel можно разбить на восемь подразделов:
1.Предварительная обработка данных;
2.Определение характеристик положения;
3.Определение корреляции, ковариации;
4.Определение характеристик рассеивания
5.Интервальное оценивание (определение вероятности попадания дискретной случайной величины в интервал);
6.Определения параметров распределения непрерывной случайной величины;
7.Определение параметров распределения дискретной случайной величины;
8.Построение уравнения регрессии и прогнозирования. -
4 слайд
Предварительная обработка данных
Подсчет количества значений (СЧЕТ).
Определение экстремальных значений совокупности данных (МАКС, МИН)
Подсчет частот из массива данных, попадающих в заданные интервалы (ЧАСТОТА)
Оценка относительного положения точки (ПРОЦЕНТРАНГ)
Определение величины, соответствующей ее относительному положению (ПЕРСЕНТИЛЬ)
Определение числа перестановок (ПЕРЕСТ)
Определение ранга чисел в списке чисел (РАНГ) -
5 слайд
Предварительная обработка данных
Массив данных
СЧЕТ
МАКС
ЧАСТОТА
ПРОЦЕНТРАНГ
ПЕРСЕНТИЛЬ
РАНГ -
6 слайд
Определение характеристик положения
Определение среднего (СРЗНАЧ, СРГЕОМ)
Определение моды в интервале данных или массиве (МОДА)
Определение медианы (МЕДИАНА)
Определение квартилей (КВАРТИЛЬ) -
7 слайд
Определение характеристик положения
Массив данных
СРГЕОМ
СРЗНАЧ
МОДА
МЕДИАНА
КВАРТИЛЬ -
8 слайд
Определение характеристик рассеивания
Определение среднего линейного отклонения (СРОТКЛ)
Определение суммы квадратов отклонения (ДИСП)
Вычисление стандартного (среднего квадратического) отклонения (СТАНДОТКЛОН)
Определения асимметрии распределения (СКОС)
Определения эксцесса (ЭКСЦЕСС) -
9 слайд
Определение характеристик рассеивания
Массив данных
СРОТКЛ
КВАДРОТКЛ
ДИСП
СТАНДОТКЛОН
СКОС
ЭКСЦЕСС -
10 слайд
Зависимость случайных величин
Определение ковариации (КОВАР)
Определение коэффициента корреляции (КОРРЕЛ) -
11 слайд
Зависимость случайных величин
Массив данных
КОВАР
КОРРЕЛ -
12 слайд
Интервальное оценивание
Определение доверительного интервала для среднего (ДОВЕРИТ)
Определение вероятности попадания дискретной случайной величины в интервал (ВЕРОЯТНОСТЬ) -
13 слайд
Интервальное оценивание
Массив данных
ДОВЕРИТ
ВЕРОЯТНОСТЬ -
14 слайд
Определение параметров распределения непрерывных случайных величин
Определение значения функции распределения и функции плотности нормального распределения (НОРМРАСПР)
Определение аргумента по значению функции распределения (НОРМОБР)
Определение вероятности статистики z при проверке гипотизы о равенстве статистической оценки математического ожидания заданному значению (ZТЕСТ)
Определение значений функций распределения отличных от нормальных (ЛОГНОРМРАСП, СТЬЮДРАСП…)
Проверка гипотезы о равенстве дисперсий (ФТЕСТ) -
15 слайд
Определение параметров распределения непрерывных случайных величин
НОРМРАСП
НОРМОБР
Массив данных
ZТЕСТ
ФТЕСТ -
16 слайд
Построение уравнения регрессии и прогнозирование
Определение параметров линейной регрессии (ЛИНЕЙН)
Определение значений результативного признака по линейному уравнению регрессии (ТЕНДЕНЦИЯ)
Определение значения уравнения регрессии вида y=b0+b1x в заданной точке (ПРЕДСКАЗ) -
17 слайд
Построение уравнения регрессии и прогнозирование
ЛИНЕЙН
ТЕНДЕНЦИЯ
Массив данных
ПРЕДСКАЗ -
18 слайд
Работа с пакетом анализа данных в MS Excel.
-
19 слайд
Работа с пакетом анализа данных в MS Excel.
В пакет анализа данных входят следующие инструменты:
1.Генерация случайных чисел
2.Выборка
3.Гистограмма
4.Описательная статистика
5.Скользящее среднее
6.Экспоненциальное сглаживание
7.Ковариционный анализ
8.Корреляционный анализ
9.Двухвыборочный F-тест для дисперсий
10. Двухвыборочныйz-тест для средних
11.Парный двухвыборочный t-тест для средних
12. Двухвыборочный t-тест с одинаковыми дисперсиями
13. Двухвыборочный t-тест с разными дисперсиями
14. Дисперсионный анализ
15. Регрессия
16.Ранг и персентиль
17. Анализ Фурье -
20 слайд
Генерация случайных чисел
Окно инструмента Генерация случайных чисел содержит следующие основные параметры:
-Число переменных При помощи этого параметра можно получать многомерную выборку (количество столбцов)
-Число случайных чисел Определяется число точек данных (число реализаций), которое вы хотите генерировать для каждой переменной
-Случайное рассеивание Вводится произвольное значение, для которого необходимо генерировать случайные числа. Применяется для повторной генерации (повторное получение той же совокупности) -
21 слайд
Выборка
В пакете Анализ данных инструмент Выборка используется для создания выборки из генеральной совокупности, рассматривая входной диапазон как генеральную совокупность -
22 слайд
Гистограмма
Гистограмма применяется для графического изображения интервального вариационного ряда -
23 слайд
Описательная статистика
Описательная статистика использует совокупность методов, позволяющих делать научно обоснованные выводы о числовых параметрах распределения генеральной совокупности по случайной выборке из нее


.Определен...")

Опре...")



Определение коэфф...")













Найдите материал к любому уроку, указав свой предмет (категорию), класс, учебник и тему:
6 208 983 материала в базе
- Выберите категорию:
- Выберите учебник и тему
- Выберите класс:
-
Тип материала:
-
Все материалы
-
Статьи
-
Научные работы
-
Видеоуроки
-
Презентации
-
Конспекты
-
Тесты
-
Рабочие программы
-
Другие методич. материалы
-
Найти материалы
Другие материалы
- 27.12.2020
- 4744
- 2
- 27.12.2020
- 4946
- 11
- 27.12.2020
- 5785
- 13
- 27.12.2020
- 5022
- 9
- 27.12.2020
- 4057
- 1
- 27.12.2020
- 3882
- 0
- 27.12.2020
- 3905
- 1
- 27.12.2020
- 3300
- 4
Вам будут интересны эти курсы:
-
Курс повышения квалификации «Основы туризма и гостеприимства»
-
Курс повышения квалификации «Организация научно-исследовательской работы студентов в соответствии с требованиями ФГОС»
-
Курс повышения квалификации «Формирование компетенций межкультурной коммуникации в условиях реализации ФГОС»
-
Курс повышения квалификации «Экономика предприятия: оценка эффективности деятельности»
-
Курс профессиональной переподготовки «Клиническая психология: теория и методика преподавания в образовательной организации»
-
Курс повышения квалификации «Введение в сетевые технологии»
-
Курс профессиональной переподготовки «Логистика: теория и методика преподавания в образовательной организации»
-
Курс повышения квалификации «Применение MS Word, Excel в финансовых расчетах»
-
Курс повышения квалификации «Основы менеджмента в туризме»
-
Курс повышения квалификации «Психодинамический подход в консультировании»
-
Курс профессиональной переподготовки «Корпоративная культура как фактор эффективности современной организации»
-
Курс профессиональной переподготовки «Деятельность по хранению музейных предметов и музейных коллекций в музеях всех видов»
-
Курс профессиональной переподготовки «Организация системы менеджмента транспортных услуг в туризме»
-
Курс профессиональной переподготовки «Техническая диагностика и контроль технического состояния автотранспортных средств»
-
Настоящий материал опубликован пользователем Гущина Мадина Ивановна. Инфоурок является
информационным посредником и предоставляет пользователям возможность размещать на сайте
методические материалы. Всю ответственность за опубликованные материалы, содержащиеся в них
сведения, а также за соблюдение авторских прав несут пользователи, загрузившие материал на сайтЕсли Вы считаете, что материал нарушает авторские права либо по каким-то другим причинам должен быть удален с
сайта, Вы можете оставить жалобу на материал.Удалить материал
-

- На сайте: 2 года и 3 месяца
- Подписчики: 0
- Всего просмотров: 46993
-
Всего материалов:
217