
Статистический анализ в MS Excel. Дисперсионный анализ, регрессии, метод наименьших квадратов.
Двухфакторный дисперсионный анализ с повторениями в MS EXCEL
Пусть имеется случайная переменная Y, значения которой мы можем измерять. Исследователь предполагает, что эта переменная зависит от 2-х факторов, значения которых мы можем контролировать, т.е. задавать с требуемой точностью. Покажем …
update Опубликовано: 26 января 2019
Однофакторный дисперсионный анализ (one-way ANOVA) в MS EXCEL
Пусть имеется случайная переменная Y , значения которой мы можем измерять. Исследователь предполагает, что эта переменная зависит от фактора, значения которого мы можем контролировать, т.е. задавать с требуемой точностью. Покажем …
update Опубликовано: 26 января 2019
Функция MS EXCEL ЛИНЕЙН()
Функция ЛИНЕЙН() специально создана для оценки параметров линейной регрессии, а также для вывода регрессионной статистики (коэффициента детерминации, стандартных ошибок, F -статистики и др.).
update Опубликовано: 26 января 2019
Двухфакторный дисперсионный анализ без повторений в MS EXCEL
Решим задачу о сравнении средних значений нескольких выборок с использованием дисперсионного анализа в случае двух факторов без повторений (Two Factor ANOVA without Replication). Подход используемый для решения данной задачи имеет …
update Опубликовано: 26 января 2019
update Опубликовано: 26 января 2019
МНК: Степенная зависимость в MS EXCEL
Метод наименьших квадратов (МНК) основан на минимизации суммы квадратов отклонений выбранной функции от исследуемых данных. В этой статье аппроксимируем имеющиеся данные с помощью степенной функции.
update Опубликовано: 11 ноября 2018
МНК: Приближение полиномом в MS EXCEL
Метод наименьших квадратов (МНК) основан на минимизации суммы квадратов отклонений выбранной функции от исследуемых данных. В этой статье аппроксимируем имеющиеся данные с помощью полинома (до 6-й степени включительно).
update Опубликовано: 24 ноября 2018
Простая линейная регрессия в MS EXCEL
Регрессия позволяет прогнозировать зависимую переменную на основании значений фактора. В MS EXCEL имеется множество функций, которые возвращают не только наклон и сдвиг линии регрессии, характеризующей линейную взаимосвязь между факторами, но …
update Опубликовано: 26 января 2019
Множественная регрессия в MS EXCEL
Рассмотрим использование MS EXCEL для прогнозирования переменной Y на основании нескольких переменных Х, т.е. множественную регрессию.
update Опубликовано: 26 января 2019
update Опубликовано: 26 января 2019
МНК: Метод Наименьших Квадратов в MS EXCEL
Метод наименьших квадратов (МНК) основан на минимизации суммы квадратов отклонений выбранной функции от исследуемых данных. В этой статье аппроксимируем имеющиеся данные с помощью линейной функции y = a x + …
update Опубликовано: 11 ноября 2018
МНК: Экспоненциальная зависимость в MS EXCEL
Метод наименьших квадратов (МНК) основан на минимизации суммы квадратов отклонений выбранной функции от исследуемых данных. В этой статье аппроксимируем имеющиеся данные с помощью экспоненциальной функции.
update Опубликовано: 11 ноября 2018
МНК: Приближение тригонометрическим полиномом в MS EXCEL
Метод наименьших квадратов (МНК) основан на минимизации суммы квадратов отклонений выбранной функции от исследуемых данных. В этой статье аппроксимируем имеющиеся данные с помощью тригонометрического полинома.
update Опубликовано: 24 ноября 2018
update Опубликовано: 26 января 2019
update Опубликовано: 26 января 2019
МНК: Логарифмическая зависимость в MS EXCEL
Метод наименьших квадратов (МНК) основан на минимизации суммы квадратов отклонений выбранной функции от исследуемых данных. В этой статье аппроксимируем имеющиеся данные с помощью логарифмической функции.
update Опубликовано: 11 ноября 2018
МНК: Квадратичная зависимость в MS EXCEL
Метод наименьших квадратов (МНК) основан на минимизации суммы квадратов отклонений выбранной функции от исследуемых данных. В этой статье аппроксимируем имеющиеся данные с помощью квадратичной функции y=ax 2 +bx+с .
update Опубликовано: 24 ноября 2018
Диаграмма рассеяния в MS EXCEL
Построим диаграмму рассеяния для различных видов взаимосвязей двух переменных. Сгенерируем различные варианты трендов: линейный, квадратичный и затухающий синусоидальный.
update Опубликовано: 25 ноября 2018
Инфоурок
›
Другое
›Презентации›Статистический анализ данных в MS Excel
Скачать материал

Скачать материал




- Сейчас обучается 264 человека из 64 регионов




Описание презентации по отдельным слайдам:
-

1 слайд
Статистический анализ данных в MS Excel
1. Обзор и характеристика основных статистических функций, входящих в MS Excel.
2. Работа с пакетом анализа данных в MS Excel.
Литература:
1. Г.И. Просветов Анализ данных с помощью Excel. Задачи и решения. М: 2009
2. А.Ю. Козлов, В.С. Мхитарян, В.Ф. Шишов Статистический анализ данных в MS Excel М: 2012 -
2 слайд
Понятие анализа данных
Анализ данных – область математики и информатики, занимающая построением и исследованием наиболее общих математических методов и вычислительных алгоритмов извлечения знаний из экспериментальных данных.
Анализ данных – это процесс исследования, фильтрации, преобразования и моделирования данных с целью извлечения полезной информации и принятия решения. -
3 слайд
Статистические функции MS Excel
Все статистические функции, входящие в MS Excel можно разбить на восемь подразделов:
1.Предварительная обработка данных;
2.Определение характеристик положения;
3.Определение корреляции, ковариации;
4.Определение характеристик рассеивания
5.Интервальное оценивание (определение вероятности попадания дискретной случайной величины в интервал);
6.Определения параметров распределения непрерывной случайной величины;
7.Определение параметров распределения дискретной случайной величины;
8.Построение уравнения регрессии и прогнозирования. -
4 слайд
Предварительная обработка данных
Подсчет количества значений (СЧЕТ).
Определение экстремальных значений совокупности данных (МАКС, МИН)
Подсчет частот из массива данных, попадающих в заданные интервалы (ЧАСТОТА)
Оценка относительного положения точки (ПРОЦЕНТРАНГ)
Определение величины, соответствующей ее относительному положению (ПЕРСЕНТИЛЬ)
Определение числа перестановок (ПЕРЕСТ)
Определение ранга чисел в списке чисел (РАНГ) -
5 слайд
Предварительная обработка данных
Массив данных
СЧЕТ
МАКС
ЧАСТОТА
ПРОЦЕНТРАНГ
ПЕРСЕНТИЛЬ
РАНГ -
6 слайд
Определение характеристик положения
Определение среднего (СРЗНАЧ, СРГЕОМ)
Определение моды в интервале данных или массиве (МОДА)
Определение медианы (МЕДИАНА)
Определение квартилей (КВАРТИЛЬ) -
7 слайд
Определение характеристик положения
Массив данных
СРГЕОМ
СРЗНАЧ
МОДА
МЕДИАНА
КВАРТИЛЬ -
8 слайд
Определение характеристик рассеивания
Определение среднего линейного отклонения (СРОТКЛ)
Определение суммы квадратов отклонения (ДИСП)
Вычисление стандартного (среднего квадратического) отклонения (СТАНДОТКЛОН)
Определения асимметрии распределения (СКОС)
Определения эксцесса (ЭКСЦЕСС) -
9 слайд
Определение характеристик рассеивания
Массив данных
СРОТКЛ
КВАДРОТКЛ
ДИСП
СТАНДОТКЛОН
СКОС
ЭКСЦЕСС -
10 слайд
Зависимость случайных величин
Определение ковариации (КОВАР)
Определение коэффициента корреляции (КОРРЕЛ) -
11 слайд
Зависимость случайных величин
Массив данных
КОВАР
КОРРЕЛ -
12 слайд
Интервальное оценивание
Определение доверительного интервала для среднего (ДОВЕРИТ)
Определение вероятности попадания дискретной случайной величины в интервал (ВЕРОЯТНОСТЬ) -
13 слайд
Интервальное оценивание
Массив данных
ДОВЕРИТ
ВЕРОЯТНОСТЬ -
14 слайд
Определение параметров распределения непрерывных случайных величин
Определение значения функции распределения и функции плотности нормального распределения (НОРМРАСПР)
Определение аргумента по значению функции распределения (НОРМОБР)
Определение вероятности статистики z при проверке гипотизы о равенстве статистической оценки математического ожидания заданному значению (ZТЕСТ)
Определение значений функций распределения отличных от нормальных (ЛОГНОРМРАСП, СТЬЮДРАСП…)
Проверка гипотезы о равенстве дисперсий (ФТЕСТ) -
15 слайд
Определение параметров распределения непрерывных случайных величин
НОРМРАСП
НОРМОБР
Массив данных
ZТЕСТ
ФТЕСТ -
16 слайд
Построение уравнения регрессии и прогнозирование
Определение параметров линейной регрессии (ЛИНЕЙН)
Определение значений результативного признака по линейному уравнению регрессии (ТЕНДЕНЦИЯ)
Определение значения уравнения регрессии вида y=b0+b1x в заданной точке (ПРЕДСКАЗ) -
17 слайд
Построение уравнения регрессии и прогнозирование
ЛИНЕЙН
ТЕНДЕНЦИЯ
Массив данных
ПРЕДСКАЗ -
18 слайд
Работа с пакетом анализа данных в MS Excel.
-
19 слайд
Работа с пакетом анализа данных в MS Excel.
В пакет анализа данных входят следующие инструменты:
1.Генерация случайных чисел
2.Выборка
3.Гистограмма
4.Описательная статистика
5.Скользящее среднее
6.Экспоненциальное сглаживание
7.Ковариционный анализ
8.Корреляционный анализ
9.Двухвыборочный F-тест для дисперсий
10. Двухвыборочныйz-тест для средних
11.Парный двухвыборочный t-тест для средних
12. Двухвыборочный t-тест с одинаковыми дисперсиями
13. Двухвыборочный t-тест с разными дисперсиями
14. Дисперсионный анализ
15. Регрессия
16.Ранг и персентиль
17. Анализ Фурье -
20 слайд
Генерация случайных чисел
Окно инструмента Генерация случайных чисел содержит следующие основные параметры:
-Число переменных При помощи этого параметра можно получать многомерную выборку (количество столбцов)
-Число случайных чисел Определяется число точек данных (число реализаций), которое вы хотите генерировать для каждой переменной
-Случайное рассеивание Вводится произвольное значение, для которого необходимо генерировать случайные числа. Применяется для повторной генерации (повторное получение той же совокупности) -
21 слайд
Выборка
В пакете Анализ данных инструмент Выборка используется для создания выборки из генеральной совокупности, рассматривая входной диапазон как генеральную совокупность -
22 слайд
Гистограмма
Гистограмма применяется для графического изображения интервального вариационного ряда -
23 слайд
Описательная статистика
Описательная статистика использует совокупность методов, позволяющих делать научно обоснованные выводы о числовых параметрах распределения генеральной совокупности по случайной выборке из нее


.Определен...")

Опре...")



Определение коэфф...")













Найдите материал к любому уроку, указав свой предмет (категорию), класс, учебник и тему:
6 212 259 материалов в базе
- Выберите категорию:
- Выберите учебник и тему
- Выберите класс:
-
Тип материала:
-
Все материалы
-
Статьи
-
Научные работы
-
Видеоуроки
-
Презентации
-
Конспекты
-
Тесты
-
Рабочие программы
-
Другие методич. материалы
-
Найти материалы
Другие материалы
- 27.12.2020
- 4749
- 2
- 27.12.2020
- 4952
- 11
- 27.12.2020
- 5787
- 13
- 27.12.2020
- 5023
- 9
- 27.12.2020
- 4058
- 1
- 27.12.2020
- 3884
- 0
- 27.12.2020
- 3907
- 1
- 27.12.2020
- 3300
- 4
Вам будут интересны эти курсы:
-
Курс повышения квалификации «Основы туризма и гостеприимства»
-
Курс повышения квалификации «Организация научно-исследовательской работы студентов в соответствии с требованиями ФГОС»
-
Курс повышения квалификации «Формирование компетенций межкультурной коммуникации в условиях реализации ФГОС»
-
Курс повышения квалификации «Экономика предприятия: оценка эффективности деятельности»
-
Курс профессиональной переподготовки «Клиническая психология: теория и методика преподавания в образовательной организации»
-
Курс повышения квалификации «Введение в сетевые технологии»
-
Курс профессиональной переподготовки «Логистика: теория и методика преподавания в образовательной организации»
-
Курс повышения квалификации «Применение MS Word, Excel в финансовых расчетах»
-
Курс повышения квалификации «Основы менеджмента в туризме»
-
Курс повышения квалификации «Психодинамический подход в консультировании»
-
Курс профессиональной переподготовки «Корпоративная культура как фактор эффективности современной организации»
-
Курс профессиональной переподготовки «Деятельность по хранению музейных предметов и музейных коллекций в музеях всех видов»
-
Курс профессиональной переподготовки «Организация системы менеджмента транспортных услуг в туризме»
-
Курс профессиональной переподготовки «Техническая диагностика и контроль технического состояния автотранспортных средств»
-
Настоящий материал опубликован пользователем Гущина Мадина Ивановна. Инфоурок является
информационным посредником и предоставляет пользователям возможность размещать на сайте
методические материалы. Всю ответственность за опубликованные материалы, содержащиеся в них
сведения, а также за соблюдение авторских прав несут пользователи, загрузившие материал на сайтЕсли Вы считаете, что материал нарушает авторские права либо по каким-то другим причинам должен быть удален с
сайта, Вы можете оставить жалобу на материал.Удалить материал
-

- На сайте: 2 года и 3 месяца
- Подписчики: 0
- Всего просмотров: 47177
-
Всего материалов:
217
Содержание
- Использование описательной статистики
- Подключение «Пакета анализа»
- Размах вариации
- Вычисление коэффициента вариации
- Шаг 1: расчет стандартного отклонения
- Шаг 2: расчет среднего арифметического
- Шаг 3: нахождение коэффициента вариации
- Простая формула для расчета объема выборки
- Пример расчета объема выборки
- Задачи о генеральной доле
- По части судить о целом
- Как рассчитать объем выборки
- Как определить статистические выбросы и сделать выборку для их удаления в Excel
- Способ 1: применение расширенного автофильтра
- Способ 2: применение формулы массива
- СРЗНАЧ()
- СРЗНАЧЕСЛИ()
- МАКС()
- МИН()
Использование описательной статистики
Под описательной статистикой понимают систематизацию эмпирических данных по целому ряду основных статистических критериев. Причем на основе полученного результата из этих итоговых показателей можно сформировать общие выводы об изучаемом массиве данных.
В Экселе существует отдельный инструмент, входящий в «Пакет анализа», с помощью которого можно провести данный вид обработки данных. Он так и называется «Описательная статистика». Среди критериев, которые высчитывает данный инструмент следующие показатели:
- Медиана;
- Мода;
- Дисперсия;
- Среднее;
- Стандартное отклонение;
- Стандартная ошибка;
- Асимметричность и др.
Рассмотрим, как работает данный инструмент на примере Excel 2010, хотя данный алгоритм применим также в Excel 2007 и в более поздних версиях данной программы.
Подключение «Пакета анализа»
Как уже было сказано выше, инструмент «Описательная статистика» входит в более широкий набор функций, который принято называть Пакет анализа. Но дело в том, что по умолчанию данная надстройка в Экселе отключена. Поэтому, если вы до сих пор её не включили, то для использования возможностей описательной статистики, придется это сделать.
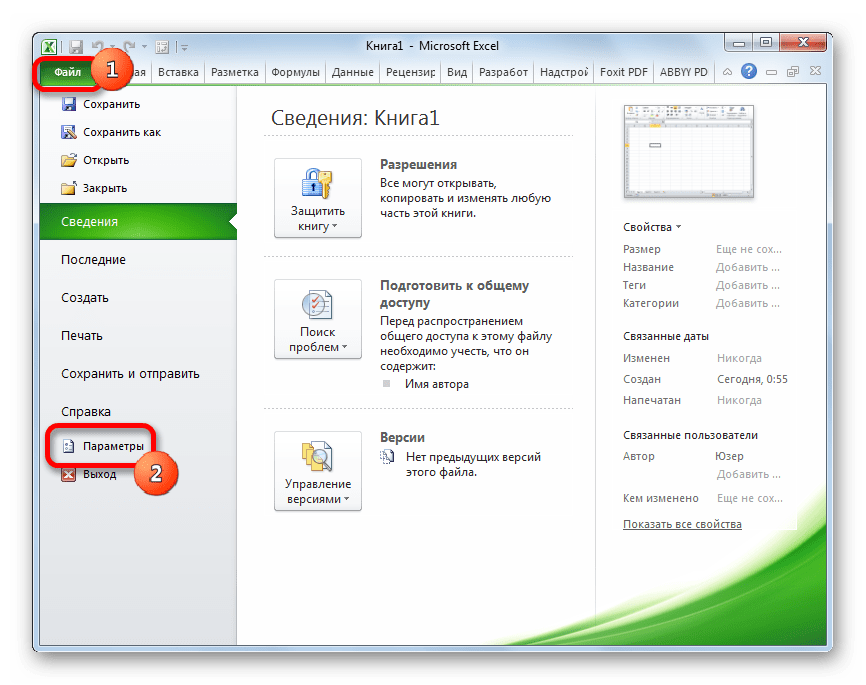
- Переходим во вкладку «Файл». Далее производим перемещение в пункт «Параметры».
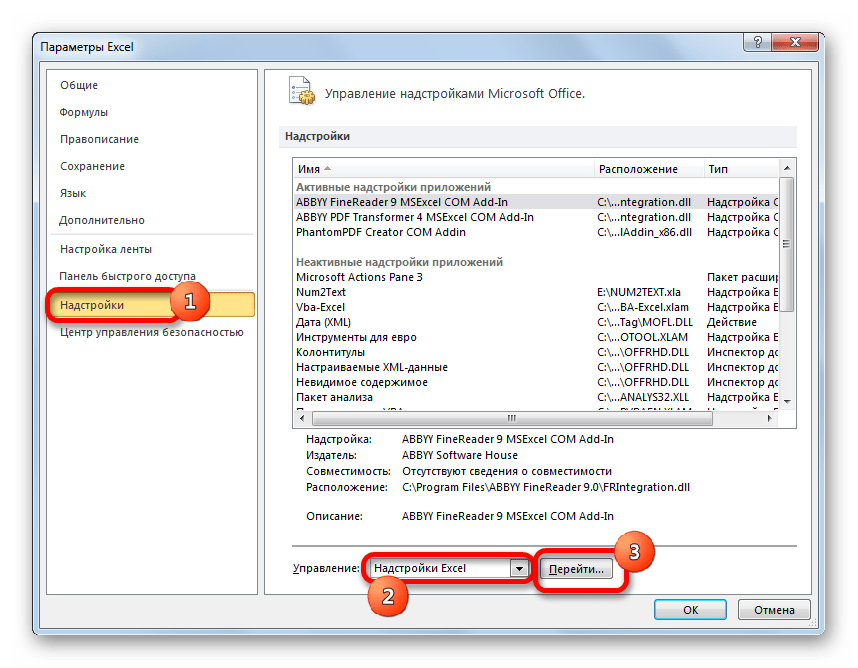
- В активировавшемся окне параметров перемещаемся в подраздел «Надстройки». В самой нижней части окна находится поле «Управление». Нужно в нем переставить переключатель в позицию «Надстройки Excel», если он находится в другом положении. Вслед за этим жмем на кнопку «Перейти…».
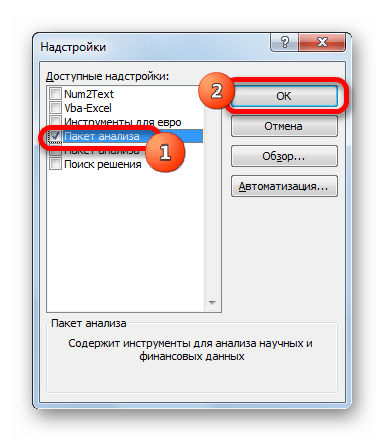
- Запускается окно стандартных надстроек Excel. Около наименования «Пакет анализа» ставим флажок. Затем жмем на кнопку «OK».



После вышеуказанных действий надстройка Пакет анализа будет активирована и станет доступной во вкладке «Данные» Эксель. Теперь мы сможем использовать на практике инструменты описательной статистики.
Размах вариации
Размах вариации – разница между максимальным и минимальным значением:
![]()
Ниже приведена графическая интерпретация размаха вариации.

Видно максимальное и минимальное значение, а также расстояние между ними, которое и соответствует размаху вариации.
С одной стороны, показатель размаха может быть вполне информативным и полезным. К примеру, максимальная и минимальная стоимость квартиры в городе N, максимальная и минимальная зарплата по профессии в регионе и проч. С другой стороны, размах может быть очень широким и не иметь практического смысла, т.к. зависит лишь от двух наблюдений. Таким образом, размах вариации очень неустойчивая величина.
Вычисление коэффициента вариации
Этот показатель представляет собой отношение стандартного отклонения к среднему арифметическому. Полученный результат выражается в процентах.
В Экселе не существует отдельно функции для вычисления этого показателя, но имеются формулы для расчета стандартного отклонения и среднего арифметического ряда чисел, а именно они используются для нахождения коэффициента вариации.
Шаг 1: расчет стандартного отклонения
Стандартное отклонение, или, как его называют по-другому, среднеквадратичное отклонение, представляет собой квадратный корень из дисперсии. Для расчета стандартного отклонения используется функция СТАНДОТКЛОН. Начиная с версии Excel 2010 она разделена, в зависимости от того, по генеральной совокупности происходит вычисление или по выборке, на два отдельных варианта: СТАНДОТКЛОН.Г и СТАНДОТКЛОН.В.
Синтаксис данных функций выглядит соответствующим образом:
= СТАНДОТКЛОН(Число1;Число2;…)
= СТАНДОТКЛОН.Г(Число1;Число2;…)
= СТАНДОТКЛОН.В(Число1;Число2;…)
- Для того, чтобы рассчитать стандартное отклонение, выделяем любую свободную ячейку на листе, которая удобна вам для того, чтобы выводить в неё результаты расчетов. Щелкаем по кнопке «Вставить функцию». Она имеет внешний вид пиктограммы и расположена слева от строки формул.

Выполняется активация Мастера функций, который запускается в виде отдельного окна с перечнем аргументов. Переходим в категорию «Статистические» или «Полный алфавитный перечень». Выбираем наименование «СТАНДОТКЛОН.Г» или «СТАНДОТКЛОН.В», в зависимости от того, по генеральной совокупности или по выборке следует произвести расчет. Жмем на кнопку «OK».

Открывается окно аргументов данной функции. Оно может иметь от 1 до 255 полей, в которых могут содержаться, как конкретные числа, так и ссылки на ячейки или диапазоны. Ставим курсор в поле «Число1». Мышью выделяем на листе тот диапазон значений, который нужно обработать. Если таких областей несколько и они не смежные между собой, то координаты следующей указываем в поле «Число2» и т.д. Когда все нужные данные введены, жмем на кнопку «OK»


Шаг 2: расчет среднего арифметического
Среднее арифметическое является отношением общей суммы всех значений числового ряда к их количеству. Для расчета этого показателя тоже существует отдельная функция – СРЗНАЧ. Вычислим её значение на конкретном примере.
- Выделяем на листе ячейку для вывода результата. Жмем на уже знакомую нам кнопку «Вставить функцию».

В статистической категории Мастера функций ищем наименование «СРЗНАЧ». После его выделения жмем на кнопку «OK».

Запускается окно аргументов СРЗНАЧ. Аргументы полностью идентичны тем, что и у операторов группы СТАНДОТКЛОН. То есть, в их качестве могут выступать как отдельные числовые величины, так и ссылки. Устанавливаем курсор в поле «Число1». Так же, как и в предыдущем случае, выделяем на листе нужную нам совокупность ячеек. После того, как их координаты были занесены в поле окна аргументов, жмем на кнопку «OK».


Шаг 3: нахождение коэффициента вариации
Теперь у нас имеются все необходимые данные для того, чтобы непосредственно рассчитать сам коэффициент вариации.
- Выделяем ячейку, в которую будет выводиться результат. Прежде всего, нужно учесть, что коэффициент вариации является процентным значением. В связи с этим следует поменять формат ячейки на соответствующий. Это можно сделать после её выделения, находясь во вкладке «Главная». Кликаем по полю формата на ленте в блоке инструментов «Число». Из раскрывшегося списка вариантов выбираем «Процентный». После этих действий формат у элемента будет соответствующий.

Снова возвращаемся к ячейке для вывода результата. Активируем её двойным щелчком левой кнопки мыши. Ставим в ней знак «=». Выделяем элемент, в котором расположен итог вычисления стандартного отклонения. Кликаем по кнопке «разделить» (/) на клавиатуре. Далее выделяем ячейку, в которой располагается среднее арифметическое заданного числового ряда. Для того, чтобы произвести расчет и вывести значение, щёлкаем по кнопке Enter на клавиатуре.


Таким образом мы произвели вычисление коэффициента вариации, ссылаясь на ячейки, в которых уже были рассчитаны стандартное отклонение и среднее арифметическое. Но можно поступить и несколько по-иному, не рассчитывая отдельно данные значения.
- Выделяем предварительно отформатированную под процентный формат ячейку, в которой будет выведен результат. Прописываем в ней формулу по типу:
Вместо наименования «Диапазон значений» вставляем реальные координаты области, в которой размещен исследуемый числовой ряд. Это можно сделать простым выделением данного диапазона. Вместо оператора СТАНДОТКЛОН.В, если пользователь считает нужным, можно применять функцию СТАНДОТКЛОН.Г.


Существует условное разграничение. Считается, что если показатель коэффициента вариации менее 33%, то совокупность чисел однородная. В обратном случае её принято характеризовать, как неоднородную.
Как видим, программа Эксель позволяет значительно упростить расчет такого сложного статистического вычисления, как поиск коэффициента вариации. К сожалению, в приложении пока не существует функции, которая высчитывала бы этот показатель в одно действие, но при помощи операторов СТАНДОТКЛОН и СРЗНАЧ эта задача очень упрощается. Таким образом, в Excel её может выполнить даже человек, который не имеет высокого уровня знаний связанных со статистическими закономерностями.
Разделы: Математика
- Совершенствование умений и навыков нахождения статистических характеристик случайной величины, работа с расчетами в Excel;
- применение информационно коммутативных технологий для анализа данных; работа с различными информационными носителями.
- Сегодня мы научимся рассчитывать статистические характеристики для больших по объему выборок, используя возможности современных компьютерных технологий.
- Для начала вспомним:
– что называется случайной величиной? (Случайной величиной называют переменную величину, которая в зависимости от исхода испытания принимает одно значение из множества возможных значений.)
– Какие виды случайных величин мы знаем? (Дискретные, непрерывные.)
– Приведите примеры непрерывных случайных величин (рост дерева), дискретных случайных величин (количество учеников в классе).
– Какие статистические характеристики случайных величин мы знаем (мода, медиана, среднее выборочное значение, размах ряда).
– Какие приемы используются для наглядного представления статистических характеристик случайной величины (полигон частот, круговые и столбчатые диаграммы, гистограммы).
- Рассмотрим, применение инструментов Excel для решения статистических задач на конкретном примере.
Пример. Проведена проверка в 100 компаниях. Даны значения количества работающих в компании (чел.):
| 23 25 24 25 30 24 30 26 28 26 32 33 31 31 25 33 25 29 30 28 23 30 29 24 33 30 30 28 26 25 26 29 27 29 26 28 27 26 29 28 29 30 27 30 28 32 28 26 30 26 31 27 30 27 33 28 26 30 31 29 27 30 30 29 27 26 28 31 29 28 33 27 30 33 26 31 34 28 32 22 29 30 27 29 34 29 32 29 29 30 29 29 36 29 29 34 23 28 24 28 |
рассчитать числовые характеристики:
|
1. Занести данные в EXCEL, каждое число в отдельную ячейку.
| 23 | 25 | 24 | 25 | 30 | 24 | 30 | 26 | 28 | 26 |
| 32 | 33 | 31 | 31 | 25 | 33 | 25 | 29 | 30 | 28 |
| 23 | 30 | 29 | 24 | 33 | 30 | 30 | 28 | 26 | 25 |
| 26 | 29 | 27 | 29 | 26 | 28 | 27 | 26 | 29 | 28 |
| 29 | 30 | 27 | 30 | 28 | 32 | 28 | 26 | 30 | 26 |
| 31 | 27 | 30 | 27 | 33 | 28 | 26 | 30 | 31 | 29 |
| 27 | 30 | 30 | 29 | 27 | 26 | 28 | 31 | 29 | 28 |
| 33 | 27 | 30 | 33 | 26 | 31 | 34 | 28 | 32 | 22 |
| 29 | 30 | 27 | 29 | 34 | 29 | 32 | 29 | 29 | 30 |
| 29 | 29 | 36 | 29 | 29 | 34 | 23 | 28 | 24 | 28 |
2. Для расчета числовых характеристик используем опцию Вставка – Функция. И в появившемся окне в строке категория выберем – статистические, в списке: МОДА

В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:

Нажимаем клавишу ОК. Получили Мо = 29 (чел) – Фирм у которых в штате 29 человек больше всего.
Используя тот же путь вычисляем медиану.
Вставка – Функция – Статистические – Медиана.

В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:

Нажимаем клавишу ОК. Получили Ме = 29 (чел) – среднее значение сотрудников в фирме.
Размах ряда чисел – разница между наименьшим и наибольшим возможным значением случайной величины. Для вычисления размаха ряда нужно найти наибольшее и наименьшее значения нашей выборки и вычислить их разность.
Вставка – Функция – Статистические – МАКС.

В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:

Нажимаем клавишу ОК. Получили наибольшее значение = 36.
Вставка – Функция – Статистические – МИН.

В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:

Нажимаем клавишу ОК. Получили наименьшее значение = 22.
36 – 22 = 14 (чел) – разница между фирмой с наибольшим штатом сотрудников и фирмой с наименьшим штатом сотрудников.
Для построения диаграммы и полигона частот необходимо задать закон распределения, т.е. составить таблицу значений случайной величины и соответствующих им частот. Мы ухе знаем, что наименьшее число сотрудников в фирме = 22, а наибольшее = 36. Составим таблицу, в которой значения xi случайной величины меняются от 22 до 36 включительно шагом 1.
| xi | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 |
| ni |
Чтобы сосчитать частоту каждого значения воспользуемся
Вставка – Функция – Статистические – СЧЕТЕСЛИ.
В окне Диапазон ставим курсор и выделяем нашу выборку, а в окне Критерий ставим число 22

Нажимаем клавишу ОК, получаем значение 1, т.е. число 22 в нашей выборке встречается 1 раз и его частота =1. Аналогичным образом заполняем всю таблицу.
| xi | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 |
| ni | 1 | 3 | 4 | 5 | 11 | 9 | 13 | 18 | 16 | 6 | 4 | 6 | 3 | 0 | 1 |
Для проверки вычисляем объем выборки, сумму частот (Вставка – Функция – Математические – СУММА). Должно получиться 100 (количество всех фирм).
Чтобы построить полигон частот выделяем таблицу – Вставка – Диаграмма – Стандартные – Точечная (точечная диаграмма на которой значения соединены отрезками)

Нажимаем клавишу Далее, в Мастере диаграмм указываем название диаграммы (Полигон частот), удаляем легенду, редактируем шкалу и характеристики диаграммы для наибольшей наглядности.


Для построения столбчатой и круговой диаграмм используем тот же путь (выбирая нужный нам тип диаграммы).
Диаграмма – Стандартные – Круговая.

Диаграмма – Стандартные – Гистограмма.

4. Сегодня на уроке мы научились применять компьютерные технологии для анализа и обработки статистической информации.
Простая формула для расчета объема выборки

где: n – объем выборки;
z – нормированное отклонение, определяемое исходя из выбранного уровня доверительности. Этот показатель характеризует возможность, вероятность попадания ответов в специальный – доверительный интервал. На практике уровень доверительности часто принимают за 95% или 99%. Тогда значения z будут соответственно 1,96 и 2,58;
p – вариация для выборки, в долях. По сути, p – это вероятность того, что респонденты выберут той или иной вариант ответа. Допустим, если мы считаем, что четверть опрашиваемых выберут ответ «Да», то p будет равно 25%, то есть p = 0,25;
q = (1 – p);
e – допустимая ошибка, в долях.
Пример расчета объема выборки
Компания планирует провести социологическое исследование с целью выявить долю курящих лиц в населении города. Для этого сотрудники компании будут задавать прохожим один вопрос: «Вы курите?». Возможных вариантов ответа, таким образом, только два: «Да» и «Нет».
Объем выборки в этом случае рассчитывается следующим образом. Уровень доверительности принимается за 95%, тогда нормированное отклонение z = 1,96. Вариацию принимаем за 50%, то есть условно считаем, что половина респондентов может ответить на вопрос о том, курят ли они – «Да». Тогда p = 0,5. Отсюда находим q = 1 – p = 1 – 0,5 = 0,5. Допустимую ошибку выборки принимаем за 10%, то есть e = 0,1.
Подставляем эти данные в формулу и считаем:

Получаем объем выборки n = 96 человек.
Задачи о генеральной доле
На вопрос «Накрывает ли доверительный интервал заданное значение p0?» — можно ответить, проверив статистическую гипотезу H0:p=p0. При этом предполагается, что опыты проводятся по схеме испытаний Бернулли (независимы, вероятность p появления события А постоянна). По выборке объема n определяют относительную частоту p* появления события A:![]() где m — количество появлений события А в серии из n испытаний. Для проверки гипотезы H0 используется статистика, имеющая при достаточно большом объеме выборки стандартное нормальное распределение (табл. 1).
где m — количество появлений события А в серии из n испытаний. Для проверки гипотезы H0 используется статистика, имеющая при достаточно большом объеме выборки стандартное нормальное распределение (табл. 1).
Таблица 1 – Гипотезы о генеральной доле
|
Гипотеза |
H0:p=p0 | H0:p1=p2 |
| Предположения | Схема испытаний Бернулли | Схема испытаний Бернулли |
| Оценки по выборке |  |
|
| Статистика K |  |
 |
| Распределение статистики K | Стандартное нормальное N(0,1) | Стандартное нормальное N(0,1) |
Пример №1. С помощью случайного повторного отбора руководство фирмы провело выборочный опрос 900 своих служащих. Среди опрошенных оказалось 270 женщин. Постройте доверительный интервал, с вероятностью 0.95 накрывающий истинную долю женщин во всем коллективе фирмы.
Решение. По условию выборочная доля женщин составляет ![]() (относительная частота женщин среди всех опрошенных). Так как отбор является повторным, и объем выборки велик (n=900) предельная ошибка выборки определяется по формуле
(относительная частота женщин среди всех опрошенных). Так как отбор является повторным, и объем выборки велик (n=900) предельная ошибка выборки определяется по формуле ![]() (относительная частота женщин среди всех опрошенных). Так как отбор является повторным, и объем выборки велик (n=900) предельная ошибка выборки определяется по формуле
(относительная частота женщин среди всех опрошенных). Так как отбор является повторным, и объем выборки велик (n=900) предельная ошибка выборки определяется по формуле
Значение uкр находим по таблице функции Лапласа из соотношения 2Ф(uкр)=γ, т.е. ![]() Функция Лапласа (приложение 1) принимает значение 0.475 при uкр=1.96. Следовательно, предельная ошибка
Функция Лапласа (приложение 1) принимает значение 0.475 при uкр=1.96. Следовательно, предельная ошибка ![]() Функция Лапласа (приложение 1) принимает значение 0.475 при uкр=1.96. Следовательно, предельная ошибка и искомый доверительный интервал
Функция Лапласа (приложение 1) принимает значение 0.475 при uкр=1.96. Следовательно, предельная ошибка и искомый доверительный интервал
(p – ε, p + ε) = (0.3 – 0.18; 0.3 + 0.18) = (0.12; 0.48)
Итак, с вероятностью 0.95 можно гарантировать, что доля женщин во всем коллективе фирмы находится в интервале от 0.12 до 0.48.
Пример №2. Владелец автостоянки считает день «удачным», если автостоянка заполнена более, чем на 80 %. В течение года было проведено 40 проверок автостоянки, из которых 24 оказались «удачными». С вероятностью 0.98 найдите доверительный интервал для оценки истинной доли «удачных» дней в течение года.
Решение. Выборочная доля «удачных» дней составляет ![]()
По таблице функции Лапласа найдем значение uкр при заданной
доверительной вероятности ![]()
По таблице функции Лапласа найдем значение uкр при заданной
доверительной вероятности
Ф(2.23) = 0.49, uкр = 2.33.
Считая отбор бесповторным (т.е. две проверки в один день не проводилось), найдем предельную ошибку: ![]()
где n=40, N = 365 (дней). Отсюда ![]()
где n=40, N = 365 (дней). Отсюда
и доверительный интервал для генеральной доли: (p – ε, p + ε) = (0.6 – 0.17; 0.6 + 0.17) = (0.43; 0.77)
С вероятностью 0.98 можно ожидать, что доля «удачных» дней в течение года находится в интервале от 0.43 до 0.77.
Пример №3. Проверив 2500 изделий в партии, обнаружили, что 400 изделий высшего сорта, а n–m – нет. Сколько надо проверить изделий, чтобы с уверенностью 95% определить долю высшего сорта с точностью до 0.01?
Решение ищем по формуле определения численности выборки для повторного отбора.
Ф(t) = γ/2 = 0.95/2 = 0.475 и этому значению по таблице Лапласа соответствует t=1.96
Выборочная доля w = 0.16; ошибка выборки ε = 0.01
Пример №4. Партия изделий принимается, если вероятность того, что изделие окажется соответствующим стандарту, составляет не менее 0.97. Среди случайно отобранных 200 изделий проверяемой партии оказалось 193 соответствующих стандарту. Можно ли на уровне значимости α=0,02 принять партию?
Решение. Сформулируем основную и альтернативную гипотезы.
H0:p=p0=0,97 — неизвестная генеральная доля p равна заданному значению p0=0,97. Применительно к условию — вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, равна 0.97; т.е. партию изделий можно принять.
H1:p<0,97 – вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, меньше 0.97; т.е. партию изделий нельзя принять. При такой альтернативной гипотезе критическая область будет левосторонней.
Наблюдаемое значение статистики K (таблица) вычислим при заданных значениях p0=0,97, n=200, m=193

Критическое значение находим по таблице функции Лапласа из равенства
![]()
По условию α=0,02 отсюда Ф(Ккр)=0,48 и Ккр=2,05. Критическая область левосторонняя, т.е. является интервалом (-∞;-Kkp)= (-∞;-2,05). Наблюдаемое значение Кнабл=-0,415 не принадлежит критической области, следовательно, на данном уровне значимости нет оснований отклонять основную гипотезу. Партию изделий принять можно.
Пример №5. Два завода изготавливают однотипные детали. Для оценки их качества сделаны выборки из продукции этих заводов и получены следующие результаты. Среди 200 отобранных изделий первого завода оказалось 20 бракованных, среди 300 изделий второго завода — 15 бракованных.
На уровне значимости 0.025 выяснить, имеется ли существенное различие в качестве изготавливаемых этими заводами деталей.
Решение. Это задача о сравнении генеральных долей двух совокупностей. Сформулируем основную и альтернативную гипотезы.
H0:p1=p2 — генеральные доли равны. Применительно к условию — вероятность появления бракованного изделия в продукции первого завода равна вероятности появления бракованного изделия в продукции второго завода (качество продукции одинаково).
H0:p1≠p2 — заводы изготавливают детали разного качества.
Для вычисления наблюдаемого значения статистики K (таблица) рассчитаем оценки по выборке.
![]()
![]()
Наблюдаемое значение равно

Так как альтернативная гипотеза двусторонняя, то критическое значение статистики K≈ N(0,1) находим по таблице функции Лапласа из равенства ![]()
Так как альтернативная гипотеза двусторонняя, то критическое значение статистики K≈ N(0,1) находим по таблице функции Лапласа из равенства
По условию α=0,025 отсюда Ф(Ккр)=0,4875 и Ккр=2,24. При двусторонней альтернативе область допустимых значений имеет вид (-2,24;2,24). Наблюдаемое значение Kнабл=2,15 попадает в этот интервал, т.е. на данном уровне значимости нет оснований отвергать основную гипотезу. Заводы изготавливают изделия одинакового качества.
По части судить о целом
О возможности судить о целом по части миру рассказал российский математик П.Л. Чебышев. «Закон больших чисел» простым языком можно сформулировать так: количественные закономерности массовых явлений проявляются только при
достаточном числе наблюдений
. Чем больше выборка, тем лучше случайные отклонения компенсируют друг друга и проявляется общая тенденция.
А.М. Ляпунов чуть позже сформулировал центральную предельную теорему. Она стала фундаментом для создания формул, которые позволяют рассчитать вероятность ошибки (при оценке среднего по выборке) и размер выборки, необходимый для достижения заданной точности.
Строгие формулировки:
С увеличением числа случайных величин их среднее арифметическое стремится к среднему арифметическому математических ожиданий и перестает быть случайным. Общий смысл закона больших чисел — совместное действие большого числа случайных факторов приводит к результату, почти не зависящему от случая.
Таким образом з.б.ч. гарантирует устойчивость для средних значений некоторых случайных событий при достаточно длинной серии экспериментов.
Распределение случайной величины, которая получена в результате сложения большого числа независимых случайных величин (ни одно из которых не доминирует, не вносит в сумму определяющего вклада и имеет дисперсию значительно меньшею по сравнению с дисперсией суммы) имеет распределение, близкое к нормальному.
Из ц.п.т. следует, что ошибки выборки также подчиняется нормальному распределению.
Еще раз: чтобы корректно оценивать популяцию по выборке, нам нужна не обычная выборка, а репрезентативная выборка достаточного размера. Начнем с определения этого самого размера.
Как рассчитать объем выборки
Достаточный размер выборки зависит от следующих составляющих:
- изменчивость признака (чем разнообразней показания, тем больше наблюдений нужно, чтобы это уловить);
- размер эффекта (чем меньшие эффекты мы стремимся зафиксировать, тем больше наблюдений необходимо);
- уровень доверия (уровень вероятности при который мы готовы отвергнуть нулевую гипотезу)
ЗАПОМНИТЕ
Объем выборки зависит от изменчивости признака и планируемой строгости эксперимента
Формулы для расчета объема выборки:

Формулы расчета объема выборки
Ошибка выборки значительно возрастает, когда наблюдений меньше ста. Для исследований в которых используется 30-100 объектов применяется особая статистическая методология: критерии, основанные на распределении Стьюдента или бутстрэп-анализ. И наконец, статистика совсем слаба, когда наблюдений меньше 30.

График зависимости ошибки выборки от ее объема при оценке доли признака в г.с.
Чем больше неопределенность, тем больше ошибка. Максимальная неопределенность при оценке доли — 50% (например, 50% респондентов считают концепцию хорошей, а другие 50% плохой). Если 90% опрошенных концепция понравится — это, наоборот, пример согласованности. В таких случаях оценить долю признака по выборке проще.
Для экспонирования и выделения цветом значений статистических выбросов от медианы можно использовать несколько простых формул и условное форматирование.
Первым шагом в поиске значений выбросов статистики является определение статистического центра диапазона данных. С этой целью необходимо сначала определить границы первого и третьего квартала. Определение границ квартала – значит разделение данных на 4 равные группы, которые содержат по 25% данных каждая. Группа, содержащая 25% наибольших значений, называется первым квартилем.
Границы квартилей в Excel можно легко определить с помощью простой функции КВАРТИЛЬ. Данная функция имеет 2 аргумента: диапазон данных и номер для получения желаемого квартиля.
В примере показанному на рисунке ниже значения в ячейках E1 и E2 содержат показатели первого и третьего квартиля данных в диапазоне ячеек B2:B19:

Вычитая от значения первого квартиля третьего, можно определить набор 50% статистических данных, который называется межквартильным диапазоном. В ячейке E3 определен размер межквартильного диапазона.
В этом месте возникает вопрос, как сильно данное значение может отличаться от среднего значения 50% данных и оставаться все еще в пределах нормы? Статистические аналитики соглашаются с тем, что для определения нижней и верхней границы диапазона данных можно смело использовать коэффициент расширения 1,5 умножив на значение межквартильного диапазона. То есть:
- Нижняя граница диапазона данных равна: значение первого квартиля – межкваритльный диапазон * 1,5.
- Верхняя граница диапазона данных равна: значение третьего квартиля + расширенных диапазон * 1,5.
Как показано на рисунке ячейки E5 и E6 содержат вычисленные значения верхней и нижней границы диапазона данных. Каждое значение, которое больше верхней границы нормы или меньше нижней границы нормы считается значением статистического выброса.
Чтобы выделить цветом для улучшения визуального анализа данных можно создать простое правило для условного форматирования.
Способ 1: применение расширенного автофильтра
Наиболее простым способом произвести отбор является применение расширенного автофильтра. Рассмотрим, как это сделать на конкретном примере.
- Выделяем область на листе, среди данных которой нужно произвести выборку. Во вкладке «Главная» щелкаем по кнопке «Сортировка и фильтр». Она размещается в блоке настроек «Редактирование». В открывшемся после этого списка выполняем щелчок по кнопке «Фильтр».

Есть возможность поступить и по-другому. Для этого после выделения области на листе перемещаемся во вкладку «Данные». Щелкаем по кнопке «Фильтр», которая размещена на ленте в группе «Сортировка и фильтр».
- После этого действия в шапке таблицы появляются пиктограммы для запуска фильтрования в виде перевернутых острием вниз небольших треугольников на правом краю ячеек. Кликаем по данному значку в заглавии того столбца, по которому желаем произвести выборку. В запустившемся меню переходим по пункту «Текстовые фильтры». Далее выбираем позицию «Настраиваемый фильтр…».
- Активируется окно пользовательской фильтрации. В нем можно задать ограничение, по которому будет производиться отбор. В выпадающем списке для столбца содержащего ячейки числового формата, который мы используем для примера, можно выбрать одно из пяти видов условий:
- равно;
- не равно;
- больше;
- больше или равно;
- меньше.
Давайте в качестве примера зададим условие так, чтобы отобрать только значения, по которым сумма выручки превышает 10000 рублей. Устанавливаем переключатель в позицию «Больше». В правое поле вписываем значение «10000». Чтобы произвести выполнение действия, щелкаем по кнопке «OK».
- Как видим, после фильтрации остались только строчки, в которых сумма выручки превышает 10000 рублей.
- Но в этом же столбце мы можем добавить и второе условие. Для этого опять возвращаемся в окно пользовательской фильтрации. Как видим, в его нижней части есть ещё один переключатель условия и соответствующее ему поле для ввода. Давайте установим теперь верхнюю границу отбора в 15000 рублей. Для этого выставляем переключатель в позицию «Меньше», а в поле справа вписываем значение «15000».
Кроме того, существует ещё переключатель условий. У него два положения «И» и «ИЛИ». По умолчанию он установлен в первом положении. Это означает, что в выборке останутся только строчки, которые удовлетворяют обоим ограничениям. Если он будет выставлен в положение «ИЛИ», то тогда останутся значения, которые подходят под любое из двух условий. В нашем случае нужно выставить переключатель в положение «И», то есть, оставить данную настройку по умолчанию. После того, как все значения введены, щелкаем по кнопке «OK».
- Теперь в таблице остались только строчки, в которых сумма выручки не меньше 10000 рублей, но не превышает 15000 рублей.
- Аналогично можно настраивать фильтры и в других столбцах. При этом имеется возможность сохранять также фильтрацию и по предыдущим условиям, которые были заданы в колонках. Итак, посмотрим, как производится отбор с помощью фильтра для ячеек в формате даты. Кликаем по значку фильтрации в соответствующем столбце. Последовательно кликаем по пунктам списка «Фильтр по дате» и «Настраиваемый фильтр».
- Снова запускается окно пользовательского автофильтра. Выполним отбор результатов в таблице с 4 по 6 мая 2016 года включительно. В переключателе выбора условий, как видим, ещё больше вариантов, чем для числового формата. Выбираем позицию «После или равно». В поле справа устанавливаем значение «04.05.2016». В нижнем блоке устанавливаем переключатель в позицию «До или равно». В правом поле вписываем значение «06.05.2016». Переключатель совместимости условий оставляем в положении по умолчанию – «И». Для того, чтобы применить фильтрацию в действии, жмем на кнопку «OK».
- Как видим, наш список ещё больше сократился. Теперь в нем оставлены только строчки, в которых сумма выручки варьируется от 10000 до 15000 рублей за период с 04.05 по 06.05.2016 включительно.
- Мы можем сбросить фильтрацию в одном из столбцов. Сделаем это для значений выручки. Кликаем по значку автофильтра в соответствующем столбце. В выпадающем списке щелкаем по пункту «Удалить фильтр».
- Как видим, после этих действий, выборка по сумме выручки будет отключена, а останется только отбор по датам (с 04.05.2016 по 06.05.2016).
- В данной таблице имеется ещё одна колонка – «Наименование». В ней содержатся данные в текстовом формате. Посмотрим, как сформировать выборку с помощью фильтрации по этим значениям.
Кликаем по значку фильтра в наименовании столбца. Последовательно переходим по наименованиям списка «Текстовые фильтры» и «Настраиваемый фильтр…».
- Опять открывается окно пользовательского автофильтра. Давайте сделаем выборку по наименованиям «Картофель» и «Мясо». В первом блоке переключатель условий устанавливаем в позицию «Равно». В поле справа от него вписываем слово «Картофель». Переключатель нижнего блока так же ставим в позицию «Равно». В поле напротив него делаем запись – «Мясо». И вот далее мы выполняем то, чего ранее не делали: устанавливаем переключатель совместимости условий в позицию «ИЛИ». Теперь строчка, содержащая любое из указанных условий, будет выводиться на экран. Щелкаем по кнопке «OK».
- Как видим, в новой выборке существуют ограничения по дате (с 04.05.2016 по 06.05.2016) и по наименованию (картофель и мясо). По сумме выручки ограничений нет.
- Полностью удалить фильтр можно теми же способами, которые использовались для его установки. Причем неважно, какой именно способ применялся. Для сброса фильтрации, находясь во вкладке «Данные» щелкаем по кнопке «Фильтр», которая размещена в группе «Сортировка и фильтр».

Второй вариант предполагает переход во вкладку «Главная». Там выполняем щелчок на ленте по кнопке «Сортировка и фильтр» в блоке «Редактирование». В активировавшемся списке нажимаем на кнопку «Фильтр».

















При использовании любого из двух вышеуказанных методов фильтрация будет удалена, а результаты выборки – очищены. То есть, в таблице будет показан весь массив данных, которыми она располагает.

Способ 2: применение формулы массива
Сделать отбор можно также применив сложную формулу массива. В отличие от предыдущего варианта, данный метод предусматривает вывод результата в отдельную таблицу.
- На том же листе создаем пустую таблицу с такими же наименованиями столбцов в шапке, что и у исходника.
- Выделяем все пустые ячейки первой колонки новой таблицы. Устанавливаем курсор в строку формул. Как раз сюда будет заноситься формула, производящая выборку по указанным критериям. Отберем строчки, сумма выручки в которых превышает 15000 рублей. В нашем конкретном примере, вводимая формула будет выглядеть следующим образом:
=ИНДЕКС(A2:A29;НАИМЕНЬШИЙ(ЕСЛИ(15000<=C2:C29;СТРОКА(C2:C29);"");СТРОКА()-СТРОКА($C$1))-СТРОКА($C$1))Естественно, в каждом конкретном случае адрес ячеек и диапазонов будет свой. На данном примере можно сопоставить формулу с координатами на иллюстрации и приспособить её для своих нужд.
- Так как это формула массива, то для того, чтобы применить её в действии, нужно нажимать не кнопку Enter, а сочетание клавиш Ctrl+Shift+Enter. Делаем это.
- Выделив второй столбец с датами и установив курсор в строку формул, вводим следующее выражение:
=ИНДЕКС(B2:B29;НАИМЕНЬШИЙ(ЕСЛИ(15000<=C2:C29;СТРОКА(C2:C29);"");СТРОКА()-СТРОКА($C$1))-СТРОКА($C$1))Жмем сочетание клавиш Ctrl+Shift+Enter.
- Аналогичным образом в столбец с выручкой вписываем формулу следующего содержания:
=ИНДЕКС(C2:C29;НАИМЕНЬШИЙ(ЕСЛИ(15000<=C2:C29;СТРОКА(C2:C29);"");СТРОКА()-СТРОКА($C$1))-СТРОКА($C$1))Опять набираем сочетание клавиш Ctrl+Shift+Enter.
Во всех трех случаях меняется только первое значение координат, а в остальном формулы полностью идентичны.
- Как видим, таблица заполнена данными, но внешний вид её не совсем привлекателен, к тому же, значения даты заполнены в ней некорректно. Нужно исправить эти недостатки. Некорректность даты связана с тем, что формат ячеек соответствующего столбца общий, а нам нужно установить формат даты. Выделяем весь столбец, включая ячейки с ошибками, и кликаем по выделению правой кнопкой мыши. В появившемся списке переходим по пункту «Формат ячейки…».
- В открывшемся окне форматирования открываем вкладку «Число». В блоке «Числовые форматы» выделяем значение «Дата». В правой части окна можно выбрать желаемый тип отображения даты. После того, как настройки выставлены, жмем на кнопку «OK».
- Теперь дата отображается корректно. Но, как видим, вся нижняя часть таблицы заполнена ячейками, которые содержат ошибочное значение «#ЧИСЛО!». По сути, это те ячейки, данных из выборки для которых не хватило. Более привлекательно было бы, если бы они отображались вообще пустыми. Для этих целей воспользуемся условным форматированием. Выделяем все ячейки таблицы, кроме шапки. Находясь во вкладке «Главная» кликаем по кнопке «Условное форматирование», которая находится в блоке инструментов «Стили». В появившемся списке выбираем пункт «Создать правило…».
- В открывшемся окне выбираем тип правила «Форматировать только ячейки, которые содержат». В первом поле под надписью «Форматировать только ячейки, для которых выполняется следующее условие» выбираем позицию «Ошибки». Далее жмем по кнопке «Формат…».
- В запустившемся окне форматирования переходим во вкладку «Шрифт» и в соответствующем поле выбираем белый цвет. После этих действий щелкаем по кнопке «OK».
- На кнопку с точно таким же названием жмем после возвращения в окно создания условий.











Теперь у нас имеется готовая выборка по указанному ограничению в отдельной надлежащим образом оформленной таблице.

СРЗНАЧ()
Статистическая функция СРЗНАЧ возвращает среднее арифметическое своих аргументов.

Данная функция может принимать до 255 аргументов и находить среднее сразу в нескольких несмежных диапазонах и ячейках:

Если в рассчитываемом диапазоне встречаются пустые или содержащие текст ячейки, то они игнорируются. В примере ниже среднее ищется по четырем ячейкам, т.е. (4+15+11+22)/4 = 13

Если необходимо вычислить среднее, учитывая все ячейки диапазона, то можно воспользоваться статистической функцией СРЗНАЧА. В следующем примере среднее ищется уже по 6 ячейкам, т.е. (4+15+11+22)/6 = 8,6(6).

Статистическая функция СРЗНАЧ может использовать в качестве своих аргументов математические операторы и различные функции Excel:

СРЗНАЧЕСЛИ()
Если необходимо вернуть среднее арифметическое значений, которые удовлетворяют определенному условию, то можно воспользоваться статистической функцией СРЗНАЧЕСЛИ. Следующая формула вычисляет среднее чисел, которые больше нуля:

В данном примере для подсчета среднего и проверки условия используется один и тот же диапазон, что не всегда удобно. На этот случай у функции СРЗНАЧЕСЛИ существует третий необязательный аргумент, по которому можно вычислять среднее. Т.е. по первому аргументу проверяем условие, по третьему – находим среднее.
Допустим, в таблице ниже собрана статистика по стоимости лекарств в городе. В одной аптеке лекарство стоит дороже, в другой дешевле. Чтобы посчитать стоимость анальгина в среднем по городу, воспользуемся следующей формулой:

Если требуется соблюсти несколько условий, то всегда можно применить статистическую функцию СРЗНАЧЕСЛИМН, которая позволяет считать среднее арифметическое ячеек, удовлетворяющих двум и более критериям.
МАКС()
Статистическая функция МАКС возвращает наибольшее значение в диапазоне ячеек:

МИН()
Статистическая функция МИН возвращает наименьшее значение в диапазоне ячеек:

Источники
- https://lumpics.ru/descriptive-statistics-in-excel/
- https://statanaliz.info/statistica/opisanie-dannyx/variatsiya-razmakh-srednee-linejnoe-otklonenie/
- https://www.hd01.ru/info/kak-poschitat-razmah-v-excel/
- http://galyautdinov.ru/post/formula-vyborki-prostaya
- https://math.semestr.ru/group/interval-estimation-share.php
- https://tidydata.ru/sample-size
- https://exceltable.com/formuly/raschet-statisticheskih-vybrosov
- https://lumpics.ru/how-to-make-a-sample-in-excel/
- https://office-guru.ru/excel/statisticheskie-funkcii-excel-kotorye-neobhodimo-znat-96.html
Содержание
- Использование описательной статистики
- Подключение «Пакета анализа»
- Применение инструмента «Описательная статистика»
- Вопросы и ответы

Пользователи Эксель знают, что данная программа имеет очень широкий набор статистических функций, по уровню которых она вполне может потягаться со специализированными приложениями. Но кроме того, у Excel имеется инструмент, с помощью которого производится обработка данных по целому ряду основных статистических показателей буквально в один клик.
Этот инструмент называется «Описательная статистика». С его помощью можно в очень короткие сроки, использовав ресурсы программы, обработать массив данных и получить о нем информацию по целому ряду статистических критериев. Давайте взглянем, как работает данный инструмент, и остановимся на некоторых нюансах работы с ним.
Использование описательной статистики
Под описательной статистикой понимают систематизацию эмпирических данных по целому ряду основных статистических критериев. Причем на основе полученного результата из этих итоговых показателей можно сформировать общие выводы об изучаемом массиве данных.
В Экселе существует отдельный инструмент, входящий в «Пакет анализа», с помощью которого можно провести данный вид обработки данных. Он так и называется «Описательная статистика». Среди критериев, которые высчитывает данный инструмент следующие показатели:
- Медиана;
- Мода;
- Дисперсия;
- Среднее;
- Стандартное отклонение;
- Стандартная ошибка;
- Асимметричность и др.
Рассмотрим, как работает данный инструмент на примере Excel 2010, хотя данный алгоритм применим также в Excel 2007 и в более поздних версиях данной программы.
Подключение «Пакета анализа»
Как уже было сказано выше, инструмент «Описательная статистика» входит в более широкий набор функций, который принято называть Пакет анализа. Но дело в том, что по умолчанию данная надстройка в Экселе отключена. Поэтому, если вы до сих пор её не включили, то для использования возможностей описательной статистики, придется это сделать.
- Переходим во вкладку «Файл». Далее производим перемещение в пункт «Параметры».
- В активировавшемся окне параметров перемещаемся в подраздел «Надстройки». В самой нижней части окна находится поле «Управление». Нужно в нем переставить переключатель в позицию «Надстройки Excel», если он находится в другом положении. Вслед за этим жмем на кнопку «Перейти…».
- Запускается окно стандартных надстроек Excel. Около наименования «Пакет анализа» ставим флажок. Затем жмем на кнопку «OK».
После вышеуказанных действий надстройка Пакет анализа будет активирована и станет доступной во вкладке «Данные» Эксель. Теперь мы сможем использовать на практике инструменты описательной статистики.
Применение инструмента «Описательная статистика»
Теперь посмотрим, как инструмент описательная статистика можно применить на практике. Для этих целей используем готовую таблицу.
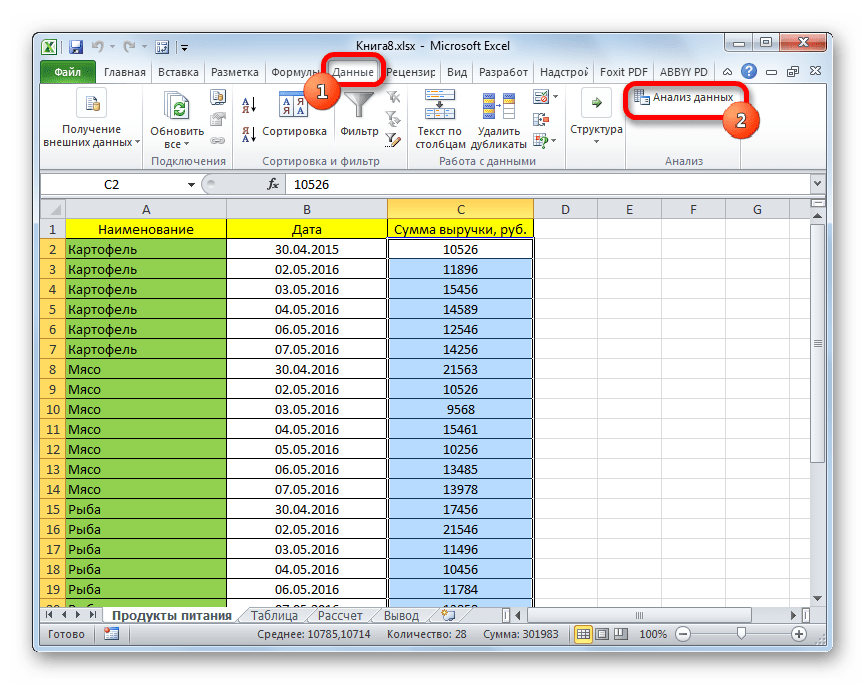
- Переходим во вкладку «Данные» и выполняем щелчок по кнопке «Анализ данных», которая размещена на ленте в блоке инструментов «Анализ».
- Открывается список инструментов, представленных в Пакете анализа. Ищем наименование «Описательная статистика», выделяем его и щелкаем по кнопке «OK».
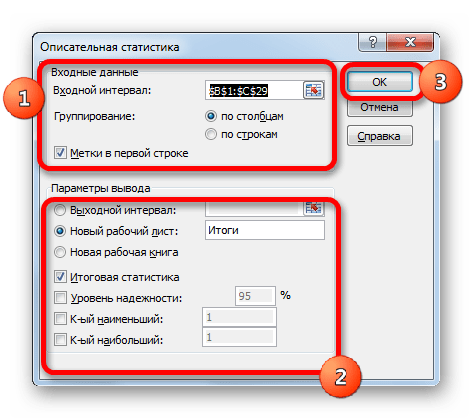
- После выполнения данных действий непосредственно запускается окно «Описательная статистика».
В поле «Входной интервал» указываем адрес диапазона, который будет подвергаться обработке этим инструментом. Причем указываем его вместе с шапкой таблицы. Для того, чтобы внести нужные нам координаты, устанавливаем курсор в указанное поле. Затем, зажав левую кнопку мыши, выделяем на листе соответствующую табличную область. Как видим, её координаты тут же отобразятся в поле. Так как мы захватили данные вместе с шапкой, то около параметра «Метки в первой строке» следует установить флажок. Тут же выбираем тип группирования, переставив переключатель в позицию «По столбцам» или «По строкам». В нашем случае подходит вариант «По столбцам», но в других случаях, возможно, придется выставить переключатель иначе.

Выше мы говорили исключительно о входных данных. Теперь переходим к разбору настроек параметров вывода, которые расположены в этом же окне формирования описательной статистики. Прежде всего, нам нужно определиться, куда именно будут выводиться обработанные данные:
- Выходной интервал;
- Новый рабочий лист;
- Новая рабочая книга.
В первом случае нужно указать конкретный диапазон на текущем листе или его верхнюю левую ячейку, куда будет выводиться обработанная информация. Во втором случае следует указать название конкретного листа данной книги, где будет отображаться результат обработки. Если листа с таким наименованием в данный момент нет, то он будет создан автоматически после того, как вы нажмете на кнопку «OK». В третьем случае никаких дополнительных параметров указывать не нужно, так как данные будут выводиться в отдельном файле Excel (книге). Мы выбираем вывод результатов на новом рабочем листе под названием «Итоги».
Далее, если вы хотите чтобы выводилась также итоговая статистика, то нужно установить флажок около соответствующего пункта. Также можно установить уровень надежности, поставив галочку около соответствующего значения. По умолчанию он будет равен 95%, но его можно изменить, внеся другие числа в поле справа.
Кроме этого, можно установить галочки в пунктах «K-ый наименьший» и «K-ый наибольший», установив значения в соответствующих полях. Но в нашем случае этот параметр так же, как и предыдущий, не является обязательным, поэтому флажки мы не ставим.
После того, как все указанные данные внесены, жмем на кнопку «OK».
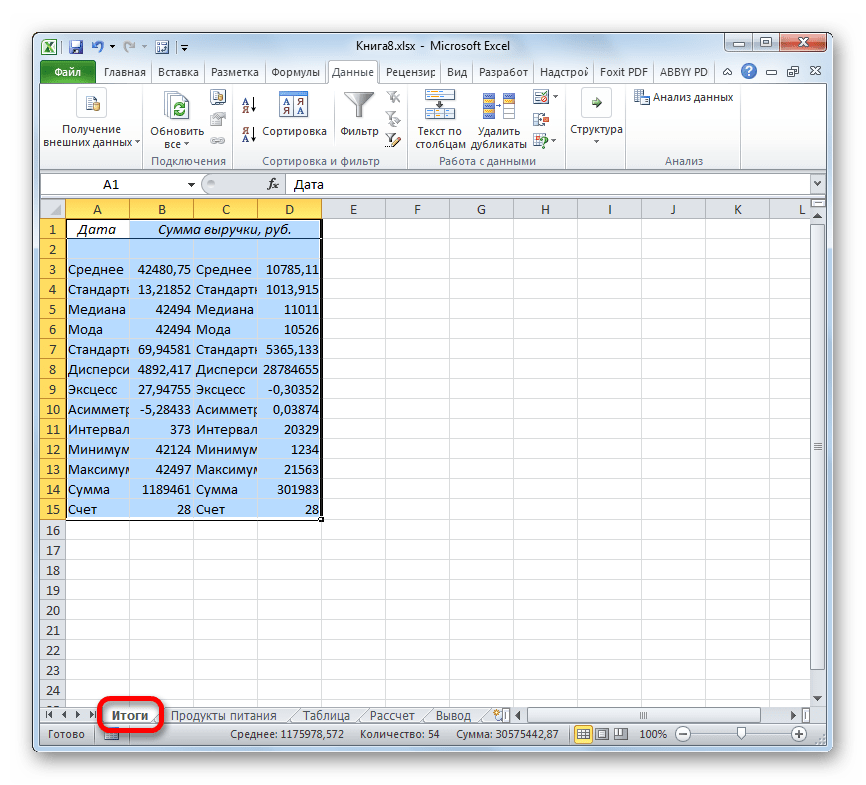
- После выполнения этих действий таблица с описательной статистикой выводится на отдельном листе, который был нами назван «Итоги». Как видим, данные представлены сумбурно, поэтому их следует отредактировать, расширив соответствующие колонки для более удобного просмотра.
- После того, как данные «причесаны» можно приступать к их непосредственному анализу. Как видим, при помощи инструмента описательной статистики были рассчитаны следующие показатели:
- Асимметричность;
- Интервал;
- Минимум;
- Стандартное отклонение;
- Дисперсия выборки;
- Максимум;
- Сумма;
- Эксцесс;
- Среднее;
- Стандартная ошибка;
- Медиана;
- Мода;
- Счет.


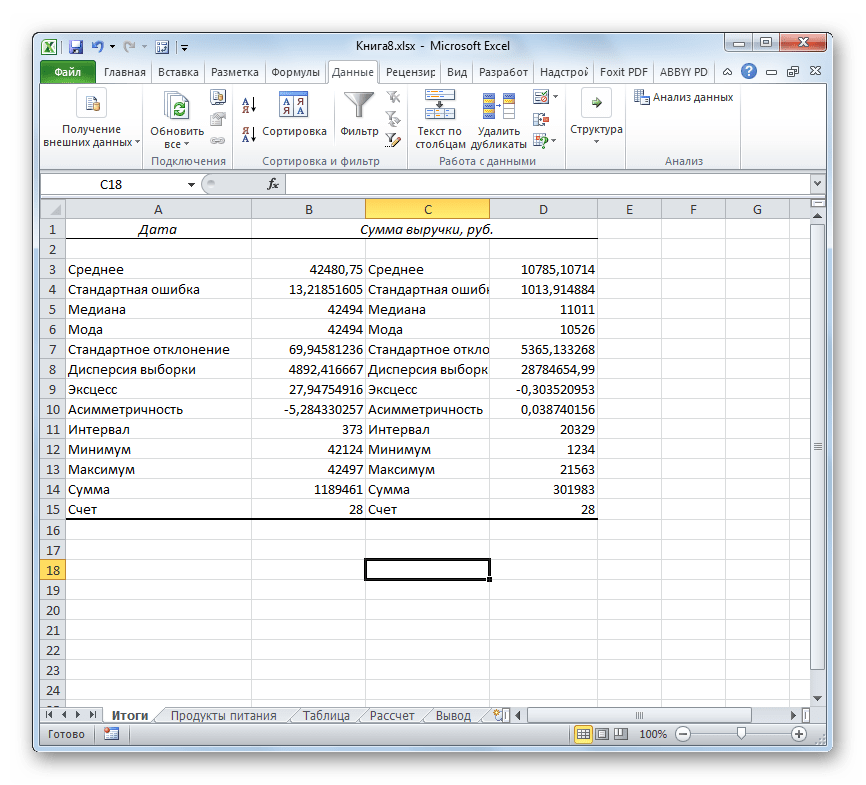
Если какие-то из вышеуказанных данных для конкретного вида анализа не нужны, то их можно удалить, чтобы они не мешали. Далее производится анализ с учетом статистических закономерностей.
Урок: Статистические функции в Excel
Как видим, с помощью инструмента «Описательная статистика» можно сразу получить результат по целому ряду критериев, которые в ином случае рассчитывались с применением отдельно предназначенной для каждого расчета функцией, что заняло бы значительное время у пользователя. А так, все эти расчеты можно получить практически в один клик, использовав соответствующий инструмент — Пакета анализа.
Еще статьи по данной теме:
Помогла ли Вам статья?
Improve Article
Save Article
Like Article
Improve Article
Save Article
Like Article
Descriptive statistics is all about describing the given data. To describe about the data, we use Measures of central tendency and measures of dispersion.
- Measures of central tendency [Mean, Median, and Mode] – a single number about the center of the data points.
- Measures of dispersion [Range, Variance and Standard Deviation] – how the data is distributed
In this article, we explain how to use “Data Analysis” in excel for descriptive statistics in detail.
Sample data:
For eg. We have given shirt size of 20 men in the below table.

Implementation:
Follow the below steps to implement descriptive statistics on sample data:
Step 1: Go to “Data” >> Click “Data Analysis” (Image 1) – to popup the “Data Analysis” Dialog box. If you cannot find “Data analysis” in excel ribbon. The end of this article finds the steps [To provide “Data Analysis”].

Image 1
Step 2: In Data Analysis, Select “Descriptive Statistics” and Press “OK” – To popup “Descriptive statistics” Dialog box for further input

Step 3: Make sure the below options are selected in “Descriptive statistics” and Press “OK”.
Input Range: “$B$1:$B$21” Grouped By: Columns Labels in first row: Checked Output Range: $D$5 Summary statistics: Checked

Output:
Descriptive statistics Output in Table “D5:E19”

To provide the “Data Analysis” button in the “Analysis Group”
Step 1: Go to File >> Click “Options” – to popup “Excel options”.


Step 2: Select “Add-ins” and Press “Go”.

Step 3: Select “Analysis ToolPak” and press “OK”.

Like Article
Save Article
В состав MicrosoftExcelвходит пакет анализа, который позволяет
осуществлять статистическую обработку
данных в таблицах. В состав этого пакета
входят разнообразные статистические
методы. Способы применения их всех
аналогичны, поэтому мы рассмотрим лишь
некоторые из них: экспоненциальное
сглаживание, корреляцию, скользящее
среднее, регрессию.
Корреляция используется для количественной
оценки взаимосвязи двух наборов данных,
представленных в безразмерном виде.
Корреляционный анализ дает возможность
установить ассоциированы ли наборы
данных по величине, то есть, большие
значения из одного набора данных связаны
с большими значениями другого набора
(положительная корреляция), или, наоборот,
малые значения одного набора связаны
с большими значениями другого
(отрицательная корреляция), или данные
двух диапазонов никак не связаны
(корреляция близка к нулю).
Скользящее среднее используется для
расчета значений в прогнозируемом
периоде на основе среднего значения
переменной для указанного числа
предшествующих периодов. Процедура
может использоваться для прогноза
сбыта, инвентаризации и других процессов.
Мы спрогнозируем курс доллара США на
основе данных за июль 1999 года.
Экспоненциальное сглаживание
предназначается для предсказания
значения на основе прогноза для
предыдущего периода, скорректированного
с учетом погрешностей в этом прогнозе.
Использует константу сглаживания, по
величине которой определяет, насколько
сильно влияют на прогнозы погрешности
в предыдущем прогнозе. Для константы
сглаживания наиболее подходящими
являются значения от 0,2 до 0,3. Эти значения
показывают, что ошибка текущего прогноза
установлена на уровне от 20 до 30 процентов
ошибки предыдущего прогноза. Более
высокие значения константы ускоряют
отклик, но могут привести к непредсказуемым
выбросам. Низкие значения константы
могут привести к сдвигу аргумента для
предсказанных значений.
Линейный регрессионный анализ заключается
в подборе графика для набора наблюдений
с помощью метода наименьших квадратов.
Регрессия используется для анализа
воздействия на отдельную зависимую
переменную значений одной или более
независимых переменных. Мы рассмотрим,
как влиял на курс ЕВРО по отношению к
рублю курс доллара США в июле 1999 года.
Установка пакета анализа.
Если в Microsoft Excel в меню Сервисотсутствует командаАнализ данных,
то необходимо установить статистический
пакет анализа данных.
Чтобы установить пакет анализа данных
-
В
 менюСервисвыберите командуНадстройки. Если в списке надстроек
менюСервисвыберите командуНадстройки. Если в списке надстроек
нет пакета анализа данных, нажмите
кнопкуОбзори укажите диск, папку
и имя файла для надстройки пакет анализа,
Analys32.xll (как правило, папка LibraryAnalysis)
или запустите программу Setup, чтобы
установить эту надстройку. -
Установите
флажок Пакет анализа,выберите
кнопкуOK.
 менюСервисвыберите командуНадстройки. Если в списке надстроек
менюСервисвыберите командуНадстройки. Если в списке надстроекВызов пакета анализа
Чтобы запустить пакет анализа:
-
В меню Сервисвыберите командуАнализ данных.
-
В списке Инструменты анализавыберите нужную строку.

Корреляция
При выборе строки Корреляцияв
диалоговом запросеАнализ данныхпоявляется следующее окно.

Входной интервал. Введите ссылку
на ячейки, содержащие анализируемые
данные. Ссылка должна состоять как
минимум из двух смежных диапазонов
данных, организованных в виде столбцов
или строк. (Для этого нужно мышью щелкнуть
по кнопке![]()
в правом конце строки, установить
мышь в верхний правый угол диапазона
анализируемых данных и, удерживая
нажатой левую кнопку мыши, отбуксировать
мышь в левый нижний угол диапазона,
нажать клавишуEnter).

Группирование. Установите переключатель
в положениеПо столбцамилиПо
строкамв зависимости от расположения
данных во входном диапазоне.
Метки в первой строке/Метки в первом
столбце. Установите переключатель в
положениеМетки в первой строке,
если первая строка во входном диапазоне
содержит названия столбцов. Установите
переключатель в положениеМетки в
первом столбце, если названия строк
находятся в первом столбце входного
диапазона. Если входной диапазон не
содержит меток, то необходимые заголовки
в выходном диапазоне будут созданы
автоматически. (В других видах анализа
этот флажок выполняет аналогичную
функцию).
Выходной интервал. Введите ссылку
на левую верхнюю ячейку выходного
диапазона. Поскольку коэффициент
корреляции двух наборов данных не
зависит от последовательности их
обработки, то выходная область занимает
только половину предназначенного для
нее места. Ячейки выходного диапазона,
имеющие совпадающие координаты строк
и столбцов, содержат значение 1, так как
каждая строка или столбец во входном
диапазоне полностью коррелирует с самим
собой.
Новый лист. Установите переключатель,
чтобы открыть новый лист в книге и
вставить результаты анализа, начиная
с ячейки A1. Если в этом есть необходимость,
введите имя нового листа в поле,
расположенном напротив соответствующего
положения переключателя.
Новая книга. Установите переключатель,
чтобы открыть новую книгу и вставить
результаты анализа в ячейку A1 на первом
листе в этой книге.
В
Смотри
лист Корреляция в примере.
Вернитесь в текущий документ
через Панель задач
результате программа сформирует
таблицу с коэффициентами корреляции
между выбранными совокупностями.

В статье рассказывается:
- Суть и методы анализа данных
- Активация и запуск функций анализа данных в Excel
- 4 техники анализа данных в Excel
-

Пройди тест и узнай, какая сфера тебе подходит:
айти, дизайн или маркетинг.Бесплатно от Geekbrains
Анализ данных в Excel не ограничен простыми функциями деления, умножения, суммирования и сведения значений из разных ячеек. Данный программный продукт от Microsoft – это мощный комплекс, позволяющий работать со сводными таблицами, подтягивать информацию из внешних отчетов, интерпретировать ее, выстраивая наглядные диаграммы и графики.
Чтобы начать работать с данным блоком функций, их нужно активировать в Excel. Никаких сложностей на подготовительном этапе возникнуть не должно – всё делается довольно просто. С аналитикой чуть посложнее, но справиться можно. О том, как выполняется анализ данных в Excel, вы узнаете из нашего материала.
Суть и методы анализа данных
Американский учёный-статистик Джон Тьюки в 1961 году сформулировал определение анализа данных. Под ним он подразумевал как сами процедуры анализа, так и методы интерпретации результатов этих процедур, а также способы планирования сбора данных в целях упрощения и уточнения анализа и результаты математической статистики, используемые для анализа.
В связи с этим анализ данных представляет собой деятельность по извлечению крупных неструктурированных данных из самых разных источников, а также их реорганизацию в информацию, которая может быть использована в целях:
- ответа на вопросы;
- проверки гипотез;
- принятия решений;
- опровержения теорий.

Есть несколько способов анализа данных, которые распространяются на многочисленные области, от маркетинга до науки. Можно выделить несколько базовых вариантов:
Сбор данных
Data Mining – это анализ больших информационных объемов в целях получения прежде неоткрытых, полезных моделей данных, нестандартных данных, а также выявления зависимостей. Стоит упомянуть, что в качестве главной задачи выступает извлечение не самих данных, а шаблонов и знаний из больших информационных объемов.
Анализ данных производится на основе различных методов информатики, в том числе систем искусственного интеллекта, машинного обучения, статистики и баз данных.
Шаблоны, которые извлекаются посредством интеллектуального анализа данных, могут определяться как сводка входных данных. Они в свою очередь могут быть применены в последующем анализе либо для извлечения более детализированных результатов прогнозирования системой поддержки принятия решений.
Скачать файл
Бизнес-аналитика
Суть бизнес-аналитики заключается в сборе и трансформации больших объемов неструктурированных бизнес-данных, что, в свою очередь, необходимо для упрощения определения, разработки и формирования новых стратегических бизнес-возможностей.
Иными словами, главная задача бизнес-аналитики — сделать процесс интерпретации больших объемов данных более простым, чтобы выявлять новые возможности. Все это способствует разработке результативной стратегии, базирующейся на концепциях, которые могут сформировать конкурентное преимущество на рынке и стабилизировать компанию в долгосрочной перспективе.
Статистический анализ
Статистику можно определить как изучение произведенного сбора, анализа, интерпретации, представления и организации данных.
В процессе анализа данных применяют 2 базовых метода статистики:
- Описательная статистика
Данная разновидность статистики предполагает суммирование данных от всей совокупности или выборки посредством числовых дескрипторов. В качестве этих дескрипторов выступают:
- среднее значение, стандартное отклонение для непрерывных данных;
- частота, процент для категориальных данных.

Топ-30 самых востребованных и высокооплачиваемых профессий 2023
Поможет разобраться в актуальной ситуации на рынке труда

Подборка 50+ ресурсов об IT-сфере
Только лучшие телеграм-каналы, каналы Youtube, подкасты, форумы и многое другое для того, чтобы узнавать новое про IT
ТОП 50+ сервисов и приложений от Geekbrains
Безопасные и надежные программы для работы в наши дни
Уже скачали 20426 ![]()
- Статистическая статистика
В этом случае применяются образцы в выборочных данных в целях формирования выводов о представленной совокупности или учета случайности. Выделяют следующие разновидности выводов:
- ответы на вопросы да / нет о данных (проверка гипотез);
- оценка числовых характеристик данных (оценка);
- описание связей в данных (корреляция);
- моделирование отношений в данных (к примеру, регрессионный анализ).
Прогнозная аналитика

Predictive Analytics применяет статистические модели в целях анализа нынешних и исторических данных. Это необходимо для создания прогнозов относительно дальнейших или иных неизвестных событий. В предпринимательстве эта разновидность анализа применяется в целях определения рисков и возможностей, способствующих принятию правильных решений.
Текстовая аналитика
Text Analytics (Text Mining, Text Data Mining) — это процесс извлечения из текста информации высокого уровня качества. Можно выделить несколько составляющих анализа текста:
- процесс структурирования исходного текста;
- извлечение шаблонов из структурированных данных с применением метода изучения статистических шаблонов и др.;
- оценка и интерпретация полученной информации.
С помощью Microsoft Excel можно использовать целый ряд средств и методов для анализа и интерпретации данных. При этом данные могут быть получены из разных источников. Имеется несколько вариантов трансформации и форматирования данных. Анализ можно осуществлять посредством различных команд, функций и инструментов программы.


Читайте также
В частности, к ним можно отнести условное форматирование, диапазоны, таблицы, текстовые функции, функции даты, функции времени, финансовые функции, промежуточные итоги, быстрый анализ, аудит формул, инструмент Inquire, анализ «что, если», решатели, модель данных, PowerPivot, PowerView, PowerMap и многое другое.
Активация и запуск функций анализа данных в Excel
Excel представляет собой не только редактор таблиц, а еще и отличный инструмент, позволяющий производить всевозможные математические и статистические расчеты. Программа отличается широким функционалом, позволяющим осуществлять вышеописанные процедуры. Однако некоторые из этих функций неактивны по умолчанию. Анализ данных в Excel является как раз такой скрытой возможностью.
Если вы хотите активировать данную функцию, то следует зайти в настройки Microsoft Excel. Причем для разных версий утилиты (2010, 2013 и 2016 года) последовательность действий будет примерно одна и та же. Несущественные расхождения в алгоритме действий имеются лишь для версии 2007 года.
Только до 20.04
Скачай подборку тестов, чтобы определить свои самые конкурентные скиллы
Список документов:
 Тест на определение компетенций
Тест на определение компетенций
Чек-лист «Как избежать обмана при трудоустройстве»
Инструкция по выходу из выгорания
Чтобы получить файл, укажите e-mail:
Подтвердите, что вы не робот,
указав номер телефона:

Уже скачали 7503
Итак, необходимо выполнить следующие действия:
- Нажать на вкладку «Файл» (либо на логотип Microsoft Office в верхнем левом углу экрана для версии 2007 года).
- Нажать на один из пунктов в левой части открывшегося окна — «Параметры».
- Перейти в подраздел «Надстройки» (второй с конца в списке в левой части окна).
- Здесь нужно обратить внимание на нижнюю часть окна. Следует найти параметр «Управление». Обратите внимание на значение в выпадающей форме — вы должны увидеть «Надстройки Excel». Далее следует нажать на вкладку «Перейти…» справа от этого пункта. Если же в выпадающей форме вы увидите какое-то другое значение, нужно будет сначала вписать то, которое мы указали выше.
- В открывшемся окне доступных надстроек найдите пункт «Пакет анализа» и поставьте возле него галочку. Затем нажмите на кнопку «OK» (в правой верхней части).
Выполнив все перечисленные действия, вы активируете нужную функцию и получите соответствующие инструменты. Найти их можно в ленте Excel.

Чтобы открыть тот или иной инструмент анализа данных, нужно произвести следующие действия:
- Зайти в раздел «Данные».
- Найти блок инструментов «Анализ», который расположен на правом краю ленты и нажать на «Анализ данных».
- Выбрать конкретный инструмент из появившегося списка. Наиболее полезными считаются:
- корреляция;
- гистограмма;
- регрессия;
- выборка;
- экспоненциальное сглаживание;
- генератор случайных чисел;
- описательная статистика;
- анализ Фурье;
- различные виды дисперсионного анализа и т.д.
Выбрав нужный инструмент, нажмите на кнопку «OK». Каждый из доступных инструментов работает на основе своего собственного алгоритма.
Таким образом, блок функций «Пакет анализа» включается с помощью всего лишь нескольких простых шагов. При этом если не знать четкую последовательность действий, пользователю сложно найти нужную кнопку.
4 техники анализа данных в Excel
Сводные таблицы
Это важнейший инструмент для обработки больших информационных объемов. Сводные таблицы позволяют быстро делать выводы на основе неструктурированных данных без ручной сортировки и фильтрации. Создание и настройка таблиц осуществляется довольно быстро. Однако от того, какой именно вариант отображения результата вам нужен, будет зависеть алгоритм настройки.
Кроме того, у пользователя есть возможность создавать сводные диаграммы на базе сводных таблиц. При изменении таблиц диаграммы будут обновляться в автоматическом режиме. Скажем, если вы на регулярной основе формируете отчёты по одним и тем же параметрам, то такая функция вам очень пригодится.
Можно вписать какие угодно исходные параметры, например, данные по продажам, отгрузкам, доставкам и т.д.
Для использования сводной таблицы вам необходимо:
- Открыть файл с таблицей, данные которой необходимо проанализировать.
- Выделить диапазон данных для анализа.
- Перейти на вкладку «Вставка», а затем «Таблица». Далее нужно нажать на «Сводная таблица» (для macOS на вкладке «Данные» в группе «Анализ»). Если вы сделали все правильно, то появится диалоговое окно «Создание сводной таблицы».
- Настроить отображение данных, которые есть у вас в таблице.
3D-карты
Благодаря этому методу визуализации данных с географической привязкой вы сможете проанализировать данные и выявить закономерности, имеющие региональное происхождение.

Однако вам не нужно указывать координаты, ведь если правильно ввести географическое название в таблице, программа сделает все сама.
Для применения инструмента вас нужно:
- Открыть файл с таблицей, информацию из которой необходимо визуализировать. К примеру, с данными по разным городам и странам.
- Подготовить данные для отображения на карте. Для этого нужно нажать на «Главная» и перейти на вкладку «Форматировать как таблицу».
- Обозначить диапазон данных для анализа.
- На вкладке «Вставка» вы увидите кнопку «3D-карта».
На карте имеются точки, обозначающие города. Однако нам нужно увидеть информацию, которая привязана к этим городам, например, суммы, отображающиеся через высоту столбика. Если навести курсор на столбик, то вы увидите сумму.
Вместе с тем, довольно полезной считается круговая диаграмма по годам, в которой размер круга зависит от суммы.
Лист прогнозов
В бизнес-процессах имеют место сезонные закономерности. Их, конечно же, нужно учитывать во время планирования. Для этой цели лучше всего подходит «Лист прогноза», который является самым точным инструментом для осуществления прогнозов в рамках Excel. Его применяют для планирования деятельности коммерческих, финансовых, маркетинговых и прочих служб.
Чтобы сделать прогноз, необходимо иметь информацию за предыдущие периоды. Чем больше информации будет внесено, тем более точный прогноз вы получите (минимальный объём информации для хорошего прогноза — 1 год). Учтите, что нужны одинаковые интервалы между точками данных (скажем, месяц или равное количество дней).
Чтобы использовать данную функцию, вам необходимо:
- Открыть таблицу с данными за период и соответствующими ему параметрами, к примеру, от года.
- Выделить 2 ряда данных.
- На вкладке «Данные» нажать на кнопку «Лист прогноза».
- В окне «Создание листа прогноза» выбрать подходящий график или гистограмму для визуализации прогноза.
- Определить дату окончания прогноза.

Читайте также
Быстрый анализ
Данный инструмент позволяет выполнять процедуры анализа в кратчайшие сроки. Чтобы получить необходимые данные, достаточно нажать всего на несколько кнопок. Вам не нужно будет производить никаких расчетов или указывать какие-либо формулы. Единственное что от вас потребуется — выделить нужный диапазон и выбрать тип результата, который вам необходим на выходе.
Благодаря данному инструменту вы можете формировать всевозможные разновидности диаграмм или спарклайны (микрографики прямо в ячейке) буквально в два счета.
Чтобы работать с инструментом, вам нужно:
- Открыть таблицу с данными для анализа.
- Выделить необходимый для анализа диапазон.
- Во время выделения диапазона в нижней части высвечивается кнопка «Быстрый анализ».
Нажав на эту кнопку, вы сможете произвести целый ряд различных действий, которые предложит программа. К примеру, найти итоги. Кроме того, можно узнать суммы, которые проставляются внизу.
Быстрый анализ предполагает несколько способов форматирования. Чтобы узнать, какие значения больше, а какие меньше, нужно перейти в ячейки гистограммы.

Плюс ко всему, вы можете выставить в ячейках значки разных цветов: зелёные — самые большие значения, красные — самые меньшие.
Все эти инструменты позволят вам ускорить процесс анализа данных и сделать его более простым. Используя различные функции, вы сможете с легкостью освоить Microsoft Excel и извлечь из него максимальную пользу.