
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel 2021 Excel 2021 для Mac Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel 2010 Excel 2007 Еще…Меньше
Если вам нужно разработать сложный статистический или инженерный анализ, вы можете сэкономить время и этапы с помощью этого средства. Вы предоставляете данные и параметры для каждого анализа, а средство использует соответствующие статистические или инженерные функции для вычисления и отображения результатов в выходной таблице. Некоторые средства создают диаграммы в дополнение к выходным таблицам.
Функции анализа данных можно применять только на одном листе. Если анализ данных проводится в группе, состоящей из нескольких листов, то результаты будут выведены на первом листе, на остальных листах будут выведены пустые диапазоны, содержащие только форматы. Чтобы провести анализ данных на всех листах, повторите процедуру для каждого листа в отдельности.
Ниже описаны инструменты, включенные в пакет анализа. Для доступа к ним нажмите кнопкуАнализ данных в группе Анализ на вкладке Данные. Если команда Анализ данных недоступна, необходимо загрузить надстройку «Пакет анализа».
-
Откройте вкладку Файл, нажмите кнопку Параметры и выберите категорию Надстройки.
-
В раскрывающемся списке Управление выберите пункт Надстройки Excel и нажмите кнопку Перейти.
Если вы используете Excel для Mac, в строке меню откройте вкладку Средства и в раскрывающемся списке выберите пункт Надстройки для Excel.
-
В диалоговом окне Надстройки установите флажок Пакет анализа, а затем нажмите кнопку ОК.
-
Если Пакет анализа отсутствует в списке поля Доступные надстройки, нажмите кнопку Обзор, чтобы выполнить поиск.
-
Если выводится сообщение о том, что пакет анализа не установлен на компьютере, нажмите кнопку Да, чтобы установить его.
-
Примечание: Чтобы включить Visual Basic для приложений (VBA) для надстройки «Надстройка анализа», вы можете загрузить надстройку VBA так же, как и надстройку «Надстройка анализа». В поле Доступные надстройки выберите «Надстройка анализа — VBA».
Существует несколько видов дисперсионного анализа. Нужный вариант выбирается с учетом числа факторов и имеющихся выборок из генеральной совокупности.
Однофакторный дисперсионный анализ
Этот инструмент выполняет простой анализ дисперсии данных для двух или более выборок. Анализ дает проверку гипотезы о том, что каждая выборка взята из одного и того же распределения вероятности на основе альтернативной гипотезы о том, что для всех выборок распределение вероятности не одно и то же. Если есть только два примера, можно использовать функцию T.ТЕСТ. В более чем двух примерах нет удобного обобщения T.ВМЕСТОэтого можно использовать модель Anova для одного фактора.
Двухфакторный дисперсионный анализ с повторениями
Этот инструмент анализа применяется, если данные можно систематизировать по двум параметрам. Например, в эксперименте по измерению высоты растений последние обрабатывали удобрениями от различных изготовителей (например, A, B, C) и содержали при различной температуре (например, низкой и высокой). Таким образом, для каждой из 6 возможных пар условий {удобрение, температура}, имеется одинаковый набор наблюдений за ростом растений. С помощью этого дисперсионного анализа можно проверить следующие гипотезы:
-
Извлечены ли данные о росте растений для различных марок удобрений из одной генеральной совокупности. Температура в этом анализе не учитывается.
-
Извлечены ли данные о росте растений для различных уровней температуры из одной генеральной совокупности. Марка удобрения в этом анализе не учитывается.
Извлечены ли шесть выборок, представляющих все пары значений {удобрение, температура}, используемые для оценки влияния различных марок удобрений (для первого пункта в списке) и уровней температуры (для второго пункта в списке), из одной генеральной совокупности. Альтернативная гипотеза предполагает, что влияние конкретных пар {удобрение, температура} превышает влияние отдельно удобрения и отдельно температуры.
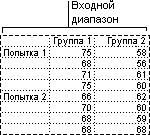
Двухфакторный дисперсионный анализ без повторений
Этот инструмент анализа применяется, если данные можно систематизировать по двум параметрам, как в случае двухфакторного дисперсионного анализа с повторениями. Однако в таком анализе предполагается, что для каждой пары параметров есть только одно измерение (например, для каждой пары параметров {удобрение, температура} из предыдущего примера).
Функции CORREL и PEARSON вычисляют коэффициент корреляции между двумя переменными измерения, если для каждой переменной наблюдаемы измерения по каждому из N-объектов. (Любые отсутствующие наблюдения по любой теме вызывают игнорирование в анализе.) Средство анализа корреляции особенно удобно использовать, если для каждого субъекта N имеется более двух переменных измерения. Она содержит выходную таблицу — матрицу корреляции, которая показывает значение CORREL (или PEARSON),примененного к каждой из возможных пар переменных измерения.
Коэффициент корреляции, как и ковариана, — это мера степени, в которой две единицы измерения «различаются». В отличие от ковариации коэффициент корреляции масштабирован таким образом, что его значение не зависит от единиц измерения, выраженных в двух переменных измерения. (Например, если двумя переменными измерения являются вес и высота, то значение коэффициента корреляции не изменяется, если вес преобразуется из фунта в фунты.) Значение любого коэффициента корреляции должно быть включительно от -1 до +1 включительно.
Корреляционный анализ дает возможность установить, ассоциированы ли наборы данных по величине, т. е. большие значения из одного набора данных связаны с большими значениями другого набора (положительная корреляция) или наоборот, малые значения одного набора связаны с большими значениями другого (отрицательная корреляция), или данные двух диапазонов никак не связаны (нулевая корреляция).
Средства корреляции и коварианс могут использоваться в одном и том же параметре, если у вас есть N различных переменных измерения, наблюдаемые для набора людей. Каждый из инструментов корреляции и ковариции дает выходную таблицу — матрицу, которая показывает коэффициент корреляции или коварианс между каждой парой переменных измерения соответственно. Разница заключается в том, что коэффициенты корреляции масштабироваться в зависимости от -1 и +1 включительно. Соответствующие ковариансы не масштабироваться. Коэффициент корреляции и коварианс — это показатели степени, в которой две переменные «различаются».
Инструмент Ковариана вычисляет значение функции КОВАРИАНА. P для каждой пары переменных измерения. (Прямое использование КОВАРИАНА. P вместо ковариана является разумной альтернативой, если есть только две переменные измерения, то есть N=2.) Запись в диагонали выходной таблицы средства Коварица в строке i, столбце i — коварианс i-й переменной измерения. Это только дисперсия по численности населения для этой переменной, вычисляемая функцией ДИСПЕРС.P.
Ковариационный анализ дает возможность установить, ассоциированы ли наборы данных по величине, то есть большие значения из одного набора данных связаны с большими значениями другого набора (положительная ковариация) или наоборот, малые значения одного набора связаны с большими значениями другого (отрицательная ковариация), или данные двух диапазонов никак не связаны (ковариация близка к нулю).
Инструмент анализа «Описательная статистика» применяется для создания одномерного статистического отчета, содержащего информацию о центральной тенденции и изменчивости входных данных.
Инструмент анализа «Экспоненциальное сглаживание» применяется для предсказания значения на основе прогноза для предыдущего периода, скорректированного с учетом погрешностей в этом прогнозе. При анализе используется константа сглаживания a, величина которой определяет степень влияния на прогнозы погрешностей в предыдущем прогнозе.
Примечание: Для константы сглаживания наиболее подходящими являются значения от 0,2 до 0,3. Эти значения показывают, что ошибка текущего прогноза установлена на уровне от 20 до 30 процентов ошибки предыдущего прогноза. Более высокие значения константы ускоряют отклик, но могут привести к непредсказуемым выбросам. Низкие значения константы могут привести к большим промежуткам между предсказанными значениями.
Двухвыборочный F-тест применяется для сравнения дисперсий двух генеральных совокупностей.
Например, можно использовать F-тест по выборкам результатов заплыва для каждой из двух команд. Это средство предоставляет результаты сравнения нулевой гипотезы о том, что эти две выборки взяты из распределения с равными дисперсиями, с гипотезой, предполагающей, что дисперсии различны в базовом распределении.
С помощью этого инструмента вычисляется значение f F-статистики (или F-коэффициент). Значение f, близкое к 1, показывает, что дисперсии генеральной совокупности равны. В таблице результатов, если f < 1, «P(F <= f) одностороннее» дает возможность наблюдения значения F-статистики меньшего f при равных дисперсиях генеральной совокупности и F критическом одностороннем выдает критическое значение меньше 1 для выбранного уровня значимости «Альфа». Если f > 1, «P(F <= f) одностороннее» дает возможность наблюдения значения F-статистики большего f при равных дисперсиях генеральной совокупности и F критическом одностороннем дает критическое значение больше 1 для «Альфа».
Инструмент «Анализ Фурье» применяется для решения задач в линейных системах и анализа периодических данных на основе метода быстрого преобразования Фурье (БПФ). Этот инструмент поддерживает также обратные преобразования, при этом инвертирование преобразованных данных возвращает исходные данные.

Инструмент «Гистограмма» применяется для вычисления выборочных и интегральных частот попадания данных в указанные интервалы значений. При этом рассчитываются числа попаданий для заданного диапазона ячеек.
Например, можно получить распределение успеваемости по шкале оценок в группе из 20 студентов. Таблица гистограммы состоит из границ шкалы оценок и групп студентов, уровень успеваемости которых находится между самой нижней границей и текущей границей. Наиболее часто встречающийся уровень является модой диапазона данных.
Совет: В Excel 2016 теперь можно создавать гистограммы и диаграммы Парето.
Инструмент анализа «Скользящее среднее» применяется для расчета значений в прогнозируемом периоде на основе среднего значения переменной для указанного числа предшествующих периодов. Скользящее среднее, в отличие от простого среднего для всей выборки, содержит сведения о тенденциях изменения данных. Этот метод может использоваться для прогноза сбыта, запасов и других тенденций. Расчет прогнозируемых значений выполняется по следующей формуле:
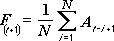
где
-
N — число предшествующих периодов, входящих в скользящее среднее;
-
A
j — фактическое значение в момент времени j; -
F
j — прогнозируемое значение в момент времени j.
Инструмент «Генерация случайных чисел» применяется для заполнения диапазона случайными числами, извлеченными из одного или нескольких распределений. С помощью этой процедуры можно моделировать объекты, имеющие случайную природу, по известному распределению вероятностей. Например, можно использовать нормальное распределение для моделирования совокупности данных по росту людей или использовать распределение Бернулли для двух вероятных исходов, чтобы описать совокупность результатов бросания монеты.
Средство анализа Ранг и процентиль создает таблицу, которая содержит порядковую и процентную ранг каждого значения в наборе данных. Можно проанализировать относительное положение значений в наборе данных. В этом средстве используются функции РАНГ. EQ и PERCENTRANK. INC. Если вы хотите учитывать связанные значения, используйте РАНГ. Функция EQ, которая обрабатывает связанные значения как имеющие одинаковый ранг или использует РАНГ.Функция AVG, которая возвращает средний ранг связанных значений.
Инструмент анализа «Регрессия» применяется для подбора графика для набора наблюдений с помощью метода наименьших квадратов. Регрессия используется для анализа воздействия на отдельную зависимую переменную значений одной или нескольких независимых переменных. Например, на спортивные качества атлета влияют несколько факторов, включая возраст, рост и вес. Можно вычислить степень влияния каждого из этих трех факторов по результатам выступления спортсмена, а затем использовать полученные данные для предсказания выступления другого спортсмена.
В средстве регрессии используется функция LINEST.
Инструмент анализа «Выборка» создает выборку из генеральной совокупности, рассматривая входной диапазон как генеральную совокупность. Если совокупность слишком велика для обработки или построения диаграммы, можно использовать представительную выборку. Кроме того, если предполагается периодичность входных данных, то можно создать выборку, содержащую значения только из отдельной части цикла. Например, если входной диапазон содержит данные для квартальных продаж, создание выборки с периодом 4 разместит в выходном диапазоне значения продаж из одного и того же квартала.
Двухвыборочный t-тест проверяет равенство средних значений генеральной совокупности по каждой выборке. Три вида этого теста допускают следующие условия: равные дисперсии генерального распределения, дисперсии генеральной совокупности не равны, а также представление двух выборок до и после наблюдения по одному и тому же субъекту.
Для всех трех средств, перечисленных ниже, значение t вычисляется и отображается как «t-статистика» в выводимой таблице. В зависимости от данных это значение t может быть отрицательным или неотрицательным. Если предположить, что средние генеральной совокупности равны, при t < 0 «P(T <= t) одностороннее» дает вероятность того, что наблюдаемое значение t-статистики будет более отрицательным, чем t. При t >=0 «P(T <= t) одностороннее» делает возможным наблюдение значения t-статистики, которое будет более положительным, чем t. «t критическое одностороннее» дает пороговое значение, так что вероятность наблюдения значения t-статистики большего или равного «t критическое одностороннее» равно «Альфа».
«P(T <= t) двустороннее» дает вероятность наблюдения значения t-статистики, по абсолютному значению большего, чем t. «P критическое двустороннее» выдает пороговое значение, так что значение вероятности наблюдения значения t- статистики, по абсолютному значению большего, чем «P критическое двустороннее», равно «Альфа».
Парный двухвыборочный t-тест для средних
Парный тест используется, когда имеется естественная парность наблюдений в выборках, например, когда генеральная совокупность тестируется дважды — до и после эксперимента. Этот инструмент анализа применяется для проверки гипотезы о различии средних для двух выборок данных. В нем не предполагается равенство дисперсий генеральных совокупностей, из которых выбраны данные.
Примечание: Одним из результатов теста является совокупная дисперсия (совокупная мера распределения данных вокруг среднего значения), вычисляемая по следующей формуле:
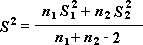
Двухвыборочный t-тест с одинаковыми дисперсиями
Этот инструмент анализа выполняет t-тест для двух образцов учащихся. В этой форме t-test предполагается, что два набора данных поступили из распределения с одинаковыми дисперсиями. Его называют гомике t-тестом. Этот t-тест можно использовать для определения вероятности того, что эти две выборки взяты из распределения с равными средствами распределения.
Двухвыборочный t-тест с различными дисперсиями
Этот инструмент анализа выполняет t-тест для двух образцов учащихся. В этой форме t-test предполагается, что два набора данных были полученными из распределения с неравными дисперсиями. Его называют гетероскестическими t-тестами. Как и в предыдущем примере с равными дисперсиями, этот t-тест можно использовать для определения вероятности того, что эти две выборки взяты из распределения с равными средствами распределения. Этот тест можно использовать, если в двух примерах есть отдельные объекты. Используйте тест Парный, описанный в примере, если существует один набор тем и две выборки представляют измерения по каждой теме до и после обработки.
Для определения тестовой величины t используется следующая формула.
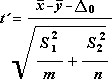
Следующая формула используется для вычисления степеней свободы (df). Так как результат вычисления обычно не является integer, значение df округлится до ближайшего другого, чтобы получить критическое значение из таблицы t. Функция Excel T .Test использует вычисляемую величину df без округлений, так как можно вычислить значение для T.ТЕСТ с неинтегрированной df. Из-за этих разных подходов к определению степеней свободы результаты T.Тест и этот t-тест будут отличаться в случае неравных дисперсий.
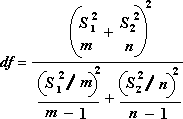
Z-тест. Средство анализа «Две выборки для середины» выполняет два примера z-теста для средств со известными дисперсиями. Этот инструмент используется для проверки гипотезы NULL о том, что между двумя значениями численности населения нет различий между односторонними или двухбокльными альтернативными гипотезами. Если дисперсии не известны, функция Z .Вместо этого следует использовать тест.
При использовании этого инструмента следует внимательно просматривать результат. «P(Z <= z) одностороннее» на самом деле есть P(Z >= ABS(z)), вероятность z-значения, удаленного от 0 в том же направлении, что и наблюдаемое z-значение при одинаковых средних значениях генеральной совокупности. «P(Z <= z) двустороннее» на самом деле есть P(Z >= ABS(z) или Z <= -ABS(z)), вероятность z-значения, удаленного от 0 в том же направлении, что и наблюдаемое z-значение при одинаковых средних значениях генеральной совокупности. Двусторонний результат является односторонним результатом, умноженным на 2. Инструмент «z-тест» можно также применять для гипотезы об определенном ненулевом значении разницы между двумя средними генеральных совокупностей. Например, этот тест можно использовать для определения разницы выступлений на соревнованиях двух автомобилей разных марок.
Дополнительные сведения
Вы всегда можете задать вопрос специалисту Excel Tech Community или попросить помощи в сообществе Answers community.
См. также
Создание гистограммы в Excel 2016
Создание диаграммы Парето в Excel 2016
Загрузка средства анализа в Excel
Инженерные функции (справка)
Общие сведения о формулах в Excel
Рекомендации, позволяющие избежать появления неработающих формул
Поиск ошибок в формулах
Сочетания клавиш и горячие клавиши в Excel
Функции Excel (по алфавиту)
Функции Excel (по категориям)
Нужна дополнительная помощь?
-
Использование пакета анализа
Пакет
анализа представляет собой надстройку
Excel–
набор средств
и инструментов, расширяющих стандартные
возможности Excel,
связанные с анализом данных.
Возможности
надстройки Пакет
анализа данных:
1. Однофакторный
дисперсионный анализ.
2. Двухфакторный
дисперсионный анализ с повторениями.
3. Двухфакторный
дисперсионный анализ без повторений.
4. Корреляция.
5. Ковариация.
6. Описательная
статистика.
7. Экспоненциальное
сглаживание.
8.Двухвыборочный
F-тест для дисперсий.
9. Анализ Фурье.
10. Гистограмма.
11. Скользящее
среднее.
12. Генерация
случайных чисел.
13. Ранг и перцентиль.
14. Регрессия.
15. Выборка.
16. Парный
двухвыборочный t-тест для средних.
17.Двухвыборочный
t-тест с одинаковыми дисперсиями.
18.Двухвыборочный
t-тест с разными дисперсиями.
19.Двухвыборочный
z-тест для средних.
Для
того, чтобы воспользоваться одним из
инструментов Пакета
анализа
исследуемые данные следует представить
в виде таблицы, где столбцами являются
соответствующие показатели. При создании
таблицы Excel информация вводится в
отдельные ячейки. Совокупность ячеек,
содержащих анализируемые данные,
называется входным интервалом.
Для
того, чтобы воспользоваться набором
средств и инструментов Пакет
анализа
необходимо произвести его установку.
Необходимо выполнить следующие действия:
Открыть
панель быстрого доступа. И из меню
выбрать Другие
команды.

Рис.Вызов окна ПараметрыExcel
Появится диалоговое
окно Параметры
Excel,
в правом окне выбрать функцию Пакет
анализа VBA.

Рис.Настройка Пакета анализа.
Щелкнуть
по кнопке Перейти
и нажать на ОК.
Появиться диалоговое окно Надстройки.
Рис.Диалоговое окно Настройки.
Ставим
флажок в поле Пакет
анализа и
подтверждаем свой выбор нажатием на
клавишу ОК.
Т.о. установили пакет анализа.
Для
дальнейшей работы на ленте выбираем
вкладку Данные.
И выбираем функцию Анализ
данных.
Рис.Вызов функции Анализ данных.
Далее
выбираем команду Данные
→ Анализ
→ Анализ
данных. В
списке Инструменты
анализа
открывшегося окна выберите пункт
Описательная
статистика
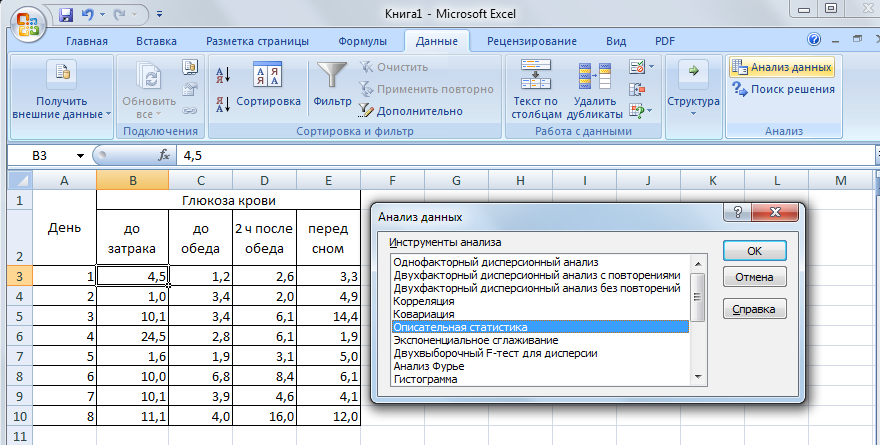 Рис.Работа с функцией Анализ данных
Рис.Работа с функцией Анализ данных
Появляется
диалоговое окно Описательная
статистика.
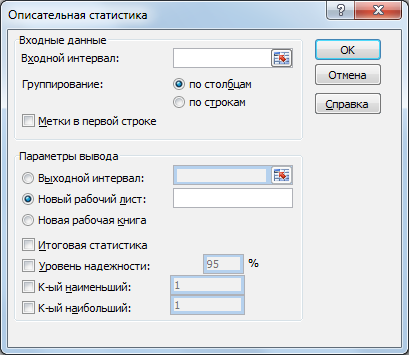
Рис.Диалоговое окно Описательная
статистика
Заполните
окно параметров статистики следующим
образом:
В
поле Входной
интервал –
диапазон ячеек с данными для статанализа,
в поле Выходной
интервал –
адрес ячейки, куда запишется результат
анализа.В параметрах вывода, устанавливаем
флажок в поле Итоговая
статистика
и нажимаем на ОК.

Рис.Ввод данных с диалоге Описательная
статистика
В результате
произведенных операций получим
рассчитанные показатели описательной
статистики.
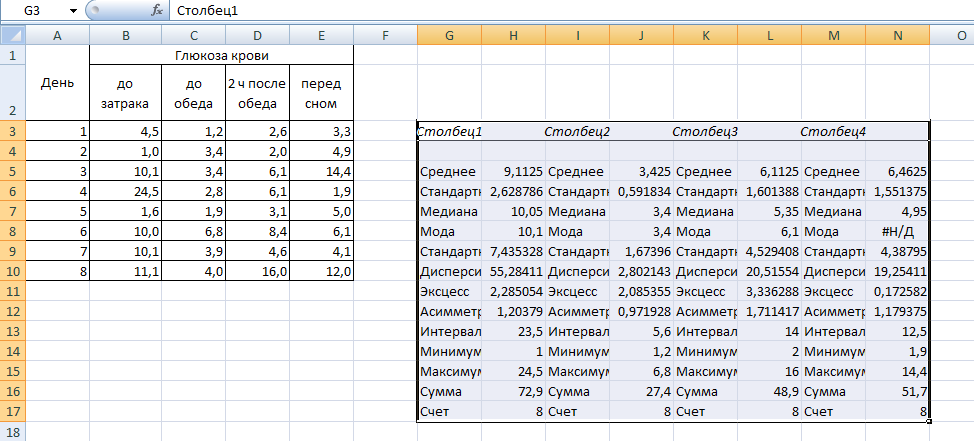
Рис. Результаты Описательной
статистики.
-
Диаграммы.
Диаграмма
– это способ наглядного представления
информации, заданной в виде таблицы
чисел. Демонстрация данных с помощью
диаграмм является более наглядной и
эффективной для восприятия.
Создание диаграммы
Диаграммы строятся
на основе данных, содержащихся на рабочем
листе, поэтому перед созданием диаграммы
они должны быть введены. Диаграммы в
Excel динамические, т. е. автоматически
обновляются после изменения данных, на
основе которых построены. Диаграмма
может быть размещена как на листе с
данными, так и на отдельном листе (занимая
весь лист).
По умолчанию
диаграмма состоит из следующих элементов:
• Ряды
данных –
представляют главную ценность, т.к.
визуализируют данные;
• Легенда
– содержит названия рядов и пример их
оформления;
• Оси
– шкала с определенной ценой промежуточных
делений;
• Область
построения
– является фоном для рядов данных;
• Линии
сетки.
Помимо упомянутых
выше объектов, могут быть добавлены
такие как:
• Названия
диаграммы;
• Линий
проекции –
нисходящие от рядов данных на горизонтальную
ось линии;
• Линия
тренда;
• Подписи
данных –
числовое значение для точки данных
ряда;
• И другие нечасто
используемые элементы.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
![]()
![]()
КУРС
EXCEL ACADEMY
Научитесь использовать все прикладные инструменты из функционала MS Excel.
Если вы ищете работу и она хоть как-то связана с математикой/экономикой/финансами, то вы очень часто будете встречать такие требования к кандидату:
— Отличное знание статистики;
— Знание и умение Python/R, чтобы эту статистику применять.
Но что делать, если никаких знаний по языкам программирования у вас нет, а встречаться со статистическими моделями так или иначе придется? А работу-то найти нужно срочно…
К счастью, в версии Microsoft Excel выше 2010 вшит целый статистический пакет. О нем мало кто знает, а его реально можно использовать, если нет навыков программирования или доступного компилятора под рукой.
Для начала поговорим, где все эти формулы найти. Как обычно, переходим на вкладку «Формулы» на главной панели, выбираем «Другие функции» и пакет «Статистические». Перед Вами полный перечень статистических возможностей Excel.
Как вы можете видеть, формул в этом разделе представлено довольно много, как «ходовых», так и «узкоспециализированных». К сожалению, разобрать все в одной статье не получится, поэтому рассмотрим здесь самые часто встречающиеся. Если вы хотите познакомиться с математическими функциями Excel, то рекомендуем скачать наш бесплатный гайд.
На первый взгляд они могут показаться очень простыми. Однако, мы постарались раскрыть те моменты, которые обычно остаются без внимания и могут быть полезными.
СРЗНАЧ() и СРЗНАЧА()
Редко кто задумывался, а ведь вычисление среднего значения – сугубо статистическая процедура: именно поэтому это операция и помещена в статистический пакет.
Наверно, особо не стоит останавливаться на правилах использования формулы: функция СРЗНАЧ() принимает на вход массив аргументов и дает на выходе среднее значение по всем ячейкам, содержащим числа(!). Это очень важный момент, который далеко не все знают. Поясним на примере.
Пусть дан диапазон А1:С2 и мы ищем среднее значение по всем 6 ячейкам диапазона:
Однако, результат функции СРЗНАЧ(А1:С2) будет не 8,7, а 13. Почему? (4+15+11+22)/6 = 8,7 ведь?
Да, это правильно, но функция СРЗНАЧ() берет в расчет только те ячейки, где «встречает» числа. Текстовая информация и пустые ячейки просто игнорируются. Поэтому в данном примере СРЗНАЧ() усредняет по 4 ячейкам и выдает правильный ответ – 13.
А вот если нужно произвести усреднение по всему диапазону, вне зависимости от типа данных, нужно использовать функцию СРЗНАЧА().
Принцип работы такой же, как и у СРЗНАЧ(), только на вход будут поступать абсолютно все ячейки. Результат в нашем примере будет уже ожидаемый – 8,7.
Замечание
Выбор той или иной функции происходит в зависимости от задачи. В реальной жизни они могут понадобится в одинаковой мере.
Например, менеджеру нужно узнать среднедневную выручку за месяц на основании продаж за каждый день. Допустим, за несколько дней ячейки оставлены пустыми. Есть два варианта, почему так произошло:
1. В эти дни не было ни одной продажи. Тогда эти дни должны принимать участие в расчете среднего значения и менеджеру нужно использовать СРЗНАЧА() – так он исключит игнорирование пустых ячеек.
2. Эти дни были выходными. Тогда пропуски сами по себе никакой информации не несут и их надо игнорировать: фактически, эти дни не принимают участие в статистической выборке и функция СРЗНАЧ() поможет их пропустить.
![]()
КУРС
EXCEL ACADEMY
Научитесь использовать все прикладные инструменты из функционала MS Excel.
СРЗНАЧЕСЛИ()
Очевидно, что функция СРЗНАЧЕСЛИ() возвращает среднее тех значений, который удовлетворяют каким-то условиям. Помимо этого, условия можно накладывать не только на сами значения, но и на другие ячейки. Проиллюстрируем.
Например, вычислим среднее значение всех ячеек, которые больше нуля:
Мы выделили диапазон А1:С3 и наложили на него условие – «>0». А можно сделать по-другому.
Рассмотрим таблицу, в которую занесены продажи лекарств в городе. Посчитаем среднюю цену Анальгина по всему городу. Для этого наложим условие уже не на саму цену, а на название лекарства.
Формула записывается так:
=СРЗНАЧЕСЛИ(Диапазон_на_который_накладываем_условия; “Условие”; Диапазон_по_которому_считаем_среднее_значение)
В нашем случае это примет вид:
Кстати говоря, условия можно комбинировать с помощью функции СРЗНАЧЕСЛИМН().
Предположим, что в аптеке Зеленый Крест продается несколько видов Анальгина и в нашу таблицу они все занесены как Анальгин.
Тогда, чтобы усреднить цену всех Анальгинов в аптеке Зеленый Крест, нужно просто использовать формулу:
=СРЗНАЧЕСЛИМН(С2:С13; A2:A13; “зеленый крест”;B2:B13; “анальгин”)
Обратите внимание: диапазон усреднения указывается в конце только при использовании функции СРЗНАЧЕСЛИ() с дополнительным условием. В остальных случаях диапазон ячеек, по которым вычисляется среднее значение, стоит первым.
МИН()/МАКС() и НАИБОЛЬШИЙ()/НАИМЕНЬШИЙ()
На первый взгляд, разница между этими функциями не особо прослеживается, хотя зачем их используют – очевидно – найти самое большое или маленькое число. Однако, в работе этих функций есть небольшая, но очень полезная разница. Разберем подробней.
Функция МИН() просто принимает массив аргументов и находит самое маленькое число. МАКС() – самое большое. Все просто.
Функция НАИМЕНЬШИЙ() же находит n-ое наименьшее число в массиве. НАИБОЛЬШИЙ(), наоборот, находит n-ое наибольшее число.
Например, нужно найти пятое по величине число. Вводим:
=НАИБОЛЬШИЙ(диапазон; 5).
Фактически, получается, что результат работы НАИБОЛЬШИЙ(массив;1) и МАКС(массив) – одно и то же. Аналогичная ситуация с НАИМЕНЬШИЙ(массив;1) и МИН(массив).
Рекомендуем записаться на наш открытый онлайн-курс «Аналитика в Excel», если вы хотите научиться выполнять рутинную работу быстрее.
МЕДИАНА() и МОДА()
Общеизвестные и достаточно важные статистические характеристики моды и медианы вычисляются по одноименным формулам.
Напомним, что медианой называется «середина» числового множества.
Например, если есть массив чисел от одного до десяти, то медианой будет число 5,5 (хотя оно само в массив не входит). Это из-за того, что количество элементов в массиве – четно и выбрать «центральное» просто невозможно.
Вот если бы выборка начиналась не с единицы, а с двойки, то ответ был бы ровно 6.
Теперь перейдем к моде. Мода – самое часто встречающееся число в выборке.
У функции нахождения моды есть целых три модификации в Excel старшее версии 2010 года: МОДА(), МОДА.ОДН() и МОДА.НСК().
Функция МОДА() оставлена для совместимости – ей, в целом, можно пользоваться: она работает совершенно аналогично функции МОДА.ОДН().
«ОДН» в названии функции значит, что, если в выборке несколько самых часто встречающихся элементов, то возвращено в качестве ответа будет только первое.
Для подсчета всех мод в выборке нужно использовать функцию МОДА.НСК().
Работает МОДА.НСК() следующим образом: выделяем побольше ячеек (если заранее не знаем, сколько мод у нас получится), в строке формул прописываем =МОДА.НСК(диапазон) и нажимаем Ctrl+Shift+Enter. Получили все моды в столбик.
Значения #Н/Д появляются, просто потому что мод у нас всего 2. Такой метод поиска мод называется «слепым» – мы просто берем побольше ячеек, чтобы наверняка хватило.
Если Вы не любите подобный «мусор» и Вам нравится, когда все красиво, можно сначала оценить: а сколько же у нас вообще будет мод? А потом просто выделить нужное количество ячеек.
Делается это так: сначала применяем функцию СЧЁТ() к нашей МОДА.НСК() – получили количество мод. А теперь выделяем только две ячейки и делаем все также, как написано выше.
Заключение
Статистический пакет Microsoft Excel содержит в себе еще огромное количество формул: проверку гипотез, принадлежность распределениям, доверительные интервалы, корреляцию и прочие инструменты, которые могут пригодиться при работе со статистикой даже на серьезном уровне.
Как мы и писали ранее, обозреть все в одной статье невозможно. Поэтому, если вы хотите узнать про менее известные, но не менее полезные статистические возможности Excel – пишите в комментариях, что вам было бы интересно и мы подготовим для вас новую статью из этого цикла.
Автор: Андрон Алексанян, СОО “Аптека-Центр”, эксперт SF Education
![]()
КУРС
EXCEL ACADEMY
Научитесь использовать все прикладные инструменты из функционала MS Excel.
Блог SF Education
MS Office
5 примеров экономии времени в Excel
Содержание статьи Что для работодателя главное в сотруднике? Добросовестность, ответственность, профессионализм и, конечно же, умение пользоваться отведенным временем! Предлагаем познакомиться с очень нужными, на…
Как работать с датами в Excel?
Содержание статьи История о том, как я пропустил свидание с очаровательной блондинкой… Вы никогда не попадали впросак из-за того, что неправильно читали дату? «Да…
Содержание
- Использование описательной статистики
- Подключение «Пакета анализа»
- Применение инструмента «Описательная статистика»
- Вопросы и ответы

Пользователи Эксель знают, что данная программа имеет очень широкий набор статистических функций, по уровню которых она вполне может потягаться со специализированными приложениями. Но кроме того, у Excel имеется инструмент, с помощью которого производится обработка данных по целому ряду основных статистических показателей буквально в один клик.
Этот инструмент называется «Описательная статистика». С его помощью можно в очень короткие сроки, использовав ресурсы программы, обработать массив данных и получить о нем информацию по целому ряду статистических критериев. Давайте взглянем, как работает данный инструмент, и остановимся на некоторых нюансах работы с ним.
Использование описательной статистики
Под описательной статистикой понимают систематизацию эмпирических данных по целому ряду основных статистических критериев. Причем на основе полученного результата из этих итоговых показателей можно сформировать общие выводы об изучаемом массиве данных.
В Экселе существует отдельный инструмент, входящий в «Пакет анализа», с помощью которого можно провести данный вид обработки данных. Он так и называется «Описательная статистика». Среди критериев, которые высчитывает данный инструмент следующие показатели:
- Медиана;
- Мода;
- Дисперсия;
- Среднее;
- Стандартное отклонение;
- Стандартная ошибка;
- Асимметричность и др.
Рассмотрим, как работает данный инструмент на примере Excel 2010, хотя данный алгоритм применим также в Excel 2007 и в более поздних версиях данной программы.
Подключение «Пакета анализа»
Как уже было сказано выше, инструмент «Описательная статистика» входит в более широкий набор функций, который принято называть Пакет анализа. Но дело в том, что по умолчанию данная надстройка в Экселе отключена. Поэтому, если вы до сих пор её не включили, то для использования возможностей описательной статистики, придется это сделать.
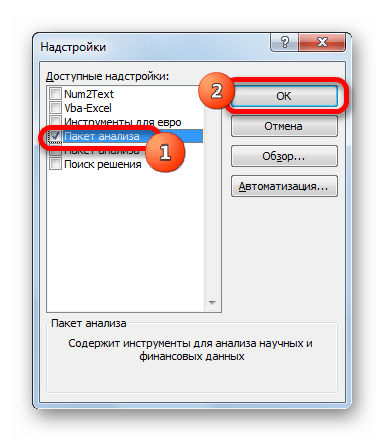
- Переходим во вкладку «Файл». Далее производим перемещение в пункт «Параметры».
- В активировавшемся окне параметров перемещаемся в подраздел «Надстройки». В самой нижней части окна находится поле «Управление». Нужно в нем переставить переключатель в позицию «Надстройки Excel», если он находится в другом положении. Вслед за этим жмем на кнопку «Перейти…».
- Запускается окно стандартных надстроек Excel. Около наименования «Пакет анализа» ставим флажок. Затем жмем на кнопку «OK».
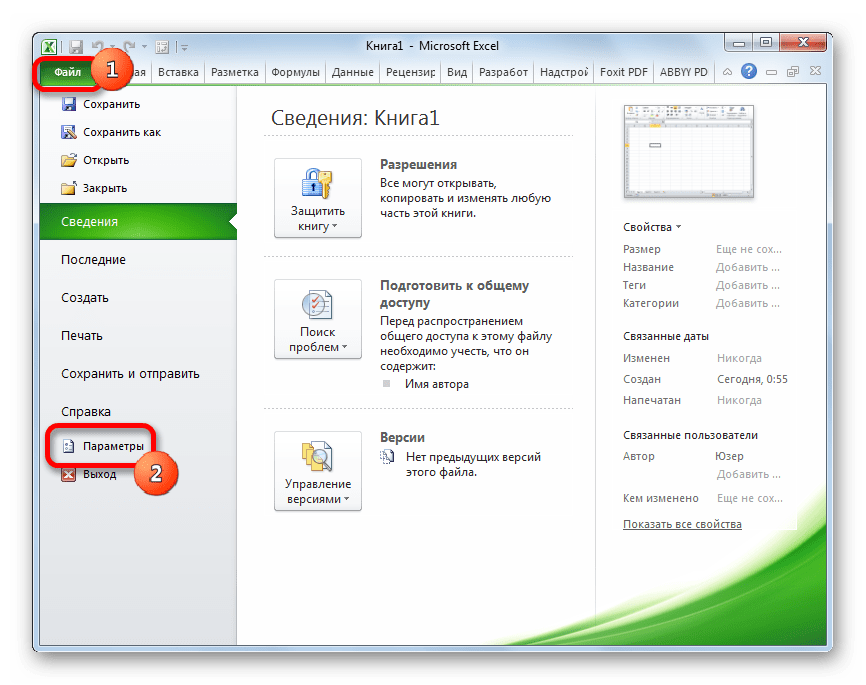
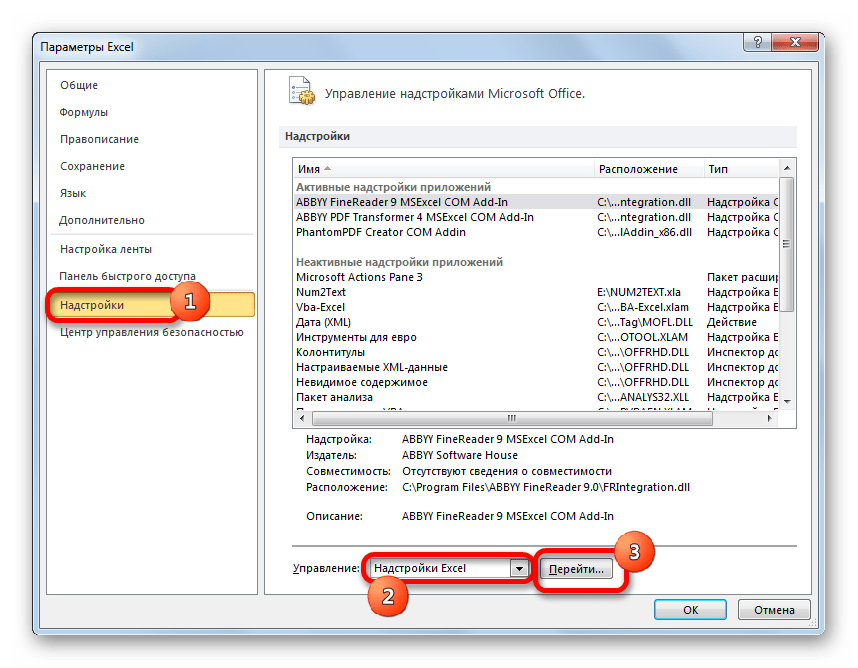
После вышеуказанных действий надстройка Пакет анализа будет активирована и станет доступной во вкладке «Данные» Эксель. Теперь мы сможем использовать на практике инструменты описательной статистики.
Применение инструмента «Описательная статистика»
Теперь посмотрим, как инструмент описательная статистика можно применить на практике. Для этих целей используем готовую таблицу.
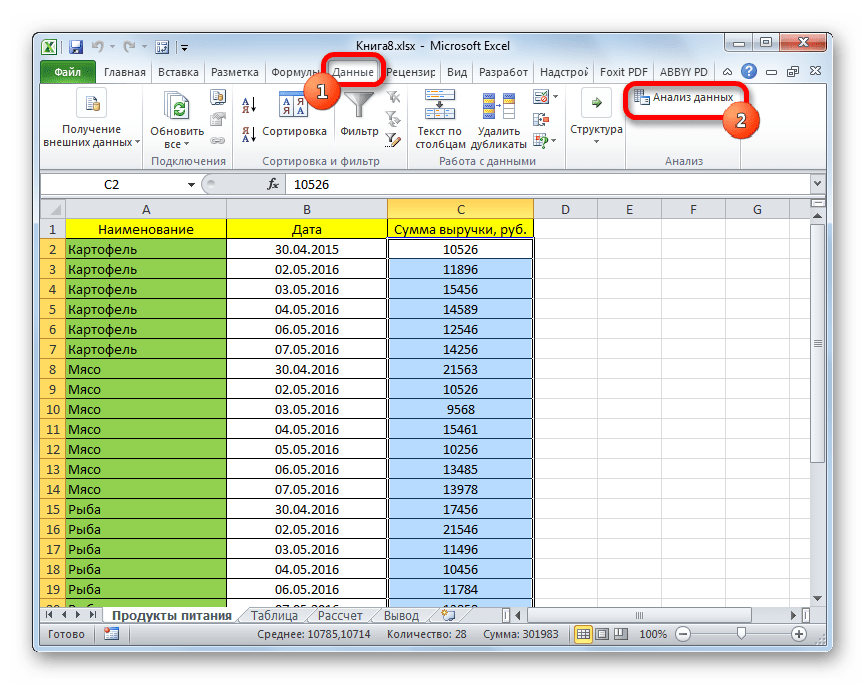
- Переходим во вкладку «Данные» и выполняем щелчок по кнопке «Анализ данных», которая размещена на ленте в блоке инструментов «Анализ».
- Открывается список инструментов, представленных в Пакете анализа. Ищем наименование «Описательная статистика», выделяем его и щелкаем по кнопке «OK».
- После выполнения данных действий непосредственно запускается окно «Описательная статистика».
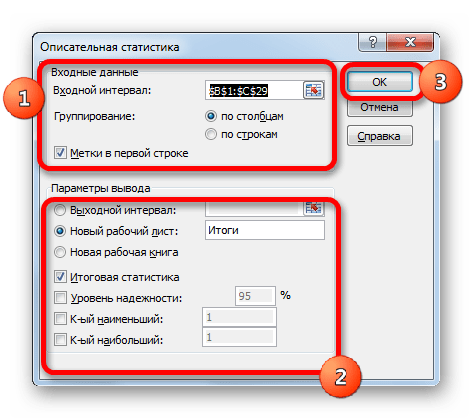
В поле «Входной интервал» указываем адрес диапазона, который будет подвергаться обработке этим инструментом. Причем указываем его вместе с шапкой таблицы. Для того, чтобы внести нужные нам координаты, устанавливаем курсор в указанное поле. Затем, зажав левую кнопку мыши, выделяем на листе соответствующую табличную область. Как видим, её координаты тут же отобразятся в поле. Так как мы захватили данные вместе с шапкой, то около параметра «Метки в первой строке» следует установить флажок. Тут же выбираем тип группирования, переставив переключатель в позицию «По столбцам» или «По строкам». В нашем случае подходит вариант «По столбцам», но в других случаях, возможно, придется выставить переключатель иначе.

Выше мы говорили исключительно о входных данных. Теперь переходим к разбору настроек параметров вывода, которые расположены в этом же окне формирования описательной статистики. Прежде всего, нам нужно определиться, куда именно будут выводиться обработанные данные:
- Выходной интервал;
- Новый рабочий лист;
- Новая рабочая книга.
В первом случае нужно указать конкретный диапазон на текущем листе или его верхнюю левую ячейку, куда будет выводиться обработанная информация. Во втором случае следует указать название конкретного листа данной книги, где будет отображаться результат обработки. Если листа с таким наименованием в данный момент нет, то он будет создан автоматически после того, как вы нажмете на кнопку «OK». В третьем случае никаких дополнительных параметров указывать не нужно, так как данные будут выводиться в отдельном файле Excel (книге). Мы выбираем вывод результатов на новом рабочем листе под названием «Итоги».
Далее, если вы хотите чтобы выводилась также итоговая статистика, то нужно установить флажок около соответствующего пункта. Также можно установить уровень надежности, поставив галочку около соответствующего значения. По умолчанию он будет равен 95%, но его можно изменить, внеся другие числа в поле справа.
Кроме этого, можно установить галочки в пунктах «K-ый наименьший» и «K-ый наибольший», установив значения в соответствующих полях. Но в нашем случае этот параметр так же, как и предыдущий, не является обязательным, поэтому флажки мы не ставим.
После того, как все указанные данные внесены, жмем на кнопку «OK».
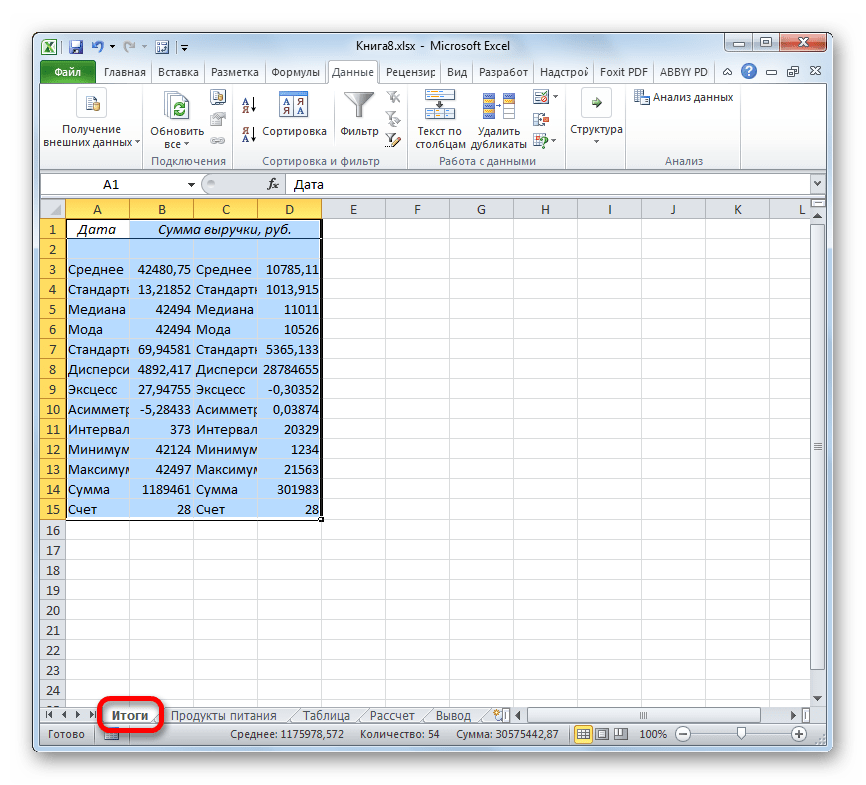
- После выполнения этих действий таблица с описательной статистикой выводится на отдельном листе, который был нами назван «Итоги». Как видим, данные представлены сумбурно, поэтому их следует отредактировать, расширив соответствующие колонки для более удобного просмотра.
- После того, как данные «причесаны» можно приступать к их непосредственному анализу. Как видим, при помощи инструмента описательной статистики были рассчитаны следующие показатели:
- Асимметричность;
- Интервал;
- Минимум;
- Стандартное отклонение;
- Дисперсия выборки;
- Максимум;
- Сумма;
- Эксцесс;
- Среднее;
- Стандартная ошибка;
- Медиана;
- Мода;
- Счет.


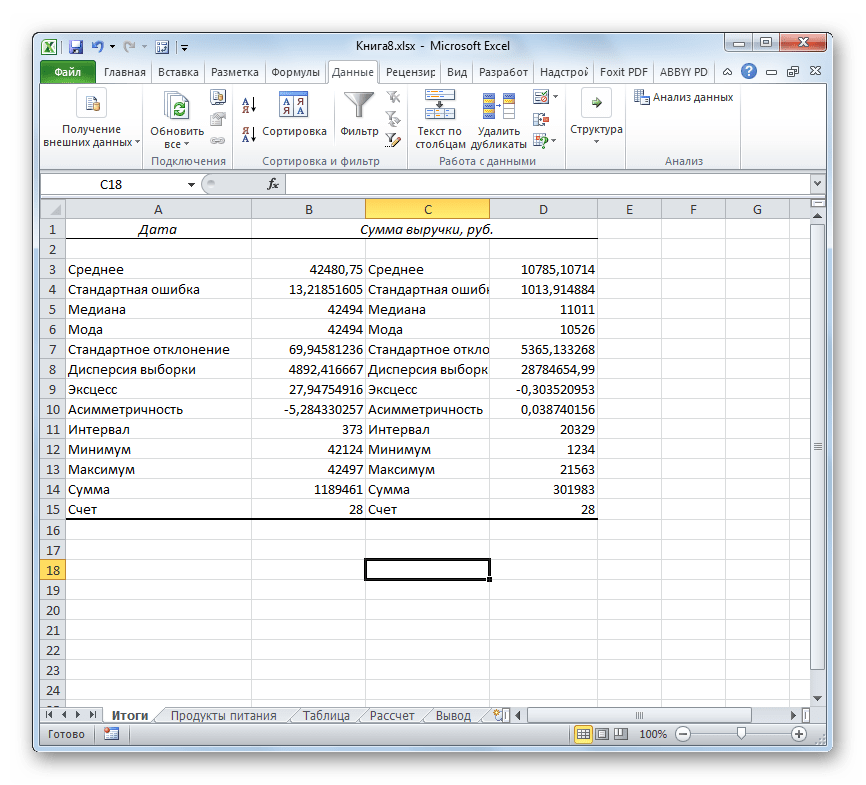
Если какие-то из вышеуказанных данных для конкретного вида анализа не нужны, то их можно удалить, чтобы они не мешали. Далее производится анализ с учетом статистических закономерностей.
Урок: Статистические функции в Excel
Как видим, с помощью инструмента «Описательная статистика» можно сразу получить результат по целому ряду критериев, которые в ином случае рассчитывались с применением отдельно предназначенной для каждого расчета функцией, что заняло бы значительное время у пользователя. А так, все эти расчеты можно получить практически в один клик, использовав соответствующий инструмент — Пакета анализа.
Еще статьи по данной теме:
Помогла ли Вам статья?
Использование надстройки «Пакет анализа», поможет упростить расчеты при проведении статистического или инженерного анали за.
Надстройка Пакет анализа ( Analysis ToolPak ) доступна из вкладки Данные , группа Анализ . Кнопка для вызова диалогового окна называется Анализ данных .
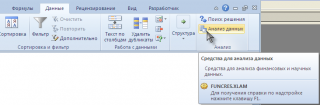
Если кнопка не отображается в указанной группе, то необходимо сначала включить надстройку (ниже дано пояснение для EXCEL 2010/2007):
- на вкладке Файл выберите команду Параметры , а затем — категорию Надстройки .
- в списке Управление (внизу окна) выберите пункт Надстройки Excel и нажмите кнопку Перейти .
- в окне Доступные надстройки установите флажок Пакет анализа и нажмите кнопку ОК.
СОВЕТ : Если пункт Пакет анализа отсутствует в списке Доступные надстройки , нажмите кнопку Обзор , чтобы найти надстройку. Файл надстройки FUNCRES.xlam обычно хранится в папке MS OFFICE, например C : Program Files Microsoft Office Office 14 Library Analysis или его можно скачать с сайта MS.
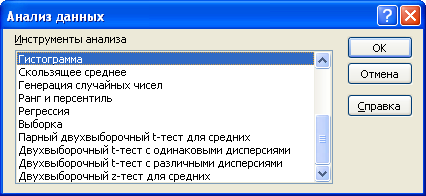
После нажатия кнопки Анализ данных будет выведено диалоговое окно надстройки Пакет анализа .
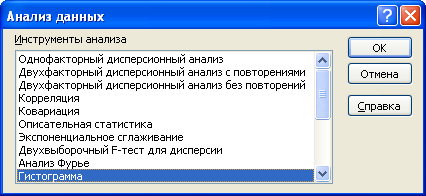
Ниже описаны средства, включенные в Пакет анализа (по теме каждого средства написана соответствующая статья – кликайте по гиперссылкам).
- Однофакторный дисперсионный анализ (ANOVA: single factor);
- Двухфакторный дисперсионный анализ с повторениями (ANOVA: two factor with replication);
- Двухфакторный дисперсионный анализ без повторений (ANOVA: two factor without replication);
- Корреляция (Correlation) ;
- Ковариация (Covariance) ;
- Описательная статистика (Descriptive Statistics) ;
- Экспоненциальное сглаживание (Exponential Smoothing);
- Двухвыборочный F-тест для дисперсии (F-test Two Sample for Variances) ;
- Анализ Фурье (Fourier Analysis);
- Гистограмма (Histogram);
- Скользящее среднее (Moving average);
- Генерация случайных чисел (Random Number Generation) ;
- Ранг и Персентиль (Rank and Percentile) ;
- Регрессия (Regression) — простая регрессия; для множественной регрессии см. здесь ;
- Выборка (Sampling) ;
- Парный двухвыборочный t-тест для средних (t-Test: Paired Two Sample for Means) ;
- Двухвыборочный t-тест с одинаковыми дисперсиями (t-Test: Two-Sample Assuming Equal Variances) ;
- Двухвыборочный t-тест с различными дисперсиями (t-Test: Two-Sample Assuming Unequal Variances) ;
- Двухвыборочный z-тест для средних (z-Test: Two Sample for Means) .