
Создание вариационного
ряда, вариационной кривой, определение среднего значения и среднеквадратичного
отклонения.
Для селекционера,
например, важно знать, сколько зерен содержит колос выведенного (выводимого) им
нового сорта пшеницы. В этой ситуации совершенно ясно, что подсчетом количества
зерен только в одном колосе не обойтись. Для определения числа зерен надо
воспользоваться достаточно большим количеством колосьев, скажем не менее сотни.
Приведем пример математической обработки результатов селекции.
Все поле
пшеницы, которое вырастил селекционер можно на математическом языке назвать
генеральной совокупностью. Подсчитать количество зерен в колосьях всей
генеральной совокупности, очевидно, не представляется возможным, но из всей
генеральной совокупности можно выбрать, скажем, сто колосьев и подсчитать
количество зерен в них. Эти сто колосьев будут называться выборкой из генеральной
совокупности, и они с определенной точностью будут отражать число зерен во всем
поле (генеральной совокупности). Чтобы по данным выборки иметь возможность
судить обо всей генеральной совокупности, она должна быть отобрана случайно.
Так в нашем случае селекционер ни в коем случае не должен отдавать предпочтение
тем или иным колосьям (по размерам, внешнему виду, месту произрастания на поле
и т.п.) в процессе их выборки. Наиболее целесообразно в данной ситуации
совершать выбор колосьев из непрозрачного мешка наугад. У всех выбранных
колосьев производится подсчет числа зерен, и результаты фиксируются в виде ряда
чисел, с которыми в дальнейшем и предстоит совершать математические действия. В
данном примере можно предложить следующую их последовательность.
2.1 Создание вариационного ряда.
Вариационным
рядом называется ранжированный в порядке возрастания или убывания ряд вариантов
с соответствующими им весами (частотами или частностями). Вариационный ряд
будет дискретным, если любые его варианты отличаются на постоянную величину, и
непрерывным, если варианты могут отличатся один от другого на сколь угодно
малую величину.
Иными словами в вариационном ряду
полученные значения располагаются в порядке их увеличения и, если значение
повторяется, то рядом записывается число его повторений. Т.е. в данном примере
по числу зерен в колосьях ряд может выглядеть так (таб. 2):
Таблица 2
|
Число зерен в колосе |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
|
Число колосьев |
1 |
2 |
2 |
4 |
6 |
8 |
8 |
9 |
10 |
|
Число зерен в колосе |
26 |
27 |
28 |
29 |
30 |
31 |
32 |
33 |
34 |
|
Число колосьев |
9 |
9 |
9 |
8 |
6 |
4 |
3 |
1 |
1 |
Полученный вариационный ряд
позволяет выявить закономерности распределения колосьев по числу зерен в них.
2.2 Создание вариационной
кривой.
Закономерности распределения
можно представить более наглядно, создав вариационную кривую, называемую
полигоном (рис 3), или представить в виде столбчатой диаграммы, которая здесь
будет называться гистограммой (рис 4).


Из полученных схем уже можно наглядно судить о закономерностях
распределения.
Диаграммы
строятся при помощи «Excel»
так:
Ø Ввести в окно программы данные вариационного
ряда.
Ø Запустить «Мастер диаграмм», нажатием
кнопки  .
.
Ø В графе «тип» выбирать или «гистограмма», или
«график».
Ø Нажать кнопку «Далее».
Ø В «шаге 2 из 4» найти строку с названием
«Диапазон» и щелкнуть по кнопке, расположенной справа от надписи и пустого
поля, при этом «Мастер диаграмм» несколько свернется.
Ø Выделить данные в окне программы (в примере это
значения в ячейках В1 – В18).
Ø Снова щелкнуть по кнопке в «Мастере диаграмм».
«Мастер» развернется. В окне «Мастера» появится эскиз гистограммы или полигона.
Ø В этом же шаге (2 из 4) щелкнуть по закладке с
надписью «Ряд».
Ø В открывшейся страничке найти строчку с надписью
«Подписи оси Х».
Ø Щелкнуть по кнопке справа от надписи и пустого
поля.
Ø Выделить значения в окне программы, которые
будут на диаграмме представляться в качестве данных оси Х. (в примере значения
в ячейках А1 – А18).
Ø Щелкнуть по кнопке в свернутом «Мастере».
Ø Щелкнуть по кнопке «Далее» (шаг 3 из 4).
Ø При необходимости, в графе «Заголовки» выполнить
подписи осей Х и Y, а
так же дать диаграмме название.
Ø Щелкнуть по кнопке далее, затем готово и в
результате получится готовая гистограмма или полигон (рис 3).
2.3 Определение среднего значения признака.
Среднее
значение ряда данных находится обычным образом. Суммируются все значения
признака и делятся на количество этих значений. Т.е. здесь общее число зерен в
100 колосках равно 2551, то среднее значение будет равно 2551/100 = 25.51.
Для определения
среднего значения признака с использованием «Excel» надо выполнить следующие шаги:
Ø Ввести в столбец А окна программы все значения
признака, в том числе и повторяющиеся. Т.е. здесь все 100 значений зерен в
колосках. Ввод можно осуществлять в любой последовательности – по возрастанию,
по убыванию или в разнобой. Введенный массив чисел лучше сохранить, так как он
пригодится для расчета отклонения.
Ø Щелкнуть в окне программы по любой пустой
ячейке. По окончании расчетов в ней появится соответствующее среднее значение.
Ø В меню «Вставка» выбрать «Функция».
Ø В появившемся списке функций выбрать функцию
«СРЗНАЧ».
Ø Щелкнуть по кнопке «ОК». Появится окно
«Аргументы функции».
Ø Щелкнуть по кнопке правее надписи «Число 1» и
поля (окно свернется).
Ø Выделить в окне программы весь числовой массив,
среднее значение которого необходимо определить.
Ø Щелчком по кнопке справа от поля с надписями
развернуть окно «Аргументы функции».
Ø Щелкнуть по кнопке «ОК». В выбранной
предварительно ячейке появится среднее значение массива чисел.
2.4 Определение среднего квадратического
отклонения.
Вариационная кривая имеет
определенную ширину. Нетрудно догадаться, что чем больше ширина вариационной
кривой, тем сильнее разброс значений относительно средней величины.


Как показано на рисунках 5 и 6 при
одном и том же среднем значении, равном 25.51, полигон первого рисунка шире
полигона второго.
Оценить
степень разброса данных относительно среднего значения можно рассчитав значение
дисперсии S2,
или среднее квадратическое отклонение S, равное корню квадратному из дисперсии. Дисперсией вариационного ряда называется
средняя арифметическая квадратов отклонений вариантов от их средней
арифметической. Значением среднего квадратического отклонения пользоваться
удобнее, так как оно выражается в тех же единицах, что и значение признака. Так
среднее квадратическое отклонение данных, представленных графически на первом
полигоне равно 3.70, а на втором полигоне 2.65. Видим, что отклонение первое
больше второго и это как раз и отражается на ширине полигона.
Алгоритм
расчета среднего квадратического отклонения
и дисперсии такой же, как и для расчета среднего арифметического
значения, только в списке функций надо выбрать «СТАНДОТКЛОН» для вычисления отклонения, или «ДИСП» для расчета дисперсии.
Построение рядов распределения
Любой ряд распределения характеризуется двумя элементами:
— варианта(хi) – это отдельные значения признака единиц выборочной совокупности. Для вариационного ряда варианта принимает числовые значения, для атрибутивного – качественные (например, х=«государственный служащий»);
— частота (ni) – число, показывающее, сколько раз встречается то или иное значение признака. Если частота выражена относительным числом (т.е. долей элементов совокупности, соответствующих данному значению варианты, в общем объеме совокупности), то она называется относительной частотойили частостью.
— дискретным, когда изучаемый признак характеризуется определенным числом (как правило целым).
— интервальным, когда определены границы «от» и «до» для непрерывно варьируемого признака. Интервальный ряд также строят если множество значений дискретно варьируемого признака велико.
Интервальный ряд может строиться как с интервалами равной длины (равноинтервальный ряд) так и с неодинаковыми интервалами, если это диктуется условиями статистического исследования. Например, может рассматриваться ряд распределения доходов населения со следующими интервалами:
где k – число интервалов, n – объем выборки. (Конечно, формула обычно дает число дробное, а в качестве числа интервалов выбирается ближайшее целое к полученному число.) Длина интервала в таком случае определяется по формуле
При работе в Excel для построения вариационных рядов могут быть использованы следующие функции:
— СЧЁТ(массив данных) – для определения объема выборки. Аргументом является диапазон ячеек, в котором находятся выборочные данные.
— СЧЁТЕСЛИ(диапазон; критерий) – может быть использована для построения атрибутивного или вариационного ряда. Аргументами являются диапазон массива выборочных значений признака и критерий – числовое или текстовое значение признака или номер ячейки, в которой оно находится. Результатом является частота появления этого значения в выборке.
Проиллюстрируем процесс первичной обработки данных на следующих примерах.
Пример 1.1. имеются данные о количественном составе 60 семей.
Построить вариационный ряд и полигон распределения
Рис.1.1 Пример 1. Первичная обработка статистических данных в таблицах Excel

Далее, подготовим таблицу для построения вариационного ряда, введя названия для столбца интервалов (значений варианты) и столбца частот. В столбец интервалов введем значения признака от минимального (1) до максимального (6), заняв диапазон В12:В17. Выделим столбец частот, введем формулу =ЧАСТОТА(А1:L5;В12:В17) и нажмем сочетание клавиш CTRL+SHIFT+ENTER

Для контроля вычислим сумму частот при помощи функции СУММ (значок функции S в группе «Редактирование» на вкладке «Главная»), вычисленная сумма должна совпасть с ранее вычисленным объемом выборки в ячейке В7.
Теперь построим полигон: выделив полученный диапазон частот, выберем команду «График» на вкладке «Вставка». По умолчанию значениями на горизонтальной оси будут порядковые числа — в нашем случае от 1 до 6, что совпадает со значениями варианты (номерами тарифных разрядов).
Название ряда диаграммы «ряд 1» можно либо изменить, воспользовавшись той же опцией «выбрать данные» вкладки «Конструктор», либо просто удалить.

Пример 1.2. Имеются данные о выбросах загрязняющих веществ из 50 источников:
| 10,4 | 18,6 | 10,3 | 26,0 | 45,0 | 18,2 | 17,3 | 19,2 | 25,8 | 18,7 |
| 28,2 | 25,2 | 18,4 | 17,5 | 41,8 | 14,6 | 10,0 | 37,8 | 10,5 | 16,0 |
| 18,1 | 16,8 | 38,5 | 37,7 | 17,9 | 29,0 | 10,1 | 28,0 | 12,0 | 14,0 |
| 14,2 | 20,8 | 13,5 | 42,4 | 15,5 | 17,9 | 19, | 10,8 | 12,1 | 12,4 |
| 12,9 | 12,6 | 16,8 | 19,7 | 18,3 | 36,8 | 15,0 | 37,0 | 13,0 | 19,5 |
Составить равноинтервальный ряд, построить гистограмму
Внесем массив данных в лист Excel, он займет диапазон А1:J5 Как и в предыдущей задаче, определим объем выборки n, минимальное и максимальное значения в выборке. Поскольку теперь требуется не дискретный, а интервальный ряд, и число интервалов в задаче не задано, вычислим число интервалов k по формуле Стерджесса. Для этого в ячейку В10 введем формулу =1+3,322*LOG10(B7).
Рис.1.4. Пример 2. Построение равноинтервального ряда

Полученное значение не является целым, оно равно примерно 6,64. Поскольку при k=7 длина интервалов будет выражаться целым числом (в отличие от случая k=6) выберем k=7, введя это значение в ячейку С10. Длину интервала d вычислим в ячейке В11, введя формулу =(В9-В8)/С10.
Рис.1.5. Пример 2. Построение равноинтервального ряда

Теперь заполним массив «карманов» при помощи функции ЧАСТОТА, как это было сделано в примере 1.
Рис.1.6. Пример 2. Построение равноинтервального ряда


Мнение эксперта
Витальева Анжела, консультант по работе с офисными программами
Со всеми вопросами обращайтесь ко мне!
Задать вопрос эксперту
Если выбор количества интервалов или их диапазонов не устраивает, то можно в диалоговом окне указать нужный массив интервалов если интервал карманов включает текстовый заголовок, то нужно установить галочку напротив поля Метка. Если же вам нужны дополнительные объяснения, обращайтесь ко мне!
Расчет ширины интервала и таблица интервалов приведены в файле примера на листе Гистограмма . Для вычисления количества значений, попадающих в каждый интервал, использована формула массива на основе функции ЧАСТОТА() . О вводе этой функции см. статью Функция ЧАСТОТА() – Подсчет ЧИСЛОвых значений в MS EXCEL .

Для построений необходимо выделить всю таблицу вместе с заголовком и выполнить команду вкладка Вставка — инструмент Точечная. Выбираем вариант Точечная с гладкими кривыми и маркерами как более показательный.
| 10,4 | 18,6 | 10,3 | 26,0 | 45,0 | 18,2 | 17,3 | 19,2 | 25,8 | 18,7 |
| 28,2 | 25,2 | 18,4 | 17,5 | 41,8 | 14,6 | 10,0 | 37,8 | 10,5 | 16,0 |
| 18,1 | 16,8 | 38,5 | 37,7 | 17,9 | 29,0 | 10,1 | 28,0 | 12,0 | 14,0 |
| 14,2 | 20,8 | 13,5 | 42,4 | 15,5 | 17,9 | 19, | 10,8 | 12,1 | 12,4 |
| 12,9 | 12,6 | 16,8 | 19,7 | 18,3 | 36,8 | 15,0 | 37,0 | 13,0 | 19,5 |
Стиль и внешний вид гистограммы
После того, как вы создали гистограмму, вам может потребоваться внести корректировки в то, как выглядит ваш график. Для изменения дизайна и стиля используйте вкладку “Конструктор”. Эта вкладка отображается на Панели инструментов, когда вы выделяете левой клавишей мыши гистограмму. С помощью дополнительных настроек в разделе “Конструктор” вы сможете:
- добавить заголовок и другие дополнительные данные для отображения. Для того, чтобы добавить данные на график, кликните на пункт “Добавить элемент диаграммы”, затем, выберите нужный пункт из выпадающего списка:




Вы также можете использовать кнопки быстрого доступа к редактированию элементов гистограммы, стиля и фильтров:

Мнение эксперта
Витальева Анжела, консультант по работе с офисными программами
Со всеми вопросами обращайтесь ко мне!
Задать вопрос эксперту
Получили следующий набор данных 18,38,28,29,26,38,34,22,28,30,22,23,35,33,27,24,30,32,28,25,29,26,31,24,29,27,32,24,29,29 Постройте интервальный ряд и исследуйте его. Если же вам нужны дополнительные объяснения, обращайтесь ко мне!
Например:
Для распределения учеников по росту получаем: begin S^2=fraccdot 104,1approx 105,1\ sapprox 10,3 end Коэффициент вариации: $ V=fraccdot 100textapprox 6,0textlt 33text $ Выборка однородна. Найденное значение среднего роста (X_)=171,7 см можно распространить на всю генеральную совокупность (старшеклассников из других школ).
Интервальный вариационный ряд и его характеристики: построение, гистограмма, выборочная дисперсия и СКО
- автоматически рассчитаны интервалы значений (карманы);
- подсчитано количество значений из указанного массива данных, попадающих в каждый интервал (построена таблица частот);
- если поставлена галочка напротив пункта Вывод графика , то вместе с таблицей частот будет выведена гистограмма.
Ряды распределения одна из разновидностей статистических рядов (кроме них в статистике используются ряды динамики), используются для анализа данных о явлениях общественной жизни. Построение вариационных рядов вполне посильная задача для каждого. Однако есть правила, которые необходимо помнить.
Задание
Для
случайной выборки объемом n=50
с несовпадающими числами выполнить
следующую последовательность действий:
1.Вывести
на лист Excel
исходные статистические данные.
2. Построить
вариационный ряд.
3. Вычислить
статистические характеристики.
4. Построить
интервальный статистический ряд.
5.Построить
гистограмму частот.
6. Составить
статистическую функцию распределения
статистического ряда.
7.
Составить и постоить статистическую
функцию распределения группированного
статистического ряда.
В качестве примера
рассмотрим следующую выборку

Порядок выполнения работы
1.Ввод исходных статистических данных.
Вводим данные в
первый столбец таблицы (рис.1).
рис.1
2. Построение вариационного ряда.
Производим
сортировку данных в порядке возрастания.
Для этого:
а) выделяем первый
столбец;
б)
на ленте
во вкладке «Данные» выбираем «Сортировка
и фильтр» (рис.2)
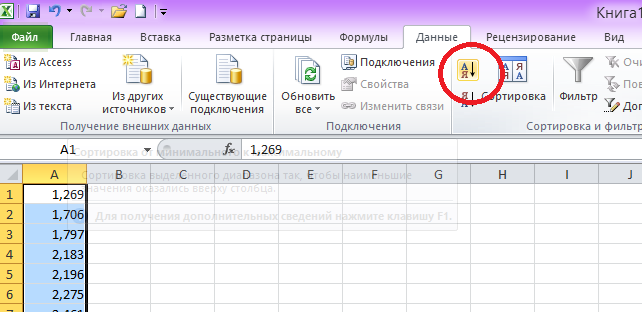
рис. 2
3. Вычисление статистических характеристик.
На ленте
во вкладке «Данные» выбираем «Анализ
данных» меню «Описательная статистика»
нажимаем ОК.
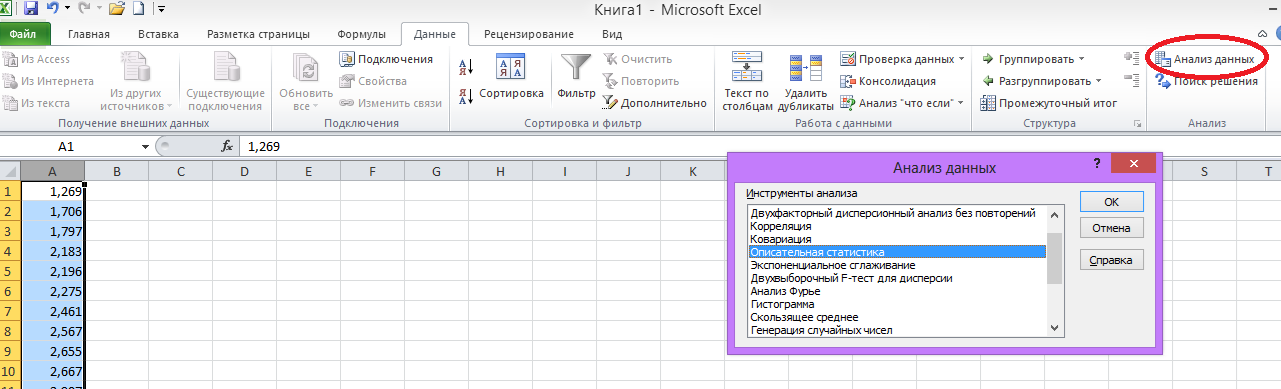
рис. 3
В пункт
«Входной интервал» вводим диапазон
ячеек с исходными данными $A$1:$A$50,
а в пункте «Выходной интервал» обозначим
первую ячейку для записи результаов
$C$1.
Ставим флажок напротив пункта «Итоговая
статистика» и нажимаем ОК.(рис.4)
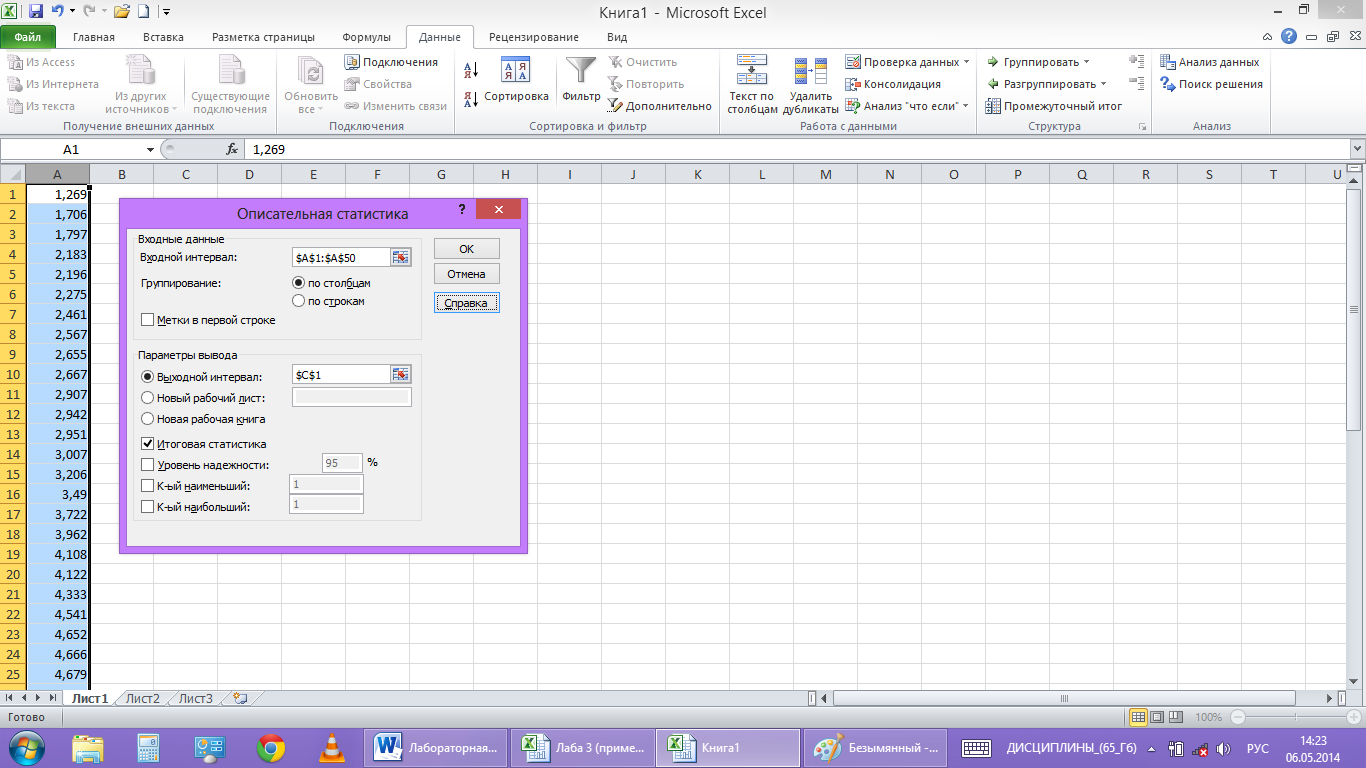
рис. 4
На
рабочем листе появляется таблица с
вычисленными значениями числовых
характеристик выборки (рис.5)
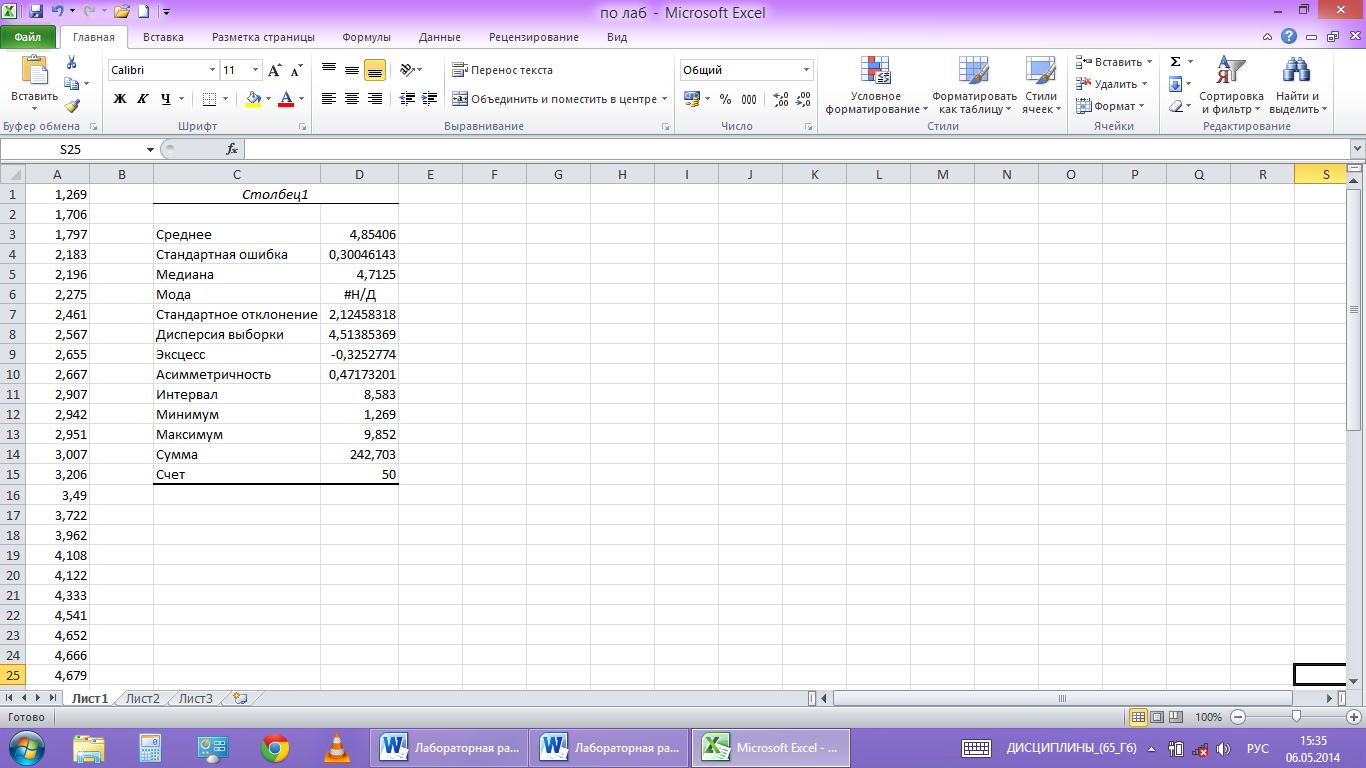
рис. 5
Здесь
«Среднее»означает математическое
ожидание выборки, а «Стандартная ошибка»
— погрешность ее значения. «Дисперсия
выборки» означает исправленную выборочную
дисперсию, а «Стандартное отклонение»
— исправленное среднее квадратичное
отклонение. Положительное значение
«Асимметричности» означает, что «длинная
часть» кривой лежит правее моды.
Отрицательное значение «Эксцесса»
означает, что кривая имеет более низкую
и «плоскую» вершину, чем нормальная
кривая. «Интервал» равен разности
Xmax−Xmin.
«Сумма»
дает результат суммирования всех
элементов выборки. «Счет» задает общее
число элементов выборки.
4. Построение интервального статистического ряда.
Длину интервала
группировки определяем по формуле

Необходимые данные
имеем в таблице: Xmax
– в ячейке D13,
Xmin–
в ячейке D12,
число элементов выборки n
— в ячейке D15.
В ячейку С16 вводим
слово «Интервал», в ячейку D16
вводим формулу
![]()
в ячейке D16
появится значение числа h.
В ячейку C17
вводим букву h.
В ячейку D17
вводим формулу
![]()
В ячейке
D17
получаем округленное до одного знака
после запятой значение интерала h.
Проведем формирование
интервалов. Для этого от Xmin
отступим влево примерно на h/2
и получим начальную точку отсчета.
Последовательно прибавляя к ней целое
число отрезков h,
получим все граничные точки интервалов.
В ячейку
F1
вводим формулу
![]()
В этой
ячейке появляется значение начальной
точки отсчета. В ячейку F2
вводим формулу
![]()
В этой
ячейке появляется значение второй
граничной точки первого интервала.
Возвращаемся в ячейку F2,
ставим курсор в правый нижний угол рамки
и двигаем его вниз, не отпуская левую
кнопку мыши. В результате такой процедуры
(протяжка) столбец F
заполнят граничные точки интервалов.
Самый нижний интервал должен включать
Xmax
(рис.6).
Проведем подсчет
числа вариант, попавших в каждый интервал,
определим относительные частоты и
серединные точки этих интервалов.
Для
этого на ленте во вкладке «Данные»
выбираем «Анализ данных» меню
«Гистограмма». (рис.
7)
|
|
|
|
рис. 6 |
рис. 7 |
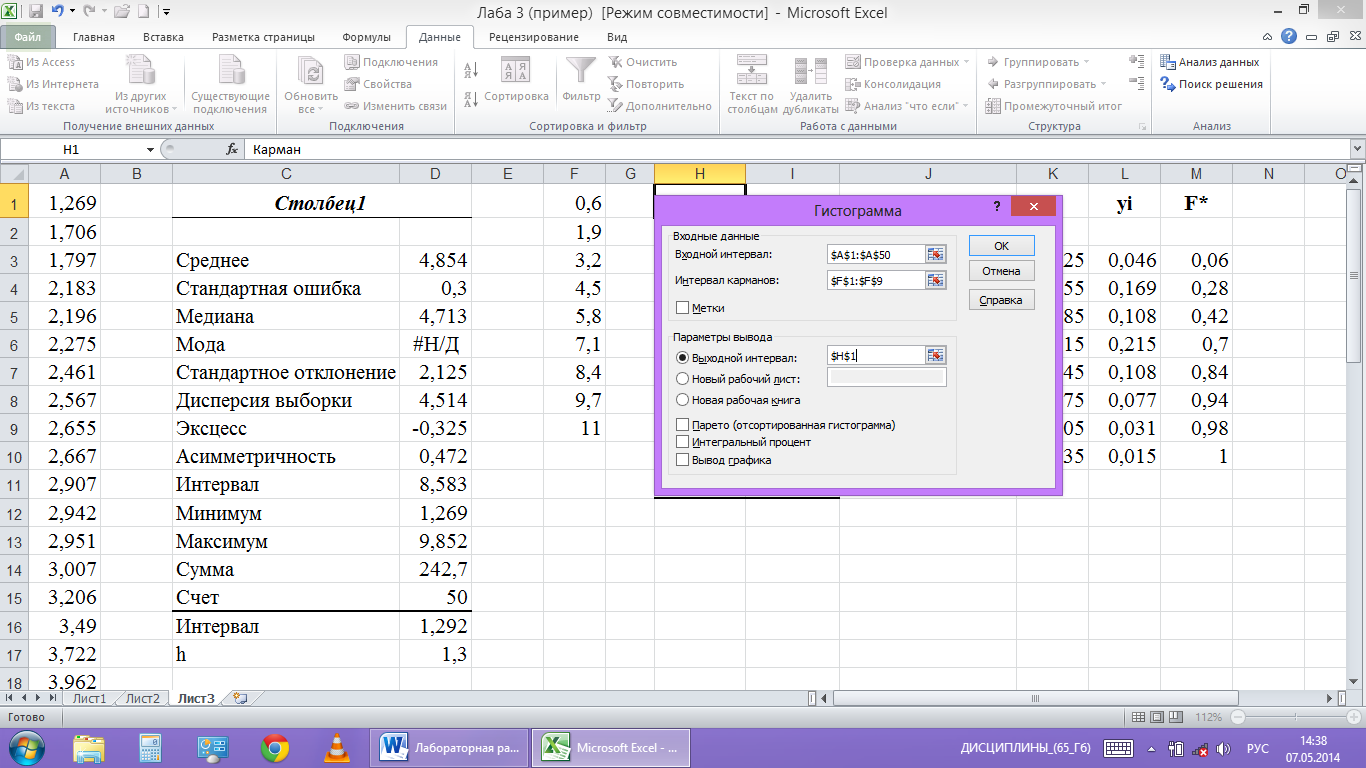
В пункт
«Входной интервал» вводим диапазон
ячеек с исходными данными $A$1:$A$50,
в пункт «Интервал карманов» — диапазон
ячеек с границами интервалов $F$1:$F$9.
Отметим точкой пункт «Выходной интервал»
и введем в него адрес первой ячейки для
записи результатов $Н$1. Появится таблица
из двух столбцов с обозначениями «Карман»
и «Частота» (рис.8).
Определим
относительные частоты рi*,
значения серединных точек интервалов
![]()
и высоты
прямоугольников
![]()
Для этого
-
в ячейку
J1
введем заголовок «Относительная
частота»; -
В ячейку
J3
введем формулу
![]()
и
протягиваем её вниз до ячейки J10.
В результате к таблице из двух столбцов
добавится третий столбец (рис.8). В этой
таблице частота появления случайной
величины в каждом интервале записана
в одной строке с концом интервала;
-
в ячейку
K1
введем заголовок столбца Х*; -
в ячейку
К3 введем формулу
![]()
Протягиваем
эту формулу до ячейки К10. В результате
в четвертом столбце таблицы (рис.8)
появятся значения серединных точек
интервалов;
-
в ячейку
L1
введем заголовок столбца Уi; -
в ячейку
L3
введем формулу
![]()
Протягиваем
её вниз до ячейки L10.
В
результате в пятом столбце таблицы
(рис.8) появятся значения Уi.
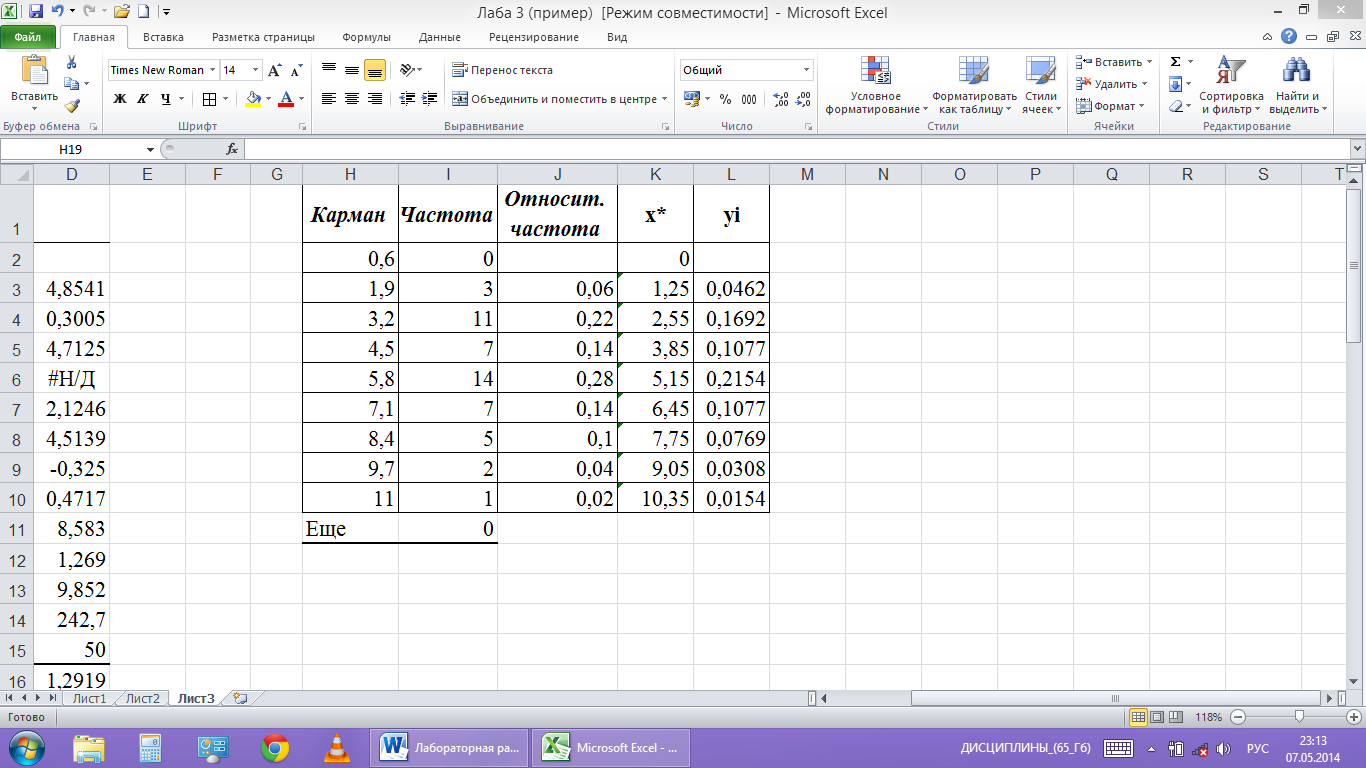
рис.8
Соседние файлы в папке Лаб.работы
- #
- #
- #
- #
- #
- #
- #
Как построить вариационный ряд в Excel
Вариационный ряд может быть:
— дискретным, когда изучаемый признак характеризуется определенным числом (как правило целым).
— интервальным, когда определены границы «от» и «до» для непрерывно варьируемого признака. Интервальный ряд также строят если множество значений дискретно варьируемого признака велико.
Рассмотрим пример построения дискретного вариационного ряда.
Пример 1. Имеются данные о количественном составе 60 семей.

Построить вариационный ряд и полигон распределения
Решение.
Алгоритм построения вариационного ряда:
1) Откроем таблицы Excel.
2) Введем массив данных в диапазон А1:L5. Если вы изучаете документ в электронной форме (в формате Word, например), для этого достаточно выделить таблицу с данными и скопировать ее в буфер, затем выделить ячейку А1 и вставить данные – они автоматически займут подходящий диапазон.
3) Подсчитаем объем выборки n – число выборочных данных, для этого в ячейку В7 введем формулу =СЧЁТ(А1:L5). Заметим, что для того, чтобы в формулу ввести нужный диапазон, необязательно вводить его обозначение с клавиатуры, достаточно его выделить.
4) Определим минимальное и максимальное значение в выборке, введя в ячейку В8 формулу =МИН(А1:L5), и в ячейку В9: =МАКС(А1:L5).
Рис.1.1 Пример 1. Первичная обработка статистических данных в таблицах Excel

5) Далее, подготовим таблицу для построения вариационного ряда, введя названия для столбца интервалов (значений варианты) и столбца частот. В столбец интервалов введем значения признака от минимального (1) до максимального (6), заняв диапазон В12:В17.
6) Выделим столбец частот, введем формулу =ЧАСТОТА(А1:L5;В12:В17) и нажмем сочетание клавиш CTRL+SHIFT+ENTER
Рис.1.2 Пример 1. Построение вариационного ряда

7) Для контроля вычислим сумму частот при помощи функции СУММ (значок функции S в группе «Редактирование» на вкладке «Главная»), вычисленная сумма должна совпасть с ранее вычисленным объемом выборки в ячейке В7.
Построим полигон:
1) выделив полученный диапазон частот, выберем команду «График» на вкладке «Вставка». По умолчанию значениями на горизонтальной оси будут порядковые числа — в нашем случае от 1 до 6, что совпадает со значениями варианты (номерами тарифных разрядов).
2) Название ряда диаграммы «ряд 1» можно либо изменить, воспользовавшись той же опцией «выбрать данные» вкладки «Конструктор», либо просто удалить.
Рис.1.3. Пример 1. Построение полигона частот

Примечание: можно скачать готовый шаблон построение дискретного вариационного ряда в Excel
Следующая тема: Построение интервального вариационного ряда в Excel.
17 авг. 2022 г.
читать 3 мин
Выборочное распределение — это вероятностное распределение определенной статистики , основанное на множестве случайных выборок из одной совокупности .
В этом руководстве объясняется, как выполнить следующие действия с выборочными распределениями в Excel:
- Сгенерируйте выборочное распределение.
- Визуализируйте распределение выборки.
- Рассчитайте среднее значение и стандартное отклонение выборочного распределения.
- Рассчитайте вероятности относительно выборочного распределения.
Создание выборочного распределения в Excel
Предположим, мы хотим сгенерировать выборочное распределение, состоящее из 1000 выборок, в каждой из которых размер выборки равен 20 и происходит от нормального распределения со средним значением 5,3 и стандартным отклонением 9 .
Мы можем легко сделать это, введя следующую формулу в ячейку A2 нашего рабочего листа:
= NORM.INV ( RAND (), 5.3, 9)
Затем мы можем навести указатель мыши на правый нижний угол ячейки, пока не появится крошечный + , и перетащить формулу на 20 ячеек вправо и на 1000 ячеек вниз:
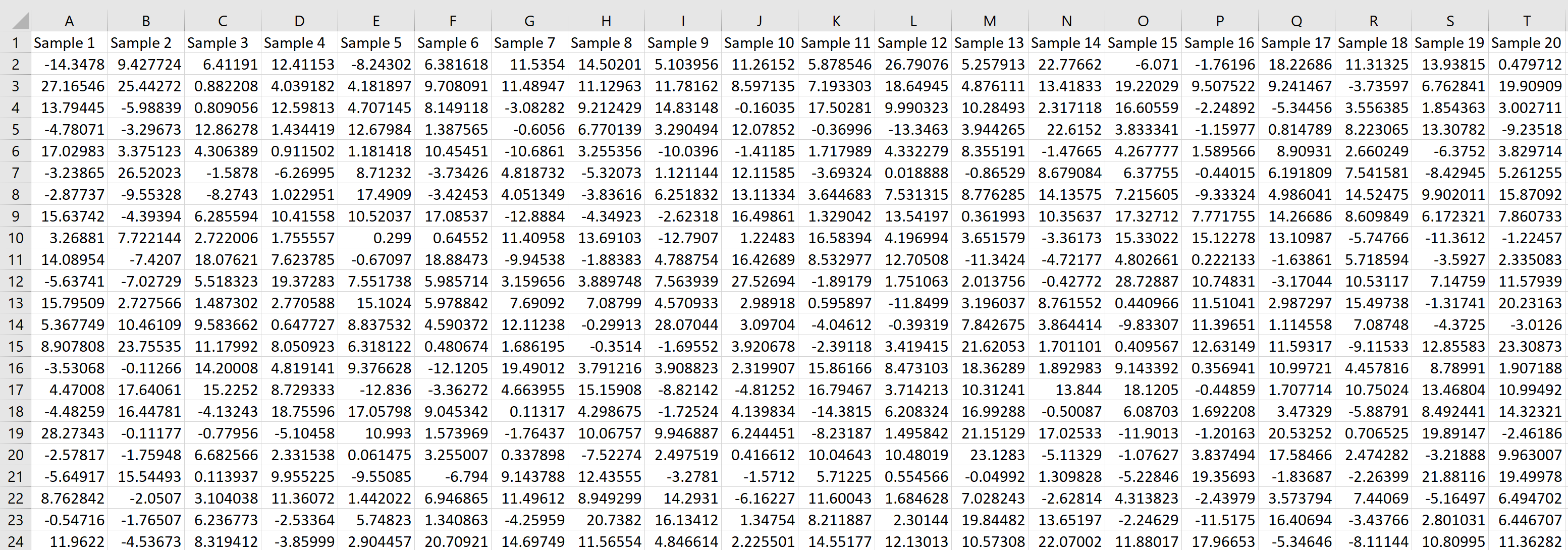
Каждая строка представляет выборку размера 20, в которой каждое значение получено из нормального распределения со средним значением 5,3 и стандартным отклонением 9.
Найдите среднее значение и стандартное отклонение
Чтобы найти среднее значение и стандартное отклонение этого выборочного распределения средних значений выборки, мы можем сначала найти среднее значение каждой выборки, введя следующую формулу в ячейку U2 нашего рабочего листа:
= AVERAGE (A2:T2)
Затем мы можем навести указатель мыши на правый нижний угол ячейки, пока не появится крошечный + , и дважды щелкнуть, чтобы скопировать эту формулу в каждую другую ячейку в столбце U:

Мы видим, что первая выборка имела среднее значение 7,563684, вторая выборка имела среднее значение 10,97299 и так далее.
Затем мы можем использовать следующие формулы для расчета среднего значения и стандартного отклонения среднего значения выборки:

Теоретически среднее значение выборочного распределения должно быть 5,3. Мы видим, что фактическое среднее значение выборки в этом примере равно 5,367869 , что близко к 5,3.
И теоретически стандартное отклонение выборочного распределения должно быть равно s/√n, что будет равно 9/√20 = 2,012. Мы видим, что фактическое стандартное отклонение выборочного распределения составляет 2,075396 , что близко к 2,012.
Визуализируйте распределение выборки
Мы также можем создать простую гистограмму для визуализации выборочного распределения выборочных средних.
Для этого просто выделите все средние значения выборки в столбце U, щелкните вкладку « Вставка », затем выберите параметр « Гистограмма » в разделе « Диаграммы ».
В результате получается следующая гистограмма:
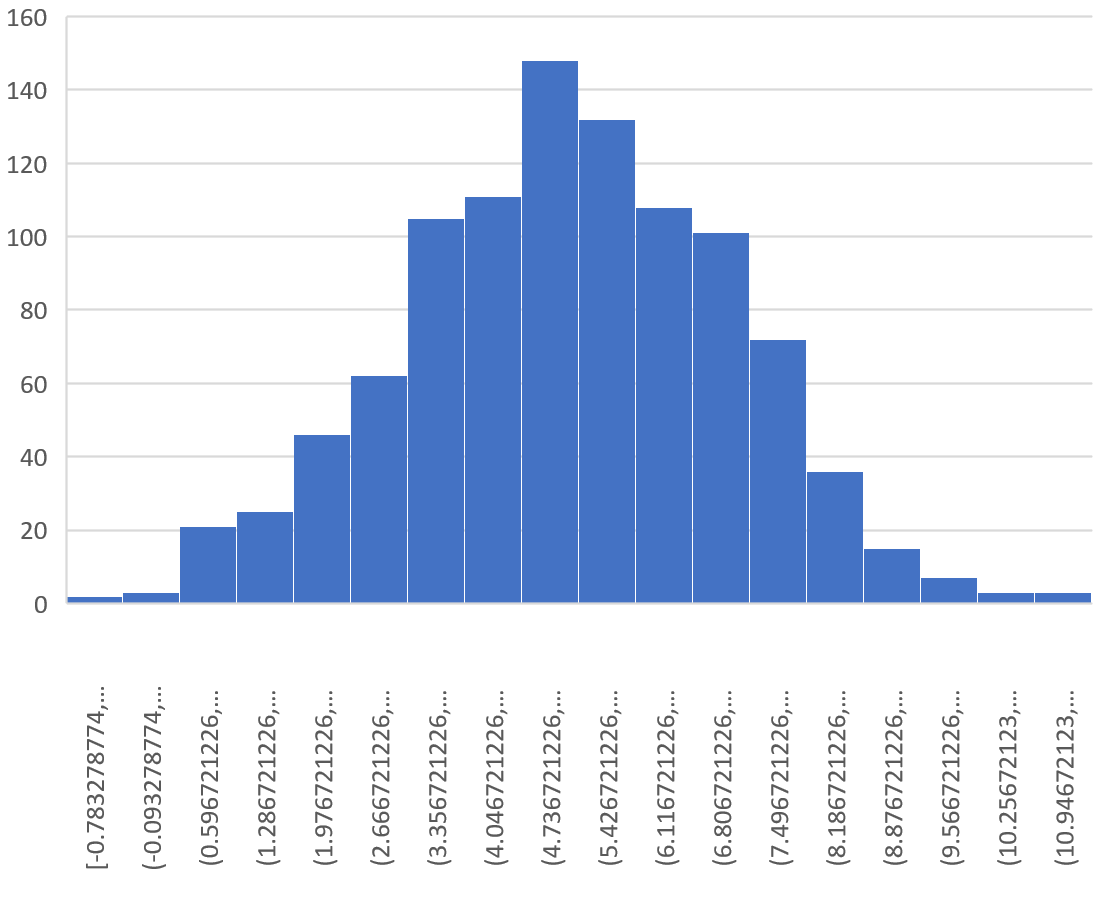
Мы видим, что распределение выборки имеет форму колокола с пиком около значения 5.
Однако из хвостов распределения мы можем видеть, что некоторые выборки имели средние значения больше 10, а некоторые — меньше 0.
Рассчитать вероятности
Мы также можем рассчитать вероятность получения определенного значения среднего значения выборки на основе среднего значения совокупности, стандартного отклонения совокупности и размера выборки.
Например, мы можем использовать следующую формулу, чтобы найти вероятность того, что среднее значение выборки меньше или равно 6, учитывая, что среднее значение генеральной совокупности равно 5,3, стандартное отклонение генеральной совокупности равно 9 и размер выборки равен:
= COUNTIF (U2:U1001, " <=6 ")/ COUNT (U2:U1001)
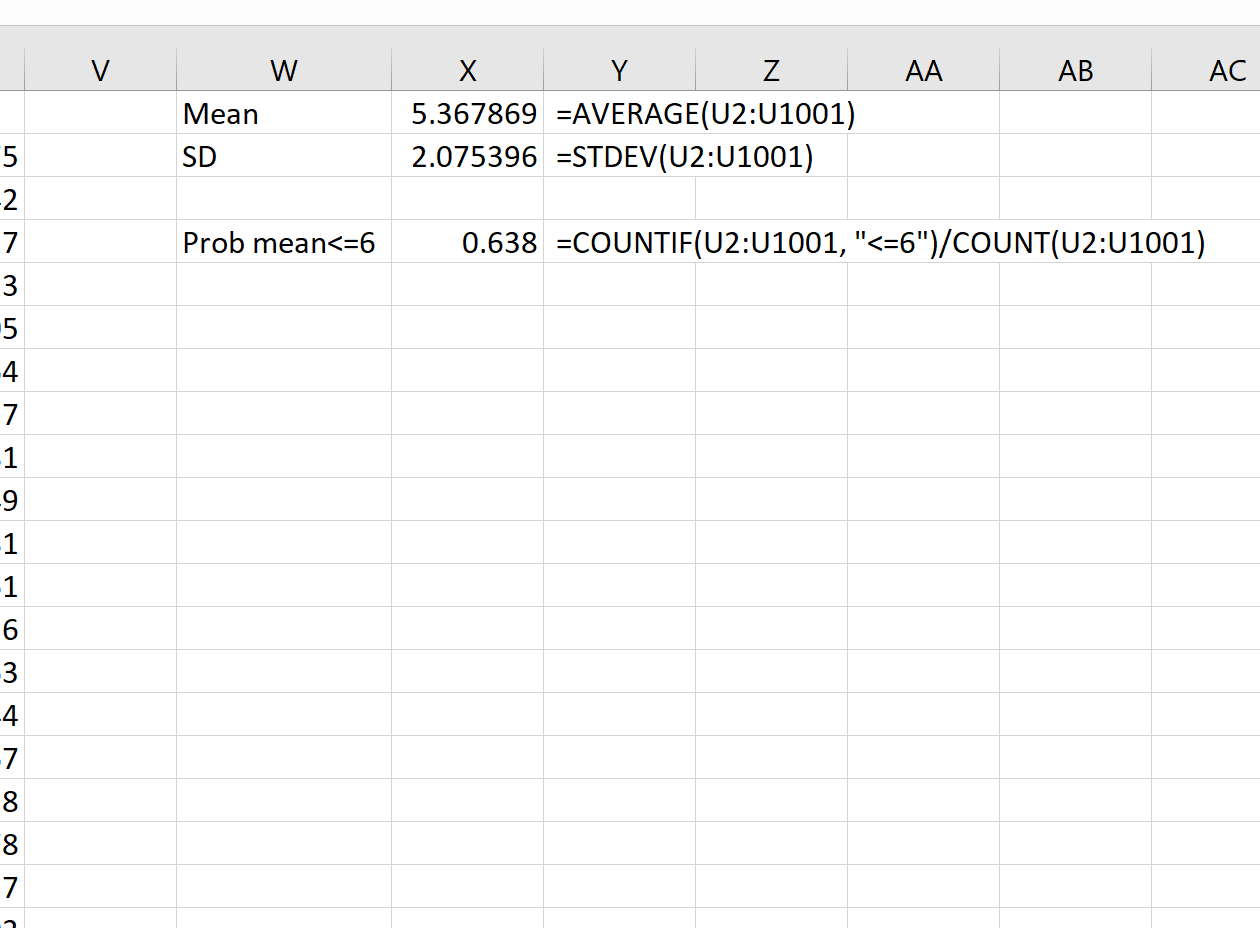
Мы видим, что вероятность того, что среднее значение выборки меньше или равно 6, составляет 0,638.
Это очень близко к вероятности, рассчитанной Калькулятором распределения выборки :

Дополнительные ресурсы
Введение в выборочные распределения
Калькулятор распределения выборки
Введение в центральную предельную теорему
На чтение 6 мин Просмотров 8к.
Содержание
- Выборочное среднее
- Математическое ожидание
- Примеры методов анализа числовых рядов в Excel
- Формула расчета линейного коэффициента вариации в Excel
Вычислим среднее значение выборки и математическое ожидание случайной величины в MS EXCEL.
Выборочное среднее
Среднее выборки или выборочное среднее (sample average, mean) представляет собой среднее арифметическое всех значений выборки.
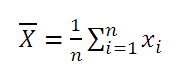
В MS EXCEL для вычисления среднего выборки можно использовать функцию СРЗНАЧ() . В качестве аргументов функции нужно указать ссылку на диапазон, содержащий значения выборки.
Выборочное среднее является «хорошей» (несмещенной и эффективной) точечной оценкой математического ожидания случайной величины (см. ниже), т.е. среднего значения исходного распределения, из которого взята выборка.
Примечание: О вычислении доверительных интервалов при оценке математического ожидания можно прочитать, например, в статье Доверительный интервал для оценки среднего (дисперсия известна) в MS EXCEL.
Некоторые свойства среднего арифметического:
- Сумма всех отклонений от среднего значения равна 0:
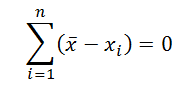
- Если к каждому из значений xi прибавить одну и туже константу с, то среднее арифметическое увеличится на такую же константу;
- Если каждое из значений xi умножить на одну и туже константу с, то среднее арифметическое умножится на такую же константу.
Математическое ожидание
Среднее значение можно вычислить не только для выборки, но для случайной величины, если известно ее распределение. В этом случае среднее значение имеет специальное название – Математическое ожидание. Математическое ожидание характеризует «центральное» или среднее значение случайной величины.
Примечание: В англоязычной литературе имеется множество терминов для обозначения математического ожидания: expectation, mathematical expectation, EV (Expected Value), average, mean value, mean, E[X] или first moment M[X].
Если случайная величина имеет дискретное распределение, то математическое ожидание вычисляется по формуле:
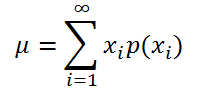
где xi – значение, которое может принимать случайная величина, а р(xi) – вероятность, что случайная величина примет это значение.
Если случайная величина имеет непрерывное распределение, то математическое ожидание вычисляется по формуле:
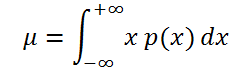
где р(x) – плотность вероятности (именно плотность вероятности, а не вероятность, как в дискретном случае).
Для каждого распределения, из представленных в MS EXCEL, Математическое ожидание можно вычислить аналитически, как функцию от параметров распределения (см. соответствующие статьи про распределения). Например, для Биномиального распределения среднее значение равно произведению его параметров: n*p (см. файл примера ).
Функция СРОТКЛ в Excel используется для анализа числового ряда, передаваемого в качестве аргумента, и возвращает число, соответствующее среднему значению, рассчитанному для модулей отклонений относительно среднего арифметического для исследуемого ряда.
Смысл данной функции становится предельно ясен после рассмотрения примера. Допустим, на протяжении суток каждые 3 часа фиксировались показатели температуры воздуха. Был получен следующий ряд значений: 16, 14, 17, 21, 25, 26, 22, 18. С помощью функции СРЗНАЧ можно определить среднее значение температуры – 19,88 (округлим до 20).
Для определения отклонения каждого значения от среднего необходимо вычесть из него полученное среднее значение. Например, для первого замера температуры это будет равно 16-20=-4. Получаем ряд значений: -4, -6, -3, 1, 5, 6, 2, -2. Поскольку СРОТКЛ по определению работает с модулями отклонений, итоговый ряд значений имеет вид: 4, 6, 3, 1, 5, 6, 2, 2. Теперь нужно получить среднее значение для данного ряда с помощью функции СРЗНАЧ – примерно 3,63. Именно таков алгоритм работы рассматриваемой функции.
Таким образом, значение, вычисляемое функцией СРОТКЛ, можно рассчитать с помощью формулы массива без использования этой функции. Допустим, перечисленные результаты замеров температур записаны в столбец (ячейки A1:A8). Тогда для определения среднего значения отклонений можно использовать формулу =СРЗНАЧ(ABS(A1:A8-СРЗНАЧ(A1:A8))). Однако, рассматриваемая функция значительно упрощает расчеты.
Пример 1. Имеются два ряда значений, представляющих собой результаты наблюдений одного и того же физического явления, сделанные в ходе двух различных экспериментов. Определить, среднее отклонение от среднего значения результатов для какого эксперимента является максимальным?
Вид таблицы данных:
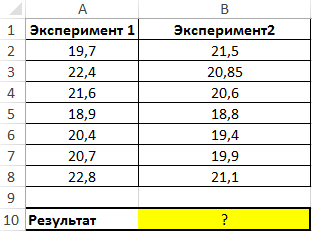
Используем следующую формулу:
Сравниваем результаты, возвращаемые функцией СРОТКЛ для первого и второго ряда чисел с использованием функции ЕСЛИ, возвращаем соответствующий результат.
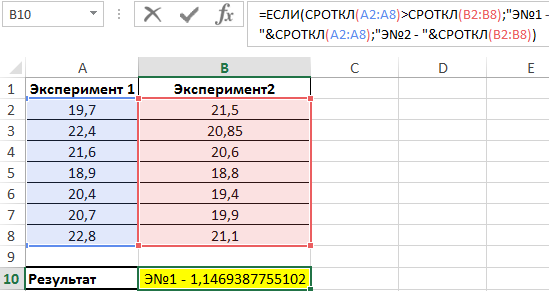
В результате мы получили среднее отклонение от среднего значения. Это весьма интересная функция для технического анализа финансовых рынков, прогнозов курсов валют и даже позволяет повысить шансы выигрышей в лотереях.
Формула расчета линейного коэффициента вариации в Excel
Пример 2. Студенты сдали экзамены по различным предметам. Определить число студентов, которые удовлетворяют следующему критерию успеваемости – линейный коэффициент вариации оценок не превышает 15%.
Вид таблицы данных:
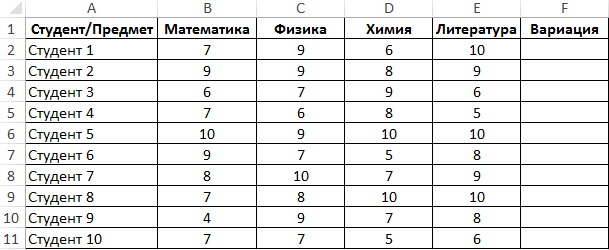
Линейный коэффициент вариации определяется как отношение среднего отклонения к среднему значению. Для расчета используем следующую формулу:
Растянем ее вниз по столбцу и получим следующие значения:
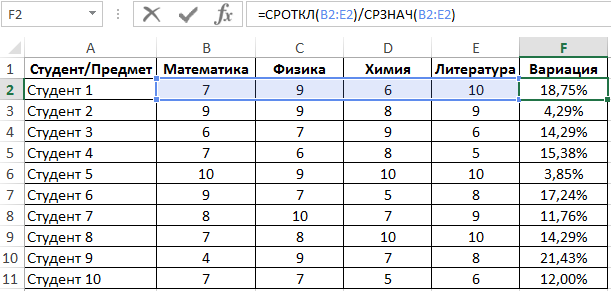
Для определения числа неуспешных студентов по указанному критерию используем функцию:
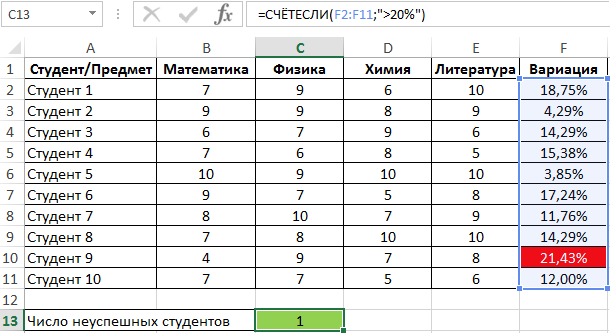
Правила использования функции СРОТКЛ в Excel
Функция имеет следующий синтаксис:
=СРОТКЛ( число1 ;[число2];. )
- число1 – обязательный, принимает числовое значение, характеризующее первый член ряда значений, для которых необходимо определить среднее отклонение от среднего;
- [число2];… – необязательный, принимает второе и последующие значения из исследуемого числового ряда.
- При использовании функции СРОТКЛ удобнее задавать первый аргумент в виде ссылки на диапазон ячеек, например =СРОТКЛ(A1:A8) вместо перечисления (=СРОТКЛ(A1;A2:A3…;A8)).
- В качестве аргумента функции может быть передана константа массива, например =СРОТКЛ(<2;5;4;7;10>).
- Для получения достоверного результата необходимо привести все значения ряда к единой системе измерения величин. Например, если часть длин указана в мм, а остальные – в см, результат расчетов будет некорректен. Необходимо преобразовать все значения в мм или см соответственно.
- Если в качестве аргументов функции переданы нечисловые данные, которые не могут быть преобразованы к числам, функция вернет код ошибки #ЧИСЛО!. Если хотя бы одно значение из ряда является числовым, функция выполнит расчет, не возвращая код ошибки.
- Не преобразуемые к числам текстовые строки и пустые ячейки не учитываются в расчете. Если ячейка содержит значение 0 (нуль), оно будет учтено.
- Логические данные автоматически преобразуются к числовым: ИСТИНА – 1, ЛОЖЬ – 0 соответственно.
1. Вычислить математическое ожидание:
1) Пуск > Все программы > Microsoft Office > Microsoft Excel
2) Так как функция математического ожидания это т оже самое, что и функция среднего арифметического, то: в пустой ячейке вводим «=», далее нажимаем fx, выбираем функцию СРЗНАЧ, выделяем числовые данные нашей исходной таблицы.
2. Вычислить дисперсию:
Вводим =, далее – fx, “Статистические” – “ДИСП”, выделить числовые данные нашей исходной таблицы.
3. Среднее квадратичесое отклонение (не смещённое):
Вводим =, далее – fx, “Статистические” – “СТАНДТОТКЛОН”, выделить числовые данные нашей исходной таблицы.
4. Среднее квадратическое отклонение (смещённое):
Вводим =, далее – fx, “Статистические” – “СТАНДТОТКЛОН”, выделить числовые данные нашей исходной таблицы.
Вывод: Microsoft Excel является одной из самых удобных компьютерных программ, с помощью которых можно высчитать статические данные. В этом я убедился, когда высчитывал вышеуказанные данные.
1. Построение вариационного ряда
Нужно выделить ячейки содержащие результаты эксперимента, и воспользоваться операцией сортировка по возрастанию (либо с панели инструментов, либо через главное меню Данные>Сортировка), и в появившемся окне сообщения – «обнаружены данные выходящие за пределы выделенного диапазона» выбрать действие – «сортировать в пределах указанного выделения»
2. Построение группировочного статистического ряда
Для вычисления абсолютной частоты нужна статистическая функция ЧАСТОТА. При её использовании нужно выполнить следующие действия:
а) выделить весь диапазон ячеек, в которых будет располагаться результат подсчёта частот (т.е. это ячейки под заголовком Абсолютная частота в количестве равном числу промежутков)
b) не снимая выделения, поставить курсор в строку формул и нажать на кнопку вставка функции (чуть левее курсора) или Главное меню – вставка – формула.
с) выбрать функцию ЧАСТОТА
d) ввести Массив_данных – диапазон, содержащий элементы выборки (в файле 2.xls это ячейки) B2:B101
e) ввести Массив_интервалов – диапазон ячеек под заголовком Начало промежутка начиная со строчки, соответствующей промежутку под номером 2 до строчки, соответствующей последнему промежутку.
f) нажмите на кнопку ОК и после закрытия окна для ввода аргументов функции ЧАСТОТА поставьте курсор обратно в строку формул.
g) Нажмите на три кнопки Ctrl+Shift+Enter (сначала на первые две, а потом, не отпуская их, нажмите на Enter).
Примечание. Формулу вычисления абсолютной частоты необходимо ввести как формулу массива. Нажатие комбинации клавиш CTRL+SHIFT+ENTER позволяет определить формулу как формулу массива. Если формула не будет введена как формула массива, единственное значение будет равно 1.
В результате изначально выделенный диапазон будет содержать абсолютные частоты попадания во все промежутка. Проверьте, что сумма всех абсолютных частот равна общему числу элементов выборки (100).
3. Построение гистограммы группировочного статистического ряда