
Хотите готовиться со мной к ЕГЭ?
Пишите: ydkras@mail.ru
Немного обо мне.
Задача 9 в демонстрационном варианте ЕГЭ по информатике на сайте ФИПИ — неожиданно сложная и мало похожая на задачи прошлых лет.
Вот её текст:
В файле электронной таблицы в каждой строке содержатся шесть натуральных чисел. Определите количество строк таблицы, для которых выполнены оба условия:
– в строке только одно число повторяется дважды (ровно 2 раза), остальные числа не повторяются;
– среднее арифметическое неповторяющихся чисел строки не больше суммы повторяющихся чисел.
Рассмотрим два способа решения этой задачи: непостредственно в Excel и с помощью программы на Питоне.
Решение в Excel
Ключевая идея решения — разделить числа в строке таблицы не две группы: повторяющиеся значения и значения, которые встречаются в строке лишь один раз.
Вот несколько строк из таблицы, предлагаемой в качестве исходных данных.
| A | B | C | D | E | F | |
| 1 | 37 | 83 | 24 | 19 | 37 | 41 |
| 2 | 59 | 77 | 43 | 43 | 118 | 38 |
| 3 | 6 | 65 | 40 | 22 | 6 | 130 |
| 4 | 63 | 77 | 76 | 8 | 63 | 51 |
| 5 | 74 | 47 | 97 | 26 | 222 | 23 |
| 6 | 48 | 24 | 17 | 7 | 24 | 36 |
| 7 | 27 | 39 | 77 | 35 | 27 | 13 |
| 8 | 77 | 67 | 74 | 3 | 115 | 134 |
| 9 | 19 | 41 | 45 | 45 | 19 | 41 |
| 10 | 74 | 66 | 64 | 33 | 74 | 33 |
Разумеется, это лишь незначительная часть исходной таблицы (в ней 6400 строк), но для объяснения решения этих данных достаточно.
Сначала запишем в ячейку H1 следующую формулу:
=ЕСЛИ(СЧЁТЕСЛИ($A1:$F1;A1)>1;A1;»»)
Функция СЧЁТЕСЛИ подсчитывает, сколько раз в ячейках A1:F1 встречается число из ячейки A1. Если более одного раза — то в ячейку H1 будет записано число из A1, в противном случае ячейка H1 будет пустой.
Теперь скопируем эту формулу в ячейки I1:M1, а потом группу ячеек H1:M1 скопируем в строки ниже первой до конца таблицы. Получим следующую таблицу:
| A | B | C | D | E | F | G | H | I | J | K | L | M | |
| 1 | 37 | 83 | 24 | 19 | 37 | 41 | 37 | 37 | |||||
| 2 | 59 | 77 | 43 | 43 | 118 | 38 | 43 | 43 | |||||
| 3 | 6 | 65 | 40 | 22 | 6 | 130 | 6 | 6 | |||||
| 4 | 63 | 77 | 76 | 8 | 63 | 51 | 63 | 63 | |||||
| 5 | 74 | 47 | 97 | 26 | 222 | 23 | |||||||
| 6 | 48 | 24 | 17 | 7 | 24 | 36 | 24 | 24 | |||||
| 7 | 27 | 39 | 77 | 35 | 27 | 13 | 27 | 27 | |||||
| 8 | 77 | 67 | 74 | 3 | 115 | 134 | |||||||
| 9 | 19 | 41 | 45 | 45 | 19 | 41 | 19 | 41 | 45 | 45 | 19 | 41 | |
| 10 | 74 | 66 | 64 | 33 | 74 | 33 | 74 | 33 | 74 | 33 |
Как видим, числа, которые повторяются, скопировались, а ячейки, соответствующие уникальным значениям, остались пустыми, что и требовалось.
Теперь запишем в ячейку O1 такую формулу:
=ЕСЛИ(H1=»»;A1;»»)
Если ячейка H1 пустая, то в ячейку O1 будет скопировано число из ячейки A1, в противном случай ячейка O1 будет пустой.
Копируем эту формулу в ячейки P1:T1, а потом группу ячеек O1:T1 копируем в строки ниже.
Теперь наша таблица выглядит так:
| A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | |
| 1 | 37 | 83 | 24 | 19 | 37 | 41 | 37 | 37 | 83 | 24 | 19 | 41 | ||||||||
| 2 | 59 | 77 | 43 | 43 | 118 | 38 | 43 | 43 | 59 | 77 | 118 | 38 | ||||||||
| 3 | 6 | 65 | 40 | 22 | 6 | 130 | 6 | 6 | 65 | 40 | 22 | 130 | ||||||||
| 4 | 63 | 77 | 76 | 8 | 63 | 51 | 63 | 63 | 77 | 76 | 8 | 51 | ||||||||
| 5 | 74 | 47 | 97 | 26 | 222 | 23 | 74 | 47 | 97 | 26 | 222 | 23 | ||||||||
| 6 | 48 | 24 | 17 | 7 | 24 | 36 | 24 | 24 | 48 | 17 | 7 | 36 | ||||||||
| 7 | 27 | 39 | 77 | 35 | 27 | 13 | 27 | 27 | 39 | 77 | 35 | 13 | ||||||||
| 8 | 77 | 67 | 74 | 3 | 115 | 134 | 77 | 67 | 74 | 3 | 115 | 134 | ||||||||
| 9 | 19 | 41 | 45 | 45 | 19 | 41 | 19 | 41 | 45 | 45 | 19 | 41 | ||||||||
| 10 | 74 | 66 | 64 | 33 | 74 | 33 | 74 | 33 | 74 | 33 | 66 | 64 |
Строка удовлетворяет условию задачи, если 1) пустых клеток в ячейках H1:M1 ровно 4 и 2) среднее значение в ячейках O1:T1 меньше или равно сумме ячеек H1:M1.
Поместим в ячейку V1 следующую формулу:
=ЕСЛИ(И(СЧЁТЕСЛИ(H1:M1;»»)=4;СРЗНАЧ(O1:T1)<=СУММ(H1:M1));1;»»)
Эта формула должна записывать в ячейку V1 единицу, если строка отвечает условию, а в противном случае оставлять её пустой.
Затем скопируем её в нижние ячейки в столбце V, чтобы после этого подсчитать сумму единиц в столбце V и получить ответ нашей задачи.
Вот что у нас получилось:
| A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | |
| 1 | 37 | 83 | 24 | 19 | 37 | 41 | 37 | 37 | 83 | 24 | 19 | 41 | 1 | |||||||||
| 2 | 59 | 77 | 43 | 43 | 118 | 38 | 43 | 43 | 59 | 77 | 118 | 38 | 1 | |||||||||
| 3 | 6 | 65 | 40 | 22 | 6 | 130 | 6 | 6 | 65 | 40 | 22 | 130 | ||||||||||
| 4 | 63 | 77 | 76 | 8 | 63 | 51 | 63 | 63 | 77 | 76 | 8 | 51 | 1 | |||||||||
| 5 | 74 | 47 | 97 | 26 | 222 | 23 | 74 | 47 | 97 | 26 | 222 | 23 | ||||||||||
| 6 | 48 | 24 | 17 | 7 | 24 | 36 | 24 | 24 | 48 | 17 | 7 | 36 | 1 | |||||||||
| 7 | 27 | 39 | 77 | 35 | 27 | 13 | 27 | 27 | 39 | 77 | 35 | 13 | 1 | |||||||||
| 8 | 77 | 67 | 74 | 3 | 115 | 134 | 77 | 67 | 74 | 3 | 115 | 134 | ||||||||||
| 9 | 19 | 41 | 45 | 45 | 19 | 41 | 19 | 41 | 45 | 45 | 19 | 41 | #ДЕЛ/0! | |||||||||
| 10 | 74 | 66 | 64 | 33 | 74 | 33 | 74 | 33 | 74 | 33 | 66 | 64 |
К сожалению, в строке 9 мы видим сообщение «#ДЕЛ/0!». Это случилось потому, что в данной строке нет уникальных значений, из-за чего все ячейки от O до T в данной строке пустые и при попытке вычислить среднее значение этих ячеек действительно происходит деление на 0.
Из-за этого просуммировать столбец V нам не удастся, поэтому нашу формулу для этого столбца придется изменить так, что среднее значение будет вычисляться только тогда, когда это не приведет к неприятностям.
Вот новая формула, которую надо записать в ячейку V1, а потом скопировать во все строки ниже:
=ЕСЛИ(СЧЁТЕСЛИ(H2:M2;»»)=4;ЕСЛИ(СРЗНАЧ(O2:T2)<=СУММ(H2:M2);1;»»);»»)
В этой формуле среднее значение вычисляется только тогда, когда не все ячейки от O до T пустые, поэтому деления на ноль не возникает.
Возможен и другой вариант избавления от деления на ноль — использование функции ЕСЛИОШИБКА. Первым параметром в ней указываем наше выражение, а вторым — значение, которое надо выводить, если в первом возникают ошибки при вычислении:
=ЕСЛИОШИБКА(ЕСЛИ(И(СЧЁТЕСЛИ(H2:M2;»»)=4;СРЗНАЧ(O2:T2)<=СУММ(H2:M2));1;»»);»»)
Заменяем формулу в ячейках столбца V, записываем в ячейку X1 формулу, суммирующую числа в столбце V, и в ней появляется ответ:
| A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | |
| 1 | 37 | 83 | 24 | 19 | 37 | 41 | 37 | 37 | 83 | 24 | 19 | 41 | 1 | 5 | ||||||||||
| 2 | 59 | 77 | 43 | 43 | 118 | 38 | 43 | 43 | 59 | 77 | 118 | 38 | 1 | |||||||||||
| 3 | 6 | 65 | 40 | 22 | 6 | 130 | 6 | 6 | 65 | 40 | 22 | 130 | ||||||||||||
| 4 | 63 | 77 | 76 | 8 | 63 | 51 | 63 | 63 | 77 | 76 | 8 | 51 | 1 | |||||||||||
| 5 | 74 | 47 | 97 | 26 | 222 | 23 | 74 | 47 | 97 | 26 | 222 | 23 | ||||||||||||
| 6 | 48 | 24 | 17 | 7 | 24 | 36 | 24 | 24 | 48 | 17 | 7 | 36 | 1 | |||||||||||
| 7 | 27 | 39 | 77 | 35 | 27 | 13 | 27 | 27 | 39 | 77 | 35 | 13 | 1 | |||||||||||
| 8 | 77 | 67 | 74 | 3 | 115 | 134 | 77 | 67 | 74 | 3 | 115 | 134 | ||||||||||||
| 9 | 19 | 41 | 45 | 45 | 19 | 41 | 19 | 41 | 45 | 45 | 19 | 41 | ||||||||||||
| 10 | 74 | 66 | 64 | 33 | 74 | 33 | 74 | 33 | 74 | 33 | 66 | 64 |
Впрочем, можно было получить ответ и с первой формулой, в которой возникало деление на ноль. Для этого нужно было не суммировать числа в столбце V, а подсчитать в нем количество единиц с помощью примерно такой формулы:
=СЧЁТЕСЛИ(V:V;1)
Решаем задачу на Питоне
Если Питон для вас проще, чем функции Excel, то могу обрадовать вас — данную задачу вполне можно решить с помощью коротенькой программы.
(Замечу, что подобный подход вполне годится и для многих других задач обработки числовой информации в Excel, предлагавшихся на ЕГЭ.)
Прежде всего необходимо сохранить nаблицу Excel в текстовом файле (формат csv). В этом формате данные из ячеек таблицы разделяются символом-разделителем. По умолчанию это точка с запятой, но при сохранении можно указать и другой символ (например, пробел). Для наших целей вполне подойдёт и точка с запятой.
Сохраненный в формате csv файл выглядит так:
37;83;24;19;37;41
59;77;43;43;118;38
6;65;40;22;6;130
63;77;76;8;63;51
74;47;97;26;222;23
48;24;17;7;24;36
27;39;77;35;27;13
77;67;74;3;115;134
19;41;45;45;19;41
74;66;64;33;74;33
Когда файл сохранен на диске, можно писать программу для его обработки.
Алгоритм достаточно прост. Открываем сохраненный файл. Переменной k присваиваем значение 0: это счетчик строк, удовлетворяющих условию. Затем в цикле читаем строки из файла и каждую строку преобразуем в массив a из шести целых чисел. Создаем дла пустых массива povt и unik, затем в цикле просматриваем массив a и те элементы, которые встречаются в нём один раз, добавляем в массив unik, а те, которые встречаются более одного — в массив povt. Если массив povt содержит ровно два элемента и среднее арифметическое чисел в массиве unik (т.е. сумма чисел, деленная на их количество) не больше суммы чисел в массиве povt, увеличиваем счетчик k на единицу. Когда цикл закончится, печатаем переменную k.
Вот полный текст программы:
f=open(‘9.csv’)
k=0
for s in f:
a=list(map(int,s.split(‘;’)))
povt=[]
unik=[]
for n in a:
(unik if a.count(n)==1 else povt).append(n)
if len(povt)==2 and sum(unik)/len(unik) <= sum(povt):
k += 1
print(k)
В строке
(unik if a.count(n)==1 else povt).append(n)
использовано условное выражение. Эта строка эквивалентна следующему фрагменту:
if a.count(n)==1:
unik.append(n)
else:
povt.append(n)
Внимательный читатель может спросить: а почему в этой программе не возникает деления на ноль, если в массиве a нет уникальных чисел, т.е. если массив unik пустой и len(unik)=0? Дело в том, что в Питоне (как и в C) логические выражения вычисляются слева направо и если на каком-то этапе значение логического выражения уже определено, то дальнейшие вычисления не производятся. В данном случае если len(povt) не равно двум, то выражение заведомо ложно и второе условие, т.е. sum(unik)/len(unik) <= sum(povt), не проверяется.
Немного о сортировке и медиане
После публикации новой задачи 9 на сайте ФИПИ в интернете появилось множество задач подобного типа. Вот, например, одна из задач с сайта Полякова:
(№ 5525) (А. Рогов) В файле электронной таблицы 9-170.xls в каждой строке содержатся шесть натуральных чисел. Определите количество строк таблицы, для которых выполнены оба условия:
– в строке нет чисел, которые повторяются;
– среднее арифметическое чисел строки не меньше медианы чисел строки.
Примечание. Медиана — это число, которое находится в середине отсортированного набора чисел. Для четного количества чисел за медиану принимают полусумму двух стоящих в центре чисел. Так, для набора 1, 4, 6, 9 медиана равна 5.
Вычисление медианы предполагает, что мы отсортировали наши шесть чисел и взяли полусумму третьего и четвертого (после сортировки) чисел. Естественно, возникает вопрос: а как отсортировать числа по возрастанию — независимо в каждой строке?
Оказывается, это достаточно просто сделать с помощью функции НАИМЕНЬШИЙ. У этой функции два параметра. Первый — это диапазон ячеек, из которого берутся числовые значения. Второй — натуральное число, если это 1 — функция возвращает наименьшее значение, 2 — второе по малости и т.д.
Имеется также функция НАИБОЛЬШИЙ, которая аналогична функции НАИМЕНЬШИЙ, но возвращает значения не по возрастанию, а по убыванию.
С помощью этих функция задача сортировки чисел в строке решается очень просто.
Допустим, у нас есть следующая таблица:
| A | B | C | D | E | F | |
| 1 | 37 | 83 | 24 | 19 | 37 | 41 |
| 2 | 59 | 77 | 43 | 43 | 118 | 38 |
| 3 | 6 | 65 | 40 | 22 | 6 | 130 |
| 4 | 63 | 77 | 76 | 8 | 63 | 51 |
| 5 | 74 | 47 | 97 | 26 | 222 | 23 |
| 6 | 48 | 24 | 17 | 7 | 24 | 36 |
| 7 | 27 | 39 | 77 | 35 | 27 | 13 |
| 8 | 77 | 67 | 74 | 3 | 115 | 134 |
| 9 | 19 | 41 | 45 | 45 | 19 | 41 |
| 10 | 74 | 66 | 64 | 33 | 74 | 33 |
Вписываем в ячейку H1 формулу =НАИМЕНЬШИЙ(A1:F1;1), в ячейку I1 — формулу =НАИМЕНЬШИЙ(A1:F1;2), …, в ячейку M1 — формулу =НАИМЕНЬШИЙ(A1:F1;6). Теперь в ячейках H1:M1 находятся числа из ячеек A1:F1, отсортированные по возрастанию.
Копируем формулы из ячеек H1:M1 в расположенные ниже строки и получаем желаемый результат:
| A | B | C | D | E | F | G | H | I | J | K | L | M | |
| 1 | 37 | 83 | 24 | 19 | 37 | 41 | 19 | 24 | 37 | 37 | 41 | 83 | |
| 2 | 59 | 77 | 43 | 43 | 118 | 38 | 38 | 43 | 43 | 59 | 77 | 118 | |
| 3 | 6 | 65 | 40 | 22 | 6 | 130 | 6 | 6 | 22 | 40 | 65 | 130 | |
| 4 | 63 | 77 | 76 | 8 | 63 | 51 | 8 | 51 | 63 | 63 | 76 | 77 | |
| 5 | 74 | 47 | 97 | 26 | 222 | 23 | 23 | 26 | 47 | 74 | 97 | 222 | |
| 6 | 48 | 24 | 17 | 7 | 24 | 36 | 7 | 17 | 24 | 24 | 36 | 48 | |
| 7 | 27 | 39 | 77 | 35 | 27 | 13 | 13 | 27 | 27 | 35 | 39 | 77 | |
| 8 | 77 | 67 | 74 | 3 | 115 | 134 | 3 | 67 | 74 | 77 | 115 | 134 | |
| 9 | 19 | 41 | 45 | 45 | 19 | 41 | 19 | 19 | 41 | 41 | 45 | 45 | |
| 10 | 74 | 66 | 64 | 33 | 74 | 33 | 33 | 33 | 64 | 66 | 74 | 74 |
Если чисел в строке много, то выписывать формулу с функцией НАИМЕНЬШИЙ много раз затруднительно. Можно избежать этого следующим образом. Вставим сверху таблицы пустую строку (поместим курсор на заголовок строки 1, нажмем правую кнопку и выберем «Вставить строки выше»). В ячейки H1:M1 впишем последовательные числа 1, 2, …, 6. Теперь впишем в ячейку H2 формулу =НАИМЕНЬШИЙ($A2:$F2;H$1) и скопируем её сначала в ячейки I2:M2, а потом в строки ниже.
| A | B | C | D | E | F | G | H | I | J | K | L | M | |
| 1 | 1 | 2 | 3 | 4 | 5 | 6 | |||||||
| 2 | 37 | 83 | 24 | 19 | 37 | 41 | 19 | 24 | 37 | 37 | 41 | 83 | |
| 3 | 59 | 77 | 43 | 43 | 118 | 38 | 38 | 43 | 43 | 59 | 77 | 118 | |
| 4 | 6 | 65 | 40 | 22 | 6 | 130 | 6 | 6 | 22 | 40 | 65 | 130 | |
| 5 | 63 | 77 | 76 | 8 | 63 | 51 | 8 | 51 | 63 | 63 | 76 | 77 | |
| 6 | 74 | 47 | 97 | 26 | 222 | 23 | 23 | 26 | 47 | 74 | 97 | 222 | |
| 7 | 48 | 24 | 17 | 7 | 24 | 36 | 7 | 17 | 24 | 24 | 36 | 48 | |
| 8 | 27 | 39 | 77 | 35 | 27 | 13 | 13 | 27 | 27 | 35 | 39 | 77 | |
| 9 | 77 | 67 | 74 | 3 | 115 | 134 | 3 | 67 | 74 | 77 | 115 | 134 | |
| 10 | 19 | 41 | 45 | 45 | 19 | 41 | 19 | 19 | 41 | 41 | 45 | 45 | |
| 11 | 74 | 66 | 64 | 33 | 74 | 33 | 33 | 33 | 64 | 66 | 74 | 74 |
Как видим, сортировка чисел в строке excel — вполне решаемая задача.
Вернемся к задаче, упомянутой выше. Для её решения нам требуется 1) убедиться, что среди шести чисел в строке таблицы нет повторяющихся и 2) что их среднее арифметическое не меньше их медианы.
Чтобы убедиться, что все числа в строке различны, выведем в ячейках H1:M1 числа, показывающие, сколько раз встречается в строке соответствующее число. Впишем в ячейку H1 формулу =СЧЁТЕСЛИ($A1:$F1;A1) и скопируем её в ячейки I1:M1, а затем — в строки ниже.
Теперь можно легко проверять, что все числа в строке различны: при этом максимум в ячейках H1:M1 будет равен 1 или же сумма чисел в ячейках H1:M1 будет равна 6.
Для вычисления медианы чисел из ячеек A1:F1 воспользуемся выражением (НАИМЕНЬШИЙ(A1:F1;3)+НАИМЕНЬШИЙ(A1:F1;3))/2. (Очевидно, для вычисления медианы нам нет необходимости сортировать массив целиком, достаточно взять лишь два числа из середины отсортированного массива.)
Впишем в ячейку O1 формулу
=ЕСЛИ(И(МАКС(H1:M1)=1;СУММ(A1:F1)/6>=(НАИМЕНЬШИЙ(A1:F1;3)+НАИМЕНЬШИЙ(A1:F1;4))/2);1;»»)
и размножим её в ячейки ниже. В строках, удовлетворяющих условию, будут единицы, в остальных — пустые ячейки.
В ячейку Q1 запишем формулу, суммирующую числа в столбце O (=СУММ(O:O)) либо подсчитывающую количество единиц в этом столбце (=СЧЁТЕСЛИ(O:O;1)) и получаем ответ.
| A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | |
| 1 | 37 | 83 | 24 | 19 | 37 | 41 | 2 | 1 | 1 | 1 | 2 | 1 | 2 | ||||
| 2 | 59 | 77 | 43 | 43 | 118 | 38 | 1 | 1 | 2 | 2 | 1 | 1 | |||||
| 3 | 6 | 65 | 40 | 22 | 6 | 130 | 2 | 1 | 1 | 1 | 2 | 1 | |||||
| 4 | 63 | 77 | 76 | 8 | 63 | 51 | 2 | 1 | 1 | 1 | 2 | 1 | |||||
| 5 | 74 | 47 | 97 | 26 | 222 | 23 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ||||
| 6 | 48 | 24 | 17 | 7 | 24 | 36 | 1 | 2 | 1 | 1 | 2 | 1 | |||||
| 7 | 27 | 39 | 77 | 35 | 27 | 13 | 2 | 1 | 1 | 1 | 2 | 1 | |||||
| 8 | 77 | 67 | 74 | 3 | 115 | 134 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ||||
| 9 | 19 | 41 | 45 | 45 | 19 | 41 | 2 | 2 | 2 | 2 | 2 | 2 | |||||
| 10 | 74 | 66 | 64 | 33 | 74 | 33 | 2 | 1 | 1 | 2 | 2 | 2 |
Приведем также решение на Питоне. Как уже говорилось, предварительно необходимо сохранить таблицу excel в текстовом файле (формат CSV).
f=open(‘9.csv’)
k=0
for s in f:
a=list(map(int,s.split(‘;’)))
a.sort()
if len(a)==len(set(a)) and sum(a)/6 >= (a[2]+a[3])/2:
k += 1
print(k)
Функция set создает из массива a множество: тип данных, представляющих неупорядоченную совокупность значений, в которую каждое значение не может входить более одного раза. Если количество элементов множества равно количеству элементов в исходном массиве, то это означает, что среди элементов массива нет повторяющихся. (Разумеется, проверку всех чисел в массиве на уникальность можно выполнить многими способами, но данный представляется мне наиболее простым.)
(c) Ю.Д.Красильников, 2022 г.
07.04.13 — 07:36
Имеется N-1 ячеек с числами от 2 до N.
например при N=4:
4; 2; 3
как задать функцию, по значению которой можно определить что все числа разные?
я только придумал что сумма всех чисел должна равняться 4+2+3 = 9, но это условие не идеальное, так как оно может выполниться при 3+3+3 = 9
Еще придумал что произведение 4*2*3=24, но это тоже возможно не идеальное условие.
1 — 07.04.13 — 07:38
упорядочить и пересчитать
2 — 07.04.13 — 07:42
(1) круто. Как эта функция называется?
3 — 07.04.13 — 07:43
(2) понятия не имею. уверен, что должно быть слово sub
4 — 07.04.13 — 07:44
(3) зачем тогда пишешь раз не знаешь
5 — 07.04.13 — 07:45
(4) мы намёков не понимаем?
6 — 07.04.13 — 07:45
(0) С умножением не прокатило, при числах
4,243850692 2,378074654 2,378074654
оба условия выполнились. Нужно еще чтобы числа были целые.
7 — 07.04.13 — 07:46
(5) Хрен вас знает.
8 — 07.04.13 — 07:46
иногда приходится заниматься программингом. работа такая
9 — 07.04.13 — 07:48
(8) удачи.
10 — 07.04.13 — 07:54
Ап
11 — 07.04.13 — 08:00
(0)Просто циклом перебрать.
12 — 07.04.13 — 08:04
Или так (А1-А2)(А1-А3)…(А1-AN)(A2-A3)…(AN-A(N-1))=0
13 — 07.04.13 — 08:47
(10) Че ап? Тебе русским языком сказали же: напиши функцию на VBA
14 — 07.04.13 — 11:38
Стандартных функций нет, так как задача достаточно частная.
Если нужно определить нет ли совпадающих чисел, то нужно написать функцию на VBA, которая получает заданный диапазон и попарно сравнивает числа в нём, если обнаруживается два одинаковых, то возвращается True, если не нашли — то False.
15 — 07.04.13 — 12:08
Можно еще упереться, извратиться и использовать поиски. Создать в EXCELе еще колонку, в которой хранить результа поиска по диапазону, содержащими ячейки после (ниже) текущей. Если в этой колонке где-то найдено, то совпадения есть.
16 — 07.04.13 — 12:23
Сортировка по возрубыв и А1 <> A2.
17 — 07.04.13 — 13:33
Давайте без VBA, средствами ячеек и формул экселя. На VBA и эксель не нужен будет, а надо именно через эксекль.
(12) интересно…
18 — 07.04.13 — 13:35
(16) сортировка не подойдет. Числа должны быть не отсортированные.
Еще одно главное свойство: числа все целые, без пропусков. Тоесть присутствуют все из диапазона 2..N
19 — 07.04.13 — 13:39
(12) Похоже это правильно. Только много забивать вручную в формулу. Надо придумать как автоматически посчитать.
20 — 07.04.13 — 13:39
21 — 07.04.13 — 14:00
А сходные таблицы чем не угодили?
22 — 07.04.13 — 14:19
(21) Не понял что такое сходные.
Нашел в поиске решений условие AllDifferent. Вопрос решен!
23 — 07.04.13 — 14:31
Колво(Функция вхождения ячейки в диапазон
24 — 07.04.13 — 18:34
(18) Если предполагается, что числа все разные, и задан диапазон, в котором они могут быть, то просто считаем сумму — если все разные, то каждое число встречается один и только один раз — то есть у нас будет арифметическая прогрессия с шагом 1 (только неотсортированная), если же что-то повторяется, то сумма не совпадёт.
25 — 07.04.13 — 18:58
На самом деле, обычная задача для тех, кто постоянно с excel работает. Решается стандартными формулами.
Например, через сравнение количества строк в диапазоне «=ЧСТРОК(A1:A100)» с количеством уникальных значений (формула массива: «{=СУММ(1/СЧЁТЕСЛИ(A1:A100;A1:A100))}»).
26 — 08.04.13 — 11:05
(24) Так не получится. Например 1 + 2 + 3 = 6. Числа разные. Но 2 + 2 + 2 = 6, числа одинаковые, сумма такая же.
27 — 08.04.13 — 11:06
(25) Отлично!
D_Pavel
28 — 08.04.13 — 11:09
Условие «AllDifferent» решает сразу все задачи:
Проверяет что все числа разные
Проверяет что числа начинаются от 1, и заканчиваются N (все числа присутствуют без пропусков)
Проверяет что все числа целые.
В общем трех зайцев одним выстрелом!
Skip to content
В этом руководстве вы узнаете, как посчитать уникальные значения в Excel с помощью формул и как это сделать в сводной таблице. Мы также разберём несколько примеров счёта уникальных текстовых и числовых значений, в том числе с учетом регистра букв.
При работе с большим набором данных в Excel вам часто может потребоваться знать, сколько в вашей таблице повторяющихся и сколько уникальных записей.
И вот о чем мы сейчас поговорим:
- Как посчитать уникальные значения в столбце.
- Считаем уникальные текстовые значения.
- Подсчет уникальных чисел.
- Как посчитать уникальные с учётом регистра.
- Формулы для подсчета различных значений.
- Как не учитывать пустые ячейки?
- Сколько встречается различных чисел?
- Считаем различные текстовые значения.
- Как сосчитать различные текстовые значения с учетом условий?
- Считаем количество различных чисел с ограничениями.
- Как учесть регистр при подсчёте?
- Как посчитать уникальные строки?
- Используем сводную таблицу.
Если вы регулярно посещаете этот блог, вы уже знаете формулу Excel для подсчета дубликатов. А сегодня мы собираемся изучить различные способы подсчета уникальных значений в Excel. Но для ясности давайте сначала определимся с терминами.
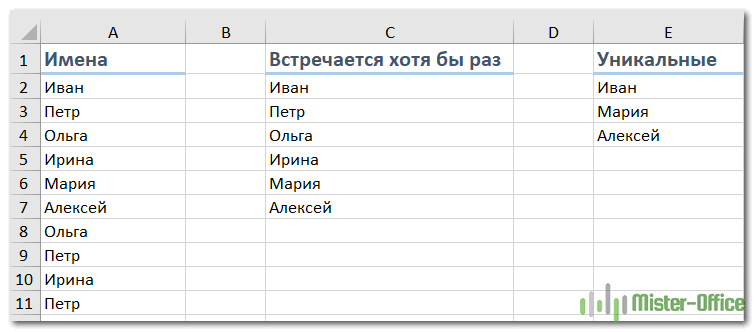
- Уникальные значения – те, которые появляются в списке только один раз.
- Различные – это все, которые имеются в списке без учета повторов, то есть уникальные плюс первое вхождение повторяющихся.
Следующий рисунок иллюстрирует эту разницу:
А теперь давайте посмотрим, как можно их посчитать с помощью формул и функций сводной таблицы.
Далее вы найдете несколько примеров для подсчета уникальных данных разных типов.
Считаем уникальные значения в столбце.
Предположим, у вас есть столбец с именами на листе Excel, и вам нужно подсчитать, сколько там есть неповторяющихся. Самое простое решение состоит в том, чтобы использовать функцию СУММ в сочетании с ЕСЛИ и СЧЁТЕСЛИ :
=СУММ(ЕСЛИ(СЧЁТЕСЛИ(диапазон ; диапазон ) = 1,1,0))
Примечание. Это формула массива, поэтому обязательно нажмите Ctrl + Shift + Enter, чтобы корректно ввести её. Как только вы это сделаете, Excel автоматически заключит всё выражение в {фигурные скобки}, как показано на скриншоте ниже. Ни в коем случае нельзя вводить фигурные скобки вручную, это не сработает.
В этом примере мы считаем уникальные имена в диапазоне A2: A10, поэтому наше выражение выглядит так:
{=СУММ(ЕСЛИ(СЧЁТЕСЛИ(A2:A10;A2:A10)=1;1;0))}

Этот метод подходит и для текстовых, и для цифровых данных. Недостатком является то, что в качестве уникального он будет пересчитывать любое содержимое, в том числе и ошибки.
Далее в этом руководстве мы обсудим несколько других подходов для подсчета уникальных значений разных типов. И поскольку в основном они являются вариациями этой базовой формулы, имеет смысл подробно рассмотреть её. Если вы поймете, как это работает, то сможете настроить ее для своих данных. Если кого-то не интересуют технические подробности, вы можете сразу перейти к следующему примеру.
Как работает формула подсчета уникальных значений?
Как видите, здесь используются 3 разные функции – СУММ, ЕСЛИ и СЧЁТЕСЛИ. Посмотрим, что делает каждая из них:
- Функция СЧЁТЕСЛИ считает, сколько раз каждое отдельное значение появляется в анализируемом диапазоне.
В этом примере СЧЁТЕСЛИ(A2:A10;A2:A10)возвращает массив {3:2:2:1:1:2:3:2:3}.
- Функция ЕСЛИ оценивает каждый элемент в этом массиве, сохраняет все единицы (то есть, уникальные) и заменяет все остальные цифры нулями.
Итак, функция ЕСЛИ(СЧЁТЕСЛИ(A2:A10;A2:A10)=1;1;0) преобразуется в ЕСЛИ({3:2:2:1:1:2:3:2:3}) = 1,1,0).
И далее она превращается в массив чисел {0:0:0:1:1:0:0:0:0}. Здесь 1 означает уникальное значение, а 0 – появляющееся более 1 раза.
- Наконец, функция СУММ складывает числа в этом итоговом массиве и выводит общее количество уникальных значений. Что нам и нужно.
Подсчет уникальных текстовых значений.
Если ваш список содержит как числа так и текст, и вы хотите посчитать только уникальные текстовые строки, добавьте функцию ЕТЕКСТ() в формулу массива, описанную выше:
{=СУММ(ЕСЛИ(ЕТЕКСТ(A2:A10)*СЧЁТЕСЛИ(A2:A10;A2:A10)=1;1;0))}
Функция ЕТЕКСТ возвращает ИСТИНА, если исследуемое содержимое ячейки является текстом, и ЛОЖЬ в противоположном случае. Поскольку звездочка (*) в формулах массива работает как оператор И, то функция ЕСЛИ возвращает 1, только если рассматриваемое одновременно текстовое и уникальное, в противном случае получаем 0. И после того, как функция СУММ сложит все числа, вы получите количество уникальных текстовых значений в указанном диапазоне.
Не забывайте нажимать Ctrl + Shift + Enter, чтобы правильно ввести формулу массива, и вы получите результат, подобный этому:

Рис3
Как вы можете видеть на скриншоте выше, мы получили общее количество уникальных текстовых значений, исключая пустые ячейки, числа, логические выражения ИСТИНА и ЛОЖЬ, а также ошибки.
Как сосчитать уникальные числовые значения.
Чтобы посчитать уникальные числа в списке данных, используйте формулу массива точно так же, как мы только что делали при подсчете текстовых данных. Отличие заключается в том, что вы используете ЕЧИСЛО вместо ЕТЕКСТ:
{=СУММ(ЕСЛИ(ЕЧИСЛО(A2:A10)*СЧЁТЕСЛИ(A2:A10;A2:A10)=1;1;0))}
Пример и результат вы видите на скриншоте чуть выше.
Уникальные значения с учетом регистра.
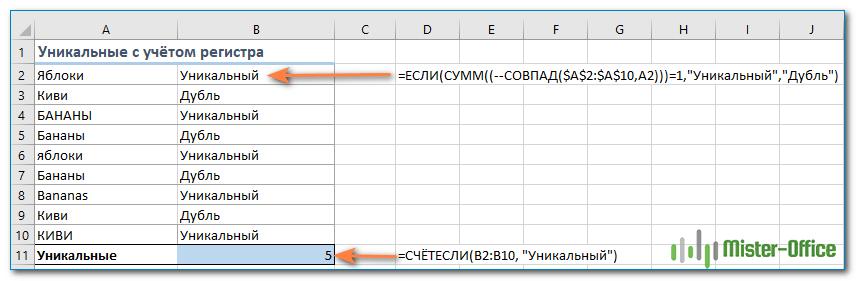
Если для вас принципиально различие в заглавных и прописных буквах, то самым простым способом подсчета будет создание вспомогательного столбца со следующей формулой массива для идентификации повторяющихся и уникальных элементов:
{=ЕСЛИ(СУММ((—СОВПАД($A$2:$A$10;A2)))=1;»Уникальный»;»Дубль»)}
А затем используйте простую функцию СЧЁТЕСЛИ для подсчета уникальных значений:
=СЧЁТЕСЛИ(B2:B10; «Уникальный»)
А теперь посмотрим, как можно посчитать количество значений, которые появляются хотя бы один раз, то есть так называемых различных значений.
Подсчет различных значений.
Используйте следующую универсальное выражение:
{=СУММ(1 / СЧЁТЕСЛИ( диапазон ; диапазон ))}
Помните, что это формула массива, поэтому вам следует нажать Ctrl + Shift + Enter, вместо обычного Enter.
Кроме того, вы можете использовать функцию СУММПРОИЗВ и записать формулу обычным способом:
=СУММПРОИЗВ(1 / СЧЁТЕСЛИ( диапазон ; диапазон ))
Например, чтобы сосчитать различные значения в диапазоне A2: A10, вы можете использовать выражение:
{=СУММ(1/СЧЁТЕСЛИ(A2:A10;A2:A10))}
или же
=СУММПРОИЗВ(1/СЧЁТЕСЛИ(A2:A10;A2:A10))

Этот способ подходит не только для подсчета в столбце, но и для диапазона данных. К примеру, у нас под имена отведено две колонки. Тогда делаем так:
{=СУММПРОИЗВ(1/СЧЁТЕСЛИ(A2:B10;A2:B10))}
Этот метод подходит для текста, чисел, дат.
Единственное ограничение – диапазон должен быть непрерывным и не содержать пустых ячеек и ошибок.
Если в вашем диапазоне данных есть пустые ячейки, то можно изменить:
{=СУММПРОИЗВ(1/СЧЁТЕСЛИ(A2:A10; A2:A10&»»))}
Тогда в расчёт попадёт и будет засчитана и пустая ячейка.
Как это работает?
Как вы уже знаете, мы используем функцию СЧЁТЕСЛИ, чтобы узнать, сколько раз каждый отдельный элемент встречается в указанном диапазоне. В приведенном выше примере, результат работы функции СЧЕТЕСЛИ представляет собой числовой массив: {3:2:2:1:3:2:1:2:3}.
После этого выполняется ряд операций деления, где единица делится на каждую цифру из этого массива. Это превращает все неуникальные значения в дробные числа, соответствующие количеству повторов. Например, если число или текст появляется в списке 2 раза, в массиве создаются 2 элемента равные 0,5 (1/2 = 0,5). А если появляется 3 раза, в массиве создаются 3 элемента 0,333333.
В нашем примере результатом вычисления выражения 1/СЧЁТЕСЛИ(A2:A10;A2:A10) является массив {0.333333333333333:0.5:0.5:1:0.333333333333333:0.5:1:0.5:0.333333333333333}.
Пока не слишком понятно? Это потому, что мы еще не применили функцию СУММ / СУММПРОИЗВ. Когда одна из этих функций складывает числа в массиве, сумма всех дробных чисел для каждого отдельного элемента всегда дает 1, независимо от того, сколько раз он появлялся. И поскольку все уникальные элементы отображаются в массиве как единицы (1/1 = 1), окончательный результат представляет собой общее количество всех встречающихся значений.
Как и в случае подсчета уникальных значений в Excel, вы можете использовать варианты универсальной формулы для обработки отдельно чисел, текста или же с учетом регистра.
Помните, что все приведенные ниже выражения являются формулами массива и требуют нажатия Ctrl + Shift + Enter.
Подсчет различных значений без учета пустых ячеек
Если столбец, в котором вы хотите совершить подсчет, может содержать пустые ячейки, вам следует в уже знакомую нам формулу массива добавить функцию ЕСЛИ. Она будет проверять ячейки на наличие пустот (основная формула Excel, описанная выше, в этом случае вернет ошибку #ДЕЛ/0):
=СУММ(ЕСЛИ( диапазон <> «»; 1 / СЧЁТЕСЛИ( диапазон ; диапазон ); 0))
Вот как, к примеру, можно посчитать количество индивидуальных значений, игнорируя пустые ячейки:

Используем:
{=СУММ(ЕСЛИ(A2:A10<>»»;1/СЧЁТЕСЛИ(A2:A10; A2:A10); 0))}
Как видите, наш список состоит из трёх имён.
Подсчет различных чисел.
Чтобы посчитать различные числовые значения (числа, даты и время), используйте функцию ЕЧИСЛО:
= СУММ(ЕСЛИ(ЕЧИСЛО( диапазон ); 1 / СЧЁТЕСЛИ( диапазон ; диапазон ); «»))
Считаем, сколько имеется различных чисел в диапазоне A2: A10:
{=СУММ(ЕСЛИ(ЕЧИСЛО(A2:A10);1/СЧЁТЕСЛИ(A2:A10; A2:A10);»»))}
Результат вы можете посмотреть ниже.

Это достаточно простое и элегантное решение, но работает оно гораздо медленнее, чем выражения, которые используют функцию ЧАСТОТА для подсчета уникальных значений. Если у вас большие наборы данных, то целесообразно переключиться на формулу, основанную на расчёте частот.
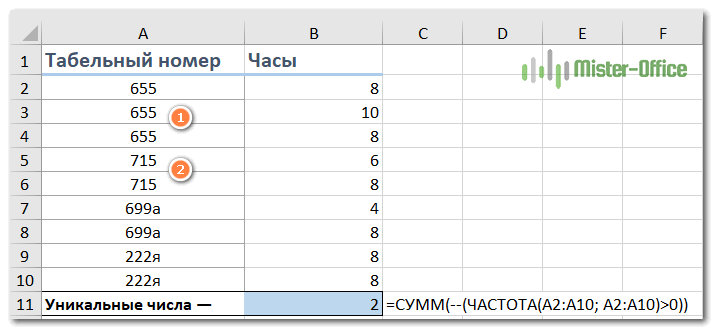
И вот еще один способ подсчета чисел:
=СУММ(—(ЧАСТОТА(диапазон; диапазон)>0))
Применительно к примеру ниже:
=СУММ(—(ЧАСТОТА(A2:A10; A2:A10)>0))
Как видите, здесь игнорируются записи, в которых имеются буквы.
Пошагово разберём, как это работает.
Функция ЧАСТОТА возвращает массив цифр, которые соответствуют интервалам, заданным имеющимися числами. В этом случае мы сравниваем один и тот же набор чисел для массива данных и для массива интервалов.
Результатом является то, что ЧАСТОТА() возвращает массив, который представляет собой счетчик для каждого числового значения в массиве данных.
Это работает, потому что ЧАСТОТА() возвращает ноль для любых чисел, которые ранее уже появились в списке. Ноль возвращается и для текстовых данных. Поэтому полученный массив выглядит следующим образом:
{3:0:0:2:0:0}
Как видите, обрабатываются только числа. Ячейки A7:A10 игнорируются, потому что там текст. А функция ЧАСТОТА() работает только с числами.
Теперь каждое из этих чисел проверяем на условие «больше нуля».
Получаем:
{ИСТИНА:ЛОЖЬ:ЛОЖЬ:ИСТИНА:ЛОЖЬ:ЛОЖЬ}
Теперь превращаем ИСТИНА и ЛОЖЬ в 1 и 0 соответственно. Делаем это при помощи двойного отрицания. Проще говоря, это двойной минус, который не меняет величину числа, но позволяет получить реальные числа, когда это вообще возможно:
{1:0:0:1:0:0}
А теперь функция СУММ складывает всё и получаем результат: 2.
Различные текстовые значения.
Чтобы посчитать отдельные текстовые записи в столбце, мы будем использовать тот же подход, который мы использовали для исключения пустых ячеек.
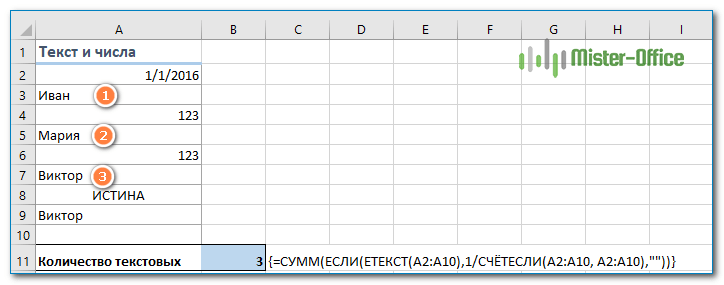
Как вы можете легко догадаться, мы просто добавим функцию ЕТЕКСТ и проверку условия:
=СУММ(ЕСЛИ(ЕТЕКСТ( диапазон ); 1 / СЧЁТЕСЛИ( диапазон ; диапазон ); «»))
Количество индивидуальных символьных значений посчитаем так:
{=СУММ(ЕСЛИ(ЕТЕКСТ(A2:A10);1/СЧЁТЕСЛИ(A2:A10; A2:A10);»»))}
Не забываем, что это формула массива.
Если в вашей таблице нет пустых ячеек и ошибок, то вы можете применить формулу, которая использует несколько функций: ЧАСТОТА, ПОИСКПОЗ, СТРОКА и СУММПРОИЗВ.
В общем виде это выглядит так:
=СУММПРОИЗВ(—(ЧАСТОТА(ПОИСКПОЗ (диапазон; диапазон;0); СТРОКА (диапазон)- СТРОКА (диапазон_первая_ячейка)+1)>0))
Предположим, у вас есть список имен сотрудников вместе с часами работы над проектом, и вы хотите знать, сколько человек в этом участвовали. Глядя на данные, вы можете увидеть, что имена повторяются. А вы хотите пересчитать всех, кто хотя бы раз появился в этом списке.

Применяем формулу массива:
{=СУММПРОИЗВ(— (ЧАСТОТА(ПОИСКПОЗ(A2:A10; A2:A10;0); СТРОКА(A2:A10) -СТРОКА(A2) +1)> 0))}
Она является более сложной, чем аналогичная, которая использует функцию ЧАСТОТА() для подсчета различных чисел. Это потому, что ЧАСТОТА() не работает с текстом. Поэтому ПОИСКПОЗ преобразует имена в номера позиций, которые может обрабатывать ЧАСТОТА().
Если какая-либо из ячеек в диапазоне пустая, вам необходимо использовать более сложную формулу массива, которая включает в себя функцию ЕСЛИ:
{= СУММ(ЕСЛИ(ЧАСТОТА(ЕСЛИ(данные <> «»;ПОИСКПОЗ(данные; данные; 0));СТРОКА(данные) -СТРОКА(данные_первая_ячейка) +1); 1))}
Примечание: поскольку логическая проверка в операторе ЕСЛИ содержит массив, то наше выражение сразу становится формулой массива, которая требует ввода через Ctrl+Shift+Enter. Поэтому же СУММПРОИЗВ была заменена на СУММ.
Применительно к нашему примеру это выглядит так:
{=СУММ(ЕСЛИ(ЧАСТОТА(ЕСЛИ(A2:A10 <> «»;ПОИСКПОЗ(A2:A10; A2:A10; 0));СТРОКА(A2:A10) -СТРОКА(A2) +1); 1))}
Теперь «сломать» этот расчет может только наличие ячеек с ошибками в исследуемом диапазоне.
Различные текстовые значения с условием.
Предположим, необходимо пересчитать, сколько наименований товаров заказал конкретный покупатель.
Чтобы решить эту проблему, вам может помочь этот вариант:
{=СУММПРОИЗВ((($A$2:$A$18=E2)) / СЧЁТЕСЛИМН($A$2:$A$18;$A$2:$A$18&»»; $B$2:$B$18;$B$2:$B$18&»»))}
Введите это в пустую ячейку, куда вы хотите поместить результат, F2, например. А затем нажмите Shift + Ctrl + Enter вместе, чтобы получить правильный результат.
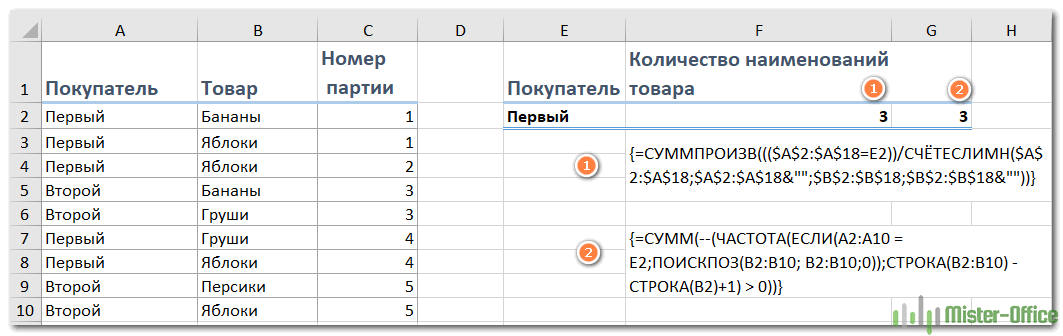
Поясним: здесь A2:A18 это список покупателей, с учётом которого вы ограничиваете область расчётов, B2: B18 — перечень товаров, в котором вы хотите посчитать уникальные значения, Е2 содержит критерий, на основании которого подсчет ограничивается только конкретным покупателем.
Второй способ.
Для уникальных значений в диапазоне с критериями, вы можете использовать формулу массива, основанную на функции ЧАСТОТА.
{=СУММ(—(ЧАСТОТА(ЕСЛИ(критерий; ПОИСКПОЗ(диапазон; диапазон;0)); СТРОКА(диапазон) -СТРОКА(диапазон_первая_ячейкаl)+1)>0))}
Применительно к нашему примеру:
{=СУММ(—(ЧАСТОТА(ЕСЛИ(A2:A10 = E2; ПОИСКПОЗ(B2:B10; B2:B10;0)); СТРОКА(B2:B10) — СТРОКА(B2)+1) > 0))}
С учетом ограничений ЕСЛИ() функция ПОИСКПОЗ определяет порядковый номер только для строк, которые соответствуют критериям.
Если какая-либо из ячеек в диапазоне критериев пустая, вам необходимо скорректировать расчёт, добавив дополнительно ЕСЛИ для обработки пустых ячеек. Иначе они будут переданы в функцию ПОИСКПОЗ, которая в ответ сгенерирует сообщение об ошибке.
Вот что получилось после корректировки:
{=СУММ(— (ЧАСТОТА(ЕСЛИ(B2:B10 <> «»; ЕСЛИ(A2:A10 = E2; ПОИСКПОЗ(B2:B10; B2:B10;0))); СТРОКА(B2:B10) -СТРОКА(B2) +1)> 0))}
То есть все действия и расчёты мы производим, если в столбце B нам встретилась непустая ячейка: ЕСЛИ(B2:B10 <> «»….
Если у вас есть два критерия, вы можете расширить логику формулы путем добавления другого вложенного ЕСЛИ.
Поясним. Определим, сколько наименований товара находилось в первой партии первого покупателя.
Критерии запишем в G2 и G3.
В общем виде это выглядит так:
{=СУММ(—(ЧАСТОТА(ЕСЛИ(критерий1; ЕСЛИ(критерий2; ПОИСКПОЗ (диапазон; диапазон;0))); СТРОКА (диапазон) — СТРОКА (диапазон_первая_позиция) +1)> 0))}
Подставляем сюда реальные данные и получаем результат:

{=СУММ(—(ЧАСТОТА(ЕСЛИ(A2:A10=G2; ЕСЛИ(C2:C10=G3;ПОИСКПОЗ(B2:B10;B2:B10;0)));СТРОКА(B2:B10)-СТРОКА(B2)+1)>0))}
В первой партии 2 наименования товара, хотя и 3 позиции.
Различные числа с условием.
Если вам нужно пересчитать уникальные (с учётом первого вхождения) числа в диапазоне с учетом каких-то ограничений, можно использовать формулу, основанную на СУММ и ЧАСТОТА, и вместе с этим применять критерии.
{=СУММ(— (ЧАСТОТА(ЕСЛИ(критерий; диапазон); диапазон)> 0))}
Предположим, у нас есть перечень табельных номеров и количество отработанных часов по дням. Нужно сосчитать, сколько человек хотя бы раз отработали менее чем по 8 часов, то есть неполную смену.

Вот наша формула массива:
{=СУММ(— (ЧАСТОТА(ЕСЛИ(B2:B10 < 8; A2:A10); A2:A10)> 0))}
Как видите, таких случаев 3, но связаны они с двумя работниками.
Различные значения с учетом регистра.
Подобно подсчету уникальных, самый простой способ подсчета различных значений с учетом регистра – это добавить вспомогательный столбец с формулой массива, который идентифицирует нужные элементы, включая первые повторяющиеся вхождения.
Подход в основном такой же, как и тот, который мы использовали для подсчета уникальных значений с учетом регистра, с одним небольшим изменением:
{=ЕСЛИ(СУММ((—СОВПАД($A$2:$A2;$A2)))=1;»Уникальный»;»»)}
Как вы помните, все формулы массива в Excel требуют нажатия Ctrl + Shift + Enter.
После того, как это выражение будет записано, вы можете посчитать «различные» значения с помощью обычной функции СЧЁТЕСЛИ, например:
=СЧЁТЕСЛИ(B2:B10; «Уникальный»)
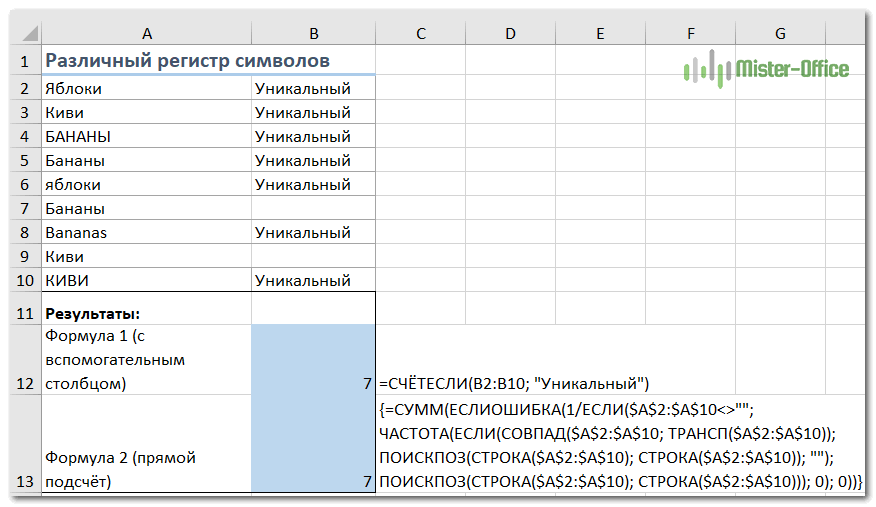
Если вы не можете добавить вспомогательный столбец на свой рабочий лист, вы можете использовать следующую более сложную формулу массива для подсчета различных значений с учетом регистра без создания дополнительного столбца:
{=СУММ(ЕСЛИОШИБКА(1/ЕСЛИ($A$2:$A$10<>»»; ЧАСТОТА(ЕСЛИ(СОВПАД($A$2:$A$10; ТРАНСП($A$2:$A$10)); ПОИСКПОЗ(СТРОКА($A$2:$A$10); СТРОКА($A$2:$A$10)); «»); ПОИСКПОЗ(СТРОКА($A$2:$A$10); СТРОКА($A$2:$A$10))); 0); 0))}
Как видите, обе формулы дают одинаковые результаты.
Подсчет уникальных строк в таблице.
Подсчет уникальных / различных строк в Excel сродни пересчёту уникальных и различных значений. С той лишь разницей, что вы используете функцию СЧЁТЕСЛИМН вместо СЧЁТЕСЛИ, что позволяет вам указать сразу несколько столбцов для проверки уникальности.
Например, чтобы подсчитать уникальные строки на основе столбцов A (Имя) и B (Фамилия), используйте один из следующих вариантов:
Для уникальных строк:
{=СУММ(ЕСЛИ(СЧЁТЕСЛИМН(A3:A11;A3:A11; B3:B11;B3:B11)=1;1;0))}
Для различных строк:
{=СУММ(1/СЧЁТЕСЛИМН(A3:A11;A3:A11;B3:B11;B3:B11))}
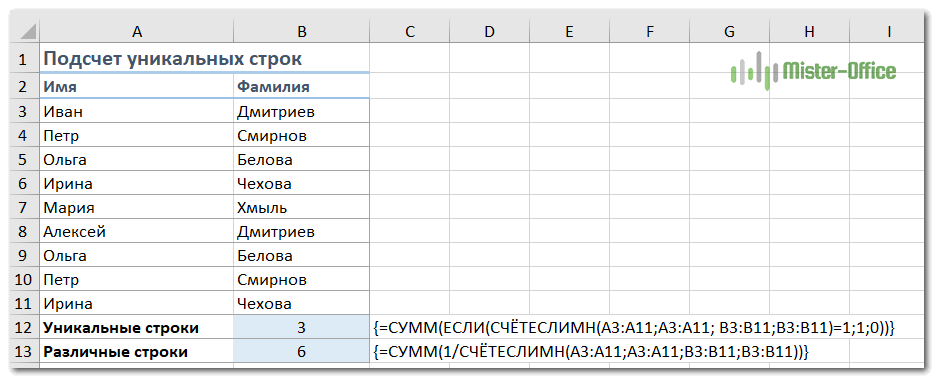
Естественно, вы не ограничены только двумя столбцами. Функция СЧЁТЕСЛИМН может обрабатывать до 127 пар диапазон / критерий.
Как можно использовать сводную таблицу.
Вот обычная задача, которую все пользователи Excel должны время от времени выполнять. У вас есть список данных (к примеру, названий товаров), и нужно узнать количество уникальных позиций в этом списке. Как это сделать? Проще, чем вы думаете 
В версиях Excel выше 2013 есть специальная функция, которая позволяет автоматически пересчитывать различные значения в сводной таблице. На следующем рисунке показано, как выглядит этот счетчик:

Чтобы создать сводную таблицу со счетчиком для определенного столбца, выполните следующие действия.
- Выберите данные для включения в сводную таблицу, перейдите на вкладку «Вставка» и нажмите кнопку «Сводная таблица» .
- В диалоговом окне «Создание сводной таблицы» выберите, следует ли разместить сводную таблицу на новом или существующем листе, и обязательно установите флажок «Добавить эти данные в модель данных» .

- Когда откроется сводная таблица, расположите области строк, столбцов и значений так, как вам нужно. Если у вас нет большого опыта работы со сводными таблицами Excel, могут оказаться полезными следующие подробные рекомендации: Создание сводной таблицы в Excel.
- Переместите поле, количество уникальных элементов которого вы хотите вычислить ( поле « Товар» в этом примере), в область « Значения» , щелкните его и выберите «Параметры значения поля…» из раскрывающегося меню.
- Откроется диалоговое окно , прокрутите вниз до операции «Число разных элементов» , которая является самым последним пунктом в списке, выберите ее и нажмите OK .
Вы также можете дать собственное имя своему счетчику, если хотите.

Готово! Вновь созданная сводная таблица будет отображать количество различных товаров, как показано на самом первом скриншоте в этом разделе.
Вот как можно подсчитать различные и уникальные значения в столбце и целиком в таблице Excel.
Благодарю вас за чтение и надеюсь увидеть вас снова. Пожалуйста, не переключайтесь!
 Как найти и выделить уникальные значения в столбце — В статье описаны наиболее эффективные способы поиска, фильтрации и выделения уникальных значений в Excel. Ранее мы рассмотрели различные способы подсчета уникальных значений в Excel. Но иногда вам может понадобиться только просмотреть уникальные…
Как найти и выделить уникальные значения в столбце — В статье описаны наиболее эффективные способы поиска, фильтрации и выделения уникальных значений в Excel. Ранее мы рассмотрели различные способы подсчета уникальных значений в Excel. Но иногда вам может понадобиться только просмотреть уникальные…  Как получить список уникальных значений — В статье описано, как получить список уникальных значений в столбце с помощью формулы и как настроить эту формулу для различных наборов данных. Вы также узнаете, как быстро получить отдельный список с…
Как получить список уникальных значений — В статье описано, как получить список уникальных значений в столбце с помощью формулы и как настроить эту формулу для различных наборов данных. Вы также узнаете, как быстро получить отдельный список с…  Как выделить цветом повторяющиеся значения в Excel? — В этом руководстве вы узнаете, как отображать дубликаты в Excel. Мы рассмотрим различные методы затенения дублирующих ячеек, целых строк или последовательных повторений с использованием условного форматирования. Ранее мы исследовали различные…
Как выделить цветом повторяющиеся значения в Excel? — В этом руководстве вы узнаете, как отображать дубликаты в Excel. Мы рассмотрим различные методы затенения дублирующих ячеек, целых строк или последовательных повторений с использованием условного форматирования. Ранее мы исследовали различные…  Как посчитать количество повторяющихся значений в Excel? — Зачем считать дубликаты? Мы можем получить ответ на множество интересных вопросов. К примеру, сколько клиентов сделало покупки, сколько менеджеров занималось продажей, сколько раз работали с определённым поставщиком и т.д. Если…
Как посчитать количество повторяющихся значений в Excel? — Зачем считать дубликаты? Мы можем получить ответ на множество интересных вопросов. К примеру, сколько клиентов сделало покупки, сколько менеджеров занималось продажей, сколько раз работали с определённым поставщиком и т.д. Если…  Как убрать повторяющиеся значения в Excel? — В этом руководстве объясняется, как удалять повторяющиеся значения в Excel. Вы изучите несколько различных методов поиска и удаления дубликатов, избавитесь от дублирующих строк, обнаружите точные повторы и частичные совпадения. Хотя…
Как убрать повторяющиеся значения в Excel? — В этом руководстве объясняется, как удалять повторяющиеся значения в Excel. Вы изучите несколько различных методов поиска и удаления дубликатов, избавитесь от дублирующих строк, обнаружите точные повторы и частичные совпадения. Хотя…
Откройте файл электронной таблицы, содержащей в каждой строке шесть натуральных чисел.
Задание 9
Определите количество строк таблицы, содержащих числа, для которых выполнены оба условия:
— в строке только одно число повторяется ровно два раза, остальные числа различны;
— среднее арифметическое неповторяющихся чисел строки не больше суммы повторяющихся чисел.
В ответе запишите только число.
Спрятать решение
Решение.
Сохраним файл в формате «.txt» и решим задачу с помощью языка Python:
count = 0
f = open(‘9.txt’)
for s in f:
arr = list(map(int, s.split()))
rep = sum(arr) — sum(set(arr))
mean_unrep = sum(set(arr) — {rep}) / 4
if len(set(arr)) == 5 and mean_unrep <= 2 * rep:
count += 1
print(count)
Ответ: 2241.
Приведем другое решение от Мокрушина Николая
В ячейку G1 помещаем формулу: =СЧЁТЕСЛИ($A1:$F1;A1) и копируем её на диапазон G1:L6400. Данная формула выдаст в ячейках количество раз, которое встречается в строке каждое число.
В ячейку M1 запишем формулу: =СУММ(G1:L1)-7 и скопируем ее на диапазон M1:M6400. Если значение в ячейке равно 1, то в строке есть повторяющиеся числа, причем только одно число повторяется ровно два раза, остальные числа различны.
В ячейку N1 запишем формулу: =ЕСЛИ(G1 = 2;A1;0) и скопируем её на диапазон N1:S6400. В данных ячейках выведутся повторяющиеся числа в строках, удовлетворяющих условию задачи.
В ячейку T1 запишем формулу: =ЕСЛИ(M1 = 1; СУММ(A1:F1);0) и скопируем её на диапазон T1:T6400. Данная формула считает сумму всех ячеек в строках, удовлетворяющих условию задачи.
В ячейку U1 запишем формулу: =СУММ(N1:S1) и скопируем её на диапазон U1:U6400. Данная формула считает сумму всех повторяющихся чисел в строках, удовлетворяющих условию задачи.
В ячейку V1 запишем формулу: =(T1-U1)/4 и скопируем её на диапазон V1:V6400. Данная формула считает среднее арифметическое неповторяющихся чисел в строках, удовлетворяющих условию задачи.
В ячейку W1 запишем формулу: =ЕСЛИ(И(V1<=U1;M1 = 1);1;0) и скопируем её на диапазон W1:W6400. Данная формула выведет значение 1, если строка удовлетворяет всем условиям задачи.
В ячейке X1 посчитаем все строки удовлетворяющие условиям задачи с помощью формулы =СУММ(W1:W6400) и получим ответ 2241.
Источник: Демонстрационная версия ЕГЭ−2023 по информатике
Колонки сравнивают для того, чтобы, например, в отчетах не было дубликатов. Или, наоборот, для проверки правильности заполнения — с поиском непохожих значений. И проще всего выполнять сравнение двух столбцов на совпадение в Excel — для этого есть 6 способов.

1 Сравнение с помощью простого поиска
При наличии небольшой по размеру таблицы заниматься сравнением можно практически вручную. Для этого достаточно выполнить несколько простых действий.
- Перейти на главную вкладку табличного процессора.
- В группе «Редактирование» выбрать пункт поиска.
- Выделить столбец, в котором будет выполняться поиск совпадений — например, второй.
- Вручную задавать значения из основного столбца (в данном случае — первого) и искать совпадения.
Если значение обнаружено, результатом станет выделение нужной ячейки. Однако с помощью такого способа можно работать только с небольшими столбцами. И, если это просто цифры, так можно сделать и без поиска — определяя совпадения визуально. Впрочем, если в колонках записаны большие объемы текста, даже такая простая методика позволит упростить поиск точного совпадения.

2 Операторы ЕСЛИ и СЧЕТЕСЛИ
Еще один способ сравнения значений в двух столбцах Excel подходит для таблиц практически неограниченного размера. Он основан на применении условного оператора ЕСЛИ и отличается от других методик тем, что для анализа совпадений берется только указанная в формуле часть, а не все значения массива. Порядок действий при использовании методики тоже не слишком сложный и подойдет даже для начинающего пользователя Excel.
- Сравниваемые столбцы размещаются на одном листе. Не обязательно, чтобы они находились рядом друг с другом.
- В третьем столбце, например, в ячейке J6, ввести формулу такого типа: =ЕСЛИ(ЕОШИБКА(ПОИСКПОЗ(H6;$I$6:$I$14;0));»;H6)
- Протянуть формулу до конца столбца.
Результатом станет появление в третьей колонке всех совпадающих значений. Причем H6 в примере — это первая ячейка одного из сравниваемых столбцов. А диапазон $I$6:$I$14 — все значения второй участвующей в сравнении колонки. Функция будет последовательно сравнивать данные и размещать только те из них, которые совпали. Однако выделения обнаруженных совпадений не происходит, поэтому методика подходит далеко не для всех ситуаций.
Еще один способ предполагает поиск не просто дубликатов в разных колонках, но и их расположения в пределах одной строки. Для этого можно применить все тот же оператор ЕСЛИ, добавив к нему еще одну функцию Excel — И. Формула поиска дубликатов для данного примера будет следующей: =ЕСЛИ(И(H6=I6); «Совпадают»; «») — ее точно так же размещают в ячейке J6 и протягивают до самого низа проверяемого диапазона. При наличии совпадений появится указанная надпись (можно выбрать «Совпадают» или «Совпадение»), при отсутствии — будет выдаваться пустота.
Тот же способ подойдет и для сравнения сразу большого количества колонок с данными на точное совпадение не только значения, но и строки. Для этого применяется уже не оператор ЕСЛИ, а функция СЧЕТЕСЛИ. Принцип написания и размещения формулы похожий.
Она имеет вид =ЕСЛИ(СЧЕТЕСЛИ($H6:$J6;$H6)=3; «Совпадают»;») и должна размещаться в верхней части следующего столбца с протягиванием вниз. Однако в формулу добавляется еще количество сравниваемых колонок — в данном случае, три.
Если поставить вместо тройки двойку, результатом будет поиск только тех совпадений с первой колонкой, которые присутствуют в одном из других столбцов. Причем, тройные дубликаты формула проигнорирует. Так же как и совпадения второй и третьей колонки.
3 Формула подстановки ВПР
Принцип действия еще одной функции для поиска дубликатов напоминает первый способ использованием оператора ЕСЛИ. Но вместо ПОИСКПОЗ применяется ВПР, которую можно расшифровать как «Вертикальный Просмотр». Для сравнения двух столбцов из похожего примера следует ввести в верхнюю ячейку (J6) третьей колонки формулу =ВПР(H6;$I$6:$I$15;1;0) и протянуть ее в самый низ, до J15.
С помощью этой функции не просто просматриваются и сравниваются повторяющиеся данные — результаты проверки устанавливаются четко напротив сравниваемого значения в первом столбце. Если программа не нашла совпадений, выдается #Н/Д.
4 Функция СОВПАД
Достаточно просто выполнить в Эксель сравнение двух столбцов с помощью еще двух полезных операторов — распространенного ИЛИ и встречающейся намного реже функции СОВПАД. Для ее использования выполняются такие действия:
- В третьем столбце, где будут размещаться результаты, вводится формула =ИЛИ(СОВПАД(I6;$H$6:$H$19))
- Вместо нажатия Enter нажимается комбинация клавиш Ctr + Shift + Enter. Результатом станет появление фигурных скобок слева и справа формулы.
- Формула протягивается вниз, до конца сравниваемой колонки — в данном случае проверяется наличие данных из второго столбца в первом. Это позволит изменяться сравниваемому показателю, тогда как знак $ закрепляет диапазон, с которым выполняется сравнение.
Результатом такого сравнения будет вывод уже не найденного совпадающего значения, а булевой переменной. В случае нахождения это будет «ИСТИНА». Если ни одного совпадения не было обнаружено — в ячейке появится надпись «ЛОЖЬ».
Стоит отметить, что функция СОВПАД сравнивает и числа, и другие виды данных с учетом верхнего регистра. А одним из самых распространенных способом использования такой формулы сравнения двух столбцов в Excel является поиска информации в базе данных. Например, отдельных видов мебели в каталоге.

5 Сравнение с выделением совпадений цветом
В поисках совпадений между данными в 2 столбцах пользователю Excel может понадобиться выделить найденные дубликаты, чтобы их было легко найти. Это позволит упростить поиск ячеек, в которых находятся совпадающие значения. Выделять совпадения и различия можно цветом — для этого понадобится применить условное форматирование.
Порядок действий для применения методики следующий:
- Перейти на главную вкладку табличного процессора.
- Выделить диапазон, в котором будут сравниваться столбцы.
- Выбрать пункт условного форматирования.
- Перейти к пункту «Правила выделения ячеек».
- Выбрать «Повторяющиеся значения».
- В открывшемся окне указать, как именно будут выделяться совпадения в первой и второй колонке. Например, красным текстом, если цвет остальных сообщений стандартный черный. Затем указать, что выделяться будут именно повторяющиеся ячейки.
Теперь можно снять выделение и сравнить совпадающие значения, которые будут заметно отличаться от остальной информации. Точно так же можно выделить, например, и уникальную информацию. Для этого следует выбрать вместо «повторяющихся» второй вариант — «уникальные».
6 Надстройка Inquire
Начиная с версий MS Excel 2013 табличный процессор позволяет воспользоваться еще одной методикой — специальной надстройкой Inquire. Она предназначена для того, чтобы сравнивать не колонки, а два файла .XLS или .XLSX в поисках не только совпадений, но и другой полезной информации.
Для использования способа придется расположить столбцы или целые блоки информации в разных книгах и удалить все остальные данные, кроме сравниваемой информации. Кроме того, для проверки необходимо, чтобы оба файла были одновременно открытыми.
Процесс использования надстройки включает такие действия:
- Перейти к параметрам электронной таблицы.
- Выбрать сначала надстройки, а затем управление надстройками COM.
- Отметить пункт Inquire и нажать «ОК».
- Перейти к вкладке Inquire.
- Нажать на кнопку Compare Files, указать, какие именно файлы будут сравниваться, и выбрать Compare.
- В открывшемся окне провести сравнения, используя показанные совпадения и различия между данными в столбцах.
У каждого варианта сравнения — свое цветовое решение. Так, зеленым цветом на примере выделены отличия. У совпадающих данных отсутствует выделение. А сравнение расчетных формул показало, что результаты отличаются все — и для выделения использован бирюзовый цвет.
Читайте также:
- 5 программ для совместной работы с документами
-
Как в Экселе протянуть формулу по строке или столбцу: 5 способов