
Рассмотрим равномерное непрерывное распределение. Вычислим математическое ожидание и дисперсию. Сгенерируем случайные значения с помощью функции MS EXCEL
СЛЧИС()
и надстройки Пакет Анализа, произведем оценку среднего значения и стандартного отклонения.
Равномерно распределенная
на отрезке [a; b] случайная величина имеет
плотность распределения (вероятности)
:

Функция распределения
определяется следующим образом:
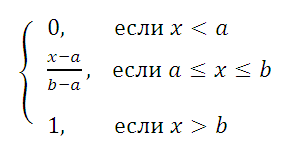
Равномерное непрерывное распределение
(англ.
Continuous
uniform d
istribution
или
Rectangular
distribution
) часто встречается на практике.
Пример1.
Например, известно, что гейзер извергается каждые 50 минут. Найти вероятность, того что турист увидит извержение, если будет ждать у гейзера 20 минут. В соответствии с вышеуказанными формулами вероятность увидеть извержение в течение времени наблюдения равна 20/50=0,4, т.е. 40%.
Пример2.
Симметричный волчок после раскручивания падает набок. Вертикальная ось волчка после падения указывает на определенный угол от 0 до 360 градусов. Найти вероятность, того что ось волчка укажет на сектор от 90 до 180 градусов. Вероятность равна (180-90)/(360-0)=0,25.
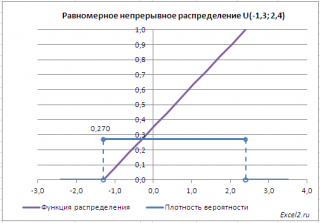
В
файле примера
приведены графики
плотности распределения вероятности
и
интегральной функции распределения
.
Математическое ожидание и дисперсия
Математическое ожидание
для
равномерного непрерывного распределения
вычисляется по формуле =(a+b)/2.
Дисперсия (квадрат стандартного отклонения)
вычисляется по формуле =((b-a)^2)/12.
Генерация случайных чисел
Случайные числа, имеющие
равномерное непрерывное распределение
на отрезке [0; 1), можно сгенерировать с помощью функции MS EXCEL
СЛЧИС()
. В функции нельзя задать нижнюю и верхнюю границу интервала, но записав формулу
=СЛЧИС()*(b-a)+a
можно сгенерировать равномерно распределенные числа на любом интервале [a; b).
Примечание
: Чтобы сгенерировать случайные числа, имеющие
равномерное дискретное распределение
, воспользуйтесь функцией
СЛУЧМЕЖДУ()
.
Сгенерировать случайные числа, извлеченные из
непрерывного равномерного
распределения,
можно также с помощью надстройки
Пакет анализа
.
Сгенерируем массив из 50 чисел из диапазона [3,3; 7,5). Для этого в окне
Генерация случайных чисел
установим следующие параметры (см.
файл примера лист Генерация
):
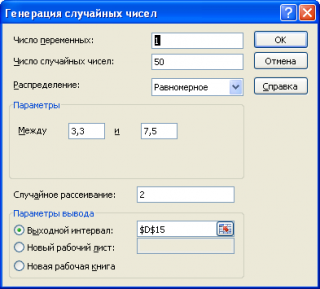
Как видно из рисунка выше, в поле
Случайное рассеивание
установлен необязательный параметр равный 2. Параметр
Случайное рассеивание
может принимать значение от 1 до 32767. Если установить этот параметр, то MS EXCEL будет каждый раз генерировать один и тот же массив чисел, соответствующий этот значению. Этот подход удобен для генерации одинаковых массивов, например, на различных компьютерах.
Оценка среднего и стандартного отклонения
Нижнюю и верхнюю границу интервала возьмем [3,3; 7,5) и разместим их в ячейках
B4:B5
. Сгенерируем 50 чисел (
выборку
) и поместим их в диапазоне
С14:С63
.
Математическое ожидание
этого распределения
=(B4+B5)/2
и равно 5,4.
Стандартное отклонение
распределения равно
=КОРЕНЬ(((B5-B4)^2)/12)=1,21
Чтобы оценить
математическое ожидание
воспользуемся значениями
выборки
=СУММ(C14:C63)/СЧЁТ(C14:C63)
.
Оценить
стандартное отклонение
можно с помощью формулы
=СТАНДОТКЛОН.В(C14:C63)
в MS EXCEL 2010 или
=СТАНДОТКЛОН(C14:C63)
для более ранних версий.
Чтобы оценить
дисперсию
используйте формулу
=ДИСП.В(C14:C63)
в MS EXCEL 2010 или
=ДИСП(C14:C63)
для более ранних версий. Также можно использовать формулу
=СТАНДОТКЛОН.В(C14:C63)^2
.
СОВЕТ
: О других распределениях MS EXCEL можно прочитать в статье
Распределения случайной величины в MS EXCEL
.
17 авг. 2022 г.
читать 2 мин
Равномерное распределение — это такое распределение вероятностей, при котором каждое значение в интервале от a до b будет выбрано с равной вероятностью.
Вероятность того, что мы получим значение между x 1 и x 2 на интервале от a до b , можно найти по формуле:
P(получить значение между x 1 и x 2 ) = (x 2 – x 1 ) / (b – a)
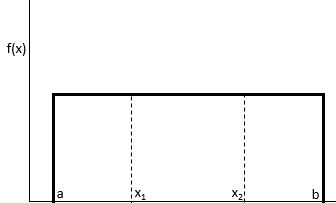
Равномерное распределение обладает следующими свойствами:
- Среднее значение распределения равно μ = (a + b)/2.
- Дисперсия распределения σ 2 = (b – a) 2 / 12
- Стандартное отклонение распределения равно σ = √σ 2
В следующих примерах показано, как рассчитать вероятности для равномерного распределения в Excel.
Примечание. Вы можете перепроверить решение каждого приведенного ниже примера с помощьюКалькулятора равномерного распределения .
Примеры: Равномерное распределение в Excel
Пример 1: Автобус появляется на автобусной остановке каждые 20 минут. Если вы прибываете на автобусную остановку, какова вероятность того, что автобус приедет через 8 минут или меньше?
Решение:
- а: 0 минут
- б: 20 минут
- х 1 : 0 минут
- х 2 : 8 минут
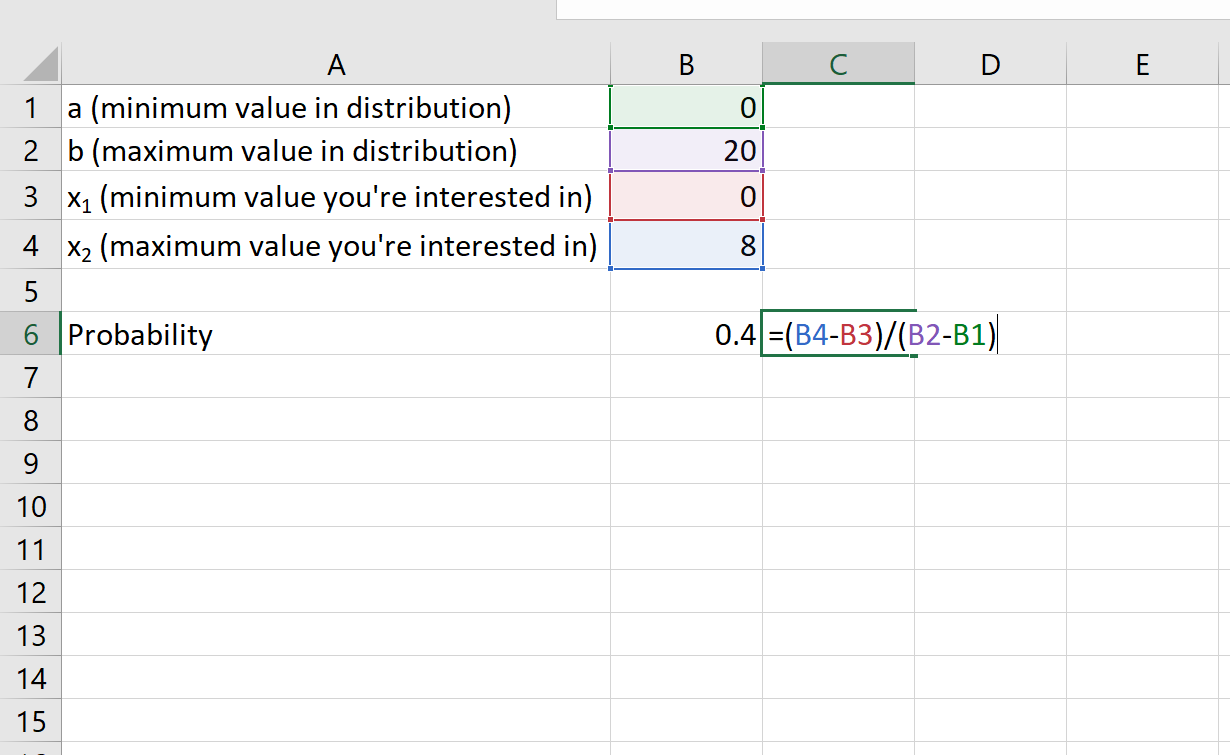
Вероятность того, что автобус приедет через 8 минут или меньше, равна 0,4 .
Пример 2: Вес определенного вида лягушек равномерно распределен между 15 и 25 граммами. Если вы случайно выберете лягушку, какова вероятность того, что она весит от 17 до 19 граммов?
Решение:
- а: 15 грамм
- б: 25 грамм
- х 1 : 17 грамм
- х 2 : 19 грамм
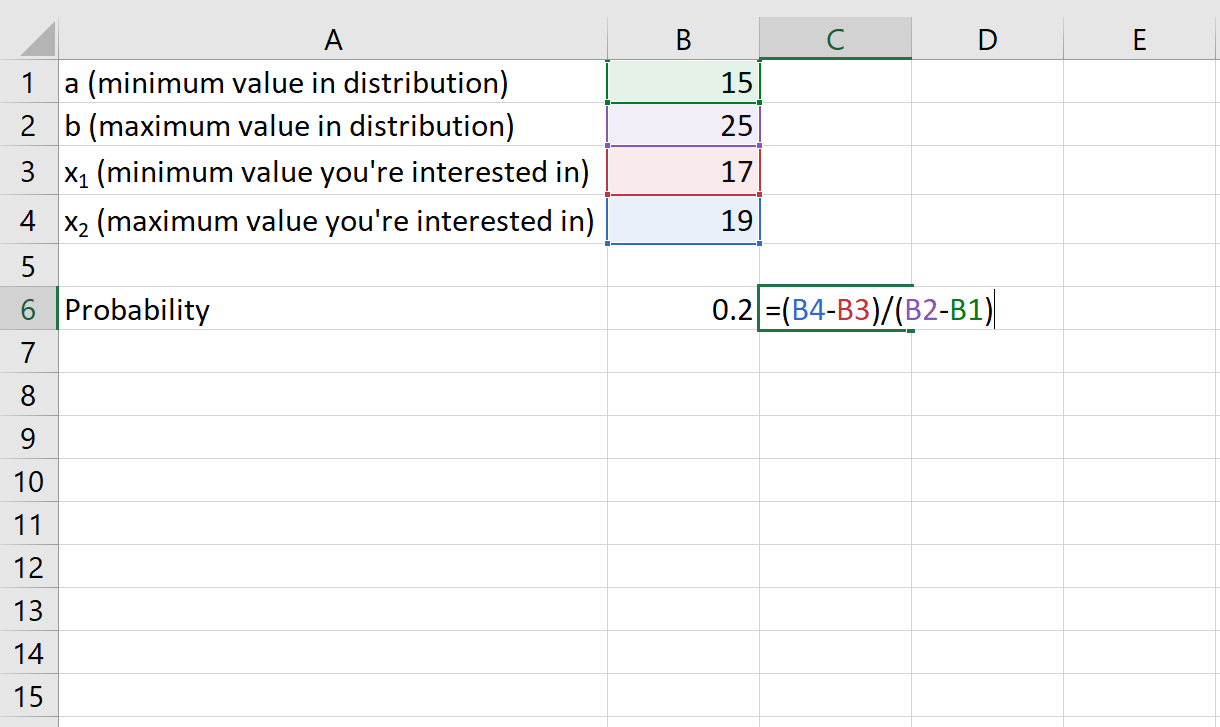
Вероятность того, что лягушка весит от 17 до 19 граммов, равна 0,2 .
Пример 3. Продолжительность игры НБА равномерно распределена между 120 и 170 минутами. Какова вероятность того, что случайно выбранная игра НБА продлится более 150 минут?
Решение:
- а: 120 минут
- б: 170 минут
- х 1 : 150 минут
- х 2 : 170 минут
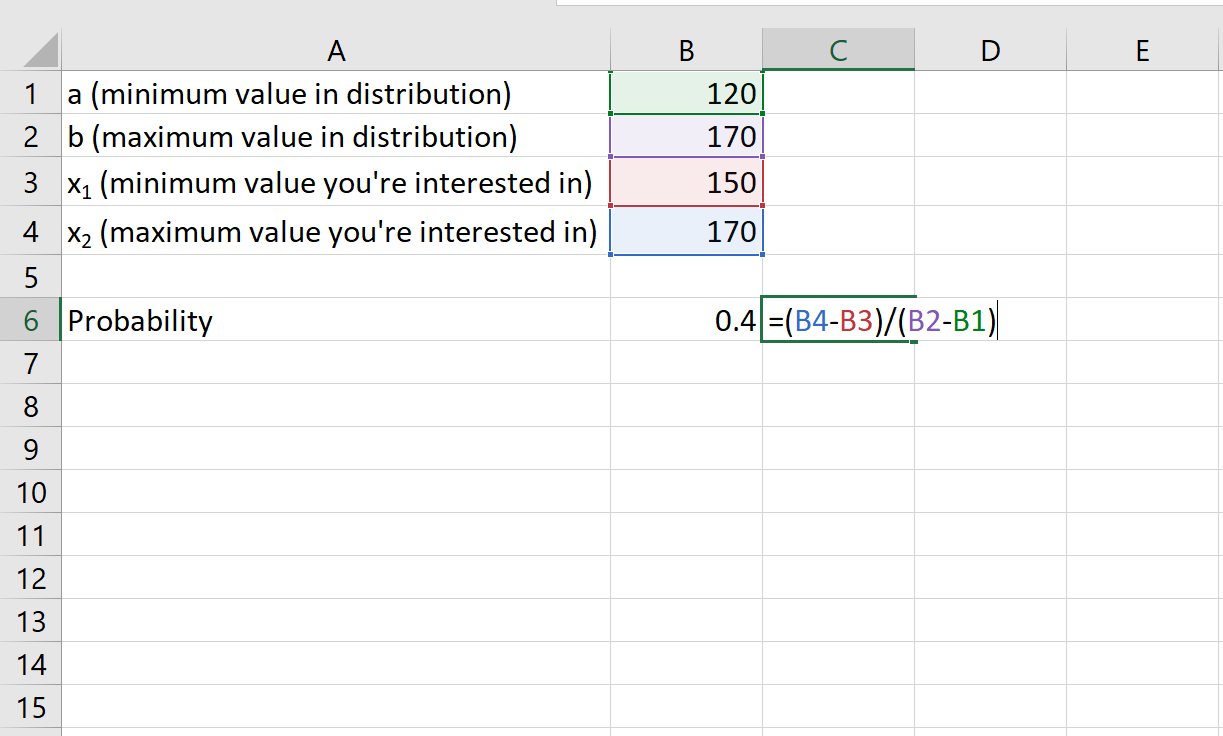
Вероятность того, что случайно выбранная игра НБА продлится более 150 минут, равна 0,4 .
Найдите больше руководств по Excel на этой странице .
Написано
![]()
Замечательно! Вы успешно подписались.
Добро пожаловать обратно! Вы успешно вошли
Вы успешно подписались на кодкамп.
Срок действия вашей ссылки истек.
Ура! Проверьте свою электронную почту на наличие волшебной ссылки для входа.
Успех! Ваша платежная информация обновлена.
Ваша платежная информация не была обновлена.
An example of a probability distribution where all possibilities are equally likely is called a uniform distribution. Since all four suits—heart, club, diamond, and spade—have an equal chance of appearing, a deck of cards has uniform distributions throughout. The chance of receiving either heads or tails in a coin toss is the same, hence a coin also has a uniform distribution. The easiest probability distribution to build in Excel is the uniform distribution. A uniform distribution is a probability distribution in which there is an equal chance of selecting any value between a and b.
The following formula can be used to calculate the probability that a value between x1 and x2 will fall within the range from a to b:
P = (x2 – x1) / (b – a)
Where P is the calculated value between x1 and x2
.png)
For calculating probability, we need:
- a: minimum value in the distribution
- b: maximum value in the distribution
- x1: the minimum value you’re interested in
- x2: the maximum value you’re interested in
Then just by using the formula mentioned above, you can easily calculate the chances or probability of anything.
The characteristics of the uniform distribution are as follows:
The distribution’s average is equal to (a + b) / 2 = μ
The distribution’s variance is σ2 = (b – a)2 / 12
The distribution’s standard deviation is σ = √σ2
How to calculate probability will be clear with the following Example
Example 1: A certain kind of bird has a weight range of 37.25 to 584.32 grams that are equally distributed throughout. What is the chance that a bird will weigh between 100.89 and 477.63 grams if a bird is randomly chosen?
Step 1: First you need to write all these given values in an excel sheet.
a (minimum value in distribution) = 37.25
b (maximum value in distribution) = 584.32
x1 (minimum value you’re interested in) = 100.89
x2 (maximum value you’re interested in) = 477.63

Entering a value in excel
Step 2: For calculating the probability you need to use the formula (x2-x1)/(b-a). Here we enter this enter =(B4-B3)/(B2-B1) because the value of x2 stores in cell B4, the value of x1 stores in cell B3, the value of b stores in cell B2, and the value of a is stored in the cell B1.
.png)
Entering the formula for calculating the chance
Step 3: Press enter then we will get the probability value which is our answer.
.png)
calculated value
Hence, the chance that a bird will weigh between 100.89 and 477.63 grams if a bird is randomly chosen is 0.68865.
Example 2: Every 10 minutes, a bus gets up to a bus stop. What is the chance that the bus will arrive in 5 minutes or less if you arrive at the bus stop?
Step 1: First you need to write all these given values in an excel sheet.
a (minimum value in distribution) = 0
b (maximum value in distribution) = 10
x1 (minimum value you’re interested in) = 0
x2 (maximum value you’re interested in) = 5

Step 2: For calculating the probability you need to use the formula (x2-x1)/(b-a). Here we enter =(B4-B3)/(B2-B1) because the value of x2 stores in cell B4, the value of x1 stores in cell B3, the value of b stores in cell B2, and the value of a is stored in cell B1.
.png)
Step 3: Press enter then we will get the probability value which is our answer.
.png)
Hence, the chance that the bus will arrive in 5 minutes or less if you arrive at the bus stop is 0.5
У нас есть последовательность чисел, состоящая из практически независимых элементов, которые подчиняются заданному распределению. Как правило, равномерному распределению.
Сгенерировать случайные числа в Excel можно разными путями и способами. Рассмотрим только лучше из них.
Функция случайного числа в Excel
- Функция СЛЧИС возвращает случайное равномерно распределенное вещественное число. Оно будет меньше 1, больше или равно 0.
- Функция СЛУЧМЕЖДУ возвращает случайное целое число.
Рассмотрим их использование на примерах.
Выборка случайных чисел с помощью СЛЧИС
Данная функция аргументов не требует (СЛЧИС()).
Чтобы сгенерировать случайное вещественное число в диапазоне от 1 до 5, например, применяем следующую формулу: =СЛЧИС()*(5-1)+1.

Возвращаемое случайное число распределено равномерно на интервале [1,10].
При каждом вычислении листа или при изменении значения в любой ячейке листа возвращается новое случайное число. Если нужно сохранить сгенерированную совокупность, можно заменить формулу на ее значение.
- Щелкаем по ячейке со случайным числом.
- В строке формул выделяем формулу.
- Нажимаем F9. И ВВОД.
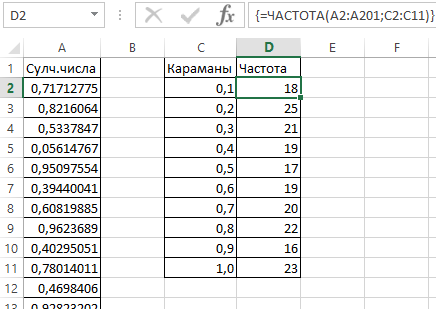
Проверим равномерность распределения случайных чисел из первой выборки с помощью гистограммы распределения.
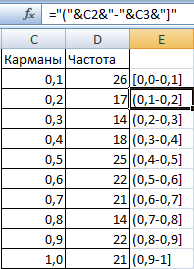
- Сформируем «карманы». Диапазоны, в пределах которых будут находиться значения. Первый такой диапазон – 0-0,1. Для следующих – формула =C2+$C$2.
- Определим частоту для случайных чисел в каждом диапазоне. Используем формулу массива {=ЧАСТОТА(A2:A201;C2:C11)}.
- Сформируем диапазоны с помощью знака «сцепления» (=»[0,0-«&C2&»]»).
- Строим гистограмму распределения 200 значений, полученных с помощью функции СЛЧИС ().
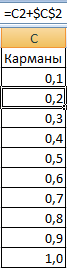
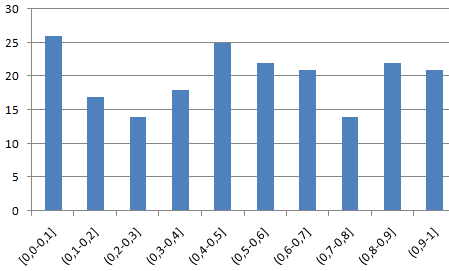
Диапазон вертикальных значений – частота. Горизонтальных – «карманы».
Функция СЛУЧМЕЖДУ
Синтаксис функции СЛУЧМЕЖДУ – (нижняя граница; верхняя граница). Первый аргумент должен быть меньше второго. В противном случае функция выдаст ошибку. Предполагается, что границы – целые числа. Дробную часть формула отбрасывает.
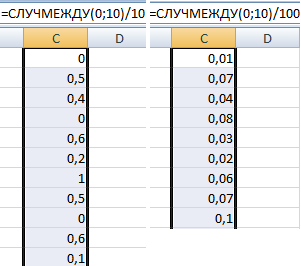
Пример использования функции:
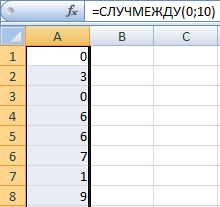
Случайные числа с точностью 0,1 и 0,01:
Как сделать генератор случайных чисел в Excel
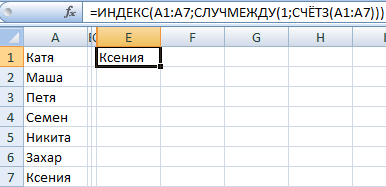
Сделаем генератор случайных чисел с генерацией значения из определенного диапазона. Используем формулу вида: =ИНДЕКС(A1:A10;ЦЕЛОЕ(СЛЧИС()*10)+1).
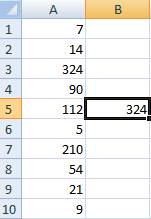
Сделаем генератор случайных чисел в диапазоне от 0 до 100 с шагом 10.
Из списка текстовых значений нужно выбрать 2 случайных. С помощью функции СЛЧИС сопоставим текстовые значения в диапазоне А1:А7 со случайными числами.
Воспользуемся функцией ИНДЕКС для выбора двух случайных текстовых значений из исходного списка.
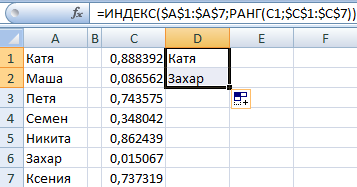
Чтобы выбрать одно случайное значение из списка, применим такую формулу: =ИНДЕКС(A1:A7;СЛУЧМЕЖДУ(1;СЧЁТЗ(A1:A7))).
Генератор случайных чисел нормального распределения
Функции СЛЧИС и СЛУЧМЕЖДУ выдают случайные числа с единым распределением. Любое значение с одинаковой долей вероятности может попасть в нижнюю границу запрашиваемого диапазона и в верхнюю. Получается огромный разброс от целевого значения.
Нормальное распределение подразумевает близкое положение большей части сгенерированных чисел к целевому. Подкорректируем формулу СЛУЧМЕЖДУ и создадим массив данных с нормальным распределением.
Себестоимость товара Х – 100 рублей. Вся произведенная партия подчиняется нормальному распределению. Случайная переменная тоже подчиняется нормальному распределению вероятностей.
При таких условиях среднее значение диапазона – 100 рублей. Сгенерируем массив и построим график с нормальным распределением при стандартном отклонении 1,5 рубля.
Используем функцию: =НОРМОБР(СЛЧИС();100;1,5).
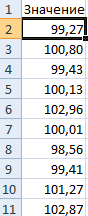
Программа Excel посчитала, какие значения находятся в диапазоне вероятностей. Так как вероятность производства товара с себестоимостью 100 рублей максимальная, формула показывает значения близкие к 100 чаще, чем остальные.
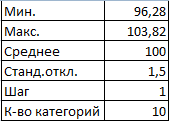
Перейдем к построению графика. Сначала нужно составить таблицу с категориями. Для этого разобьем массив на периоды:
- Определим минимальное и максимальное значение в диапазоне с помощью функций МИН и МАКС.
- Укажем величину каждого периода либо шаг. В нашем примере – 1.
- Количество категорий – 10.
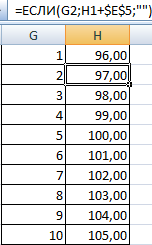
- Нижняя граница таблицы с категориями – округленное вниз ближайшее кратное число. В ячейку Н1 вводим формулу =ОКРВНИЗ(E1;E5).
- В ячейке Н2 и последующих формула будет выглядеть следующим образом: =ЕСЛИ(G2;H1+$E$5;»»). То есть каждое последующее значение будет увеличено на величину шага.
- Посчитаем количество переменных в заданном промежутке. Используем функцию ЧАСТОТА. Формула будет выглядеть так:
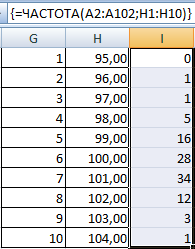
На основе полученных данных сможем сформировать диаграмму с нормальным распределением. Ось значений – число переменных в промежутке, ось категорий – периоды.
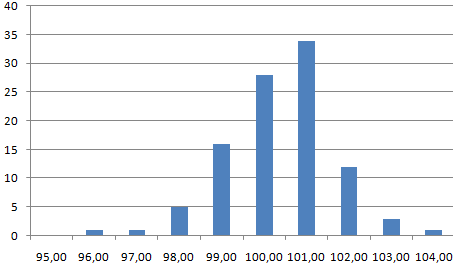
График с нормальным распределением готов. Как и должно быть, по форме он напоминает колокол.
Сделать то же самое можно гораздо проще. С помощью пакета «Анализ данных». Выбираем «Генерацию случайных чисел».
О том как подключить стандартную настройку «Анализ данных» читайте здесь.
Заполняем параметры для генерации. Распределение – «нормальное».
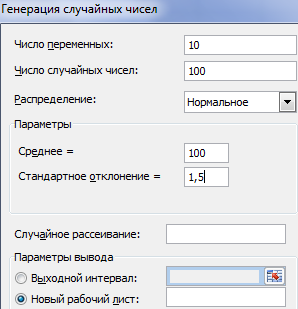
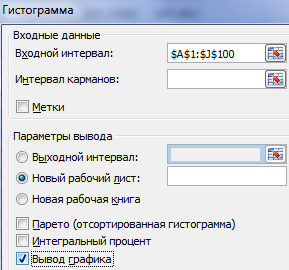
Жмем ОК. Получаем набор случайных чисел. Снова вызываем инструмент «Анализ данных». Выбираем «Гистограмма». Настраиваем параметры. Обязательно ставим галочку «Вывод графика».
Получаем результат:
Скачать генератор случайных чисел в Excel
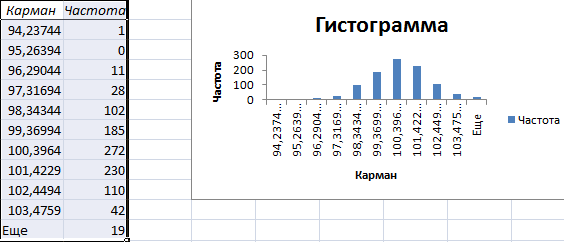
График с нормальным распределением в Excel построен.
В статье подробно показано, что такое нормальный закон распределения случайной величины и как им пользоваться при решении практически задач.
Нормальное распределение в статистике
История закона насчитывает 300 лет. Первым открывателем стал Абрахам де Муавр, который придумал аппроксимацию биномиального распределения еще 1733 году. Через много лет Карл Фридрих Гаусс (1809 г.) и Пьер-Симон Лаплас (1812 г.) вывели математические функции.
Лаплас также обнаружил замечательную закономерность и сформулировал центральную предельную теорему (ЦПТ), согласно которой сумма большого количества малых и независимых величин имеет нормальное распределение.
Нормальный закон не является фиксированным уравнением зависимости одной переменной от другой. Фиксируется только характер этой зависимости. Конкретная форма распределения задается специальными параметрами. Например, у = аx + b – это уравнение прямой. Однако где конкретно она проходит и под каким наклоном, определяется параметрами а и b. Также и с нормальным распределением. Ясно, что это функция, которая описывает тенденцию высокой концентрации значений около центра, но ее точная форма задается специальными параметрами.
Кривая нормального распределения Гаусса имеет следующий вид.

График нормального распределения напоминает колокол, поэтому можно встретить название колоколообразная кривая. У графика имеется «горб» в середине и резкое снижение плотности по краям. В этом заключается суть нормального распределения. Вероятность того, что случайная величина окажется около центра гораздо выше, чем то, что она сильно отклонится от середины.

На рисунке выше изображены два участка под кривой Гаусса: синий и зеленый. Основания, т.е. интервалы, у обоих участков равны. Но заметно отличаются высоты. Синий участок удален от центра, и имеет существенно меньшую высоту, чем зеленый, который находится в самом центре распределения. Следовательно, отличаются и площади, то бишь вероятности попадания в обозначенные интервалы.
Формула нормального распределения (плотности) следующая.
![]()
Формула состоит из двух математических констант:
π – число пи 3,142;
е – основание натурального логарифма 2,718;
двух изменяемых параметров, которые задают форму конкретной кривой:
m – математическое ожидание (в различных источниках могут использоваться другие обозначения, например, µ или a);
σ2 – дисперсия;
ну и сама переменная x, для которой высчитывается плотность вероятности.
Конкретная форма нормального распределения зависит от 2-х параметров: математического ожидания (m) и дисперсии (σ2). Кратко обозначается N(m, σ2) или N(m, σ). Параметр m (матожидание) определяет центр распределения, которому соответствует максимальная высота графика. Дисперсия σ2 характеризует размах вариации, то есть «размазанность» данных.
Параметр математического ожидания смещает центр распределения вправо или влево, не влияя на саму форму кривой плотности.

А вот дисперсия определяет остроконечность кривой. Когда данные имеют малый разброс, то вся их масса концентрируется у центра. Если же у данных большой разброс, то они «размазываются» по широкому диапазону.

Плотность распределения не имеет прямого практического применения. Для расчета вероятностей нужно проинтегрировать функцию плотности.
Вероятность того, что случайная величина окажется меньше некоторого значения x, определяется функцией нормального распределения:
![]()
Используя математические свойства любого непрерывного распределения, несложно рассчитать и любые другие вероятности, так как
P(a ≤ X < b) = Ф(b) – Ф(a)
Стандартное нормальное распределение
Нормальное распределение зависит от параметров средней и дисперсии, из-за чего плохо видны его свойства. Хорошо бы иметь некоторый эталон распределения, не зависящий от масштаба данных. И он существует. Называется стандартным нормальным распределением. На самом деле это обычное нормальное нормальное распределение, только с параметрами математического ожидания 0, а дисперсией – 1, кратко записывается N(0, 1).
Любое нормальное распределение легко превращается в стандартное путем нормирования:
![]()
где z – новая переменная, которая используется вместо x;
m – математическое ожидание;
σ – стандартное отклонение.
Для выборочных данных берутся оценки:
![]()
Среднее арифметическое и дисперсия новой переменной z теперь также равны 0 и 1 соответственно. В этом легко убедиться с помощью элементарных алгебраических преобразований.
В литературе встречается название z-оценка. Это оно самое – нормированные данные. Z-оценку можно напрямую сравнивать с теоретическими вероятностями, т.к. ее масштаб совпадает с эталоном.
Посмотрим теперь, как выглядит плотность стандартного нормального распределения (для z-оценок). Напомню, что функция Гаусса имеет вид:
![]()
Подставим вместо (x-m)/σ букву z, а вместо σ – единицу, получим функцию плотности стандартного нормального распределения:
![]()
График плотности:

Центр, как и ожидалось, находится в точке 0. В этой же точке функция Гаусса достигает своего максимума, что соответствует принятию случайной величиной своего среднего значения (т.е. x-m=0). Плотность в этой точке равна 0,3989, что можно посчитать даже в уме, т.к. e0=1 и остается рассчитать только соотношение 1 на корень из 2 пи.
Таким образом, по графику хорошо видно, что значения, имеющие маленькие отклонения от средней, выпадают чаще других, а те, которые сильно отдалены от центра, встречаются значительно реже. Шкала оси абсцисс измеряется в стандартных отклонениях, что позволяет отвязаться от единиц измерения и получить универсальную структуру нормального распределения. Кривая Гаусса для нормированных данных отлично демонстрирует и другие свойства нормального распределения. Например, что оно является симметричным относительно оси ординат. В пределах ±1σ от средней арифметической сконцентрирована большая часть всех значений (прикидываем пока на глазок). В пределах ±2σ находятся большинство данных. В пределах ±3σ находятся почти все данные. Последнее свойство широко известно под названием правило трех сигм для нормального распределения.
Функция стандартного нормального распределения позволяет рассчитывать вероятности.
![]()
Понятное дело, вручную никто не считает. Все подсчитано и размещено в специальных таблицах, которые есть в конце любого учебника по статистике.
Таблица нормального распределения
Таблицы нормального распределения встречаются двух типов:
— таблица плотности;
— таблица функции (интеграла от плотности).
Таблица плотности используется редко. Тем не менее, посмотрим, как она выглядит. Допустим, нужно получить плотность для z = 1, т.е. плотность значения, отстоящего от матожидания на 1 сигму. Ниже показан кусок таблицы.

В зависимости от организации данных ищем нужное значение по названию столбца и строки. В нашем примере берем строку 1,0 и столбец 0, т.к. сотых долей нет. Искомое значение равно 0,2420 (0 перед 2420 опущен).
Функция Гаусса симметрична относительно оси ординат. Поэтому φ(z)= φ(-z), т.е. плотность для 1 тождественна плотности для -1, что отчетливо видно на рисунке.

Чтобы не тратить зря бумагу, таблицы печатают только для положительных значений.
На практике чаще используют значения функции стандартного нормального распределения, то есть вероятности для различных z.
В таких таблицах также содержатся только положительные значения. Поэтому для понимания и нахождения любых нужных вероятностей следует знать свойства стандартного нормального распределения.
Функция Ф(z) симметрична относительно своего значения 0,5 (а не оси ординат, как плотность). Отсюда справедливо равенство:
![]()
Это факт показан на картинке:

Значения функции Ф(-z) и Ф(z) делят график на 3 части. Причем верхняя и нижняя части равны (обозначены галочками). Для того, чтобы дополнить вероятность Ф(z) до 1, достаточно добавить недостающую величину Ф(-z). Получится равенство, указанное чуть выше.
Если нужно отыскать вероятность попадания в интервал (0; z), то есть вероятность отклонения от нуля в положительную сторону до некоторого количества стандартных отклонений, достаточно от значения функции стандартного нормального распределения отнять 0,5:
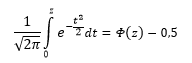
Для наглядности можно взглянуть на рисунок.

На кривой Гаусса, эта же ситуация выглядит как площадь от центра вправо до z.

Довольно часто аналитика интересует вероятность отклонения в обе стороны от нуля. А так как функция симметрична относительно центра, предыдущую формулу нужно умножить на 2:

Рисунок ниже.

Под кривой Гаусса это центральная часть, ограниченная выбранным значением –z слева и z справа.

Указанные свойства следует принять во внимание, т.к. табличные значения редко соответствуют интересующему интервалу.
Для облегчения задачи в учебниках обычно публикуют таблицы для функции вида:

Если нужна вероятность отклонения в обе стороны от нуля, то, как мы только что убедились, табличное значение для данной функции просто умножается на 2.
Теперь посмотрим на конкретные примеры. Ниже показана таблица стандартного нормального распределения. Найдем табличные значения для трех z: 1,64, 1,96 и 3.

Как понять смысл этих чисел? Начнем с z=1,64, для которого табличное значение составляет 0,4495. Проще всего пояснить смысл на рисунке.

То есть вероятность того, что стандартизованная нормально распределенная случайная величина попадет в интервал от 0 до 1,64, равна 0,4495. При решении задач обычно нужно рассчитать вероятность отклонения в обе стороны, поэтому умножим величину 0,4495 на 2 и получим примерно 0,9. Занимаемая площадь под кривой Гаусса показана ниже.

Таким образом, 90% всех нормально распределенных значений попадает в интервал ±1,64σ от средней арифметической. Я не случайно выбрал значение z=1,64, т.к. окрестность вокруг средней арифметической, занимающая 90% всей площади, иногда используется для проверки статистических гипотез и расчета доверительных интервалов. Если проверяемое значение не попадает в обозначенную область, то его наступление маловероятно (всего 10%).
Для проверки гипотез, однако, чаще используется интервал, накрывающий 95% всех значений. Половина вероятности от 0,95 – это 0,4750 (см. второе выделенное в таблице значение).

Для этой вероятности z=1,96. Т.е. в пределах почти ±2σ от средней находится 95% значений. Только 5% выпадают за эти пределы.

Еще одно интересное и часто используемое табличное значение соответствует z=3, оно равно по нашей таблице 0,4986. Умножим на 2 и получим 0,997. Значит, в рамках ±3σ от средней арифметической заключены почти все значения.

Так выглядит правило 3 сигм для нормального распределения на диаграмме.
С помощью статистических таблиц можно получить любую вероятность. Однако этот метод очень медленный, неудобный и сильно устарел. Сегодня все делается на компьютере. Далее переходим к практике расчетов в Excel.
В Excel есть несколько функций для подсчета вероятностей или обратных значений нормального распределения.

Функция НОРМ.СТ.РАСП
Функция НОРМ.СТ.РАСП предназначена для расчета плотности ϕ(z) или вероятности Φ(z) по нормированным данным (z).
=НОРМ.СТ.РАСП(z;интегральная)
z – значение стандартизованной переменной
интегральная – если 0, то рассчитывается плотность ϕ(z), если 1 – значение функции Ф(z), т.е. вероятность P(Z<z).
Рассчитаем плотность и значение функции для различных z: -3, -2, -1, 0, 1, 2, 3 (их укажем в ячейке А2).
Для расчета плотности потребуется формула =НОРМ.СТ.РАСП(A2;0). На диаграмме ниже – это красная точка.
Для расчета значения функции =НОРМ.СТ.РАСП(A2;1). На диаграмме – закрашенная площадь под нормальной кривой.

В реальности чаще приходится рассчитывать вероятность того, что случайная величина не выйдет за некоторые пределы от средней (в среднеквадратичных отклонениях, соответствующих переменной z), т.е. P(|Z|<z).

Определим, чему равна вероятность попадания случайной величины в пределы ±1z, ±2z и ±3z от нуля. Потребуется формула 2Ф(z)-1, в Excel =2*НОРМ.СТ.РАСП(A2;1)-1.

На диаграмме отлично видны основные основные свойства нормального распределения, включая правило трех сигм. Функция НОРМ.СТ.РАСП – это автоматическая таблица значений функции нормального распределения в Excel.
Может стоять и обратная задача: по имеющейся вероятности P(Z<z) найти стандартизованную величину z ,то есть квантиль стандартного нормального распределения.
Функция НОРМ.СТ.ОБР
НОРМ.СТ.ОБР рассчитывает обратное значение функции стандартного нормального распределения. Синтаксис состоит из одного параметра:
=НОРМ.СТ.ОБР(вероятность)
вероятность – это вероятность.
Данная формула используется так же часто, как и предыдущая, ведь по тем же таблицам искать приходится не только вероятности, но и квантили.

Например, при расчете доверительных интервалов задается доверительная вероятность, по которой нужно рассчитать величину z.

Учитывая то, что доверительный интервал состоит из верхней и нижней границы и то, что нормальное распределение симметрично относительно нуля, достаточно получить верхнюю границу (положительное отклонение). Нижняя граница берется с отрицательным знаком. Обозначим доверительную вероятность как γ (гамма), тогда верхняя граница доверительного интервала рассчитывается по следующей формуле.
![]()
Рассчитаем в Excel значения z (что соответствует отклонению от средней в сигмах) для нескольких вероятностей, включая те, которые наизусть знает любой статистик: 90%, 95% и 99%. В ячейке B2 укажем формулу: =НОРМ.СТ.ОБР((1+A2)/2). Меняя значение переменной (вероятности в ячейке А2) получим различные границы интервалов.

Доверительный интервал для 95% равен 1,96, то есть почти 2 среднеквадратичных отклонения. Отсюда легко даже в уме оценить возможный разброс нормальной случайной величины. В общем, доверительным вероятностям 90%, 95% и 99% соответствуют доверительные интервалы ±1,64, ±1,96 и ±2,58 σ.
В целом функции НОРМ.СТ.РАСП и НОРМ.СТ.ОБР позволяют произвести любой расчет, связанный с нормальным распределением. Но, чтобы облегчить и уменьшить количество действий, в Excel есть несколько других функций. Например, для расчета доверительных интервалов средней можно использовать ДОВЕРИТ.НОРМ. Для проверки статистической гипотезы о средней арифметической есть формула Z.ТЕСТ.
Рассмотрим еще пару полезных формул с примерами.
Функция НОРМ.РАСП
Функция НОРМ.РАСП отличается от НОРМ.СТ.РАСП лишь тем, что ее используют для обработки данных любого масштаба, а не только нормированных. Параметры нормального распределения указываются в синтаксисе.
=НОРМ.РАСП(x;среднее;стандартное_откл;интегральная)
x – значение (или ссылка на ячейку), для которого рассчитывается плотность или значение функции нормального распределения
среднее – математическое ожидание, используемое в качестве первого параметра модели нормального распределения
стандартное_откл – среднеквадратичное отклонение – второй параметр модели
интегральная – если 0, то рассчитывается плотность, если 1 – то значение функции, т.е. P(X<x).
Например, плотность для значения 15, которое извлекли из нормальной выборки с матожиданием 10, стандартным отклонением 3, рассчитывается так:

Если последний параметр поставить 1, то получим вероятность того, что нормальная случайная величина окажется меньше 15 при заданных параметрах распределения. Таким образом, вероятности можно рассчитывать напрямую по исходным данным.
Функция НОРМ.ОБР
Это квантиль нормального распределения, т.е. значение обратной функции. Синтаксис следующий.
=НОРМ.ОБР(вероятность;среднее;стандартное_откл)
вероятность – вероятность
среднее – матожидание
стандартное_откл – среднеквадратичное отклонение
Назначение то же, что и у НОРМ.СТ.ОБР, только функция работает с данными любого масштаба.
Пример показан в ролике в конце статьи.
Моделирование нормального распределения
Для некоторых задач требуется генерация нормальных случайных чисел. Готовой функции для этого нет. Однако В Excel есть две функции, которые возвращают случайные числа: СЛУЧМЕЖДУ и СЛЧИС. Первая выдает случайные равномерно распределенные целые числа в указанных пределах. Вторая функция генерирует равномерно распределенные случайные числа между 0 и 1. Чтобы сделать искусственную выборку с любым заданным распределением, нужна функция СЛЧИС.
Допустим, для проведения эксперимента необходимо получить выборку из нормально распределенной генеральной совокупности с матожиданием 10 и стандартным отклонением 3. Для одного случайного значения напишем формулу в Excel.
=НОРМ.ОБР(СЛЧИС();10;3)
Протянем ее на необходимое количество ячеек и нормальная выборка готова.
Для моделирования стандартизованных данных следует воспользоваться НОРМ.СТ.ОБР.
Процесс преобразования равномерных чисел в нормальные можно показать на следующей диаграмме. От равномерных вероятностей, которые генерируются формулой СЛЧИС, проведены горизонтальные линии до графика функции нормального распределения. Затем от точек пересечения вероятностей с графиком опущены проекции на горизонтальную ось.

На выходе получаются значения с характерной концентрацией около центра. Вот так обратный прогон через функцию нормального распределения превращает равномерные числа в нормальные. Excel позволяет за несколько секунд воспроизвести любое количество выборок любого размера.
Как обычно, прилагаю ролик, где все вышеописанное показывается в действии.
Скачать файл с примером.
Поделиться в социальных сетях: