
7 класс Информатика 10.02.2023
Тема урока: Текстовые документы и их структурные элементы (страница, абзац, строка, слово, символ). Текстовый процессор – инструмент создания, редактирования и форматирования текстов. Правила набора текста.
Цель урока: раскрывать смысл изученных понятий; актуализировать знания о текстовых документах и их структурных элементах; узнать о текстовом процессоре как об инструменте создания, редактирования и форматирования текста; выучить и закрепить правила набора текста.
Вид урока: дистанционный.
Тип урока: урок изучения нового материала.
ХОД УРОКА
— Здравствуйте, ребята!
— С сегодняшнего дня и на протяжении шести уроков мы с вами будем изучать новую тему «Текстовые документы».
— Откройте тетради, запишите дату и тему урока:
Десятое февраля
Дистанционное обучение
Тема: Текстовые документы и их структурные элементы (страница, абзац, строка, слово, символ). Текстовый процессор – инструмент создания, редактирования и форматирования текстов. Правила набора текста.
— Ознакомьтесь с материалом и составьте в тетради конспект:

— Посмотрите на картинку и ознакомьтесь со структурой текстового документа:




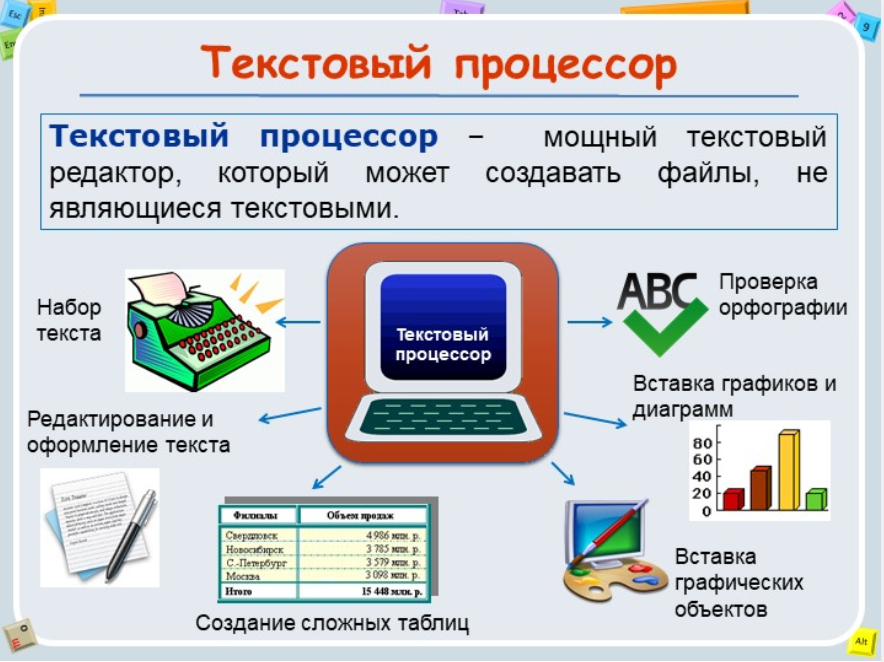

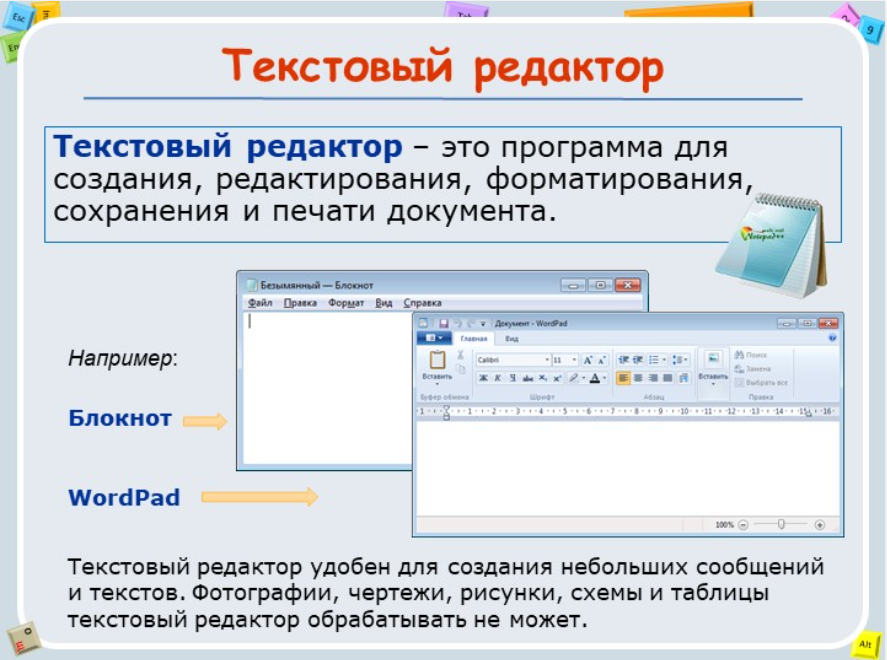



ДОМАШНЕЕ ЗАДАНИЕ:
1. Щелкните на кнопке ПУСК.
2. Выберите пункт меню ВСЕ ПРОГРАММЫ.
3. Выберите пункт меню Microsoft Office Word.
4. Щелкните на имени программы Microsoft Office Word.
5. Наберите и отформатируйте текст по образцу:

6. Далее сохраните набранный текст по следующему алгоритму:

7. Отправьте файл с текстом, а также фото написанных конспектов на почту учителя.
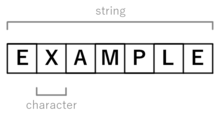
Strings are typically made up of characters, and are often used to store human-readable data, such as words or sentences.
In computer programming, a string is traditionally a sequence of characters, either as a literal constant or as some kind of variable. The latter may allow its elements to be mutated and the length changed, or it may be fixed (after creation). A string is generally considered as a data type and is often implemented as an array data structure of bytes (or words) that stores a sequence of elements, typically characters, using some character encoding. String may also denote more general arrays or other sequence (or list) data types and structures.
Depending on the programming language and precise data type used, a variable declared to be a string may either cause storage in memory to be statically allocated for a predetermined maximum length or employ dynamic allocation to allow it to hold a variable number of elements.
When a string appears literally in source code, it is known as a string literal or an anonymous string.[1]
In formal languages, which are used in mathematical logic and theoretical computer science, a string is a finite sequence of symbols that are chosen from a set called an alphabet.
Purpose[edit]
A primary purpose of strings is to store human-readable text, like words and sentences. Strings are used to communicate information from a computer program to the user of the program.[2] A program may also accept string input from its user. Further, strings may store data expressed as characters yet not intended for human reading.
Example strings and their purposes:
- A message like «
file upload complete» is a string that software shows to end users. In the program’s source code, this message would likely appear as a string literal. - User-entered text, like «
I got a new job today» as a status update on a social media service. Instead of a string literal, the software would likely store this string in a database. - Alphabetical data, like «
AGATGCCGT» representing nucleic acid sequences of DNA.[3] - Computer settings or parameters, like «
?action=edit» as a URL query string. Often these are intended to be somewhat human-readable, though their primary purpose is to communicate to computers.
The term string may also designate a sequence of data or computer records other than characters — like a «string of bits» — but when used without qualification it refers to strings of characters.[4]
History[edit]
Use of the word «string» to mean any items arranged in a line, series or succession dates back centuries.[5][6] In 19th-Century typesetting, compositors used the term «string» to denote a length of type printed on paper; the string would be measured to determine the compositor’s pay.[7][4][8]
Use of the word «string» to mean «a sequence of symbols or linguistic elements in a definite order» emerged from mathematics, symbolic logic, and linguistic theory to speak about the formal behavior of symbolic systems, setting aside the symbols’ meaning.[4]
For example, logician C. I. Lewis wrote in 1918:[9]
A mathematical system is any set of strings of recognisable marks in which some of the strings are taken initially and the remainder derived from these by operations performed according to rules which are independent of any meaning assigned to the marks. That a system should consist of ‘marks’ instead of sounds or odours is immaterial.
According to Jean E. Sammet, «the first realistic string handling and pattern matching language» for computers was COMIT in the 1950s, followed by the SNOBOL language of the early 1960s.[10]
String datatypes[edit]
A string datatype is a datatype modeled on the idea of a formal string. Strings are such an important and useful datatype that they are implemented in nearly every programming language. In some languages they are available as primitive types and in others as composite types. The syntax of most high-level programming languages allows for a string, usually quoted in some way, to represent an instance of a string datatype; such a meta-string is called a literal or string literal.
String length[edit]
Although formal strings can have an arbitrary finite length, the length of strings in real languages is often constrained to an artificial maximum. In general, there are two types of string datatypes: fixed-length strings, which have a fixed maximum length to be determined at compile time and which use the same amount of memory whether this maximum is needed or not, and variable-length strings, whose length is not arbitrarily fixed and which can use varying amounts of memory depending on the actual requirements at run time (see Memory management). Most strings in modern programming languages are variable-length strings. Of course, even variable-length strings are limited in length – by the size of available computer memory. The string length can be stored as a separate integer (which may put another artificial limit on the length) or implicitly through a termination character, usually a character value with all bits zero such as in C programming language. See also «Null-terminated» below.
Character encoding[edit]
String datatypes have historically allocated one byte per character, and, although the exact character set varied by region, character encodings were similar enough that programmers could often get away with ignoring this, since characters a program treated specially (such as period and space and comma) were in the same place in all the encodings a program would encounter. These character sets were typically based on ASCII or EBCDIC. If text in one encoding was displayed on a system using a different encoding, text was often mangled, though often somewhat readable and some computer users learned to read the mangled text.
Logographic languages such as Chinese, Japanese, and Korean (known collectively as CJK) need far more than 256 characters (the limit of a one 8-bit byte per-character encoding) for reasonable representation. The normal solutions involved keeping single-byte representations for ASCII and using two-byte representations for CJK ideographs. Use of these with existing code led to problems with matching and cutting of strings, the severity of which depended on how the character encoding was designed. Some encodings such as the EUC family guarantee that a byte value in the ASCII range will represent only that ASCII character, making the encoding safe for systems that use those characters as field separators. Other encodings such as ISO-2022 and Shift-JIS do not make such guarantees, making matching on byte codes unsafe. These encodings also were not «self-synchronizing», so that locating character boundaries required backing up to the start of a string, and pasting two strings together could result in corruption of the second string.
Unicode has simplified the picture somewhat. Most programming languages now have a datatype for Unicode strings. Unicode’s preferred byte stream format UTF-8 is designed not to have the problems described above for older multibyte encodings. UTF-8, UTF-16 and UTF-32 require the programmer to know that the fixed-size code units are different than the «characters», the main difficulty currently is incorrectly designed APIs that attempt to hide this difference (UTF-32 does make code points fixed-sized, but these are not «characters» due to composing codes).
Implementations[edit]
Some languages, such as C++, Perl and Ruby, normally allow the contents of a string to be changed after it has been created; these are termed mutable strings. In other languages, such as Java, JavaScript, Lua, Python, and Go, the value is fixed and a new string must be created if any alteration is to be made; these are termed immutable strings. Some of these languages with immutable strings also provide another type that is mutable, such as Java and .NET’s StringBuilder, the thread-safe Java StringBuffer, and the Cocoa NSMutableString. There are both advantages and disadvantages to immutability: although immutable strings may require inefficiently creating many copies, they are simpler and completely thread-safe.
Strings are typically implemented as arrays of bytes, characters, or code units, in order to allow fast access to individual units or substrings—including characters when they have a fixed length. A few languages such as Haskell implement them as linked lists instead.
Some languages, such as Prolog and Erlang, avoid implementing a dedicated string datatype at all, instead adopting the convention of representing strings as lists of character codes.
Representations[edit]
Representations of strings depend heavily on the choice of character repertoire and the method of character encoding. Older string implementations were designed to work with repertoire and encoding defined by ASCII, or more recent extensions like the ISO 8859 series. Modern implementations often use the extensive repertoire defined by Unicode along with a variety of complex encodings such as UTF-8 and UTF-16.
The term byte string usually indicates a general-purpose string of bytes, rather than strings of only (readable) characters, strings of bits, or such. Byte strings often imply that bytes can take any value and any data can be stored as-is, meaning that there should be no value interpreted as a termination value.
Most string implementations are very similar to variable-length arrays with the entries storing the character codes of corresponding characters. The principal difference is that, with certain encodings, a single logical character may take up more than one entry in the array. This happens for example with UTF-8, where single codes (UCS code points) can take anywhere from one to four bytes, and single characters can take an arbitrary number of codes. In these cases, the logical length of the string (number of characters) differs from the physical length of the array (number of bytes in use). UTF-32 avoids the first part of the problem.
Null-terminated[edit]
The length of a string can be stored implicitly by using a special terminating character; often this is the null character (NUL), which has all bits zero, a convention used and perpetuated by the popular C programming language.[11] Hence, this representation is commonly referred to as a C string. This representation of an n-character string takes n + 1 space (1 for the terminator), and is thus an implicit data structure.
In terminated strings, the terminating code is not an allowable character in any string. Strings with length field do not have this limitation and can also store arbitrary binary data.
An example of a null-terminated string stored in a 10-byte buffer, along with its ASCII (or more modern UTF-8) representation as 8-bit hexadecimal numbers is:
F |
R |
A |
N |
K
|
NUL | k
|
e
|
f
|
w
|
| 4616 | 5216 | 4116 | 4E16 | 4B16 | 0016 | 6B16 | 6516 | 6616 | 7716 |
The length of the string in the above example, «FRANK«, is 5 characters, but it occupies 6 bytes. Characters after the terminator do not form part of the representation; they may be either part of other data or just garbage. (Strings of this form are sometimes called ASCIZ strings, after the original assembly language directive used to declare them.)
Byte- and bit-terminated[edit]
Using a special byte other than null for terminating strings has historically appeared in both hardware and software, though sometimes with a value that was also a printing character. $ was used by many assembler systems, : used by CDC systems (this character had a value of zero), and the ZX80 used "[12] since this was the string delimiter in its BASIC language.
Somewhat similar, «data processing» machines like the IBM 1401 used a special word mark bit to delimit strings at the left, where the operation would start at the right. This bit had to be clear in all other parts of the string. This meant that, while the IBM 1401 had a seven-bit word, almost no-one ever thought to use this as a feature, and override the assignment of the seventh bit to (for example) handle ASCII codes.
Early microcomputer software relied upon the fact that ASCII codes do not use the high-order bit, and set it to indicate the end of a string. It must be reset to 0 prior to output.[13]
Length-prefixed[edit]
The length of a string can also be stored explicitly, for example by prefixing the string with the length as a byte value. This convention is used in many Pascal dialects; as a consequence, some people call such a string a Pascal string or P-string. Storing the string length as byte limits the maximum string length to 255. To avoid such limitations, improved implementations of P-strings use 16-, 32-, or 64-bit words to store the string length. When the length field covers the address space, strings are limited only by the available memory.
If the length is bounded, then it can be encoded in constant space, typically a machine word, thus leading to an implicit data structure, taking n + k space, where k is the number of characters in a word (8 for 8-bit ASCII on a 64-bit machine, 1 for 32-bit UTF-32/UCS-4 on a 32-bit machine, etc.).
If the length is not bounded, encoding a length n takes log(n) space (see fixed-length code), so length-prefixed strings are a succinct data structure, encoding a string of length n in log(n) + n space.
In the latter case, the length-prefix field itself doesn’t have fixed length, therefore the actual string data needs to be moved when the string grows such that the length field needs to be increased.
Here is a Pascal string stored in a 10-byte buffer, along with its ASCII / UTF-8 representation:
| length | F |
R |
A |
N |
K
|
k
|
e
|
f
|
w
|
| 0516 | 4616 | 5216 | 4116 | 4E16 | 4B16 | 6B16 | 6516 | 6616 | 7716 |
Strings as records[edit]
Many languages, including object-oriented ones, implement strings as records with an internal structure like:
class string { size_t length; char *text; };
However, since the implementation is usually hidden, the string must be accessed and modified through member functions. text is a pointer to a dynamically allocated memory area, which might be expanded as needed. See also string (C++).
Other representations[edit]
Both character termination and length codes limit strings: For example, C character arrays that contain null (NUL) characters cannot be handled directly by C string library functions: Strings using a length code are limited to the maximum value of the length code.
Both of these limitations can be overcome by clever programming.
It is possible to create data structures and functions that manipulate them that do not have the problems associated with character termination and can in principle overcome length code bounds. It is also possible to optimize the string represented using techniques from run length encoding (replacing repeated characters by the character value and a length) and Hamming encoding[clarification needed].
While these representations are common, others are possible. Using ropes makes certain string operations, such as insertions, deletions, and concatenations more efficient.
The core data structure in a text editor is the one that manages the string (sequence of characters) that represents the current state of the file being edited.
While that state could be stored in a single long consecutive array of characters, a typical text editor instead uses an alternative representation as its sequence data structure—a gap buffer, a linked list of lines, a piece table, or a rope—which makes certain string operations, such as insertions, deletions, and undoing previous edits, more efficient.[14]
Security concerns[edit]
The differing memory layout and storage requirements of strings can affect the security of the program accessing the string data. String representations requiring a terminating character are commonly susceptible to buffer overflow problems if the terminating character is not present, caused by a coding error or an attacker deliberately altering the data. String representations adopting a separate length field are also susceptible if the length can be manipulated. In such cases, program code accessing the string data requires bounds checking to ensure that it does not inadvertently access or change data outside of the string memory limits.
String data is frequently obtained from user input to a program. As such, it is the responsibility of the program to validate the string to ensure that it represents the expected format. Performing limited or no validation of user input can cause a program to be vulnerable to code injection attacks.
Literal strings[edit]
Sometimes, strings need to be embedded inside a text file that is both human-readable and intended for consumption by a machine. This is needed in, for example, source code of programming languages, or in configuration files. In this case, the NUL character doesn’t work well as a terminator since it is normally invisible (non-printable) and is difficult to input via a keyboard. Storing the string length would also be inconvenient as manual computation and tracking of the length is tedious and error-prone.
Two common representations are:
- Surrounded by quotation marks (ASCII 0x22 double quote
"str"or ASCII 0x27 single quote'str'), used by most programming languages. To be able to include special characters such as the quotation mark itself, newline characters, or non-printable characters, escape sequences are often available, usually prefixed with the backslash character (ASCII 0x5C). - Terminated by a newline sequence, for example in Windows INI files.
Non-text strings[edit]
While character strings are very common uses of strings, a string in computer science may refer generically to any sequence of homogeneously typed data. A bit string or byte string, for example, may be used to represent non-textual binary data retrieved from a communications medium. This data may or may not be represented by a string-specific datatype, depending on the needs of the application, the desire of the programmer, and the capabilities of the programming language being used. If the programming language’s string implementation is not 8-bit clean, data corruption may ensue.
C programmers draw a sharp distinction between a «string», aka a «string of characters», which by definition is always null terminated, vs. a «byte string» or «pseudo string» which may be stored in the same array but is often not null terminated.
Using C string handling functions on such a «byte string» often seems to work, but later leads to security problems.[15][16][17]
String processing algorithms[edit]
«Stringology» redirects here. For the physical theory, see String theory.
There are many algorithms for processing strings, each with various trade-offs. Competing algorithms can be analyzed with respect to run time, storage requirements, and so forth. The name stringology was coined in 1984 by computer scientist Zvi Galil for the theory of algorithms and data structures used for string processing.[18][19][20]
Some categories of algorithms include:
- String searching algorithms for finding a given substring or pattern
- String manipulation algorithms
- Sorting algorithms
- Regular expression algorithms
- Parsing a string
- Sequence mining
Advanced string algorithms often employ complex mechanisms and data structures, among them suffix trees and finite-state machines.
Character string-oriented languages and utilities[edit]
Character strings are such a useful datatype that several languages have been designed in order to make string processing applications easy to write. Examples include the following languages:
- awk
- Icon
- MUMPS
- Perl
- Rexx
- Ruby
- sed
- SNOBOL
- Tcl
- TTM
Many Unix utilities perform simple string manipulations and can be used to easily program some powerful string processing algorithms. Files and finite streams may be viewed as strings.
Some APIs like Multimedia Control Interface, embedded SQL or printf use strings to hold commands that will be interpreted.
Many scripting programming languages, including Perl, Python, Ruby, and Tcl employ regular expressions to facilitate text operations. Perl is particularly noted for its regular expression use,[21] and many other languages and applications implement Perl compatible regular expressions.
Some languages such as Perl and Ruby support string interpolation, which permits arbitrary expressions to be evaluated and included in string literals.
Character string functions[edit]
String functions are used to create strings or change the contents of a mutable string. They also are used to query information about a string. The set of functions and their names varies depending on the computer programming language.
The most basic example of a string function is the string length function – the function that returns the length of a string (not counting any terminator characters or any of the string’s internal structural information) and does not modify the string. This function is often named length or len. For example, length("hello world") would return 11. Another common function is concatenation, where a new string is created by appending two strings, often this is the + addition operator.
Some microprocessor’s instruction set architectures contain direct support for string operations, such as block copy (e.g. In intel x86m REPNZ MOVSB).[22]
Formal theory[edit]
Let Σ be a finite set of symbols (alternatively called characters), called the alphabet. No assumption is made about the nature of the symbols. A string (or word) over Σ is any finite sequence of symbols from Σ.[23] For example, if Σ = {0, 1}, then 01011 is a string over Σ.
The length of a string s is the number of symbols in s (the length of the sequence) and can be any non-negative integer; it is often denoted as |s|. The empty string is the unique string over Σ of length 0, and is denoted ε or λ.[23][24]
The set of all strings over Σ of length n is denoted Σn. For example, if Σ = {0, 1}, then Σ2 = {00, 01, 10, 11}. Note that Σ0 = {ε} for any alphabet Σ.
The set of all strings over Σ of any length is the Kleene closure of Σ and is denoted Σ*. In terms of Σn,

For example, if Σ = {0, 1}, then Σ* = {ε, 0, 1, 00, 01, 10, 11, 000, 001, 010, 011, …}. Although the set Σ* itself is countably infinite, each element of Σ* is a string of finite length.
A set of strings over Σ (i.e. any subset of Σ*) is called a formal language over Σ. For example, if Σ = {0, 1}, the set of strings with an even number of zeros, {ε, 1, 00, 11, 001, 010, 100, 111, 0000, 0011, 0101, 0110, 1001, 1010, 1100, 1111, …}, is a formal language over Σ.
Concatenation and substrings[edit]
Concatenation is an important binary operation on Σ*. For any two strings s and t in Σ*, their concatenation is defined as the sequence of symbols in s followed by the sequence of characters in t, and is denoted st. For example, if Σ = {a, b, …, z}, s = bear, and t = hug, then st = bearhug and ts = hugbear.
String concatenation is an associative, but non-commutative operation. The empty string ε serves as the identity element; for any string s, εs = sε = s. Therefore, the set Σ* and the concatenation operation form a monoid, the free monoid generated by Σ. In addition, the length function defines a monoid homomorphism from Σ* to the non-negative integers (that is, a function  , such that
, such that  ).
).
A string s is said to be a substring or factor of t if there exist (possibly empty) strings u and v such that t = usv. The relation «is a substring of» defines a partial order on Σ*, the least element of which is the empty string.
Prefixes and suffixes[edit]
A string s is said to be a prefix of t if there exists a string u such that t = su. If u is nonempty, s is said to be a proper prefix of t. Symmetrically, a string s is said to be a suffix of t if there exists a string u such that t = us. If u is nonempty, s is said to be a proper suffix of t. Suffixes and prefixes are substrings of t. Both the relations «is a prefix of» and «is a suffix of» are prefix orders.
Reversal[edit]
The reverse of a string is a string with the same symbols but in reverse order. For example, if s = abc (where a, b, and c are symbols of the alphabet), then the reverse of s is cba. A string that is the reverse of itself (e.g., s = madam) is called a palindrome, which also includes the empty string and all strings of length 1.
Rotations[edit]
A string s = uv is said to be a rotation of t if t = vu. For example, if Σ = {0, 1} the string 0011001 is a rotation of 0100110, where u = 00110 and v = 01. As another example, the string abc has three different rotations, viz. abc itself (with u=abc, v=ε), bca (with u=bc, v=a), and cab (with u=c, v=ab).
Lexicographical ordering[edit]
It is often useful to define an ordering on a set of strings. If the alphabet Σ has a total order (cf. alphabetical order) one can define a total order on Σ* called lexicographical order. For example, if Σ = {0, 1} and 0 < 1, then the lexicographical order on Σ* includes the relationships ε < 0 < 00 < 000 < … < 0001 < 001 < 01 < 010 < 011 < 0110 < 01111 < 1 < 10 < 100 < 101 < 111 < 1111 < 11111 … The lexicographical order is total if the alphabetical order is, but isn’t well-founded for any nontrivial alphabet, even if the alphabetical order is.
See Shortlex for an alternative string ordering that preserves well-foundedness.
String operations[edit]
A number of additional operations on strings commonly occur in the formal theory. These are given in the article on string operations.
Topology[edit]

(Hyper)cube of binary strings of length 3
Strings admit the following interpretation as nodes on a graph, where k is the number of symbols in Σ:
- Fixed-length strings of length n can be viewed as the integer locations in an n-dimensional hypercube with sides of length k-1.
- Variable-length strings (of finite length) can be viewed as nodes on a perfect k-ary tree.
- Infinite strings (otherwise not considered here) can be viewed as infinite paths on a k-node complete graph.
The natural topology on the set of fixed-length strings or variable-length strings is the discrete topology, but the natural topology on the set of infinite strings is the limit topology, viewing the set of infinite strings as the inverse limit of the sets of finite strings. This is the construction used for the p-adic numbers and some constructions of the Cantor set, and yields the same topology.
Isomorphisms between string representations of topologies can be found by normalizing according to the lexicographically minimal string rotation.
See also[edit]
- Binary-safe — a property of string manipulating functions treating their input as raw data stream
- Bit array — a string of binary digits
- C string handling — overview of C string handling
- C++ string handling — overview of C++ string handling
- Comparison of programming languages (string functions)
- Connection string — passed to a driver to initiate a connection (e.g., to a database)
- Empty string — its properties and representation in programming languages
- Incompressible string — a string that cannot be compressed by any algorithm
- Rope (data structure) — a data structure for efficiently manipulating long strings
- String metric — notions of similarity between strings
References[edit]
- ^ «Introduction To Java — MFC 158 G». Archived from the original on 2016-03-03.
String literals (or constants) are called ‘anonymous strings’
- ^ de St. Germain, H. James. «Strings». University of Utah, Kahlert School of Computing.
- ^ Francis, David M.; Merk, Heather L. (November 14, 2019). «DNA as a Biochemical Entity and Data String».
- ^ a b c Burchfield, R.W. (1986). «string». A Supplement to the Oxford English Dictionary. Oxford at the Clarendon Press.
- ^ «string». The Oxford English Dictionary. Vol. X. Oxford at the Clarendon Press. 1933.
- ^ «string (n.)». Online Etymology Dictionary.
- ^ Whitney, William Dwight; Smith, Benjamin E. «string». The Century Dictionary. New York: The Century Company. p. 5994.
- ^ «Old Union’s Demise». Milwaukee Sentinel. January 11, 1898. p. 3.
- ^ Lewis, C.I. (1918). A survey of symbolic logic. Berkeley: University of California Press. p. 355.
- ^ Sammet, Jean E. (July 1972). «Programming Languages: History and Future» (PDF). Communications of the ACM. 15 (7).
- ^
Bryant, Randal E.; David, O’Hallaron (2003), Computer Systems: A Programmer’s Perspective (2003 ed.), Upper Saddle River, NJ: Pearson Education, p. 40, ISBN 0-13-034074-X, archived from the original on 2007-08-06 - ^ Wearmouth, Geoff. «An Assembly Listing of the ROM of the Sinclair ZX80». Archived from the original on August 15, 2015.
{{cite web}}: CS1 maint: unfit URL (link) - ^ Allison, Dennis. «Design Notes for Tiny BASIC». Archived from the original on 2017-04-10.
- ^
Charles Crowley.
«Data Structures for Text Sequences» Archived 2016-03-04 at the Wayback Machine.
Section
«Introduction» Archived 2016-04-04 at the Wayback Machine. - ^
«strlcpy and strlcat — consistent, safe, string copy and concatenation.» Archived 2016-03-13 at the Wayback Machine - ^
«A rant about strcpy, strncpy and strlcpy.» Archived 2016-02-29 at the Wayback Machine - ^
Keith Thompson.
«No, strncpy() is not a «safer» strcpy()».
2012. - ^ «The Prague Stringology Club». stringology.org. Archived from the original on 1 June 2015. Retrieved 23 May 2015.
- ^ Evarts, Holly (18 March 2021). «Former Dean Zvi Galil Named a Top 10 Most Influential Computer Scientist in the Past Decade». Columbia Engineering.
He invented the terms ‘stringology,’ which is a subfield of string algorithms,
- ^ Crochemore, Maxime (2002). Jewels of stringology. Singapore. p. v. ISBN 981-02-4782-6.
The term stringology is a popular nickname for string algorithms as well as for text algorithms.
- ^ «Essential Perl». Archived from the original on 2012-04-21.
Perl’s most famous strength is in string manipulation with regular expressions.
- ^ «x86 string instructions». Archived from the original on 2015-03-27.
- ^ a b Barbara H. Partee; Alice ter Meulen; Robert E. Wall (1990). Mathematical Methods in Linguistics. Kluwer.
- ^ John E. Hopcroft, Jeffrey D. Ullman (1979). Introduction to Automata Theory, Languages, and Computation. Addison-Wesley. ISBN 0-201-02988-X. Here: sect.1.1, p.1
Эта статья о типе данных. Для использования в других целях см. Строка (значения).
|
|
Эта статья нужны дополнительные цитаты для проверка. Пожалуйста помоги улучшить эту статью к добавление цитат в надежные источники. Материал, не полученный от источника, может быть оспорен и удален. |

В компьютерное программирование, а нить традиционно последовательность из символы, либо как буквальная константа или как какая-то переменная. Последний может допускать мутацию своих элементов и изменение длины или может быть исправлен (после создания). Строка обычно рассматривается как тип данных и часто реализуется как структура данных массива из байты (или же слова ), который хранит последовательность элементов, обычно символов, используя некоторые кодировка символов. Нить может также обозначать более общий массивы или другая последовательность (или список ) типы данных и структуры.
В зависимости от языка программирования и используемого точного типа данных Переменная объявленная как строка, может либо вызвать статическое выделение памяти в памяти для предопределенной максимальной длины, либо использовать динамическое размещение чтобы он мог содержать переменное количество элементов.
Когда строка появляется буквально в исходный код, он известен как строковый литерал или анонимная строка.[1]
В формальные языки, которые используются в математическая логика и теоретическая информатика, строка — это конечная последовательность символы которые выбраны из набор называется алфавит.
Строковые типы данных
А строковый тип данных это тип данных, смоделированный по идее формальной строки. Строки — это такой важный и полезный тип данных, что они реализованы почти в каждом язык программирования. На некоторых языках они доступны как примитивные типы а в других как составные типы. В синтаксис большинства языков программирования высокого уровня позволяет строке, обычно заключенной в кавычки, представлять экземпляр строкового типа данных; такая мета-строка называется буквальный или же строковый литерал.
Длина строки
Хотя формальные строки могут иметь произвольную конечную длину, длина строк в реальных языках часто ограничивается искусственным максимумом. В общем, есть два типа строковых типов данных: струны фиксированной длины, которые имеют фиксированную максимальную длину, определяемую при время компиляции и которые используют один и тот же объем памяти независимо от того, нужен этот максимум или нет, и строки переменной длины, длина которого не является произвольно фиксированной и может использовать различные объемы памяти в зависимости от фактических требований во время выполнения (см. Управление памятью ). Большинство струнных в модерне языки программирования — строки переменной длины. Конечно, даже строки переменной длины ограничены по длине — размером доступного память компьютера. Длина строки может быть сохранена как отдельное целое число (что может наложить другое искусственное ограничение на длину) или неявно через символ завершения, обычно это символьное значение со всеми нулевыми битами, например, в языке программирования C. Смотрите также «Без завершения » ниже.
Кодировка символов
Для строковых типов данных исторически выделялся один байт на символ, и, хотя точный набор символов варьировался в зависимости от региона, кодировки символов были достаточно похожи, чтобы программисты могли часто игнорировать это, поскольку символы, которые программа обрабатывала особым образом (например, точка, пробел и запятая ) находились в одном месте во всех кодировках, с которыми могла столкнуться программа. Эти наборы символов обычно основывались на ASCII или же EBCDIC. Если текст в одной кодировке отображался в системе с использованием другой кодировки, текст часто отображался. искалеченный, хотя часто бывает несколько читабельным, и некоторые пользователи компьютеров научились читать искаженный текст.
Логографический языки, такие как Китайский, Японский, и Корейский (известные вместе как CJK ) требуется намного больше 256 символов (ограничение в один 8-битный байт на символьную кодировку) для разумного представления. Обычные решения включают сохранение однобайтовых представлений для ASCII и использование двухбайтовых представлений для CJK. идеограммы. Их использование с существующим кодом приводило к проблемам с сопоставлением и обрезкой строк, серьезность которых зависела от того, как была разработана кодировка символов. Некоторые кодировки, такие как EUC Семейство гарантирует, что значение байта в диапазоне ASCII будет представлять только этот символ ASCII, что делает кодирование безопасным для систем, которые используют эти символы в качестве разделителей полей. Другие кодировки, такие как ISO-2022 и Shift-JIS не дают таких гарантий, что делает сопоставление по байтовым кодам небезопасным. Эти кодировки также не были «самосинхронизирующимися», поэтому для определения границ символов требовалось резервное копирование до начала строки, а вставка двух строк вместе могла привести к повреждению второй строки.
Unicode несколько упростил картину. В большинстве языков программирования теперь есть тип данных для строк Unicode. Предпочтительный формат байтового потока Unicode UTF-8 спроектирован так, чтобы не иметь проблем, описанных выше для старых многобайтовых кодировок. UTF-8, UTF-16 и UTF-32 требуется, чтобы программист знал, что единицы кода фиксированного размера отличаются от «символов», основная трудность в настоящее время заключается в неправильно разработанных API, которые пытаются скрыть это различие (UTF-32 действительно делает кодовые точки фиксированного размера, но это не «символы» из-за составления кодов).
Реализации
Некоторые языки, такие как C ++ и Рубин, обычно позволяют изменять содержимое строки после того, как она была создана; они называются изменчивый струны. На других языках, например Ява и Python, значение фиксировано, и необходимо создать новую строку, если необходимо внести какие-либо изменения; они называются неизменный строки (некоторые из этих языков также предоставляют другой изменяемый тип, например Java и .СЕТЬ StringBuilder, потокобезопасная Java StringBuffer, а Какао NSMutableString).
Строки обычно реализуются как массивы байтов, символов или кодовых единиц, чтобы обеспечить быстрый доступ к отдельным единицам или подстрокам, включая символы, если они имеют фиксированную длину. Несколько языков, например Haskell реализовать их как связанные списки вместо.
Некоторые языки, например Пролог и Erlang, избегайте реализации специального строкового типа данных вообще, вместо этого принимайте соглашение о представлении строк в виде списков кодов символов.
Представления
Представления строк сильно зависят от выбора репертуара символов и метода кодирования символов. Старые строковые реализации были разработаны для работы с репертуаром и кодировкой, определенными ASCII, или более поздними расширениями, такими как ISO 8859 серии. Современные реализации часто используют обширный репертуар, определенный Unicode, вместе с множеством сложных кодировок, таких как UTF-8 и UTF-16.
Период, термин байтовая строка обычно обозначает строку байтов общего назначения, а не строки только (читаемых) символов, строки битов и т.п. Строки байтов часто подразумевают, что байты могут принимать любое значение и любые данные могут храниться как есть, что означает, что не должно быть никакого значения, интерпретируемого как значение завершения.
Большинство строковых реализаций очень похожи на переменную длину массивы с записями, хранящими коды символов соответствующих символов. Принципиальное отличие состоит в том, что при определенных кодировках один логический символ может занимать более одной записи в массиве. Это происходит, например, с UTF-8, где одиночные коды (UCS кодовые точки) могут занимать от одного до четырех байтов, а отдельные символы могут принимать произвольное количество кодов. В этих случаях логическая длина строки (количество символов) отличается от физической длины массива (количества используемых байтов). UTF-32 позволяет избежать первой части проблемы.
Без завершения
Длина строки может быть сохранена неявно с помощью специального символа завершения; часто это нулевой символ (NUL), в котором все биты равны нулю, соглашение, используемое и закрепленное популярными Язык программирования C.[2] Следовательно, это представление обычно называют C строка. Это представление п-строка символов принимает п + 1 пробел (1 для терминатора) и, таким образом, является неявная структура данных.
В строках с завершением код завершения не является допустимым символом ни в одной строке. Струны с длина поле не имеет этого ограничения и может также хранить произвольные двоичные данные.
Пример строка с завершающим нулем хранится в 10-байтовом буфер вместе с его ASCII (или более современный UTF-8 ) представление как 8-битное шестнадцатеричные числа является:
F |
р |
А |
N |
K |
NUL | k |
е |
ж |
ш |
| 4616 | 5216 | 4116 | 4E16 | 4B16 | 0016 | 6B16 | 6516 | 6616 | 7716 |
Длина строки в приведенном выше примере «ОТКРОВЕННЫЙ«, составляет 5 символов, но занимает 6 байтов. Символы после терминатора не являются частью представления; они могут быть частью других данных или просто мусором. (Строки такой формы иногда называют Строки ASCIZ, после оригинала язык ассемблера директива, используемая для их объявления.)
Байт- и битовое завершение
Использование специального байта, отличного от нуля, для завершения строки исторически появлялось как в аппаратном, так и в программном обеспечении, хотя иногда и со значением, которое также было печатным символом. $ использовался многими ассемблерными системами, : использован CDC систем (этот символ имел нулевое значение), а ZX80 использовал "[3] поскольку это был разделитель строк на его БЕЙСИКЕ.
В чем-то похожие машины для «обработки данных», такие как IBM 1401 использовал специальный словесный знак бит, чтобы разделить строки слева, где операция будет начинаться справа. Этот бит должен быть очищен во всех остальных частях строки. Это означало, что, хотя в IBM 1401 было семибитное слово, почти никто никогда не думал использовать его в качестве функции и отменять назначение седьмого бита (например) для обработки кодов ASCII.
Раннее программное обеспечение для микрокомпьютеров основывалось на том факте, что коды ASCII не используют бит старшего разряда, и устанавливали его для обозначения конца строки. Перед выводом он должен быть сброшен на 0.[4]
С префиксом длины
Длину строки также можно сохранить явно, например, поставив перед строкой длину в качестве байтового значения. Это соглашение используется во многих Паскаль диалекты; как следствие, некоторые люди называют такую строку Строка Паскаля или же P-строка. Сохранение длины строки в байтах ограничивает максимальную длину строки 255. Чтобы избежать таких ограничений, улучшенные реализации P-строк используют 16-, 32- или 64-разрядные. слова для хранения длины строки. Когда длина поле охватывает адресное пространство, строки ограничены только доступная память.
Если длина ограничена, то ее можно закодировать в постоянном пространстве, обычно в машинном слове, что приводит к неявная структура данных, принимая п + k пространство, где k — количество символов в слове (8 для 8-битного ASCII на 64-битной машине, 1 для 32-битного UTF-32 / UCS-4 на 32-битной машине и т. д.). Если длина не равна ограниченный, кодирование длины п берет журнал (п) пространство (см. код фиксированной длины ), поэтому строки с префиксом длины являются лаконичная структура данных, кодирующая строку длины п в журнале (п) + п Космос.
В последнем случае само поле префикса длины не имеет фиксированной длины, поэтому фактические строковые данные необходимо перемещать, когда строка растет, так что поле длины нужно увеличивать.
Вот строка Паскаля, хранящаяся в 10-байтовом буфере, вместе с ее представлением ASCII / UTF-8:
| длина | F |
р |
А |
N |
K |
k |
е |
ж |
ш |
| 0516 | 4616 | 5216 | 4116 | 4E16 | 4B16 | 6B16 | 6516 | 6616 | 7716 |
Строки как записи
Многие языки, включая объектно-ориентированные, реализуют строки как записи с внутренней структурой типа:
учебный класс нить { size_t длина; char *текст;};
Однако, поскольку реализация обычно скрытый, строка должна быть доступна и изменена через функции-члены. текст — указатель на динамически выделяемую область памяти, которая может быть расширена по мере необходимости. Смотрите также строка (C ++).
Другие представления
И символы завершения, и коды длины ограничивают строки: например, символьные массивы C, содержащие нулевые (NUL) символы, не могут быть обработаны напрямую C строка библиотечные функции: строки, использующие код длины, ограничены максимальным значением кода длины.
Оба эти ограничения можно преодолеть с помощью грамотного программирования.
Можно создавать структуры данных и функции, которые манипулируют ими, которые не имеют проблем, связанных с завершением символа, и могут в принципе преодолеть ограничения длины кода. Также возможно оптимизировать строку, представленную, используя методы из кодирование длины прогона (замена повторяющихся символов значением символа и длиной) и Кодирование Хэмминга[требуется разъяснение ].
Хотя эти представления распространены, возможны и другие. С помощью веревки делает некоторые строковые операции, такие как вставки, удаления и конкатенации, более эффективными.
Основная структура данных в Текстовый редактор это тот, который управляет строкой (последовательностью символов), которая представляет текущее состояние редактируемого файла. Хотя это состояние может храниться в одном длинном последовательном массиве символов, типичный текстовый редактор вместо этого использует альтернативное представление в качестве своей последовательности структура данных — a буфер промежутка, а связанный список линий, штучный стол, или веревка — что делает некоторые строковые операции, такие как вставка, удаление и отмена предыдущих изменений, более эффективными.[5]
Проблемы безопасности
Различная структура памяти и требования к хранению строк могут повлиять на безопасность программы, обращающейся к строковым данным. Строковые представления, требующие завершающего символа, обычно подвержены переполнение буфера проблемы, если завершающий символ отсутствует, вызванные ошибкой кодирования или злоумышленник умышленное изменение данных. Строковые представления, использующие отдельное поле длины, также восприимчивы, если длиной можно управлять. В таких случаях программный код для доступа к строковым данным требует проверка границ чтобы гарантировать, что он не сможет случайно получить доступ или изменить данные за пределами строковой памяти.
Строковые данные часто получаются из пользовательского ввода в программу. Таким образом, программа несет ответственность за проверку строки, чтобы убедиться, что она представляет ожидаемый формат. Выполнение ограниченная проверка или без проверки пользовательского ввода может сделать программу уязвимой для внедрение кода атаки.
Буквальные строки
Иногда строки необходимо встраивать в текстовый файл, который удобен для чтения и предназначен для использования машиной. Это необходимо, например, в исходном коде языков программирования или в файлах конфигурации. В этом случае символ NUL плохо работает в качестве терминатора, поскольку обычно он невидим (не печатается) и его трудно вводить с клавиатуры. Сохранение длины строки также будет неудобным, поскольку ручное вычисление и отслеживание длины утомительно и подвержено ошибкам.
Два общих представления:
- Окружен кавычки (ASCII 0x22 двойные кавычки или одинарные кавычки ASCII 0x27), используемые в большинстве языков программирования. Чтобы иметь возможность включать специальные символы, такие как кавычки, символы новой строки или непечатаемые символы, escape-последовательности часто доступны, обычно с префиксом обратная косая черта символ (ASCII 0x5C).
- Прекращено новая линия последовательность, например в Windows Файлы INI.
Нетекстовые строки
В то время как символьные строки — это очень распространенное использование строк, строка в информатике может относиться к любой последовательности однородно типизированных данных. А битовая строка или же байтовая строка, например, может использоваться для представления нетекстовых двоичные данные извлекается из средства связи. Эти данные могут быть представлены или не представлены типом данных, зависящим от строки, в зависимости от потребностей приложения, желания программиста и возможностей используемого языка программирования. Если строковая реализация языка программирования не 8-битный чистый, это может привести к повреждению данных.
Программисты на C проводят резкое различие между «строкой», также известной как «строка символов», которая по определению всегда заканчивается нулем, и «байтовой строкой» или «псевдострочкой», которые могут храниться в том же массиве, но часто не завершается нулевым символом. Обработка строки C функции с такой «байтовой строкой» часто кажутся работающими, но позже приводит к проблемы безопасности.[6][7][8]
Алгоритмы обработки строк
«Стрингология» перенаправляется сюда. Относительно физической теории см. Теория струн.
Есть много алгоритмы для обработки строк, каждая из которых имеет различные компромиссы. Конкурирующие алгоритмы могут быть проанализированы относительно времени выполнения, требований к памяти и т. д.
Некоторые категории алгоритмов включают:
- Алгоритмы поиска по строкам для поиска данной подстроки или шаблона
- Алгоритмы обработки строк
- Алгоритмы сортировки
- Регулярное выражение алгоритмы
- Парсинг строка
- Последовательный майнинг
Продвинутые строковые алгоритмы часто используют сложные механизмы и структуры данных, в том числе суффиксные деревья и конечные автоматы.
Название струнология был придуман в 1984 году компьютерным ученым Цви Галил по вопросу об алгоритмах и структурах данных, используемых для обработки строк.[9][требуется сторонний источник ]
Языки и утилиты, ориентированные на символьные строки
Символьные строки являются настолько полезным типом данных, что было разработано несколько языков, чтобы упростить написание приложений для обработки строк. Примеры включают следующие языки:
- awk
- Значок
- МАМПЫ
- Perl
- Rexx
- Рубин
- sed
- СНОБОЛ
- Tcl
- ТТМ
Много Unix Утилиты выполняют простые манипуляции со строками и могут использоваться для простого программирования некоторых мощных алгоритмов обработки строк. Файлы и конечные потоки можно рассматривать как строки.
Немного API подобно Мультимедийный интерфейс управления, встроенный SQL или же printf используйте строки для хранения команд, которые будут интерпретироваться.
Недавний скриптовые языки программирования, включая Perl, Python, Ruby и Tcl используют обычные выражения для облегчения текстовых операций. Perl особенно известен использованием регулярных выражений,[10] и многие другие языки и приложения реализуют Регулярные выражения, совместимые с Perl.
Некоторые языки, такие как Perl и Ruby, поддерживают строковая интерполяция, который позволяет вычислять произвольные выражения и включать их в строковые литералы.
Функции символьных строк
Строковые функции используются для создания строк или изменения содержимого изменяемой строки. Они также используются для запроса информации о строке. Набор функций и их названия различаются в зависимости от язык компьютерного программирования.
Самый простой пример строковой функции — это длина строки function — функция, которая возвращает длину строки (без учета каких-либо символов терминатора или какой-либо внутренней структурной информации строки) и не изменяет строку. Эту функцию часто называют длина или же len. Например, длина ("привет, мир") вернет 11. Другой распространенной функцией является конкатенация, где новая строка создается путем добавления двух строк, часто это оператор сложения +.
Немного микропроцессор с архитектуры наборов команд содержат прямую поддержку строковых операций, таких как копирование блока (например, In Intel x86m РЭПНЗ МОВСБ).[11]
Формальная теория
Пусть Σ — конечный набор символов (также называемых символами), называемых алфавит. Не делается никаких предположений о природе символов. А нить (или же слово) над Σ любая конечная последовательность символов из Σ.[12] Например, если Σ = {0, 1}, то 01011 — струна над Σ.
В длина строки s это количество символов в s (длина последовательности) и может быть любой неотрицательное целое число; его часто обозначают как |s|, В пустой строкой — единственная строка длины 0 над Σ и обозначается ε или же λ.[12][13]
Множество всех строк над Σ длины п обозначается Σп. Например, если Σ = {0, 1}, то Σ2 = {00, 01, 10, 11}. Отметим, что Σ0 = {ε} для любого алфавита Σ.
Множество всех струн над Σ любой длины — это Клини закрытие Σ и обозначается Σ*. В терминах Σп,
Например, если Σ = {0, 1}, то Σ* = {ε, 0, 1, 00, 01, 10, 11, 000, 001, 010, 011, …}. Хотя множество Σ* сам по себе счетно бесконечный, каждый элемент Σ* — строка конечной длины.
Набор строк над Σ (т.е. любой подмножество из Σ*) называется формальный язык над Σ. Например, если Σ = {0, 1}, набор строк с четным числом нулей, {ε, 1, 00, 11, 001, 010, 100, 111, 0000, 0011, 0101, 0110, 1001, 1010, 1100, 1111, …}, является формальным языком над Σ.
Конкатенация и подстроки
Конкатенация это важный бинарная операция на Σ*. Для любых двух струн s и т в Σ*, их конкатенация определяется как последовательность символов в s за которым следует последовательность символов в т, и обозначается ул. Например, если Σ = {a, b, …, z}, s = нести, и т = обнимать, тогда ул = медвежьи объятия и ts = hugbear.
Конкатенация строк — это ассоциативный, но некоммутативный операция. Пустая строка ε служит элемент идентичности; для любой строки s, εs = sε = s. Следовательно, множество Σ* и операция конкатенации формирует моноид, то свободный моноид порожденный Σ. Кроме того, функция длины определяет моноидный гомоморфизм из Σ* к неотрицательным целым числам (то есть функция , так что ).
Строка s считается подстрока или же фактор из т если есть (возможно, пустые) строки ты и v такой, что т = usv. В связь «является подстрокой» определяет частичный заказ на Σ*, то наименьший элемент из которых пустая строка.
Префиксы и суффиксы
Строка s считается префикс из т если существует строка ты такой, что т = вс. Если ты непусто, s считается правильный префикс т. Симметрично струна s считается суффикс из т если существует строка ты такой, что т = нас. Если ты непусто, s считается правильный суффикс т. Суффиксы и префиксы — это подстроки т. Оба отношения «является префиксом» и «является суффиксом» являются префиксные заказы.
Разворот
Обратная сторона строки — это строка с такими же символами, но в обратном порядке. Например, если s = abc (где a, b и c — символы алфавита), то обратное s это cba. Строка, противоположная самой себе (например, s = мадам) называется палиндром, который также включает пустую строку и все строки длины 1.
Вращения
Строка s = УФ называется вращением т если т = ву. Например, если Σ = {0, 1} строка 0011001 представляет собой поворот 0100110, где ты = 00110 и v = 01. В качестве другого примера строка abc имеет три разных поворота, а именно. сам abc (с ты= abc, v= ε), bca (с ты= bc, v= a), и cab (с ты= c, v= ab).
Лексикографический порядок
Часто бывает полезно определить заказ на наборе струн. Если в алфавите Σ есть общий заказ (ср. Алфавитный порядок ) можно определить полный порядок на Σ* называется лексикографический порядок. Например, если Σ = {0, 1} и 0 <1, то лексикографический порядок на Σ* включает отношения ε <0 <00 <000 <… <0001 <001 <01 <010 <011 <0110 <01111 <1 <10 <100 <101 <111 <1111 <11111 … Лексикографический порядок общий если алфавитный порядок есть, но не обоснованный для любого нетривиального алфавита, даже если в алфавитном порядке.
Видеть Shortlex для альтернативного порядка строк, сохраняющего обоснованность.
Строковые операции
В формальной теории обычно встречается ряд дополнительных операций со строками. Они приведены в статье о строковые операции.
Топология
(Гипер) куб двоичных строк длины 3
Строки допускают следующую интерпретацию как узлы на графе, где k — количество символов в Σ:
- Строки фиксированной длины длины п можно рассматривать как целые числа в п-размерный гиперкуб со сторонами длины k-1.
- Строки переменной длины (конечной длины) можно рассматривать как узлы на идеально k-арное дерево.
- Бесконечные струны (в противном случае здесь не рассматривается) можно рассматривать как бесконечные пути на k-узел полный график.
Естественная топология на множестве строк фиксированной длины или строк переменной длины — это дискретная топология, но естественная топология на множестве бесконечных строк — это предельная топология, рассматривая набор бесконечных строк как обратный предел наборов конечных строк. Это конструкция, используемая для п-адические числа и некоторые конструкции Кантор набор, и дает ту же топологию.
Изоморфизмы между строковыми представлениями топологий можно найти путем нормализации в соответствии с лексикографически минимальное вращение строки.
Смотрите также
- Бинарно-безопасный — свойство функций, управляющих строкой, обрабатывающих их ввод как поток необработанных данных
- Битовый массив — строка двоичных цифр
- Обработка строки C — обзор обработки строк C
- Обработка строк C ++ — обзор обработки строк C ++
- Сравнение языков программирования (строковые функции)
- Строка подключения — передается драйверу для инициации соединения (например, с базой данных)
- Пустой строкой — его свойства и представление на языках программирования
- Несжимаемая строка — строка, которую нельзя сжать никаким алгоритмом
- Веревка (структура данных) — структура данных для эффективного управления длинными строками
- Строковая метрика — представления о сходстве струн
Рекомендации
- ^ «Введение в Java — MFC 158 G». В архиве из оригинала от 03.03.2016.
Строковые литералы (или константы) называются «анонимными строками».
- ^ Брайант, Рэндал Э.; Дэвид, О’Халларон (2003), Компьютерные системы: взгляд программиста (Изд. 2003 г.), Верхняя Сэдл-Ривер, Нью-Джерси: Pearson Education, стр. 40, ISBN 0-13-034074-X, в архиве из оригинала от 06.08.2007
- ^ Уэрмаут, Джефф. «Листинг сборки ПЗУ Sinclair ZX80». Архивировано 15 августа 2015 года.CS1 maint: неподходящий URL (связь)
- ^ Эллисон, Деннис. «Замечания по дизайну для Tiny BASIC». В архиве из оригинала от 10.04.2017.
- ^ Чарльз Кроули.«Структуры данных для текстовых последовательностей» В архиве 2016-03-04 в Wayback Machine.Раздел»Вступление» В архиве 2016-04-04 в Wayback Machine.
- ^ «strlcpy и strlcat — согласованное, безопасное, строковое копирование и объединение». В архиве 2016-03-13 в Wayback Machine
- ^ «Рассуждения о strcpy, strncpy и strlcpy». В архиве 2016-02-29 в Wayback Machine
- ^ Кейт Томпсон. «Нет, strncpy () не является« более безопасной »strcpy ()». 2012.
- ^ «Пражский клуб струнологии». stringology.org. В архиве из оригинала на 1 июня 2015 г.. Получено 23 мая 2015.
- ^ «Essential Perl». В архиве из оригинала от 21.04.2012.
Самая известная сила Perl — это обработка строк с помощью регулярных выражений.
- ^ «строковые инструкции x86». В архиве из оригинала 27.03.2015.
- ^ а б Барбара Х. Парти; Алиса тер Мёлен; Роберт Э. Уолл (1990). Математические методы в лингвистике. Kluwer.
- ^ Джон Э. Хопкрофт, Джеффри Д. Ульман (1979). Введение в теорию автоматов, языки и вычисления. Эддисон-Уэсли. ISBN 0-201-02988-X. Здесь: раздел 1.1, п.1
Оглавление:
- 1 Как строку в word 10 сделать? — Разбираем подробно
- 2 Пустая подчеркнутая строка с помощью Tab
- 3 Создание пустой строчки с помощью горячих клавиш
- 4 Делаем пустую строку с помощью автозамены
- 5 Рисуем линию, используя фигуры
- 6 Как сделать много подчеркнутых строк
- 6.1 Подчеркивание
- 6.2 Комбинация клавиш
- 6.3 Автозамена
- 6.4 Рисованная линия
- 6.5 Таблица
- 6.6 Несколько рекомендаций напоследок
- 6.7 Помогла ли вам эта статья?
- 6.8 Автоматический перенос шапки
- 6.9 Автоматический перенос не первой строки шапки таблицы
- 6.10 Удаление шапки на каждой странице
- 6.11 Помогла ли вам эта статья?
- 7 Как закрепить шапку на каждом листе
- 8 Делаем вторую строку шапки на каждой странице
- 9 Как убрать повторяющиеся заголовки таблицы
В различных документах, создаваемых в Microsoft Word, может возникнуть необходимость оставить пустое место, чтобы другой пользователь мог ввести свои реквизиты или прочие данные.
Например, Вы делаете анкету. Соответственно вверху должно быть как минимум два поля «Имя» и «Фамилия». Для того чтобы человек, которые отвечает на вопросы, знал, что данные поля следует заполнить, возле них должно быть пустое место, подчеркнутое снизу.
Оставить пустую подчеркнутую строку, может потребоваться и в различных деловых документах, чтобы была возможность дописать необходимые данные в нужных местах на листе.
Если у Вас документ на другую тему, но все равно необходимо сделать подчеркнутую строку в Ворде, тогда в данной статье мы с этим и разберемся. Научимся вставлять ее на всю ширину страницы, или определенной длины, чтобы потом можно было добавить текст, скорее всего, написанный от руки.
Пустая подчеркнутая строка с помощью Tab
Первый способ, чтобы сделать подчеркивание без текста – это использование клавиши «Tab».
Установите курсор в том месте на лисье,где должна быт линия. Перейдите на вкладку «Главная» и возле кнопки с буквой «Ч» нажмите на маленькую стрелочку. Откроется выпадающий список, из которого можно выбрать вид линии. Если ничего не подойдет, нажмите «Другие подчеркивания» и определите вид сами. Кнопка «Цвет подчеркивания» поможет выбрать цвет.

После того, как буква «Ч» подсветится оранжевым цветом, нажмите на клавиатуре клавишу «Tab» (на ней изображены две стрелки, указывающие в разные стороны) необходимое количество раз.

В примере, я сделала пустую строчку в виде волны.

Создание пустой строчки с помощью горячих клавиш
Строка, сделанная первым способом, получается определенной длины, и если вам такое не подходит, например, пряма выходит за поля текста, или за отведенные пределы, тогда воспользуйтесь вторым способом.
С помощью горячих клавиш, можно сделать ее нужной длины, поскольку рисуется она очень маленькими шагами.
Активируйте инструмент «Подчеркивание» и выберите подходящий вид линии. Затем нажмите и удерживайте на клавиатуре «Ctrl+Shift» и нажимайте пробел до тех пор, пока прямая не станет нужной длины.
Первый и второй способы можно объединить. Сначала нарисуйте с помощью «Tab», а потом немного дорисуйте, используя горячие клавиши.

Делаем пустую строку с помощью автозамены
В Ворде сделать прямую также можно, используя автозамену. Правда в данном случае, в документ будет вставлена линия границы. Давайте разберемся, как это сделать.
Установите курсор под той строкой, которую нужно подчеркнуть. Обратите внимание, линия будет не определенной длины, а от одного поля документа до другого. Затем нажмите на клавиатуре три раза клавишу с изображением дефиса.

После этого, кликните «Enter».

На верхнем скриншоте видно, что дефисы я добавила под строкой со словом «Автозамена», и в итоге, подчеркнулась именно строка, которая была над дефисами. То есть, таким образом, создается линия между текстом, но и сделать пустую линию так тоже можно.

Рисуем линию, используя фигуры
Четвертый способ – это добавление фигуры.
Перейдите на вкладку «Вставка» и нажмите «Фигуры». В списке кликните по изображению прямой линии.

Нарисуйте линию в нужном месте на листе. Преимущества такого способа – можно сделать ее любой длины, выбрать подходящий цвет, толщину и вид.
Чтобы нарисовать ровную горизонтальную линию, нажмите и удерживайте при этом клавишу «Shift» на клавиатуре.
Если нужно выбрать другой цвет, тогда просто в готовых стилях кликните по той линии, которая Вам подойдет – нужная вкладка «Средства рисования» – «Формат» откроется сразу после того, как Вы нарисуете линию. Толщину и вид выберите, нажав по кнопке «Контур фигуры» – на ней изображен карандаш с подчеркиванием.
Прочесть подробнее про то, как изменить вид линии, можно в статье: как сделать стрелку в Ворде.

Как сделать много подчеркнутых строк
Если нужно добавить не короткую пустую строку в тексте, или небольшой отрезок для заполнения данными, а много таких строк, например, чтобы человек написал развернутый ответ, тогда сделать это можно, вставив в документ таблицу и немного изменив ее границы.
Перейдите на вкладку «Вставка» и нажмите «Таблица». Выберите из выпадающего списка «Вставить таблицу».

Появится вот такое окошко. В нем нужно заполнить «Число столбцов» – «1», а вот «Число строк» укажите столько, сколько нужно добавить пустых строк на лист. Нажмите «ОК».
Дальше выделите всю добавленную таблицу, кликнув по маленькой кнопочке со стрелочками в разные стороны, которая появляется в левом верхнем углу таблицы. Потом перейдите на вкладку «Работа с таблицами» – «Конструктор» и нажмите на стрелочку возле кнопки «Границы».
В выпадающем списке нужно кликнуть по тем границам, которые нужно убрать: левая и правая.

В итоге, Вы получите много линий для заполнения.

На этом, буду заканчивать. Думаю, у Вас получилось добавить в свой документ Ворд пустую подчеркнутую строку, и теперь или готова анкета, или есть текст, в котором пропущены слова, или документ, в который необходимо дописать данные.
Поделитесь статьёй с друзьями:

Довольно часто во время работы с документом MS Word возникает необходимость создать строчки (линиатуры). Наличие строк может потребоваться в официальных документах или же, например, в пригласительных, открытках. Впоследствии в эти строки будет добавлен текст, вероятнее всего, он будет вписываться туда ручкой, а не печататься.
Урок: Как в Ворде поставить подпись
В этой статье мы рассмотрим несколько простых и удобных в работе способов, с помощью которых можно сделать строку или строки в Word.
ВАЖНО: В большинстве описанных ниже методов длина линии будет зависеть от значения полей, установленных в Ворде по умолчанию или ранее измененных пользователем. Чтобы изменить ширину полей, а вместе с ними обозначить максимально возможную длину строки для подчеркивания, воспользуйтесь нашей инструкцией.
Урок: Настройка и изменение полей в MS Word



Подчеркивание
Во вкладке “Главная” в группе “Шрифт” есть инструмент для подчеркивания текста — кнопка “Подчеркнутый”. Вместо нее также можно использовать комбинацию клавиш “CTRL+U”.

Урок: Как в Word подчеркнуть текст
Используя этот инструмент, можно подчеркнуть не только текст, но и пустое место, в том числе и целую строку. Все, что требуется, предварительно обозначить длину и количество этих самых строк пробелами или знаками табуляции.
Урок: Табуляция в Ворде
1. Установите курсор в том месте документа, где должна начинаться подчеркнутая строка.

2. Нажмите “TAB” нужное количество раз, чтобы обозначить длину строки для подчеркивания.

3. Повторите аналогичное действие для остальных строк в документе, в которых тоже нужно сделать подчеркивание. Также вы можете скопировать пустую строку, выделив ее мышкой и нажав “CTRL+C”, а затем вставить в начале следующей строки, нажав “CTRL+V” .
Урок: Горячие клавиши в Ворде

4. Выделите пустую строку или строки и нажмите кнопку “Подчеркнутый” на панели быстрого доступа (вкладка “Главная”), или используйте для этого клавиши “CTRL+U”.

5. Пустые строки будут подчеркнуты, теперь вы можете документ и написать на нем от руки все, что требуется.

Примечание: Вы всегда можете изменить цвет, стиль и толщину линии подчеркивания. Для этого просто нажмите на небольшую стрелку, расположенную справа от кнопки “Подчеркнутый”, и выберите необходимые параметры.
Если это необходимо, вы также можете изменить цвет страницы, на которой вы создали строчки. Воспользуйтесь для этого нашей инструкцией:
Урок: Как в Word изменить фон страницы
Комбинация клавиш
Еще один удобный способ, с помощью которого можно сделать в Ворде строку для заполнения — использование специальной комбинации клавиш. Преимущество данного метода перед предыдущим заключается в том, что с его помощью можно создать подчеркнутую строку любой длины.
1. Установите курсор в том месте, где должна начинаться строка.

2. Нажмите кнопку “Подчеркнутый” (или используйте “CTRL+U”), чтобы активировать режим подчеркивания.

3. Нажмите вместе клавиши “CTRL+SHIFT+ПРОБЕЛ” и держите до тех пор, пока не проведете строку необходимой длины или необходимое количество строк.
4. Отпустите клавиши, отключите режим подчеркивания.

5. Необходимое количество строк для заполнения указанной вами длины будет добавлено в документ.

Примечание: Важно понимать, что расстояние между строками, добавленными с помощью непрерывного нажатия комбинации клавиш “CTRL+SHIFT+ПРОБЕЛ” и строками, добавленными методом копирования/вставки (а также нажатия «ENTER» в конце каждой строки) будет отличаться. Во втором случае оно будет больше. Этот параметр зависит от установленных значений интервалов, это же происходит с текстом во время набора, когда интервал между строками и абзацами отличается.
Автозамена
В случае, когда необходимо поставить всего одну-две строки, можно воспользоваться стандартными параметрами автозамены. Так будет быстрее, да и просто удобнее. Однако, у этого метода есть парочка недостатков: во-первых, непосредственно над такой строкой нельзя напечатать текст и, во-вторых, если таких строк будет три и более, расстояние между ними будет не одинаковым.
Урок: Автозамена в Ворде
Следовательно, если вам нужна всего одна или две подчеркнутых строки, а заполнять вы их будете не печатным текстом, а с помощью ручки на уже распечатанном листе, то этот метод вас вполне устроит.
1. Кликните в том месте документа, где должно быть начало строки.
2. Нажмите клавишу “SHIFT” и, не отпуская ее, трижды нажмите “-”, расположенную в верхнем цифровом блоке на клавиатуре.
Урок: Как в Word сделать длинное тире
3. Нажмите “ENTER”, введенные вами дефисы будут преобразованы в нижнее подчеркивание длиною на всю строку.
Если это необходимо, повторите действие для еще одной строки.
Рисованная линия
В Ворде имеются инструменты для рисования. В большом наборе всевозможных фигур можно также найти и горизонтальную линию, которая послужит нам обозначением строки для заполнения.
1. Кликните в том месте, где должно быть начало строки.
2. Перейдите во вкладку “Вставка” и нажмите на кнопку “Фигуры”, расположенную в группе “Иллюстрации”.
3. Выберите там обычную прямую линию и нарисуйте ее.
4. В появившейся после добавления линии вкладке “Формат” вы можете изменить ее стиль, цвет, толщину и другие параметры.
Если это необходимо, повторите вышеописанные действия для того, чтобы добавить еще строки в документ. Более подробно о работе с фигурами вы можете прочесть в нашей статье.
Урок: Как в Word нарисовать линию
Таблица
Если вам необходимо добавить большое количество строк, наиболее эффективное решение в таком случае — это создание таблицы размером в один столбец, конечно же, с необходимым вам количеством строк.
1. Кликните там, где должна начинаться первая строка, и перейдите во вкладку “Вставка”.
2. Нажмите на кнопку “Таблицы”.
3. В выпадающем меню выберите раздел “Вставка таблицы”.
4. В открывшемся диалоговом окне укажите необходимое количество строк и всего один столбец. Если это необходимо, выберите подходящий параметр для функции “Автоподбор ширины столбцов”.
5. Нажмите “ОК”, в документе появится таблица. Потянув за “плюсик”, расположенный в левом верхнем углу, вы можете ее переместить в любое место страницы. Потянув за маркер в правом нижнем углу, вы можете изменить ее размер.
6. Кликните по “плюсику” в левом верхнем углу, чтобы выделить всю таблицу.
7. Во вкладке “Главная” в группе “Абзац” нажмите на стрелку, расположенную справа от кнопки “Границы”.
8. Поочередно выберите пункты “Левая граница” и “Правая граница”, чтобы скрыть их.
9. Теперь в вашем документе будет отображаться только необходимое количество строк, указанного вами размера.
10. Если это необходимо, измените стиль таблицы, а наша инструкция вам в этом поможет.
Урок: Как в Ворде сделать таблицу
Несколько рекомендаций напоследок
Создав необходимое количество строк в документе с помощью одного из вышеописанных методов, не забудьте сохранить файл. Также, во избежание неприятных последствий в работе с документами, рекомендуем настроить функцию автосохранения.
Урок: Автосохранение в Word
Возможно, вам потребуется изменить интервалы между строками, сделав их больше или меньше. Наша статья на данную тему вам в этом поможет.
Урок: Настройка и изменение интервалов в Ворде
Если строки, которые вы создавали в документе, необходимы для того, чтобы в дальнейшем их заполняли вручную, с помощью обычной ручки, документ вам поможет наша инструкция.
Урок: Как в Word документ
Если у вас возникнет необходимость удалить линии, обозначающие строки, наша статья поможет вам это сделать.
Урок: Как в Ворде удалить горизонтальную линию
Вот, собственно, и все, теперь вы знаете обо всех возможных методах, с помощью которых можно сделать строчки в MS Word. Выберите тот, который вам наиболее подходит и используйте его по мере необходимости. Успехов в работе и обучении.
Мы рады, что смогли помочь Вам в решении проблемы.
Задайте свой вопрос в комментариях, подробно расписав суть проблемы. Наши специалисты постараются ответить максимально быстро.
Помогла ли вам эта статья?
Да Нет
Если в Microsoft Word вы создали таблицу больших размеров, занимающую более одной страницы, для удобства работы с ней может понадобиться сделать отображение шапки на каждой странице документа. Для этого потребуется настроить автоматический перенос заголовка (той самой шапки) на последующие страницы.
Урок: Как в Ворде сделать продолжение таблицы
Итак, в нашем документе есть большая таблица, которая уже занимает или только будет занимать более одной страницы. Наша с вами задача — настроить эту самую таблицу таким образом, чтобы ее шапка автоматически появлялась в верхней строке таблицы при переходе на нее. О том, как создать таблицу, вы можете прочесть в нашей статье.
Урок: Как в Word сделать таблицу
Примечание: Для переноса шапки таблицы, состоящей из двух и более строк, обязательно необходимо выделять и первую строку.
Автоматический перенос шапки
1. Установите курсор в первой строке заголовка (первая ячейка) и выделите эту строку или строки, из которых и состоит шапка.
2. Перейдите во вкладку «Макет», которая находится в основном разделе «Работа с таблицами».
3. В разделе инструментов «Данные» выберите параметр «Повторить строки заголовков».
Готово! С добавлением строк в таблице, которые будут переносить ее на следующую страницу, сначала будет автоматически добавлена шапка, а за ней уже новые строки.
Урок: Добавление строки в таблицу в Ворде
Автоматический перенос не первой строки шапки таблицы
В некоторых случаях шапка таблицы может состоять из нескольких строк, но автоматический перенос требуется сделать только для одной из них. Это, к примеру, может быть строка с номерами столбцов, расположенная под строкой или строками с основными данными.
Урок: Как сделать автоматическую нумерацию строк в таблице в Word
В данном случае сначала нужно разделить таблицу, сделав необходимую нам строку шапкой, которая и будет переноситься на все последующие страницы документа. Только после этого для данной строки (уже шапки) можно будет активировать параметр «Повторить строки заголовков».
1. Установите курсор в последней строке таблицы, расположенной на первой странице документа.
2. Во вкладке «Макет» («Работа с таблицами») и в группе «Объединение» выберите параметр «Разделить таблицу».
Урок: Как в Ворд разделить таблицу
3. Скопируйте ту строку из «большой», основной шапки таблицы, которая будет выступать шапкой на всех последующих страницах (в нашем примере это строка с наименованиями столбцов).
4. Вставьте скопированную строку в первую строку таблицы на следующей странице.
5. Выделите новую шапку с помощью мышки.
6. Во вкладке «Макет» нажмите на кнопку «Повторить строки заголовков», расположенную в группе «Данные».
Готово! Теперь основная шапка таблицы, состоящая из нескольких строк, будет отображаться только на первой странице, а добавленная вами строка будет автоматически переносится на все последующие страницы документа, начиная со второй.
Удаление шапки на каждой странице
Если вам необходимо удалить автоматическую шапку таблицы на всех страницах документа, кроме первой, выполните следующее:
1. Выделите все строки в шапке таблицы на первой странице документа и перейдите во вкладку «Макет».
2. Нажмите на кнопку «Повторить строки заголовков» (группа «Данные»).
3. После этого шапка будет отображаться только на первой странице документа.
Урок: Как преобразовать таблицу в текст в Word
На этом можно закончить, из этой статьи вы узнали, как сделать шапку таблицы на каждой странице документа Ворд.
Мы рады, что смогли помочь Вам в решении проблемы.
Задайте свой вопрос в комментариях, подробно расписав суть проблемы. Наши специалисты постараются ответить максимально быстро.
Помогла ли вам эта статья?
Да Нет
В некоторых документах Microsoft Word приходится работать с таблицами. Информация в таком виде лучше воспринимается и запоминается. Если она небольшая и занимает один лист, тогда сделать таблицу в Ворде несложно. Но что делать, если она занимает несколько листов?
Просматривая материал, оформленный таким образом, неудобно постоянно возвращаться в начало, чтобы посмотреть, как называются столбцы с данными. Вот в данной статье мы и рассмотрим, как сделать повторяющуюся шапку таблицы в Ворд. То есть строка с заголовками столбцов будет отображаться на каждой странице.
Как закрепить шапку на каждом листе
Давайте сделаем перенос названий для столбцов на таком примере.
Чтобы повторить их на каждом новом листе, выделите соответствующую строку. Затем перейдите на вкладку «Работа с таблицами» – «Макет» и в группе «Данные» нажмите на кнопку «Повторить строки заголовков».
После этого, повторение названий столбцов будет на каждом новом листе.
Делаем вторую строку шапки на каждой странице
Если у Вас названия столбцов указаны в нескольких строках, например, основное название всех столбцов и отдельно название каждого, или название и их нумерация, тогда может потребоваться перенести на последующие листы не первую строку, а вторую или третью.
В примере я покажу, как сделать перенос второго ряда. Но если Вам нужно продублировать заголовки третьего или любого другого, тогда все делается точно так же.
Поставьте курсор в последнюю правую ячейку на первой странице и нажмите «Ctrl+Enter», чтобы поделить таблицу на две части.
На вкладке «Главная» можете нажать на кнопку «Отобразить все знаки», и тогда в конце первого листа Вы увидите надпись «Разрыв страницы».
Если у Вас последняя ячейка на первой странице была большая, строк на 8-10, тогда после вставки разрыва, на первой странице останется много свободного места. Чтобы этого не произошло, нужно добавить еще одну строку. Как это сделать, я писала в статье, как написать продолжение таблицы в Ворде. Перейдите по ссылке, и прочтите 2 способ.
Дальше скопируйте нужное из шапки, что будет дублироваться – выделите ее и нажмите «Ctrl+C».
Перейдите ко второй странице и поставьте курсор в верхнюю левую ячейку. Затем нужно вставить то, что мы копировали ранее – нажмите «Ctrl+V».
Заголовок будет добавлен на втором листе.
Теперь нужно его продублировать. Выделите добавленную строку, откройте вкладку «Макет» и в группе «Данные» кликните «Повторить строки заголовков».
Вот так можно сделать перенос заголовков, но не всех, а только тех, которые нужны.
Обратите внимание, что если хотите изменить шапку, тогда делать это нужно с той, которую Вы дублировали. Продублированные, то есть те, которые повторяются, изменить не получится.
Как убрать повторяющиеся заголовки таблицы
Если у Вас в документе есть таблица с перенесенными на вторую страницу названиями столбцов, и их нужно убрать, чтобы они отображались один раз в начале, тогда сделайте следующее.
Выделите первую ту шапку, которая дублируется, а не продублированную (кстати, их выделить и не получится). Затем откройте вкладку «Работа с таблицами» – «Макет» и в группе «Данные» нажмите на кнопку «Повторить строки заголовков».
После этого, названия на всех остальных страницах будут убраны.
На этом все. Мы с Вами рассмотрели, как дублировать шапку для столбцов таблицы в Ворде. Если остались вопросы, пишите их в комментариях.
Поделитесь статьёй с друзьями:
Did you find apk for android? You can find new Free Android Games and apps.
Текстовый редактор – самостоятельная компьютерная программа (приложение) или часть программного комплекса, которая предназначена для создания и редактирования текстовых данных.
Текстовые редакторы предназначены в основном лишь для ввода и редактирования текста, но не имеют средств для оформления внешнего вида текста (форматирования). Таким образом, применяются в тех случаях, когда оформление текста является лишним или не нужным (например, при подготовке документов для отправки электронной почтой).
Созданный текстовый файл в одном редакторе можно редактировать с помощью другого редактора, т.к. текстовый файл при сохранении содержит только коды введенных символов.
Кроме создания и просмотра текста текстовые редакторы позволяют выполнять следующие операции редактирования текста – перемещение, копирование, вставка текста, поиск по тексту и замена, сортировка строк, просмотр кодов символов и конвертация кодировок, печать документа и т.п.
Блокнот — самый простой текстовый редактор.

Рис. (1). Окно Блокнота
Данная программа служит в основном для просмотра и редактирования текстовых документов, которые имеют разрешение *.txt.
Популярные текстовые редакторы: Poet, TextPad, RJ TextEd, AkelPad, jEdit, DPAD, Notepad, Notepad++, Notepad2, EditPlus, EmEditor, UltraEdit.
Текстовый процессор — компьютерная программа, предназначенная для создания и редактирования текстовых документов, компоновки макета текста и предварительного просмотра документов в том виде, в котором они будут напечатаны.
Текстовые процессоры умеют форматировать текст, вставлять в документ графику и другие объекты, не относящиеся к классическому понятию «текст».
Современные текстовые процессоры позволяют выполнять форматирование шрифтов и абзацев, проверку орфографии, вставку таблиц и графических объектов, а также включают некоторые возможности настольных издательских систем.
Текстовые процессоры используют в случаях, когда кроме содержания текста имеет значение и его внешний вид (подготовка официальных документов). Документ, созданный с помощью текстового процессора, содержит кроме текста еще и информацию о его форматировании, которая сохраняется в кодах, не видимых пользователю.
Популярные текстовые процессоры:
1) Microsoft Word — мощный текстовый процессор, предназначенный для создания, просмотра и редактирования текстовых документов.

Рис. 2. Окно текстового процессора Microsoft Word
2) OpenOffice.org Writer — текстовый процессор, который входит в состав пакета свободного программного обеспечения OpenOffice.org. Writer во многом аналогичен Microsoft Word, но имеет некоторые возможности, которые отсутствуют в Word (например, поддержка стилей страниц).

Рис. 3. Окно текстового процессора OpenOffice.org Writer
Интерфейс текстовых процессоров имеют похожую структуру. В качестве примера посмотрим интерфейс текстового процессора Microsoft Word (рис. 2):
- строка заголовка: строка под верхней границей окна, содержащая имя документа, имя программы и кнопки управления;
- строка меню: располагается под строкой заголовка, содержащая имена групп команд, объединенных по функциональному признаку;
- панель инструментов: располагается под строкой меню и представляет собой набор кнопок, которые обеспечивают быстрый доступ к наиболее важным и часто используемым пунктам меню окна;
- линейка: располагается ниже панели инструментов, которая определяет границы документа;
- рабочая область: внутренняя часть окна, предназначенная для создания документа и работы с ним;
- строка состояния: строка, в которой выводится справочная информация.