
Разведочный анализ данных (Exploratory Data Analysis) – предварительное исследование Датасета (Dataset) с целью определения его основных характеристик, взаимосвязей между Признаками (Feature), а также сужения набора методов, используемых для создания Модели (Model) Машинного обучения (ML).
Итак, в первой части статьи мы познакомились со следующими этапами разведочного анализа:
- Удаление дубликатов
- Обработка пропусков
- Обнаружение аномалий
И теперь продолжим глубже знакомиться с особенностями датасета.
Одномерный анализ
Описательная статистика
Прежде чем применять те или иные методы обучения, нам необходимо удостовериться, что они применимы к текущему датасету. Раздел описательной статистики включает в себя проверку на нормальность распределения и определение прочих статистических метрик. С этим нам поможет замечательная библиотека pandas-profiling. Установим самую свежую версию во избежание ошибок:
!pip install pandas_profiling --upgradeЗапустим профайлер и передадим df в качестве аргумента:
from pandas_profiling import ProfileReport
profile = ProfileReport(df)
profileПрофайлер высчитывает основные статистические метрики для каждой переменной и датасета в целом:

К примеру, в признаке «Длительность» мы вычислили:
- Количество уникальных значений (Distinct)
- Количество пропусков (Missing)
- Вероятно, параметр «Бесконечность» (‘Infinite’), рассчитываемый только для вещественных чисел, отыскивает сильно выделяющиеся значения, которыми иногда обозначают пропуски.
- Среднее значение (Mean)
- Минимум (Minimum)
- Максимум (Maximum)
- Количество нулей (Zeros)
- Память, задействованная этой переменной (Memory Size)
- Нормальность распределения (график)
Следующий интересный раздел – «Корреляции» (‘Correlations’). Чем ярче (краснее / синее) ячейка, тем сильнее выражена корреляция между парой признаков. Диагональные ячейки игнорируются, поскольку являются результатом расчета коэффициента между переменной и ее копией.

Профайлер вычленил из датасета только числовые признаки, и потому матрица имеет размер 11 x 11. К примеру, «колебание уровня безработицы» и «европейская межбанковская ставка» сильно коррелируют друг с другом, но поскольку эти признаки второстепенны, в дальнейшем их можно объединить на этапе инжиниринга признаков (Feature Engineering). Зачастую целевая переменная не сильно коррелирует с предикторами.
Важность признаков
Прежде чем произвести инжиниринг признаков и сократить объем входных данных, стоит определить, какие признаки имеют первостепенную значимость, и в этом нам поможет Scikit-Learn и критерий Хи-квадрат (Chi-Squared Test).:
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
X = df[['Возраст', 'Длительность', 'Кампания', 'День', 'Предыдущий контакт', 'Индекс потребительских цен', 'Европейская межбанковская ставка', 'Количество сотрудников в компании']]
y = df.iloc[:, -1]
bestfeatures = SelectKBest(score_func = chi2, k = 'all')
fit = bestfeatures.fit(X, y)
dfscores = pd.DataFrame(fit.scores_)
dfcolumns = pd.DataFrame(X.columns)
featureScores = pd.concat([dfcolumns, dfscores], axis = 1)
featureScores.columns = ['Specs', 'Score']
print(featureScores.nlargest(10, 'Score')) Неожиданно, но самым важным признаком оказалась длительность разговора и день звонка. Люди склонны брать кредитные продукты, если им позвонили в определенный день недели и разговор длился оптимальное время.

Многомерный анализ
Рассмотрение парных особенностей
Чего только не создаст комьюнити в Науке о данных! Для нужд разведочного анализа крайне кстати будет и попарные графики, и здесь на помощь приходит другой великолепный класс — seaborn.pairplot(). Каждая из переменных ляжет в основу одной из осей двумерного точечного графика, и так, пока все пары признаков не будут отображены. Сократим названия длинных переменных, чтобы уместить их на скромном отведенном пространстве:

Уменьшение размерности, стандартизация
Рассмотрев признаки по отдельности и попарно, мы пришли к выводу, что некоторые признаки могут быть как бы объединены с помощью специальной техники – Анализ главных компонент (PCA). Итак, давайте создадим заменяющий столбец, который представляет эти признаки в равной мере и тем самым уменьшим размер данных.
# Создадим список признаков, подлежащих уменьшению
features = ['Колебание уровня безработицы', 'Индекс потребительских цен', 'Индекс потребительской уверенности', 'Европейская межбанковская ставка']
# Выбираем сокращаемые признаки и целевой
x = df.loc[:, features].values
y = df.loc[:,['y']].valuesВыполняем Стандартизацию (Standartization) x, и это впоследствии станет частью тренировочных данных:
>>> from sklearn.preprocessing import StandardScaler
x = StandardScaler().fit_transform(x)
pd.DataFrame(data = x, columns = features).head()
StandardScaler() на месте заменяет данные на их стандартизированную версию, и мы получаем признаки, где все значения как бы центрованы относительно нуля. Такое преобразование необходимо, чтобы сократить нагрузку на вычислительную систему компьютера, который будет обучать модель:

Анализ главных компонент (Principal Component Analysis) представляет собой метод уменьшения размерности больших наборов данных путем преобразования большого набора переменных в меньший с минимальными потерями информативности.
from sklearn.decomposition import PCA
pca = PCA(n_components = 2)
principalComponents = pca.fit_transform(x)
principalDf = pd.DataFrame(data = principalComponents, columns = ['principal component 1', 'principal component 2'])
principalDf.head()Мы получили два принципиальных компонента и путем такого сокращения понижаем размерность датасета без потерь.

Нормализация
Еще один шаг, не затронутый в примере выше, – это Нормализация (Normalization), и порой приходится выбирать между ею и стандартизацией. Мы нормализуем те же признаки, характеризующие состояние экономики и потому загрузим датасет в исходном виде еще раз:
from sklearn import preprocessing
df = pd.read_csv('https://www.dropbox.com/s/62xm9ymoaunnfg6/bank-full.csv?dl=1', sep=';')
# Выберем признаки, выраженные вещественными числами и подлежащие
# нормализации
features = ['Колебание уровня безработицы', 'Индекс потребительских цен', 'Индекс потребительской уверенности', 'Европейская межбанковская ставка']
x = df.loc[:, features].values
# Инициализируем нормализатор
min_max_scaler = preprocessing.MinMaxScaler()
x_scaled = min_max_scaler.fit_transform(x)
df = pd.DataFrame(x_scaled) 
Ноутбук, не требующий дополнительной настройки на момент написания статьи, можно скачать здесь.
Фото: @yassine_khalfall
Если вам по работе или учёбе приходится погружаться в океан цифр и искать в них подтверждение своих гипотез, вам определённо пригодятся эти техники работы в Microsoft Excel. Как их применять — показываем с помощью гифок.

Юлия Перминова
Тренер Учебного центра Softline с 2008 года.
1. Сводные таблицы
Базовый инструмент для работы с огромным количеством неструктурированных данных, из которых можно быстро сделать выводы и не возиться с фильтрацией и сортировкой вручную. Сводные таблицы можно создать с помощью нескольких действий и быстро настроить в зависимости от того, как именно вы хотите отобразить результаты.
Полезное дополнение. Вы также можете создавать сводные диаграммы на основе сводных таблиц, которые будут автоматически обновляться при их изменении. Это полезно, если вам, например, нужно регулярно создавать отчёты по одним и тем же параметрам.
Как работать
Исходные данные могут быть любыми: данные по продажам, отгрузкам, доставкам и так далее.
- Откройте файл с таблицей, данные которой надо проанализировать.
- Выделите диапазон данных для анализа.
- Перейдите на вкладку «Вставка» → «Таблица» → «Сводная таблица» (для macOS на вкладке «Данные» в группе «Анализ»).
- Должно появиться диалоговое окно «Создание сводной таблицы».
- Настройте отображение данных, которые есть у вас в таблице.
Перед нами таблица с неструктурированными данными. Мы можем их систематизировать и настроить отображение тех данных, которые есть у нас в таблице. «Сумму заказов» отправляем в «Значения», а «Продавцов», «Дату продажи» — в «Строки». По данным разных продавцов за разные годы тут же посчитались суммы. При необходимости можно развернуть каждый год, квартал или месяц — получим более детальную информацию за конкретный период.
Набор опций будет зависеть от количества столбцов. Например, у нас пять столбцов. Их нужно просто правильно расположить и выбрать, что мы хотим показать. Скажем, сумму.
Можно её детализировать, например, по странам. Переносим «Страны».
Можно посмотреть результаты по продавцам. Меняем «Страну» на «Продавцов». По продавцам результаты будут такие.
2. 3D-карты
Этот способ визуализации данных с географической привязкой позволяет анализировать данные, находить закономерности, имеющие региональное происхождение.
Полезное дополнение. Координаты нигде прописывать не нужно — достаточно лишь корректно указать географическое название в таблице.
Как работать
- Откройте файл с таблицей, данные которой нужно визуализировать. Например, с информацией по разным городам и странам.
- Подготовьте данные для отображения на карте: «Главная» → «Форматировать как таблицу».
- Выделите диапазон данных для анализа.
- На вкладке «Вставка» есть кнопка 3D-карта.
Точки на карте — это наши города. Но просто города нам не очень интересны — интересно увидеть информацию, привязанную к этим городам. Например, суммы, которые можно отобразить через высоту столбика. При наведении курсора на столбик показывается сумма.
Также достаточно информативной является круговая диаграмма по годам. Размер круга задаётся суммой.
3. Лист прогнозов
Зачастую в бизнес-процессах наблюдаются сезонные закономерности, которые необходимо учитывать при планировании. Лист прогноза — наиболее точный инструмент для прогнозирования в Excel, чем все функции, которые были до этого и есть сейчас. Его можно использовать для планирования деятельности коммерческих, финансовых, маркетинговых и других служб.
Полезное дополнение. Для расчёта прогноза потребуются данные за более ранние периоды. Точность прогнозирования зависит от количества данных по периодам — лучше не меньше, чем за год. Вам требуются одинаковые интервалы между точками данных (например, месяц или равное количество дней).
Как работать
- Откройте таблицу с данными за период и соответствующими ему показателями, например, от года.
- Выделите два ряда данных.
- На вкладке «Данные» в группе нажмите кнопку «Лист прогноза».
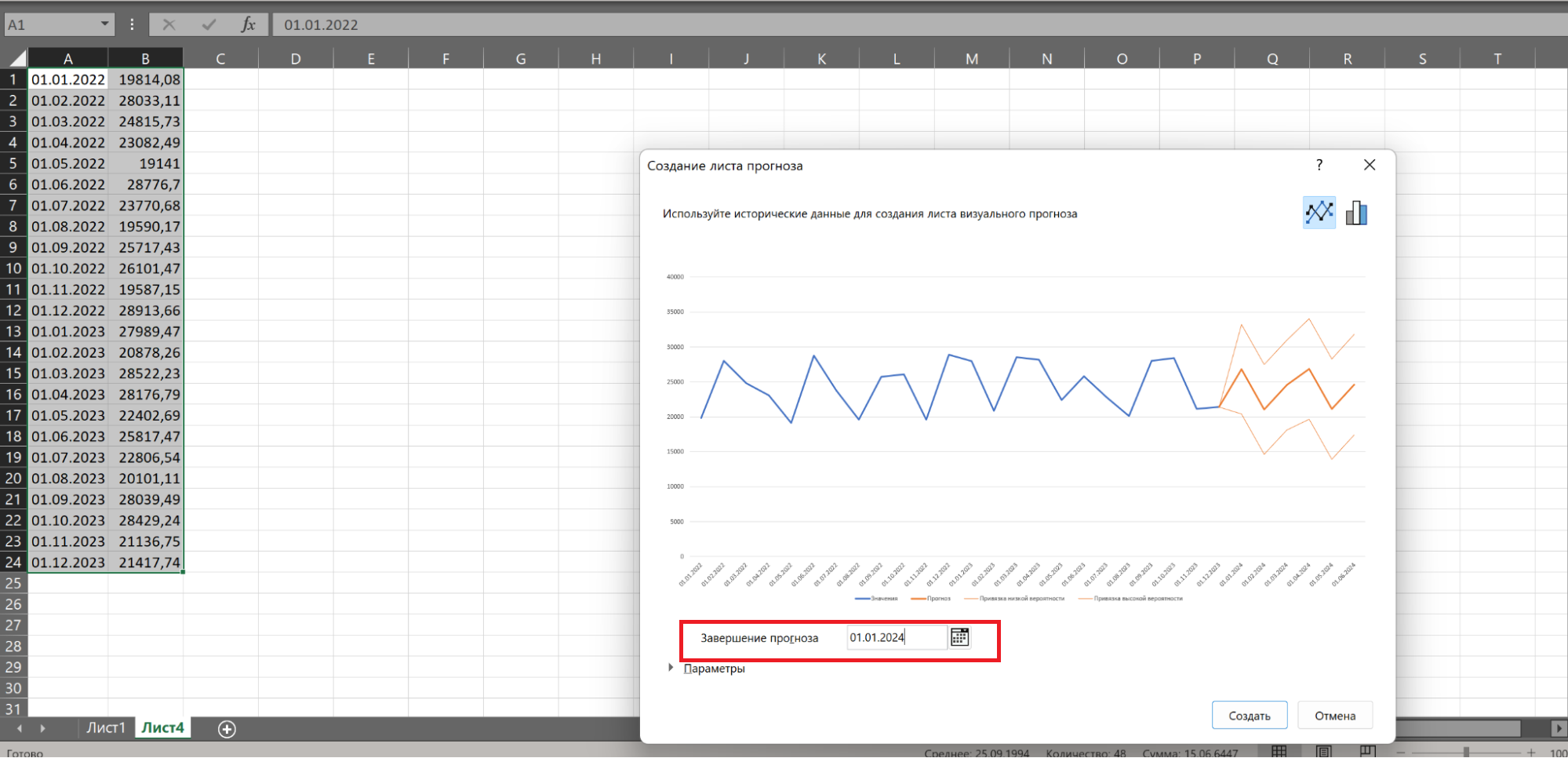
- В окне «Создание листа прогноза» выберите график или гистограмму для визуального представления прогноза.
- Выберите дату окончания прогноза.
В примере ниже у нас есть данные за 2011, 2012 и 2013 годы. Важно указывать не числа, а именно временные периоды (то есть не 5 марта 2013 года, а март 2013-го).
Для прогноза на 2014 год вам потребуются два ряда данных: даты и соответствующие им значения показателей. Выделяем оба ряда данных.
На вкладке «Данные» в группе «Прогноз» нажимаем на «Лист прогноза». В появившемся окне «Создание листа прогноза» выбираем формат представления прогноза — график или гистограмму. В поле «Завершение прогноза» выбираем дату окончания, а затем нажимаем кнопку «Создать». Оранжевая линия — это и есть прогноз.
4. Быстрый анализ
Эта функциональность, пожалуй, первый шаг к тому, что можно назвать бизнес-анализом. Приятно, что эта функциональность реализована наиболее дружественным по отношению к пользователю способом: желаемый результат достигается буквально в несколько кликов. Ничего не нужно считать, не надо записывать никаких формул. Достаточно выделить нужный диапазон и выбрать, какой результат вы хотите получить.
Полезное дополнение. Мгновенно можно создавать различные типы диаграмм или спарклайны (микрографики прямо в ячейке).
Как работать
- Откройте таблицу с данными для анализа.
- Выделите нужный для анализа диапазон.
- При выделении диапазона внизу всегда появляется кнопка «Быстрый анализ». Она сразу предлагает совершить с данными несколько возможных действий. Например, найти итоги. Мы можем узнать суммы, они проставляются внизу.
В быстром анализе также есть несколько вариантов форматирования. Посмотреть, какие значения больше, а какие меньше, можно в самих ячейках гистограммы.
Также можно проставить в ячейках разноцветные значки: зелёные — наибольшие значения, красные — наименьшие.
Надеемся, что эти приёмы помогут ускорить работу с анализом данных в Microsoft Excel и быстрее покорить вершины этого сложного, но такого полезного с точки зрения работы с цифрами приложения.
Читайте также:
- 10 быстрых трюков с Excel →
- 20 секретов Excel, которые помогут упростить работу →
- 10 шаблонов Excel, которые будут полезны в повседневной жизни →
Анализ данных • 23 ноября 2022 • 5 мин чтения
4 инструмента быстрого и простого анализа данных в Microsoft Excel
Обычно аналитики работают со специфическими программами, но в некоторых случаях эффективнее использовать простой инструмент — Microsoft Excel.
Продакт-менеджер, эксперт бесплатного курса по Excel
- Настройка анализа данных в Excel
- Техники анализа данных в Microsoft Excel
- Совет эксперта
-
1. Сводные таблицы
-
2. Лист прогноза в Excel
-
3. Быстрый анализ в Excel
-
4. 3D-карты
Практически все инструменты для анализа данных уже встроены в Excel, и специально настраивать их не нужно. Эти инструменты находятся в главном меню программы в разделе «Данные».

Здесь лежат инструменты для сортировки, фильтрации, прогнозирования и других действий с данными таблицы
В других разделах они тоже встречаются — например, отображение географически привязанных данных на глобусе находится в разделе «Вставка → 3D-карта».
В Excel есть инструменты, которые нужно подключать отдельно. К таким относится анализ корреляций между значениями. Чтобы его использовать, нужно нажать «Файл → Параметры → Надстройки».

Затем в выпадающем списке «Управление» выбрать «Настройки Excel» и нажать «Перейти». Откроется список надстроек.
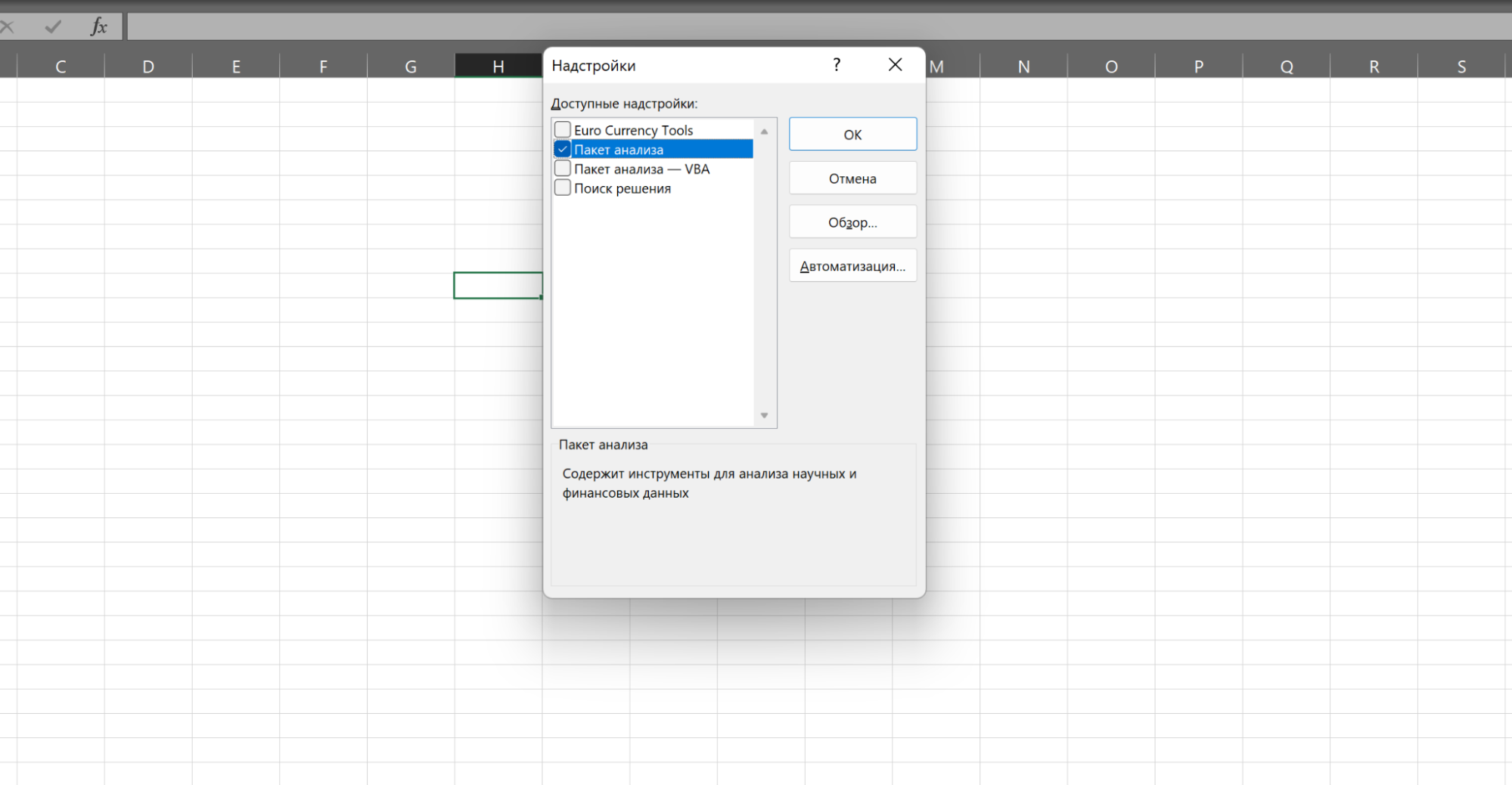
Нужно поставить галочку на «Пакет анализа» и нажать «ОК». После этого в разделе меню «Данные» появится пункт «Анализ данных» с доступными инструментами для анализа.
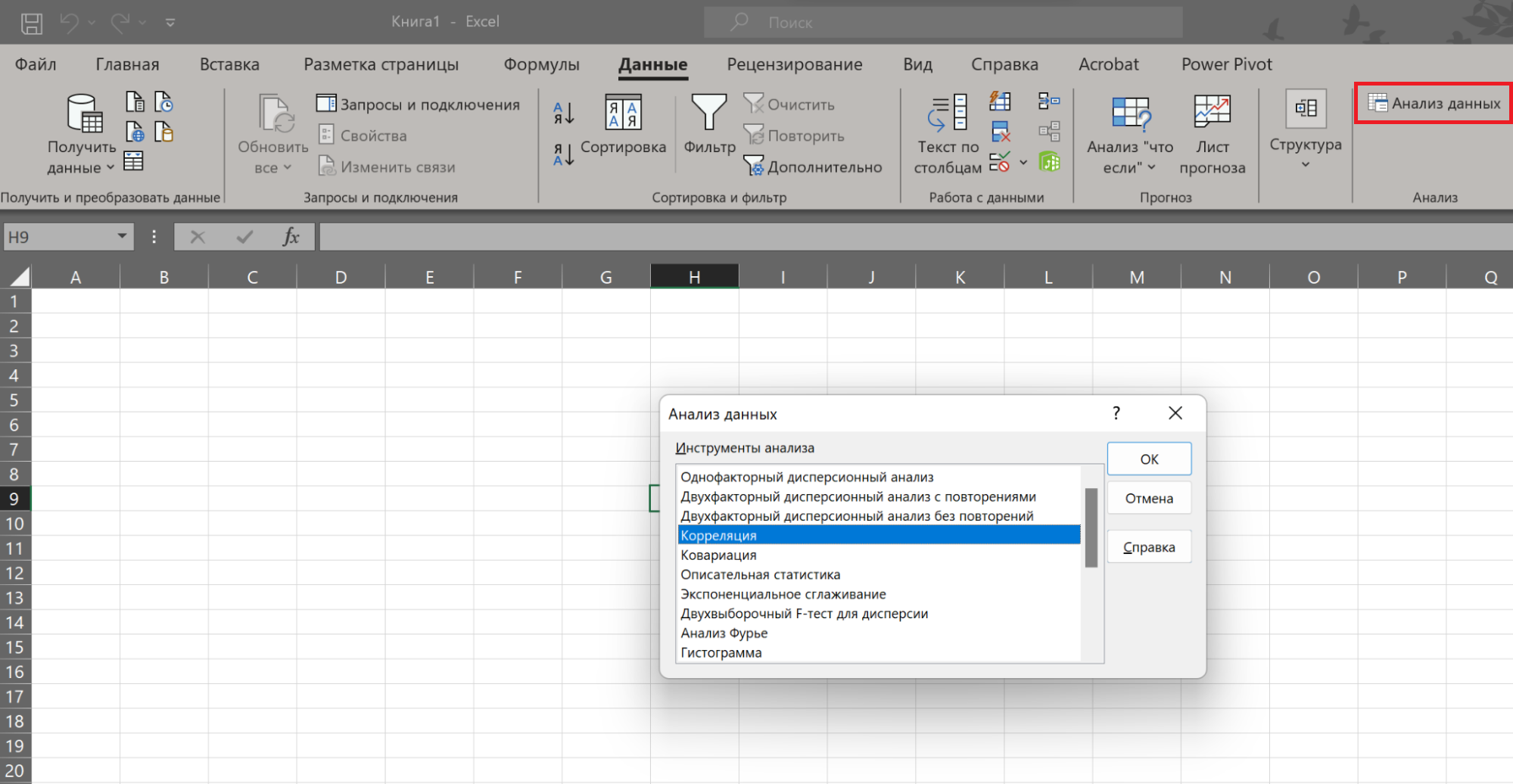
Инструменты для анализа данных в Excel простые в освоении, но плохо подходят для сложных задач. Тут аналитикам пригодится специальное ПО, аналитические базы данных и код на Python. Работать с этими инструментами учат на курсе «Аналитик данных».
Повышайте прибыль компании с помощью данных
Научитесь анализировать большие данные, строить гипотезы и соберите 13 проектов в портфолио за 6 месяцев, а не 1,5 года. Сделайте первый шаг к новой профессии в бесплатной вводной части курса «Аналитик данных».

Техники анализа данных в Microsoft Excel
Разберём несколько техник, которые позволят быстро изучить информацию, собранную в таблицу Excel.
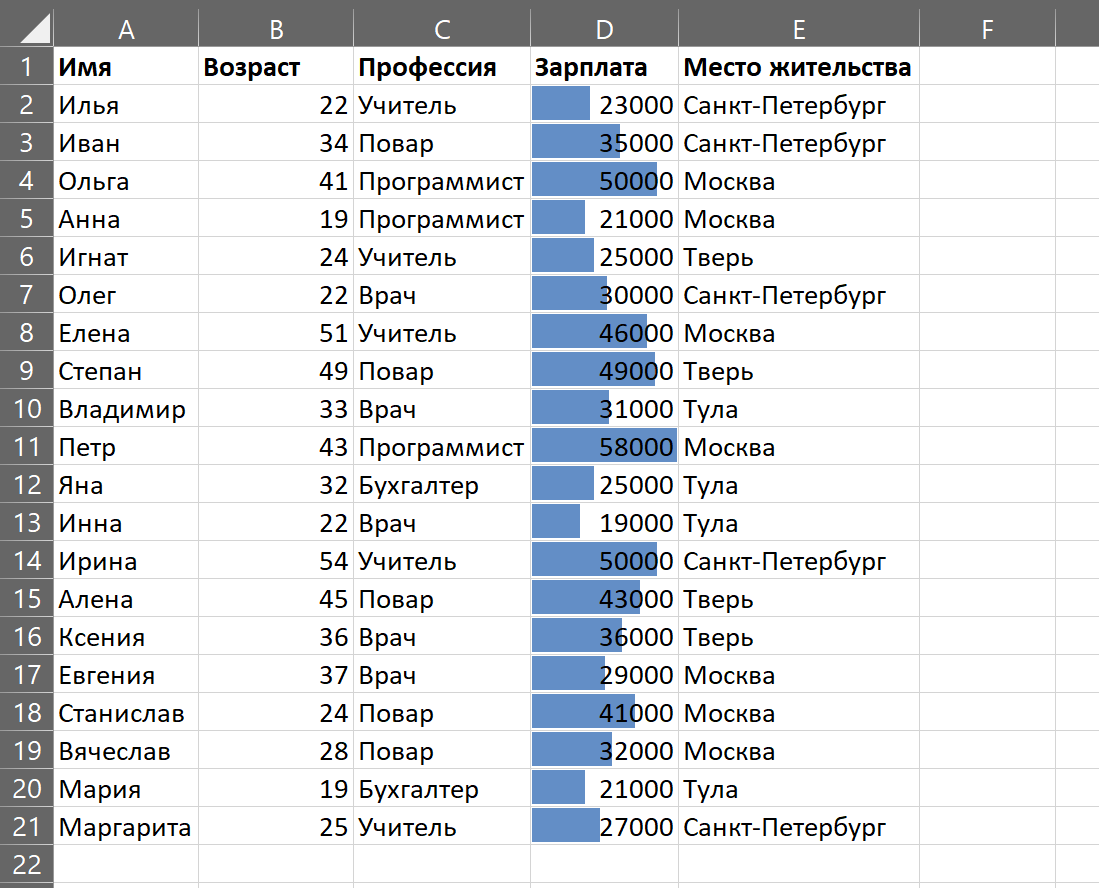
Нужны для того, чтобы сводить данные, то есть смотреть, как соотносится информация в разных столбцах и строках исходной таблицы. Например, есть данные по профессиям и зарплатам разных специалистов. Сводная таблица покажет, сколько в среднем зарабатывает представитель каждой профессии или какая из профессий популярнее.
Чтобы создать сводную таблицу для анализа данных в Microsoft Excel, сначала нужно сделать простую. Затем выделить все данные для анализа и нажать «Вставка» → «Сводная таблица». Excel предложит опции.
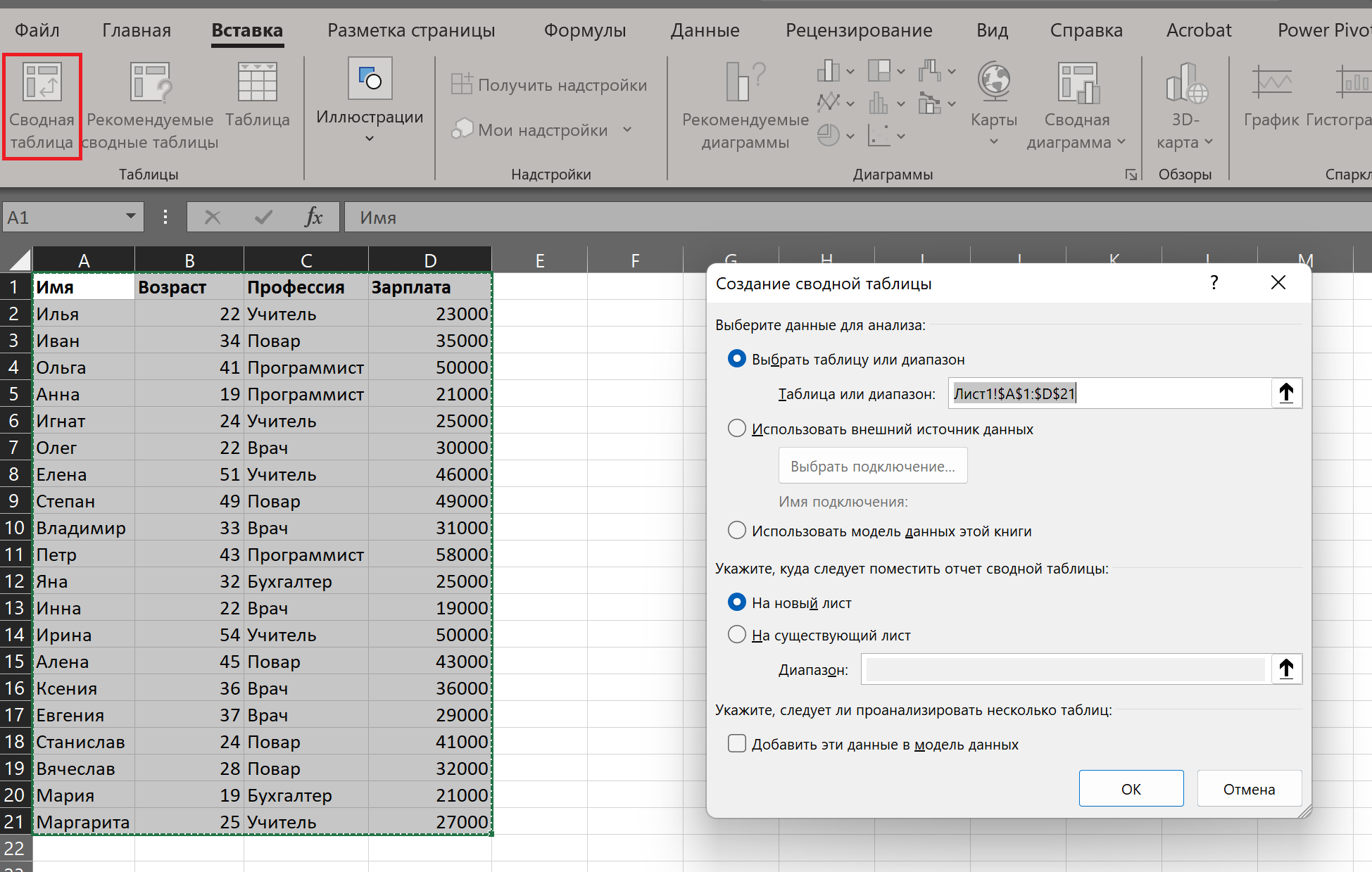
В этом окне можно задать диапазон, а также указать, куда именно вставить новую сводную таблицу — на новый или на этот же лист.
Затем появится новый лист, пока ещё пустой. В окне справа нужно задать поля сводной таблицы.
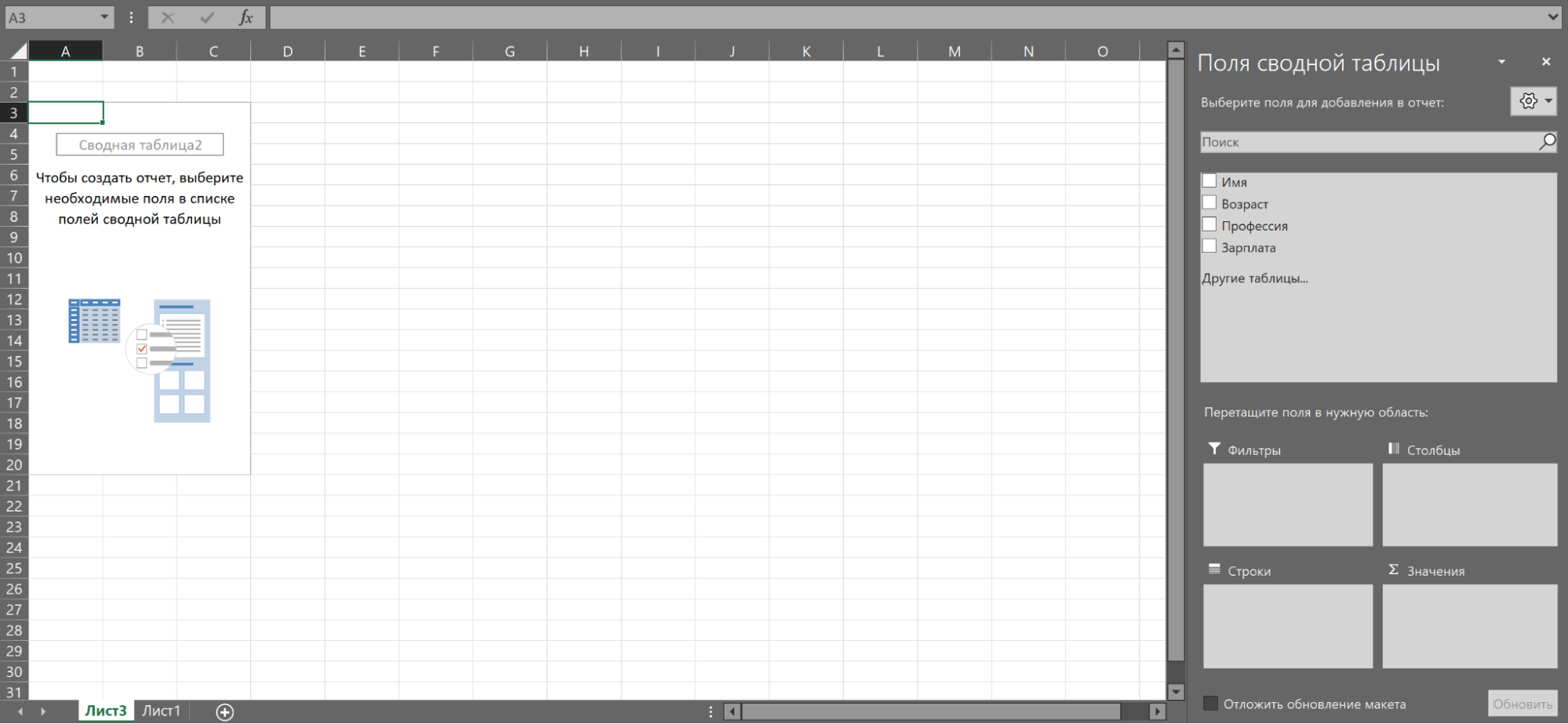
Например, зададим поля «Профессия» и «Зарплата».

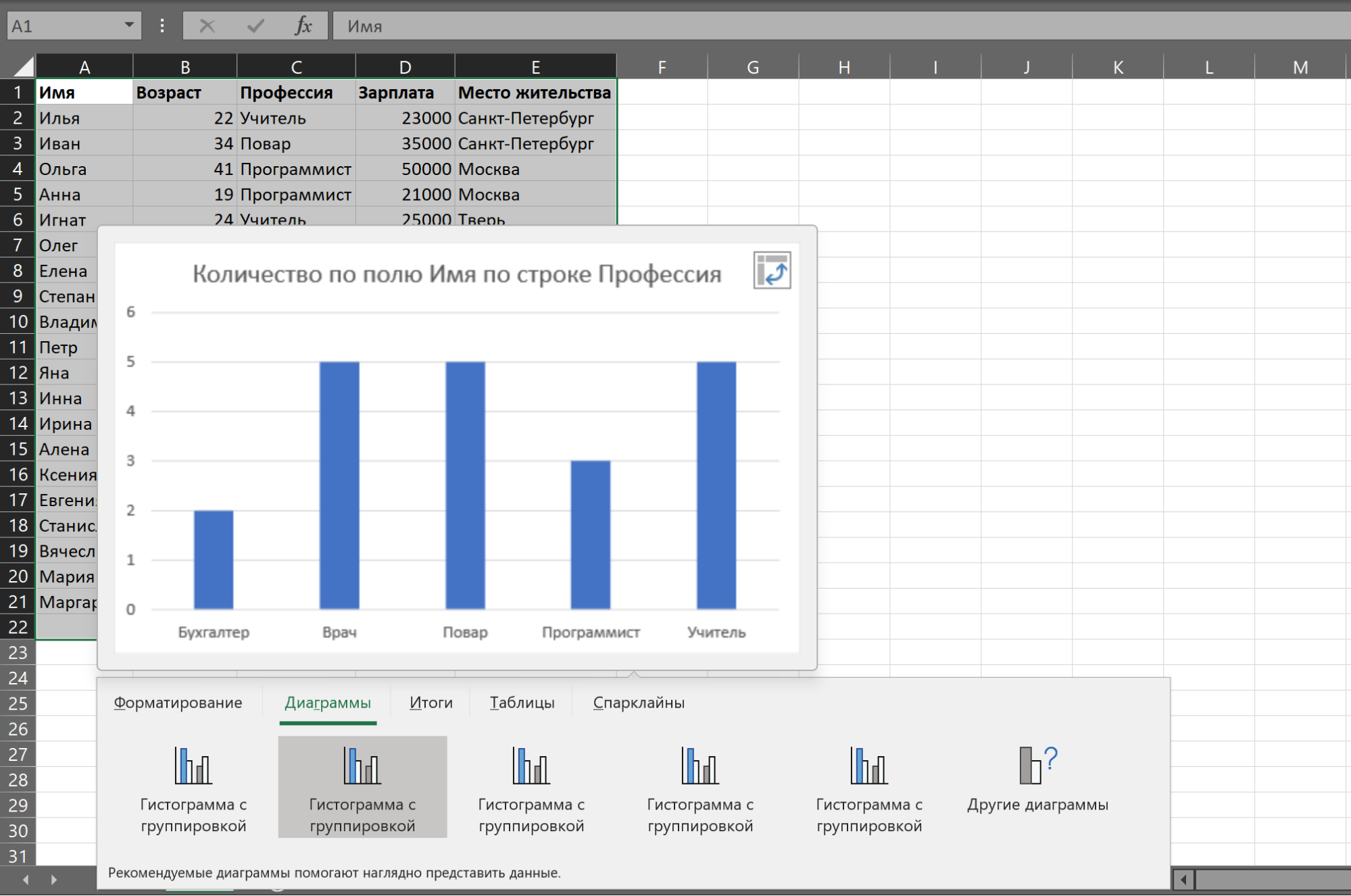
По умолчанию Excel выбирает для числовых данных «Сумму по полю», то есть показывает сумму всех значений. Это можно скорректировать в графе значения, нажав на строку «Сумма по полю» → «Параметры поля значений».

Здесь можно выбрать новое имя для колонки и задать нужную операцию, например вычисление среднего. Получится следующая таблица.
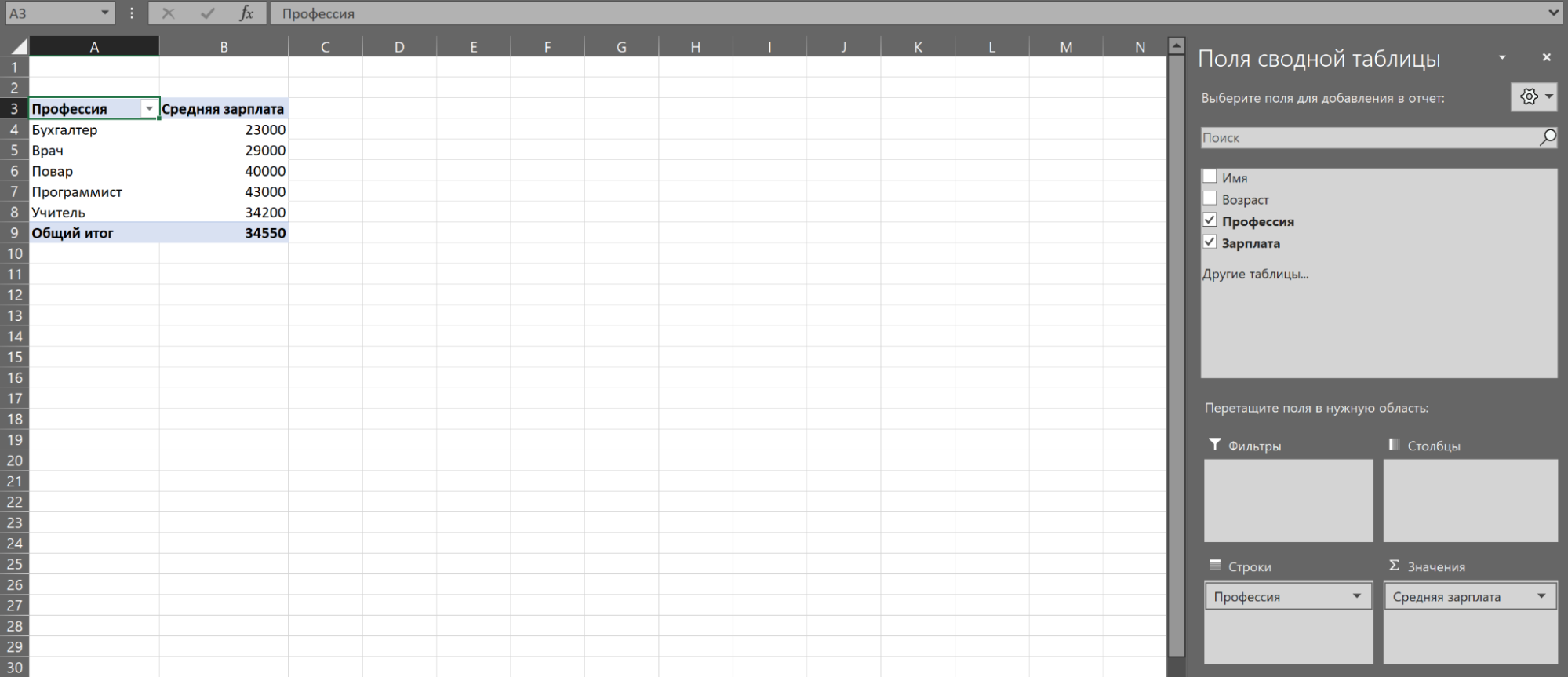
В таблицу можно добавлять дополнительные значения. Допустим, поставить галочку в графе «Возраст», чтобы узнать средний возраст представителей профессии.

Если перетащить графу «Возраст» из раздела «Значений» в «Строки», получится средняя зарплата по профессиям для каждого возраста.

Чтобы вычислить самую популярную профессию, нужно распределить все по столбцам и посчитать, сколько раз они встречаются в таблице.
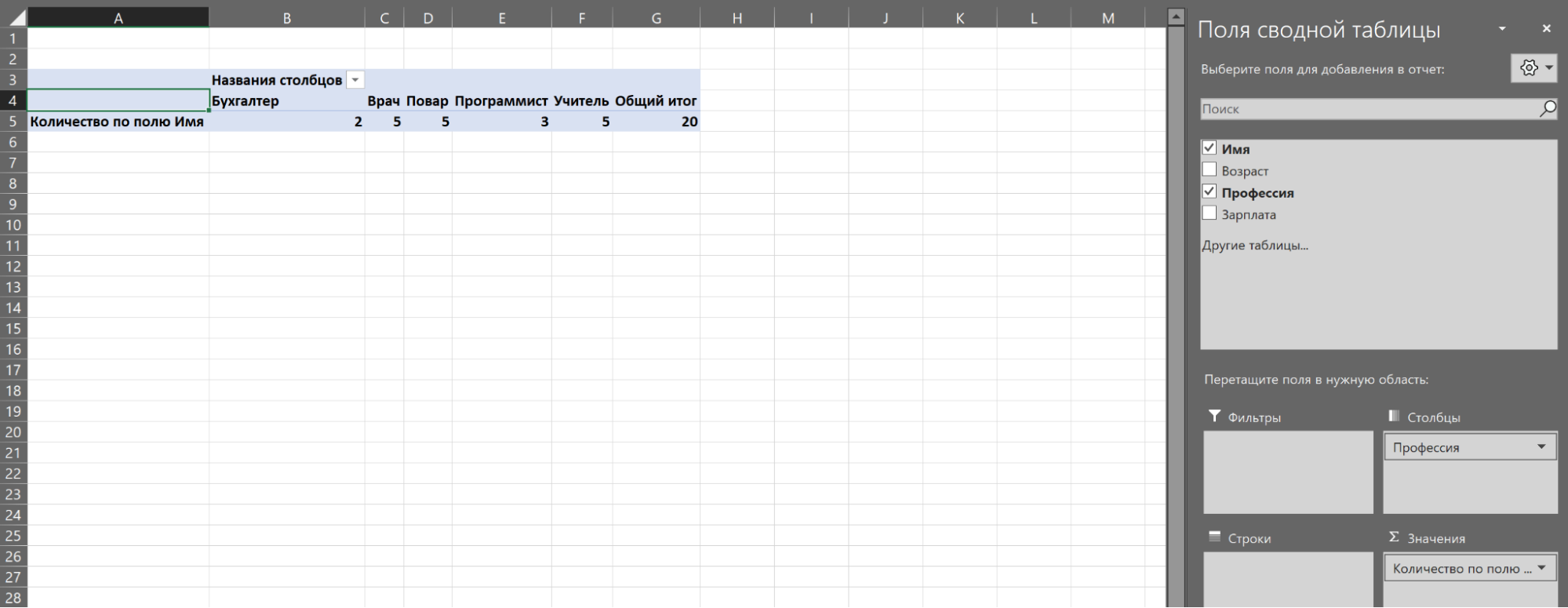
Инструмент «Сводные таблицы» позволяет сопоставлять самые разные значения друг с другом и делать простые вычисления. Часто для базового анализа данных большего и не требуется.
С чем работает аналитик данных: 10 популярных инструментов
2. Лист прогноза в Excel
Это средство анализа данных в MS Excel позволяет взять набор изменяющихся данных и спрогнозировать, как они будут изменяться дальше. Для этого понадобится как можно больший набор данных за прошлые периоды, причём равные — неделю, месяц, год.
Для примера возьмём динамику зарплат за два года.
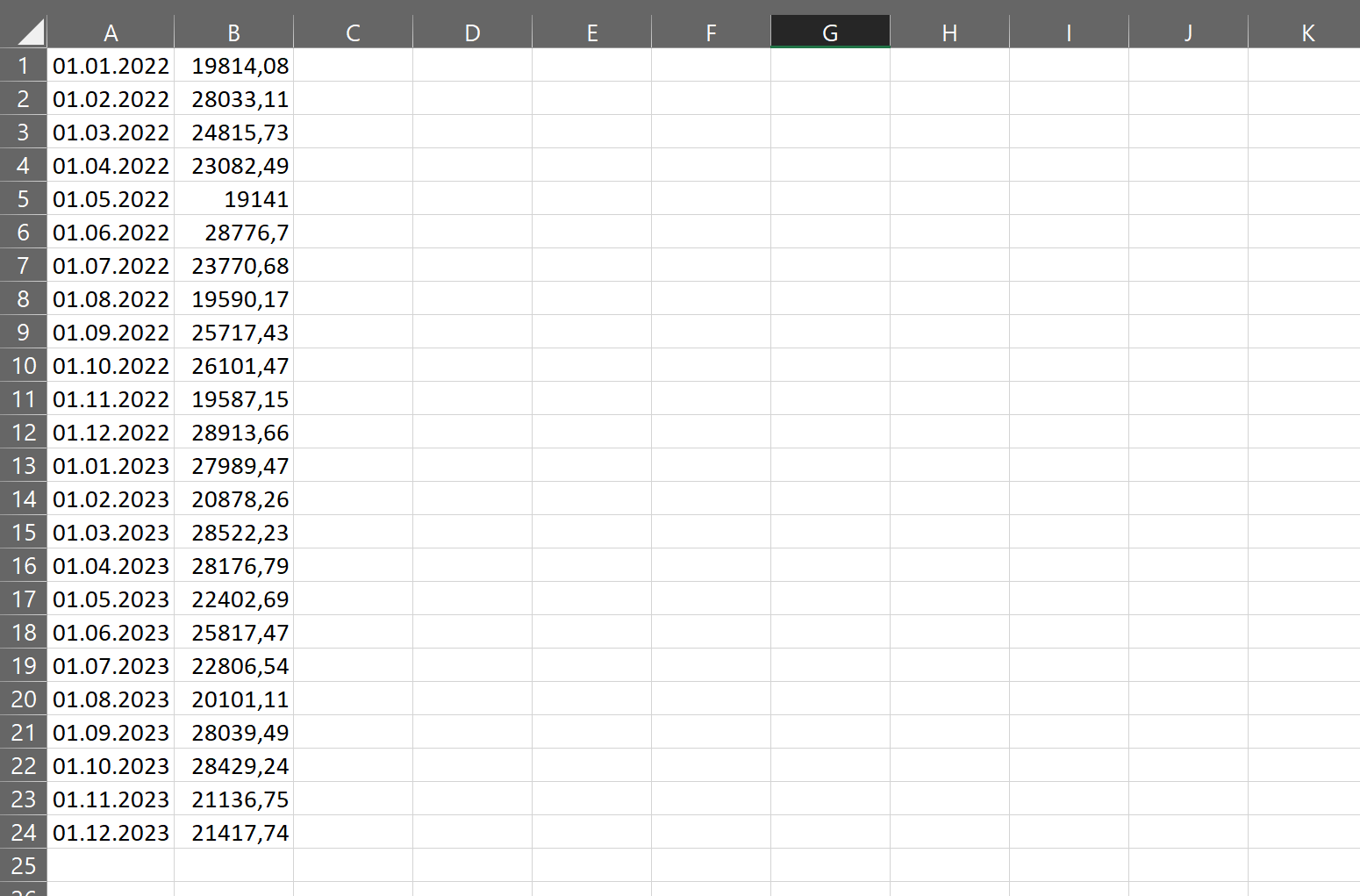
Посчитаем, какой примерно будет зарплата в течение следующего года. Для этого нужно выделить данные для анализа и нажать «Данные» → «Лист прогноза». Появится диалоговое окно.
В нём можно выставить конечную точку и сразу увидеть примерный график. После нажатия кнопки «Создать» Excel создаст отдельный лист с прогнозируемыми данными.
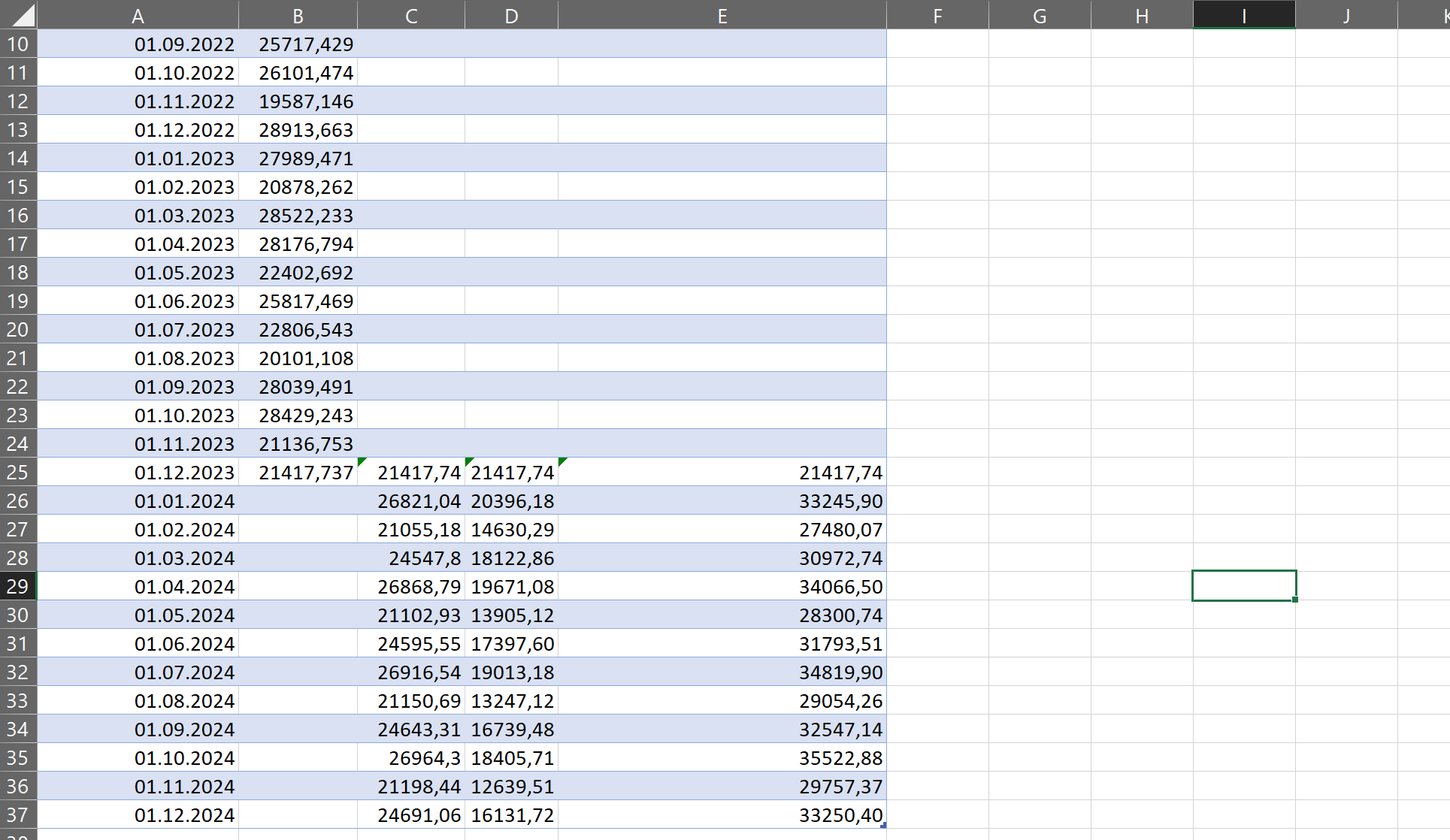
Также на листе будет график, на котором можно визуально отследить примерные изменения.

Чем больше значений для анализа, тем точнее будет прогноз. Разумеется, он построен на простом математическом анализе, а не на моделях машинного обучения, поэтому не может учитывать нюансы и сложные факторы. Однако для простых примерных прогнозов подойдёт.
3. Быстрый анализ в Excel
Этот набор инструментов отвечает на вопрос «Как сделать анализ данных в Excel быстро?». В Microsoft Office 365 он называется экспресс-анализом. Инструмент появляется в нижнем правом углу, если выделить диапазон данных. У быстрого анализа чуть меньший набор опций, однако он позволяет в пару кликов проводить большинство стандартных аналитических операций.
Если нажать на кнопку с иконкой в виде молнии либо сочетание клавиш CTRL+Q, открывается большой набор инструментов для анализа и визуализации.
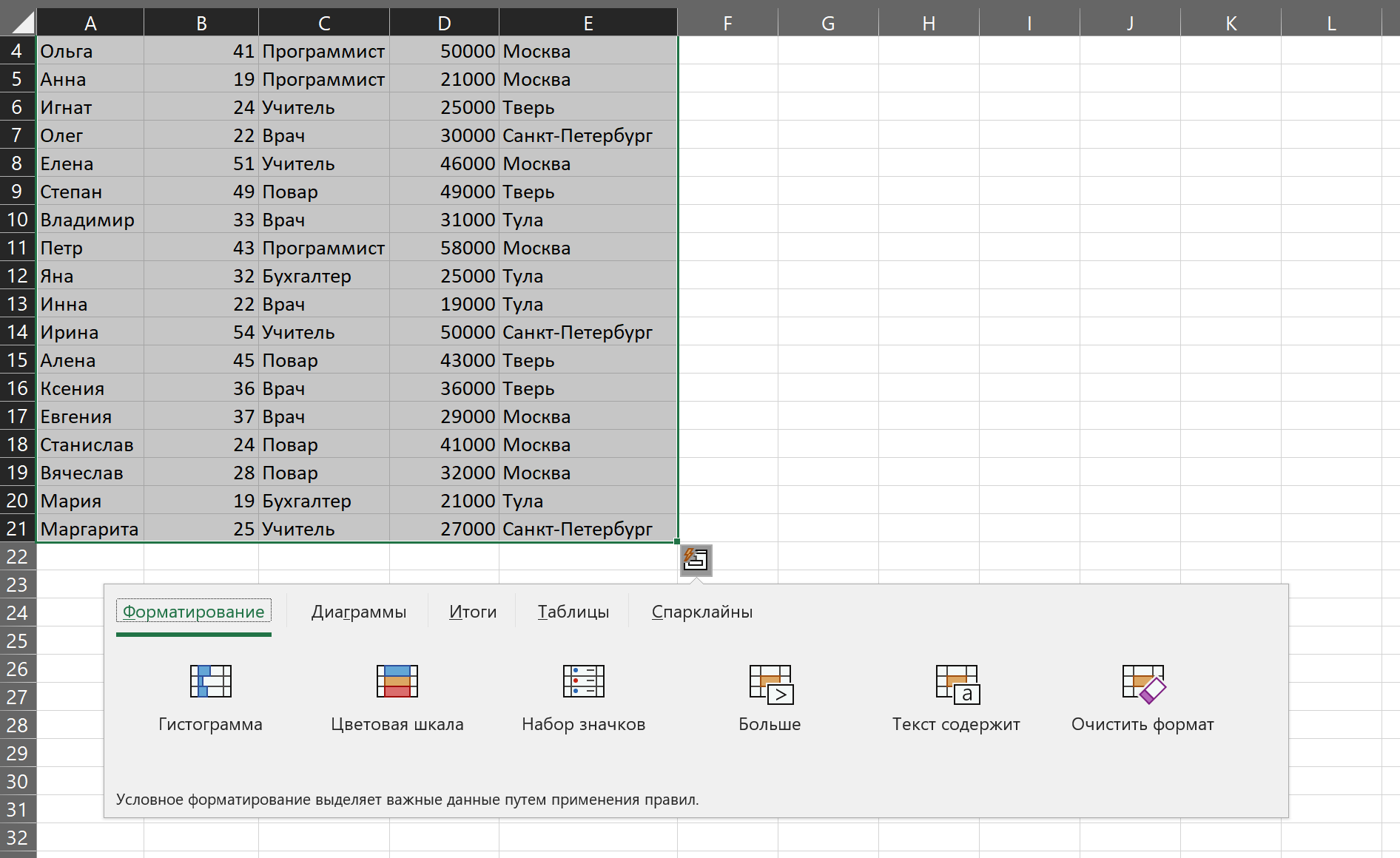
Например, если выбрать «Форматирование» → «Гистограмма», Excel прямо
внутри ячеек для сравнения наглядно отобразит, насколько одни значения больше других.
При выборе «Диаграмма» Excel отобразит предварительный результат.
Затем создаст отдельный лист с настраиваемой диаграммой, в которой можно задавать свои параметры.
Прямо здесь можно вычислить среднее с автоматическим добавлением строки с результатами.

Инструмент быстрого анализа позволяет составить сводную таблицу без перехода в отдельные пункты меню.

Этот инструмент позволяет с помощью MS Excel провести анализ данных, в которых есть указание города или страны. Работает только в последних версиях Excel старше 2019 года, без интернета недоступен.
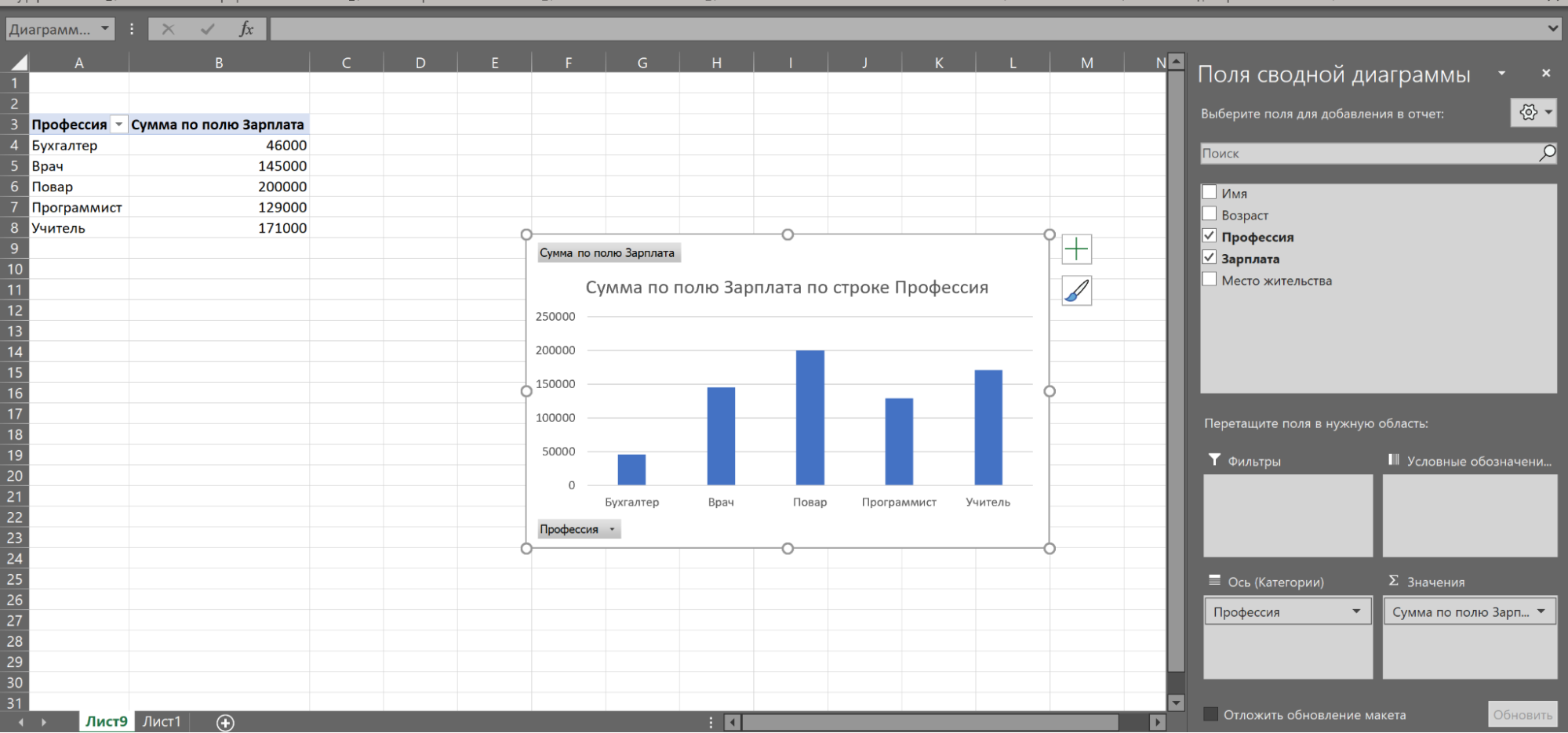
Возьмём таблицу с профессиями и зарплатами и добавим в неё новую колонку — город проживания. Далее нужно выделить диапазон данных и нажать «Вставка» → «3D-карта». В отдельном окне откроется карта.

Слева можно выбрать параметры отображения. Например, задать высоту столбцов в зависимости от нужного показателя. Возьмём «Зарплату», выставим среднее значение и посмотрим, как это отобразится на 3D-карте.

Высота столбцов изменится в зависимости от средней зарплаты в регионе — Excel посчитает это самостоятельно. Можно задать категории, например «Профессию».
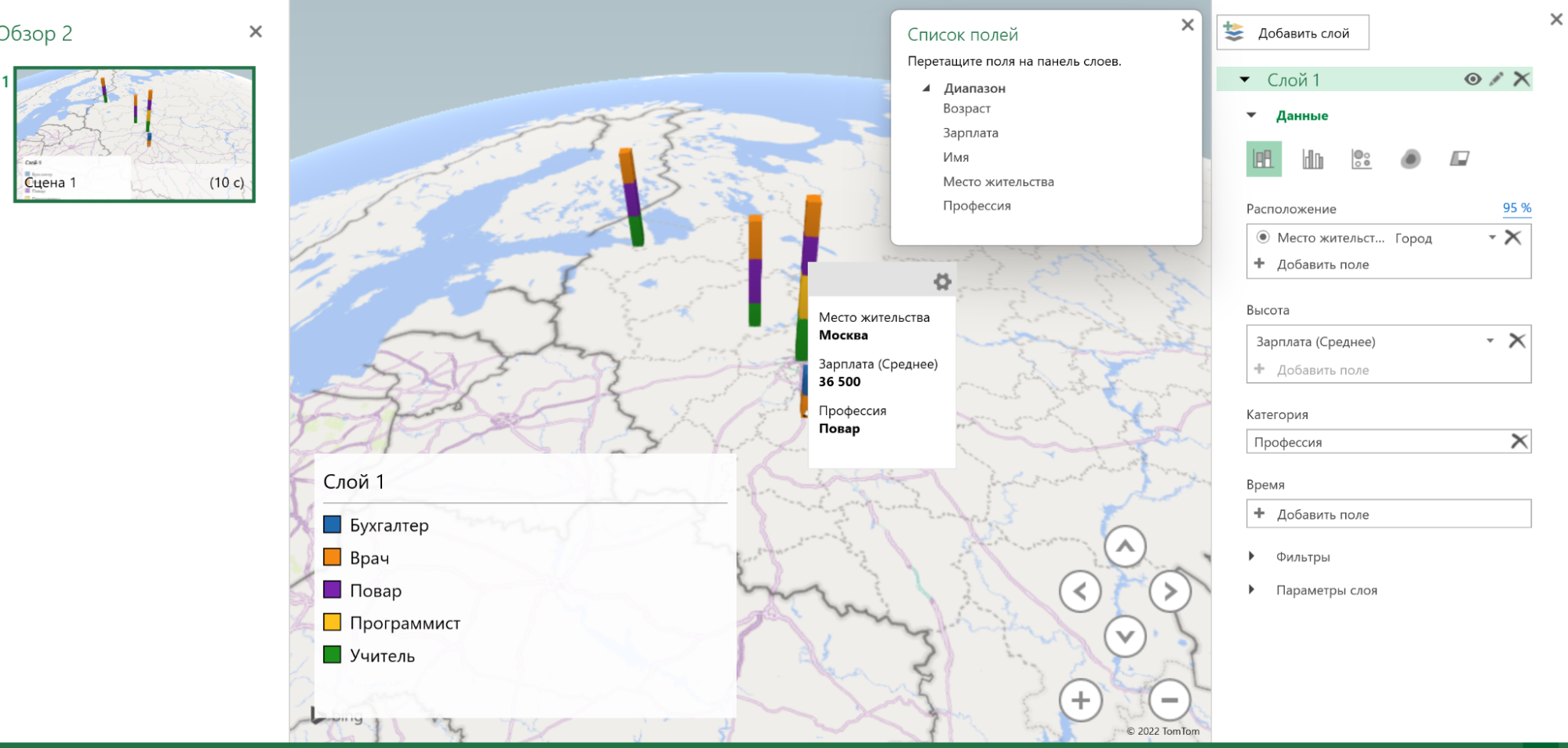
Excel раскрасит столбики в зависимости от того, сколько представителей каждой профессии живёт в конкретном городе.
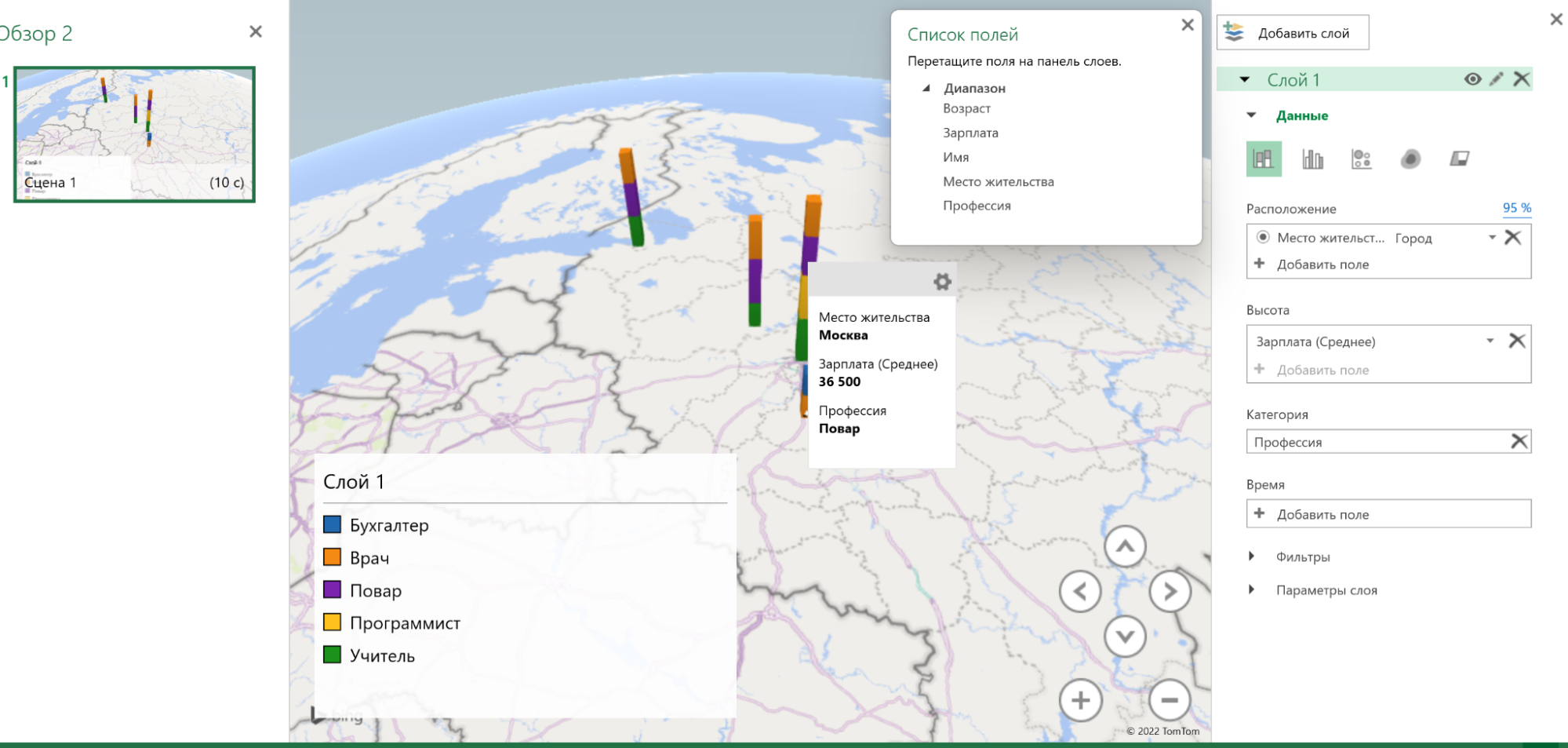
При наведении на конкретный элемент столбика можно увидеть город, профессию и среднюю зарплату.
3D-карты пригодятся, когда в таблице очень много данных и их география имеет большое значение. Этот инструмент подойдёт как для анализа, так и для быстрой визуализации. Внутри инструмента можно изменить параметры отображения и быстро создать видео для презентации результатов анализа.
Совет эксперта
Настя Шушурина
Вышеописанные функции и лайфхаки — только часть инструментария Excel. Ими можно воспользоваться, когда нужно быстро провести агрегацию данных, найти ответ на вопрос или просто сравнить ряд данных и добавить пару классных визуализаций в презентацию. В Excel есть и множество других инструментов, которые позволяют делать интересные вещи и проводить быстрые манипуляции с данными без умения писать код.

Как пересечение и объединение множеств используются в анализе данных

С чем работает аналитик данных: 10 популярных инструментов
Время на прочтение
3 мин
Количество просмотров 4.7K
Всем привет! Меня зовут Сергей Коньков — я работаю архитектором в компании CloudReports. Сегодня я расскажу, как мы создали продукт, который помогает пользователям работать с данными и в какой-то мере соединяет два мира аналитики: Excel и облачные хранилища данных.
Задача
BigQuery и другие аналитические хранилища в сочетании с современными BI инструментами перевернули работу с данными за последние годы. Возможность обрабатывать терабайты информации за секунды, интерактивные дашборды в DataStudio и PowerBI, сделали работу очень комфортной.
Однако если посмотреть глубже, можно увидеть — выиграли от этих изменений в основном профессионалы, владеющие SQL и Python и бизнес пользователи на руководящих позициях, для которых разрабатываются дашборды.
А как быть с сотнями миллионов сотрудников, для которых главным инструментом анализа был и остается Microsoft Excel? Они в каком-то смысле, остались за бортом новых изменений. Это менеджеры по продажам, владельцы малого бизнеса, руководители небольших отделов. Освоить PowerBI у них нет времени. Все что им остается это экспортировать данные из отчетов в свой любимый Excel и продолжить работу там, но это не очень удобно, занимает время и есть ограничения по объему данных.
Мы часто наблюдаем, как наши клиенты использующих Google BigQuery загружают данные в Excel с помощью различных коннекторов, натыкаясь на ограничения. И родилась идея: если Excel не теряет популярности, а данные уходят в облака, то давайте придумаем способ как помочь пользователю работать из Excel с облаком.
Вспоминаем OLAP
Да, сегодня Excel по-прежнему самый популярный инструмент для работы с информацией в мире. А Сводная таблица, это то что используют миллионы пользователей каждый день. А раньше было еще больше. Если вы работали с данными в крупной компании десять лет назад вы наверняка слышали про технологию OLAP кубов от Microsoft и других вендоров, которые создаются поверх реляционных SQL баз, и позволяют получать результаты обработки миллионов строк данных за секунды. Самым популярным способом работы с OLAP кубами была и есть сводная таблица Excel. К слову OLAP по прежнему очень распространен в корпоративном мире, это все так же часть Microsoft SQL Server, однако имеет ряд ограничений по объемам и скорости обработки и все больше уступает рынок облачным аналитическим хранилищам.
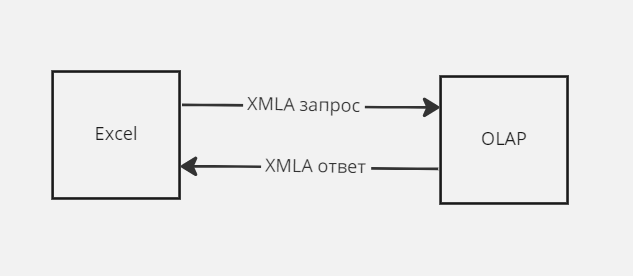
Так вот в решении этой задачи нам поможет OLAP. Как я уже писал выше в Excel есть готовый клиент для работы с OLAP, мы будем использовать его.
Kогда Microsoft выводил на рынок данную технологию был опубликован открытый протокол для работы с OLAP базами — XMLA (XML для аналитики). Именно этот протокол и использует Excel когда подключается к OLAP серверу. Все работает примерно так:
Решение
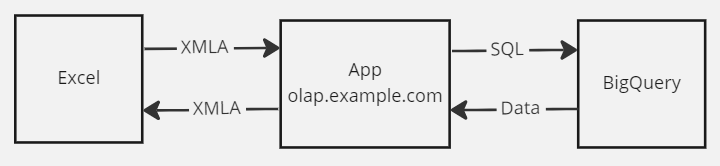
Идея проста — вместо OLAP сервера мы сделаем Python приложение , которое будет делать следующее:
-
принимать XMLA запросы от Excel
-
конвертировать логику XMLA запроса в SQL код
-
отправлять SQL запрос в BigQiery
-
полученный от BigQuery ответ конвертировать в XMLA и отправлять обратно в Excel
Данное приложение (App) можем опубликовать в облаке, так как Excel имеет возможность отправлять запросы XMLA запросы по протоколу HTTPS. Все будет работать примерно так:
Использование
После того как мы разработали и опубликовали приложение, администратору BigQuery для начала использования достаточно просто создать таблицу и определить для соответсnвующих полей типы агрегации (сумма, минимум, максимум и т.д.). Далее пользователь в Excel используя подключение к службам аналитики (OLAP) соединяется с нашим сервисом:
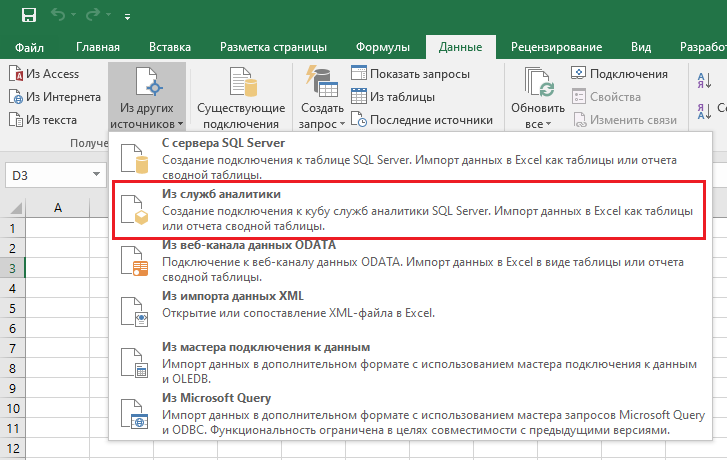
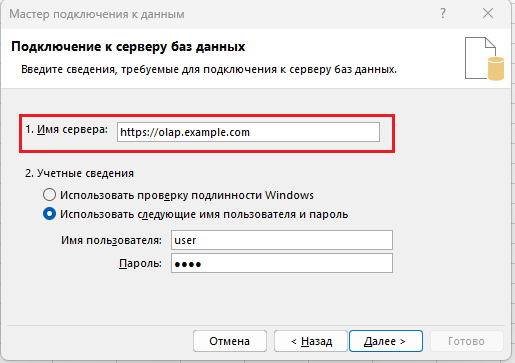
После этого мы получаем доступ к таблице BigQuery непосредственно из сводной таблицы. И можем легко «играть» с данными.
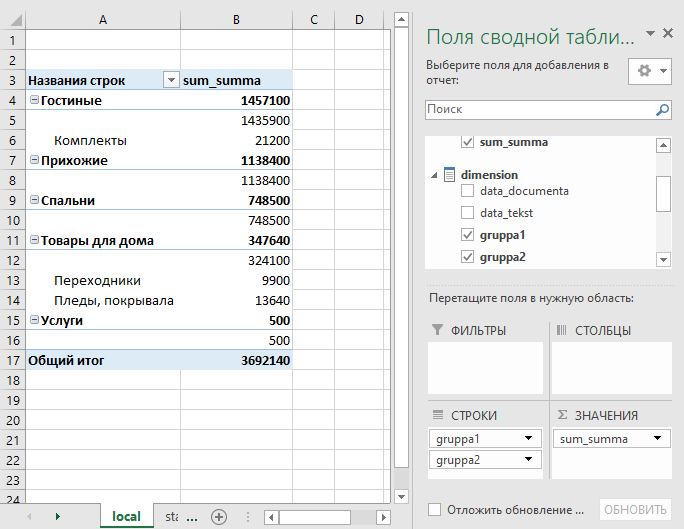
Кроме того, мы реализовали в данном сервисе слой кэширования данных для ускорения запросов и экономии затрат на BigQuery.
Что дальше
Сейчас мы активно тестируем сервис на своих клиентах и думаем над добавлением нового функционала.
Например, SQL запросы наряду с BigQuery поддерживают и другие облачные хранилища данных. Добавив один класс в наше приложение мы реализовали аналогичный механизм для ClickHouse. Скоро будет готова версия для Snowflake и Amazon Redshift.
Будем рады услышать вопросы и мнение коллег в комментариях.
В годы Второй мировой войны разведка союзников пыталась определить объем производства тяжелых немецких танков. Сведения из разных источников были противоречивыми, и статистики разработали метод оценки на основе серийных номеров захваченных танков. Чем больше отличаются эти серийные номера, тем больше танков было произведено. Таблица демонстрирует превосходство статистических методов оценки над разведданными:

Производство тяжелых немецких танков; * – согласно захваченным после войны документам
Предыдущая глава Оглавление Следующая глава
Скачать заметку в формате Word или pdf
В статистике термин «разведочный анализ» ввел Джон Тьюки в 1970-х. Суть метода – преобразование данных наблюдений и их наглядное представление, позволяющие выявить внутренние закономерности в данных.
Генеральная совокупность и выборка
Генеральная совокупность – множество всех рассматриваемых объектов, выборка – часть генеральной совокупности, извлекаемая для анализа. Пример, генеральной совокупности – сплошная перепись населения, пример выборки – экзитпол. Цель разведочного анализа – сделать выводы о генеральной совокупности на основе одной или нескольких выборок. Числа, которые характеризуют генеральную совокупность, называют параметрами и обозначают греческими буквами. Числа, описывающие выборку, называют статистиками и обозначают латинскими буквами.
Основной принцип подготовки выборки – обеспечить чтобы каждая единица генеральной совокупности имела равный шанс попасть в выборку. Выборы президента США 1936 г. продемонстрировали, к чему могут привести прогнозы, основанные на неаккуратно сделанной выборке. Авторитетное издание Литерари дайджест, много лет удивлявшее американцев своими точными прогнозами, предсказывало поражение Рузвельта. Журнал разослал десять миллионов опросных листов владельцам телефонов и автомобилей, и обработал два миллиона ответов. К сожалению, выборка журнала была не беспристрастной. В нее попали преимущественно более обеспеченные слои общества, которые были недовольны «Новым курсом», и жаждали перемен.
Визуализация данных
Для начала данные полезно представить в наглядном виде. Это может быть диаграмма ствол и листья, диаграмма рассеяния или что-то еще. Важно, чтобы визуальный образ содержал все данные.
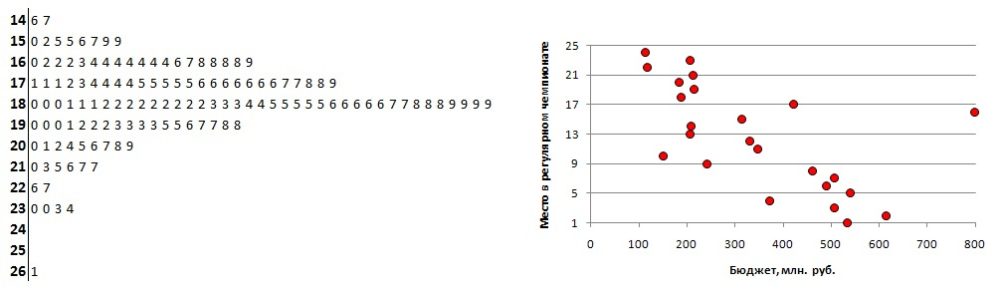
Визуализация данных выборки: (а) диаграмма «ствол и листья», (б) диаграмма рассеяния; чтобы увеличить изображение кликните на нем правой кнопкой мыши и выберите Открыть картинку в новой вкладке
Диаграмма «ствол и листья» была предложена Тьюки еще до эры ПК (Excel не строит эту диаграмму автоматически). На рисунке представлены средние температуры июля в Москве, начиная с 1879 г. Например, число 18,9°C состоит из ствола 18 и листа 9. На диаграмме легко увидеть минимальное (14,6°С) и максимальное (26,1°С) значения. Большинство данных попадают в диапазон 16…20°С, а сами значения образуют распределение близкое к нормальному со средним около 18°С, и довольно широким хвостом в области больших значений. Также можно увидеть, что значение 26,1°С не просто максимально, а экстремально. Помните жару 2010 г.?
Диаграмма рассеяния на рисунке показывает для чемпионата КХЛ обратную зависимость места, занятого в сезоне 2008–2009, от бюджета клуба.
Сводки данных
Вместо демонстрации всех данных выборку удобно представить несколькими числами – сводками данных, среди которых наиболее известны:
- меры центральной тенденции: среднее, медиана и мода;
- меры рассеяния (разброса): размах, дисперсия, стандартное отклонение.
Несмотря на то, что сводки очень полезны, не забывайте, что они могут скрывать важные подробности. Наверное, самой популярной сводкой является среднее значение. Однако, использование среднего негласно подразумевает, что распределение генеральной совокупности близко к нормальному.
Допустим вы измерили средний рост 100 случайно взятых людей, и получили значение 1,650 м. Добавление к этой выборке самого высокого человека в мире с ростом 2,51 м, увеличит среднее 101 человека менее чем на сантиметр до 1,659 м.
По данным Credit Suisse богатство в мире на одного взрослого человека составляет в среднем $51 600. Если к 100 случайным людям добавить Джеффа Безоса, самого богатого на планете, то среднее для этих 101 человека взлетит до $1,49 млрд.
Всё дело в том, что рост людей на планете подчиняется нормальному распределению, а богатство – нет.
Среднее значение чувствительно к выбросам. Более универсальным показателем меры центральной тенденции является медиана – такое число, что половина из элементов выборки больше него, а другая половина меньше. Длинный хвост практически не влияет на медиану.
Блочная диаграмма или диаграмма ящик с усами
Идеальным графическим представлением сводки данных является блочная диаграмма, введенная также Джоном Тьюки (а эту диаграмму Excel строит автоматически). Продолжая пример со средними температурами июля в Москве, ниже приведена блочная диаграмма за период 1987–2016 гг.
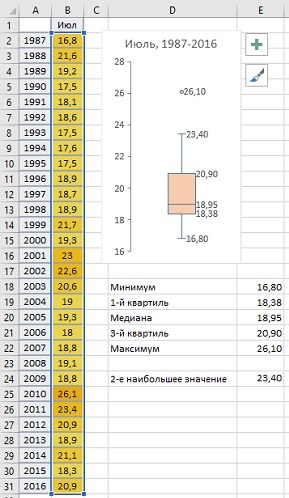
Визуализация статистических данных в Excel с помощью диаграммы ящик с усами
Джон Тьюки. Анализ результатов наблюдений. Разведочный анализ. – М.: Мир, 1981. – 696 с. Конспект: https://baguzin.ru/wp/?p=15897
Дуглас Хаббард. Как измерить всё, что угодно. Оценка стоимости нематериального в бизнесе. – М.: Олимп-Бизнес, 2009. – 320 с. Конспект: https://baguzin.ru/wp/?p=2511
Малые выборки в конкурентной разведке: https://baguzin.ru/wp/?p=2880
Левин, Дэвид М., Стефан, Дэвид, Кребиль, Тимоти С., Беренсон, Марк Л. Статистика для менеджеров с использованием Microsoft Excel, 4-е изд. — М.: Издательский дом «Вильямс», 2004. — 1312 с. Конспект: https://baguzin.ru/wp/?p=5285
Сара Бослаф. Статистика для всех. – М.: ДМК Пресс, 2017. – 586. Конспект: https://baguzin.ru/wp/?p=19047
Визуализация статистических данных с помощью диаграммы ящик с усами: https://baguzin.ru/wp/?p=17422