
Содержание
- Как рассчитать распределения выборки в Excel
- Создание выборочного распределения в Excel
- Найдите среднее значение и стандартное отклонение
- Визуализируйте распределение выборки
- Рассчитать вероятности
- Как построить вариационный ряд в excel
Как рассчитать распределения выборки в Excel
Выборочное распределение — это вероятностное распределение определенной статистики , основанное на множестве случайных выборок из одной совокупности .
В этом руководстве объясняется, как выполнить следующие действия с выборочными распределениями в Excel:
- Сгенерируйте выборочное распределение.
- Визуализируйте распределение выборки.
- Рассчитайте среднее значение и стандартное отклонение выборочного распределения.
- Рассчитайте вероятности относительно выборочного распределения.
Создание выборочного распределения в Excel
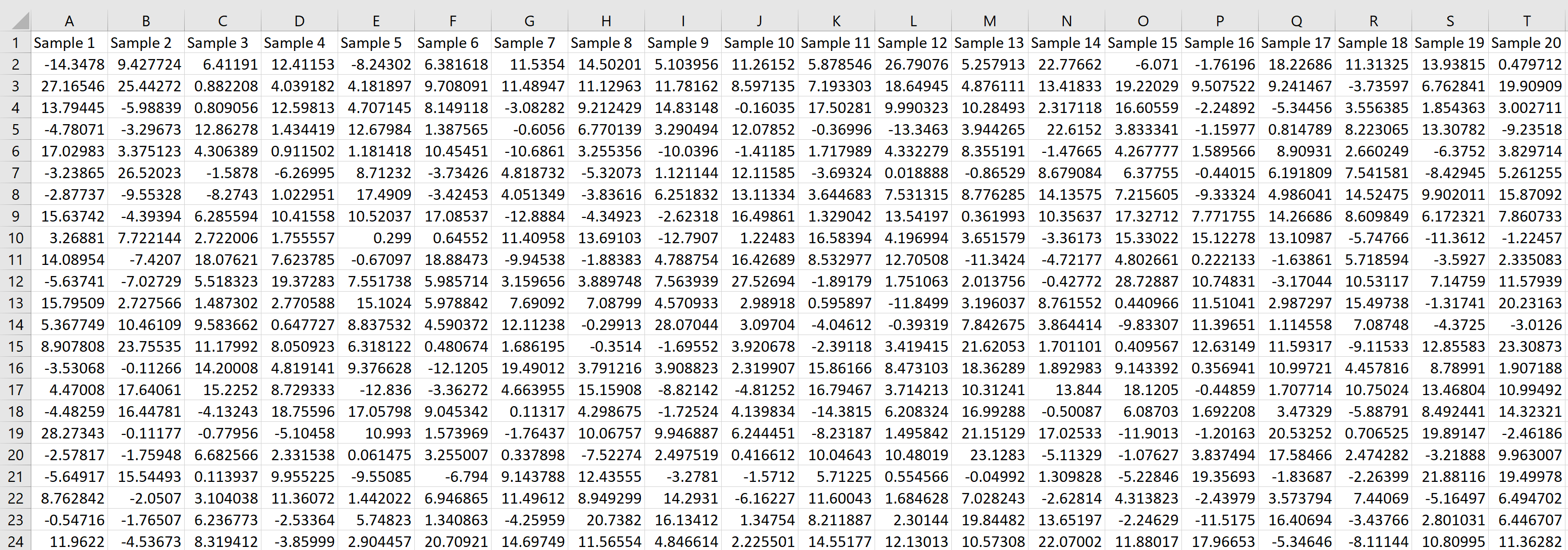
Предположим, мы хотим сгенерировать выборочное распределение, состоящее из 1000 выборок, в каждой из которых размер выборки равен 20 и происходит от нормального распределения со средним значением 5,3 и стандартным отклонением 9 .
Мы можем легко сделать это, введя следующую формулу в ячейку A2 нашего рабочего листа:
Затем мы можем навести указатель мыши на правый нижний угол ячейки, пока не появится крошечный + , и перетащить формулу на 20 ячеек вправо и на 1000 ячеек вниз:
Каждая строка представляет выборку размера 20, в которой каждое значение получено из нормального распределения со средним значением 5,3 и стандартным отклонением 9.
Найдите среднее значение и стандартное отклонение
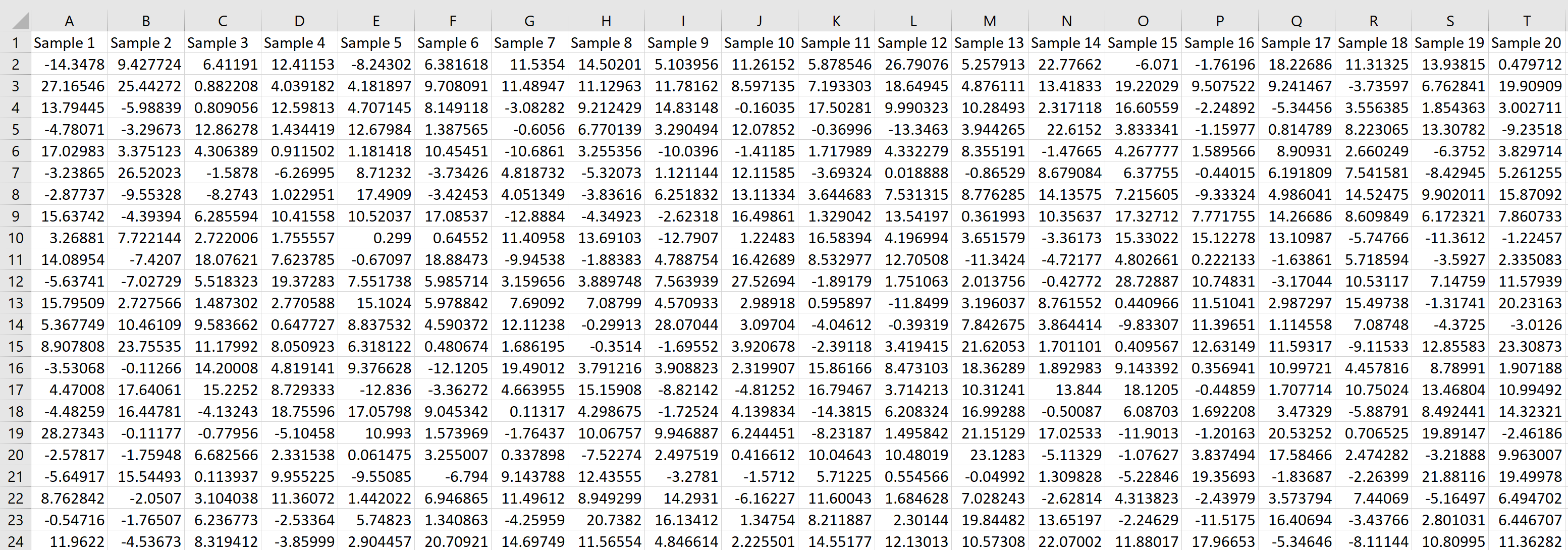
Чтобы найти среднее значение и стандартное отклонение этого выборочного распределения средних значений выборки, мы можем сначала найти среднее значение каждой выборки, введя следующую формулу в ячейку U2 нашего рабочего листа:
Затем мы можем навести указатель мыши на правый нижний угол ячейки, пока не появится крошечный + , и дважды щелкнуть, чтобы скопировать эту формулу в каждую другую ячейку в столбце U:

Мы видим, что первая выборка имела среднее значение 7,563684, вторая выборка имела среднее значение 10,97299 и так далее.
Затем мы можем использовать следующие формулы для расчета среднего значения и стандартного отклонения среднего значения выборки:

Теоретически среднее значение выборочного распределения должно быть 5,3. Мы видим, что фактическое среднее значение выборки в этом примере равно 5,367869 , что близко к 5,3.
И теоретически стандартное отклонение выборочного распределения должно быть равно s/√n, что будет равно 9/√20 = 2,012. Мы видим, что фактическое стандартное отклонение выборочного распределения составляет 2,075396 , что близко к 2,012.
Визуализируйте распределение выборки
Мы также можем создать простую гистограмму для визуализации выборочного распределения выборочных средних.
Для этого просто выделите все средние значения выборки в столбце U, щелкните вкладку « Вставка », затем выберите параметр « Гистограмма » в разделе « Диаграммы ».
В результате получается следующая гистограмма:
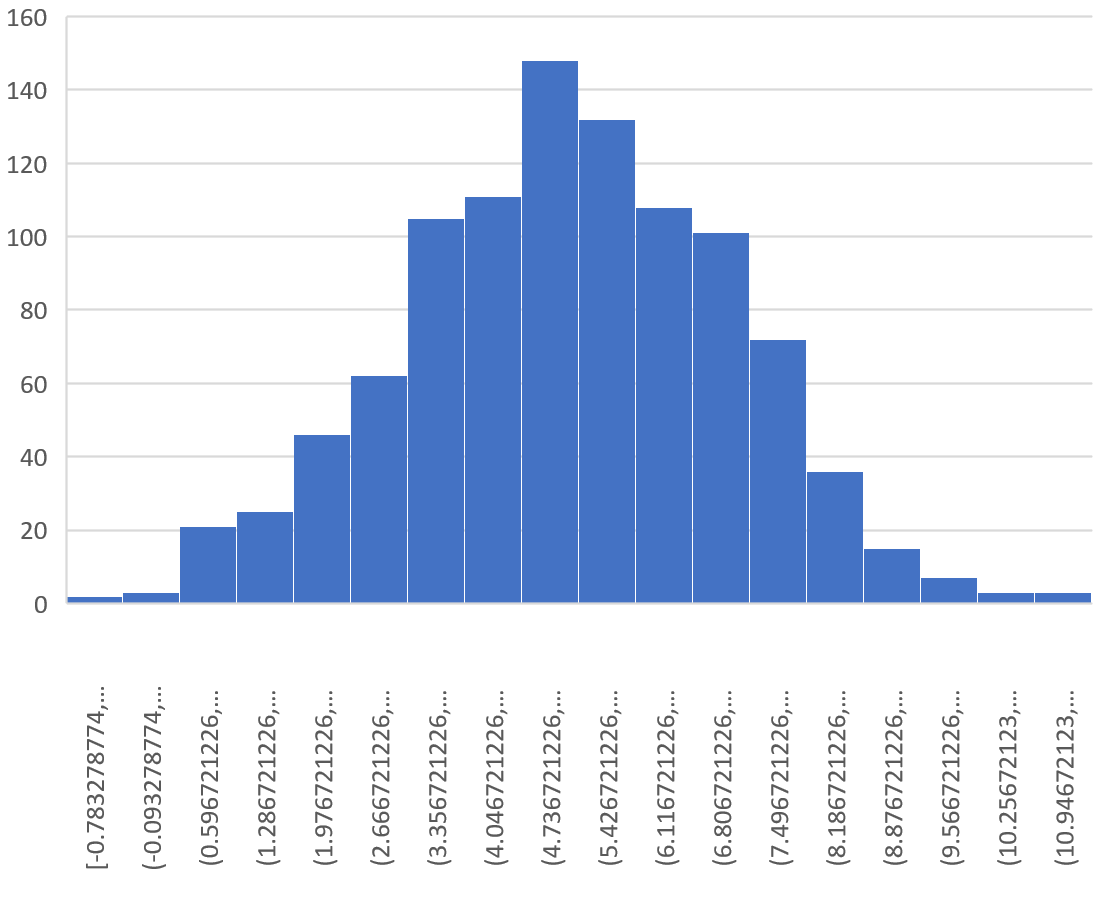
Мы видим, что распределение выборки имеет форму колокола с пиком около значения 5.
Однако из хвостов распределения мы можем видеть, что некоторые выборки имели средние значения больше 10, а некоторые — меньше 0.
Рассчитать вероятности
Мы также можем рассчитать вероятность получения определенного значения среднего значения выборки на основе среднего значения совокупности, стандартного отклонения совокупности и размера выборки.
Например, мы можем использовать следующую формулу, чтобы найти вероятность того, что среднее значение выборки меньше или равно 6, учитывая, что среднее значение генеральной совокупности равно 5,3, стандартное отклонение генеральной совокупности равно 9 и размер выборки равен:
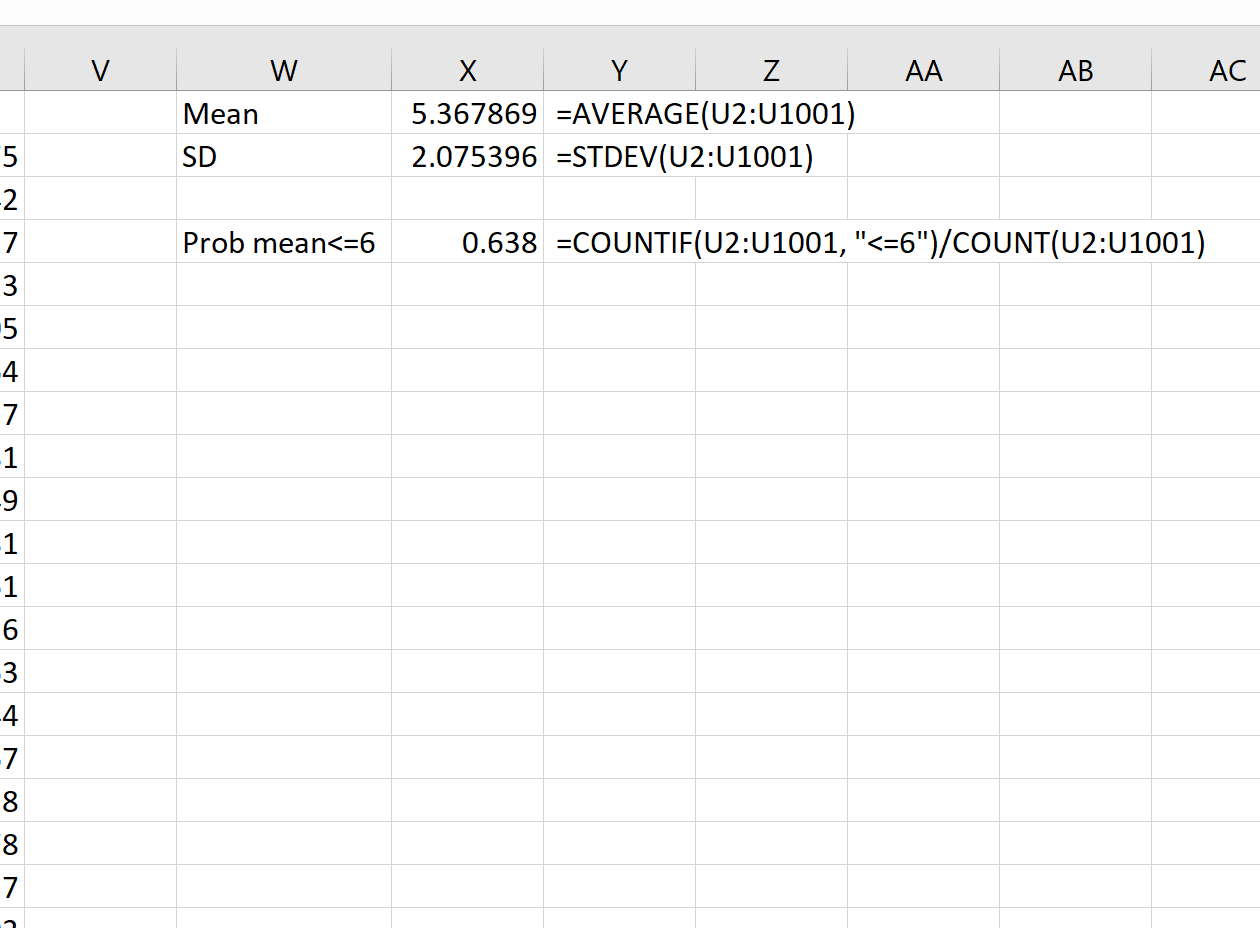
Мы видим, что вероятность того, что среднее значение выборки меньше или равно 6, составляет 0,638.
Это очень близко к вероятности, рассчитанной Калькулятором распределения выборки :
Источник
Как построить вариационный ряд в excel
При изучении величины, принимающей случайные значения (результатов физических измерений в серии экспериментов, экономических показателей, параметров технологических процессов и т.п.), мы имеем дело с выборками. Выборочное наблюдение – это способ наблюдения, при котором обследуется не вся совокупность значений изучаемой величины, а лишь часть ее, отобранная по определенным правилам выборки и обеспечивающая получение данных, характеризующих всю совокупность в целом.
При выборочном наблюдении обследованию подвергается определенная, заранее обусловленная часть совокупности, а результаты обследования распространяются на всю совокупность.
Ту часть единиц, которая отобрана для наблюдения, принято называть выборочной совокупностью или выборкой, а всю совокупность единиц, из которых производится отбор, – генеральной совокупностью.
Число единиц (элементов) статистической совокупности называется ее объемом. Объем генеральной совокупности обозначается N, а объем выборочной совокупности п.
Качество результатов выборочного наблюдения зависит от того, насколько состав выборки представляет генеральную совокупность, иначе говоря, от того, насколько выборка репрезентативна (представительна).
Элементами выборки (x1 х2, . хп) являются числовые значения, называемые вариантами, которые могут быть дискретными, т.е. изолированными (например, целыми числами), или могут принимать значения из некоторого интервала (а, b).
Вариационный ряд получается из выборки упорядочением по возрастанию (или убыванию) и подсчетом частоты каждого значения. Если вариационный ряд содержит значения признака и соответствующие ему частоты,то такой ряд носит название дискретный вариационный ряд. Если нам известно, что исследуемый показатель может принимать любые значения из некоторого интервала, то строим интервальный вариационный.
Удобнее всего ряды распределения анализировать с помощью их графического изображения, позволяющего судить о форме распределения. Наглядное представление о характере изменения частот вариационного ряда дают полигон и гистограмма.
Пример 2.1.
Известны следующие данные о результатах сдачи студентами экзамена (в баллах):
| 18 | 16 | 20 | 17 | 19 | 20 | 17 |
| 17 | 12 | 15 | 20 | 18 | 19 | 18 |
| 18 | 16 | 18 | 14 | 14 | 17 | 19 |
| 16 | 14 | 19 | 12 | 15 | 16 | 20 |
Необходимо построить ряд распределения числа студентов по баллу, представить графически результаты.
Введем данные в диапазоне A1: A29, в ячейку A1 введем текст «Балл» (рис.2.6).
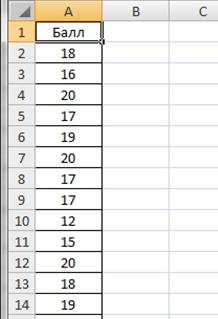
Рисунок 2.6. Баллы успеваемости студентов
Определим наименьший и наибольший балл по выборке. Для этого введем в ячейках С1 и С2 соответственно введем формулы =МИН(A2:A29) и =МАКС(A2:A29). Получим значения 12 и 20 соответственно (рис.2.7).
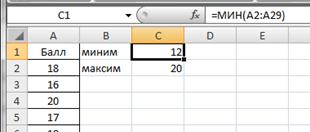
Рисунок 2.7. Минимальный и максимальный балл
Построим вариационный ряд. Для каждого значения необходимо подсчитать частоту. Так как значения признака (балл) отличаются на единицу, то можно воспользоваться следующим способом. В ячейку С4 введем формулу =С1, в С5 соответственно С4+1. Ячейку С5 протянем маркером заполнения (правый нижний угол ячейки) вниз до С12. Результаты представлены на рисунке 2.8.
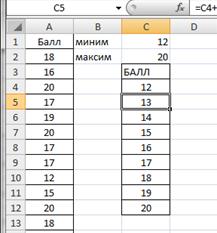
Рисунок 2.8. Значения признака
Вычислим частоту для каждого значения признака. В ячейку D4 введем формулу =СЧЕТЕСЛИ(A$2:A$29;C4) и протянем D4 маркером вниз до заполнения D12. В ячейке D13 просуммируем частоты с помощью формулы =СУММ(D4:D12).
Получим вариационный ряд (значения признака и соответствующие им частоты) на рисунке 2.9.
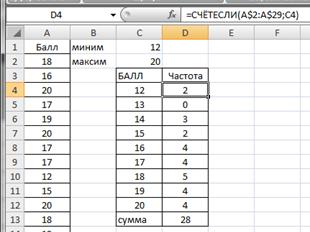
Рис.2.9. Частоты вариационного ряда
Вычислим частость (относительную частоту) для каждого значения признака. В ячейку Е4 введем формулу = D4/D$13. Протянем Е4 маркером заполнения вниз до Е12 (рис.2.10).
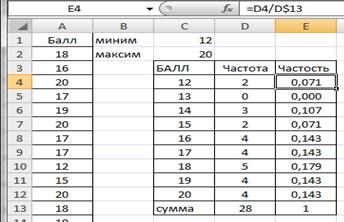
Рисунок 2.10. Частости ряда распределения
Вычислим накопленные частоты. В ячейку F4 введем формулу =D4, а в ячейку F5 – формулу = D5+F4. Протянем F5 маркером заполнения вниз до F12 (рис.2.11).
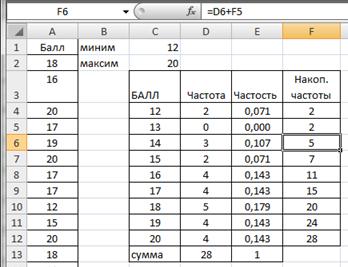
Рисунок 2.11. Накопленные частоты ряда
Построим эмпирическую функцию распределения, т.е. найдем наколенные частости. Выделим F4:F12 и маркером заполнения протянем вправо на соседний столбец (рис.2.12). В G4 получим формулу = Е4, в ячейке G5 формулу =Е5+ G4 и т.д.
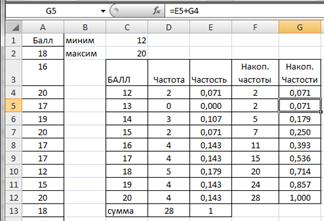
Рисунок 2.12. Накопленные частости ряда
Построим полигон распределения частот и частостей. Выделим диапазон ячеек С4:D12. Выполним команду меню «Диаграмма» и выберем тип «Точечная», вариант «Точечная с прямыми отрезками и маркерами». Полигон распределения частот представлен на рисунке 2.13.

Рисунок 2.13. Полигон распределения частот
Выделим диапазон ячеек С4:С12 и, удерживая клавишу CTRL, диапазон Е4:Е12. Выполним команду меню «Диаграмма» и выберем тип «Точечная», вариант «Точечная с прямыми отрезками и маркерами». Полигон распределения частостей представлен на рисунке 2.14.
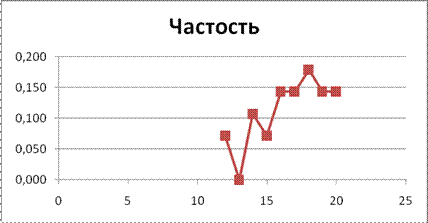
Рисунок 2.14. Полигон распределения частостей
Построим гистограмму распределения частостей, для чего выделим диапазон Е4:Е12, выберем тип диаграммы «Гистограмма». Щелкнем правой кнопкой в области диаграммы, выберем «Выбрать данные», выберете «Ряд» – «Изменить», левой кнопкой щелкнем в строке «Подписи оси Х» и выделим диапазон С4:С12 (рис.2.15).
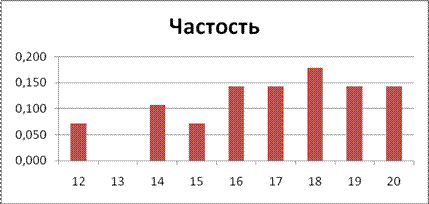
Рисунок 2.15. Гистограмма распределения частостей
Построим кумуляту частостей, для чего выделим диапазон ячеек С4:С12 и, удерживая клавишу CTRL, диапазон G4:G12. Выполним команду меню «Диаграмма» и выберем тип «Точечная», вариант «Точечная с прямыми отрезками». Кумулята представлена на рис.2.16.

Рисунок 2.16. Кумулята
Пример 2.2.
В таблице 2.7 представлены значения процентных ставок по кредитам по 30 коммерческим банкам.
Банковские процентные ставки
| № Банка | Процентная ставка, % |
| 1 | 20,3 |
| 2 | 17,1 |
| 3 | 14,2 |
| 4 | 11,0 |
| 5 | 17,3 |
| 6 | 19,6 |
| 7 | 20,5 |
| 8 | 23,6 |
| 9 | 14,6 |
| 10 | 17,5 |
| 11 | 20,8 |
| 12 | 13,6 |
| 13 | 24,0 |
| 14 | 17,5 |
| 15 | 15,0 |
| 16 | 21,1 |
| 17 | 17,6 |
| 18 | 15,8 |
| 19 | 18,8 |
| 20 | 22,4 |
| 21 | 16,1 |
| 22 | 17,9 |
| 23 | 21,7 |
| 24 | 18,0 |
| 25 | 16,4 |
| 26 | 26,0 |
| 27 | 18,4 |
| 28 | 16,7 |
| 29 | 12,2 |
| 30 | 13,9 |
Построим интервальный вариационный ряд. Для этого вычислим границы интервалов (карманов) с использованием формулы Стэрджесса.
Введем данные в диапазоне A1:A31 (рис.2.17). Определим максимальное и минимальное значения (ячейки С2 и С3 соответственно) так же как и в примере 2.1. Определим число интервалов по формуле Стэрджесса, для чего в ячейку С6 введем формулу =ЦЕЛОЕ(1+3,322*LOG10(30)) (рис.2.18).
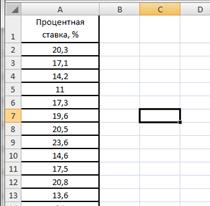
Рисунок 2.17. Процентные ставки банков

Рисунок 2.18. Число интервалов
Вычислим длину интервалов, для чего в ячейке С8 введем формулу =ОКРУГЛ((C3-C2)/C6;2) (рис.2.19).
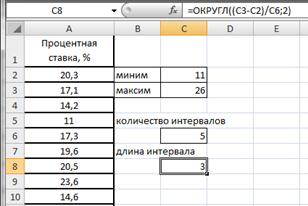
Рисунок 2.19. Длина интервала
Определим нижние и верхние границы интервалов (карманы), для чего в ячейке Е2 запишем формулу =С2, в ячейке Е3 запишем ==E2+$C$8. Протянем Е3 маркером заполнения вниз до Е7 (рис.2.20).
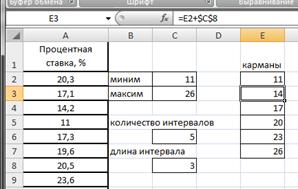
Рисунок 2.20. Границы интервалов
Подсчитаем частоты – в интервал считаем те значения, которые больше нижней границы интервала или равны ей и меньше верхней границы.
Воспользуемся функцией ЧАСТОТА. Для этого в ячейке F2 введем формулу =ЧАСТОТА(A2:A31;E2:E7). Протянем F2 маркером заполнения вниз до F8.
Формулу в этом примере необходимо ввести как формулу массива. Выделим диапазон F2:F8, нажмем клавишу F2, а затем нажмем клавиши CTRL+SHIFT+ВВОД (рис.2.21).
Если формула не будет введена как формула массива, отобразится только одно ее значение в ячейке F2.
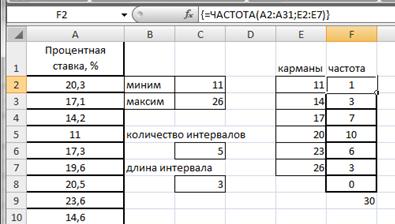
Рисунок 2.21. Частоты значений признака
Также можно воспользоваться средством Пакета анализа (Анализ данных в Office 2007) ГИСТОГРАММА (рис.2.22). Выберем входной интервал, интервал карманов, метки, интегральный процент, поместим результаты на этом же листе (укажем ячейку $H$2).
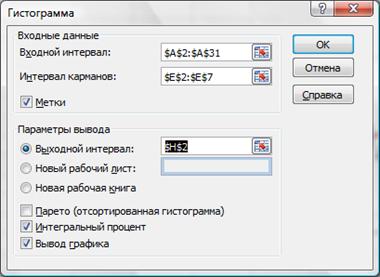
Рисунок 2.22. Построение гистограммы
Полученная гистограмма представлена на рис.2.23.
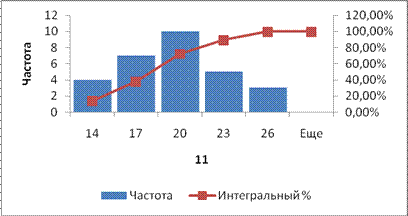
Рис.2.23. Гистограмма частот
Замечание. Если диапазон карманов не был введен, то набор отрезков, равномерно распределенных между минимальным и максимальным значениями данных, будет создан автоматически.
Дата добавления: 2018-11-12 ; просмотров: 1065 | Нарушение авторских прав
Вариационный ряд может быть:
– дискретным, когда изучаемый признак характеризуется определенным числом (как правило целым).
– интервальным, когда определены границы «от» и «до» для непрерывно варьируемого признака. Интервальный ряд также строят если множество значений дискретно варьируемого признака велико.
Рассмотрим пример построения дискретного вариационного ряда.
Пример 1. Имеются данные о количественном составе 60 семей.

Построить вариационный ряд и полигон распределения
Решение .
Алгоритм построения вариационного ряда:
1) Откроем таблицы Excel.
2) Введем массив данных в диапазон А1:L5. Если вы изучаете документ в электронной форме (в формате Word, например), для этого достаточно выделить таблицу с данными и скопировать ее в буфер, затем выделить ячейку А1 и вставить данные – они автоматически займут подходящий диапазон.
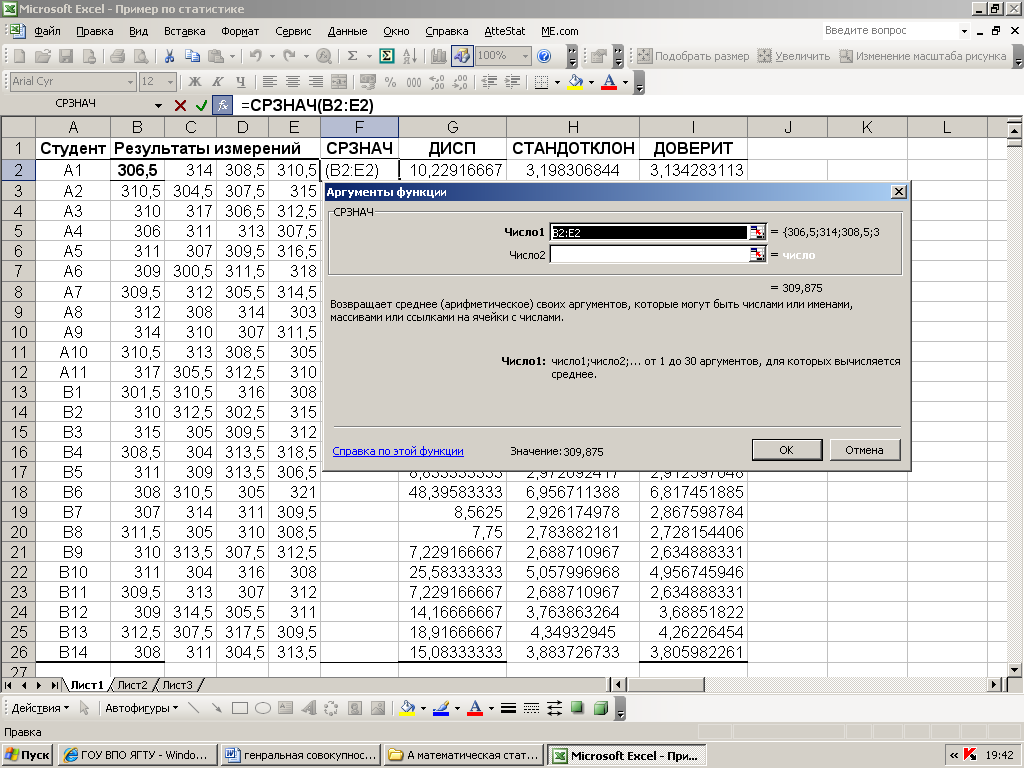
3) Подсчитаем объем выборки n – число выборочных данных, для этого в ячейку В7 введем формулу =СЧЁТ(А1:L5). Заметим, что для того, чтобы в формулу ввести нужный диапазон, необязательно вводить его обозначение с клавиатуры, достаточно его выделить.
4) Определим минимальное и максимальное значение в выборке, введя в ячейку В8 формулу =МИН(А1:L5), и в ячейку В9: =МАКС(А1:L5).
Рис.1.1 Пример 1. Первичная обработка статистических данных в таблицах Excel

5) Далее, подготовим таблицу для построения вариационного ряда, введя названия для столбца интервалов (значений варианты) и столбца частот. В столбец интервалов введем значения признака от минимального (1) до максимального (6), заняв диапазон В12:В17.
6) Выделим столбец частот, введем формулу =ЧАСТОТА(А1:L5;В12:В17) и нажмем сочетание клавиш CTRL+SHIFT+ENTER
Рис.1.2 Пример 1. Построение вариационного ряда

7) Для контроля вычислим сумму частот при помощи функции СУММ (значок функции S в группе «Редактирование» на вкладке «Главная»), вычисленная сумма должна совпасть с ранее вычисленным объемом выборки в ячейке В7.
Построим полигон:
1) выделив полученный диапазон частот, выберем команду «График» на вкладке «Вставка». По умолчанию значениями на горизонтальной оси будут порядковые числа – в нашем случае от 1 до 6, что совпадает со значениями варианты (номерами тарифных разрядов).
2) Название ряда диаграммы «ряд 1» можно либо изменить, воспользовавшись той же опцией «выбрать данные» вкладки «Конструктор», либо просто удалить.
Рис.1.3. Пример 1. Построение полигона частот
В реальных социально-экономических системах нельзя проводить активные эксперименты, поэтому данные обычно представляют собой наблюдения за происходящим процессом, например: курс валюты на бирже в течение месяца, урожайность пшеницы в хозяйстве за 30 лет, производительность труда рабочих за смену и т.д. Результаты наблюдений — это в общем случае ряд чисел, расположенных в беспорядке, который для изучения необходимо упорядочить (проранжи- ровать).
Операция, заключающаяся в расположении значений признака по возрастанию, называется ранжированием опытных данных.
После операции ранжирования опытные данные можно сгруппировать так, чтобы в каждой группе признак принимал одно и то же значение, которое называется вариантом (х,). Число элементов в каждой группе называется частотой варианта («,).
Размахом вариации называется число

где хтах — наибольший вариант;
x min — наименьший вариант.
Сумма всех частот равна определенному числу л, которое называется объемом совокупности:

Отношение частоты данного варианта к объему совокупности называется относительной частотой, или частостью, этого варианта:

Последовательность вариант, расположенных в возрастающем порядке, называется вариационным рядом (вариация — изменение).
Вариационные ряды бывают дискретными и непрерывными. Дискретным вариационным рядом называется ранжированная последовательность вариант с соответствующими частотами и (или) частостями.
Пример 1. В результате тестирования группа из 24 человек набрала баллы: 4, 0, 3, 4, 1, 0, 3, 1, 0, 4, 0, 0, 3, 1, 0, 1, 1, 3, 2, 3, 1, 2, 1, 2. Построить дискретный вариационный ряд.
Решение. Проранжируем исходный ряд, подсчитаем частоту и частость вариант: 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 3, 3, 3, 3, 3, 4, 4, 4.
В результате получим дискретный вариационный ряд (табл. 3.10).
Ранжированный ряд успеваемости
Число студентов, л,
Относительная частота, А
В Excel проранжируем исходный ряд. Для этого введем все данные в диапазон А1 :А24 и воспользуемся кнопкой Щ (Сортировка по возрастанию).
Подсчитаем частоту и частость вариант. Построим таблицу в диапазоне D2:G7 (рис. 3.13).

Рис. 3.13. Контекстное меню строки состояния
Рассмотрим два варианта подсчета частот:
- 1) выделим диапазон, в котором находятся нули. Щелкнем в нижней правой части окна Excel правой кнопкой мыши и выберем в контекстном меню вид итога, который по умолчанию будет появляться в итоговой строке при выделении произвольного диапазона (см. рис. 3.13) — количество. Таким образом, последовательно выделяя диапазоны с одинаковыми значениями вариант, мы получим все частоты;
- 2) выполним команду Сервис — Анализ данных — Гистограмма. Заполним диалоговое окно в соответствии с рис. 3.14.

Рис. 3.14. Диалоговое окно инструмента пакета анализа «Гистограмма»
В результате получим таблицу с частотами вариантов и соответствующий график (рис. 3.15).

Рис. 3.15. Результаты применения инструмента «Гистограмма)
Найдем объем выборки, заполнив все частоты вариант в диапазоне ЕЗ:Е7, выделим его левой кнопкой мыши и щелкнем по кнопке ? (автосумма).
В ячейку F3 введем формулу «=ЕЗ/$Е$8», за маркер заполнения (крест в правом нижнем углу ячейки) с помощью мыши скопируем до F7 и выберем кнопку автосумма, в результате получим частоты вариантов и их сумму (1). В ячейку G3 введем частоту варианта 0 — цифру 6 (или ссылку на ячейку, ее содержащую — ЕЗ), в ячейку G4 введем формулу «=G3+E4» и скопируем ее до ячейки G7, в результате получим накопленные частоты. Таким образом, мы получили дискретный вариационный ряд. Естественно, частоты необходимо округлить, но таким образом, чтобы их сумма равнялась 1. Для этого выделим левой кнопкой мыши диапазон частот (F3:F7), щелкнув по правой кнопке, откроем контекстное меню и выполним команду Формат ячеек — Числовой — Число знаков 3 — ОК. Преобразовав обозначения, получим дискретный вариационный ряд, представленный в табл. 3.11.
Источник
Построение рядов распределения
Любой ряд распределения характеризуется двумя элементами:
— варианта(хi) – это отдельные значения признака единиц выборочной совокупности. Для вариационного ряда варианта принимает числовые значения, для атрибутивного – качественные (например, х=«государственный служащий»);
— частота (ni) – число, показывающее, сколько раз встречается то или иное значение признака. Если частота выражена относительным числом (т.е. долей элементов совокупности, соответствующих данному значению варианты, в общем объеме совокупности), то она называется относительной частотойили частостью.
— дискретным, когда изучаемый признак характеризуется определенным числом (как правило целым).
— интервальным, когда определены границы «от» и «до» для непрерывно варьируемого признака. Интервальный ряд также строят если множество значений дискретно варьируемого признака велико.
Интервальный ряд может строиться как с интервалами равной длины (равноинтервальный ряд) так и с неодинаковыми интервалами, если это диктуется условиями статистического исследования. Например, может рассматриваться ряд распределения доходов населения со следующими интервалами:
где k – число интервалов, n – объем выборки. (Конечно, формула обычно дает число дробное, а в качестве числа интервалов выбирается ближайшее целое к полученному число.) Длина интервала в таком случае определяется по формуле
При работе в Excel для построения вариационных рядов могут быть использованы следующие функции:
— СЧЁТ(массив данных) – для определения объема выборки. Аргументом является диапазон ячеек, в котором находятся выборочные данные.
— СЧЁТЕСЛИ(диапазон; критерий) – может быть использована для построения атрибутивного или вариационного ряда. Аргументами являются диапазон массива выборочных значений признака и критерий – числовое или текстовое значение признака или номер ячейки, в которой оно находится. Результатом является частота появления этого значения в выборке.
Проиллюстрируем процесс первичной обработки данных на следующих примерах.
Пример 1.1. имеются данные о количественном составе 60 семей.
Построить вариационный ряд и полигон распределения
Рис.1.1 Пример 1. Первичная обработка статистических данных в таблицах Excel

Далее, подготовим таблицу для построения вариационного ряда, введя названия для столбца интервалов (значений варианты) и столбца частот. В столбец интервалов введем значения признака от минимального (1) до максимального (6), заняв диапазон В12:В17. Выделим столбец частот, введем формулу =ЧАСТОТА(А1:L5;В12:В17) и нажмем сочетание клавиш CTRL+SHIFT+ENTER

Для контроля вычислим сумму частот при помощи функции СУММ (значок функции S в группе «Редактирование» на вкладке «Главная»), вычисленная сумма должна совпасть с ранее вычисленным объемом выборки в ячейке В7.
Теперь построим полигон: выделив полученный диапазон частот, выберем команду «График» на вкладке «Вставка». По умолчанию значениями на горизонтальной оси будут порядковые числа — в нашем случае от 1 до 6, что совпадает со значениями варианты (номерами тарифных разрядов).
Название ряда диаграммы «ряд 1» можно либо изменить, воспользовавшись той же опцией «выбрать данные» вкладки «Конструктор», либо просто удалить.

Пример 1.2. Имеются данные о выбросах загрязняющих веществ из 50 источников:
| 10,4 | 18,6 | 10,3 | 26,0 | 45,0 | 18,2 | 17,3 | 19,2 | 25,8 | 18,7 |
| 28,2 | 25,2 | 18,4 | 17,5 | 41,8 | 14,6 | 10,0 | 37,8 | 10,5 | 16,0 |
| 18,1 | 16,8 | 38,5 | 37,7 | 17,9 | 29,0 | 10,1 | 28,0 | 12,0 | 14,0 |
| 14,2 | 20,8 | 13,5 | 42,4 | 15,5 | 17,9 | 19, | 10,8 | 12,1 | 12,4 |
| 12,9 | 12,6 | 16,8 | 19,7 | 18,3 | 36,8 | 15,0 | 37,0 | 13,0 | 19,5 |
Составить равноинтервальный ряд, построить гистограмму
Внесем массив данных в лист Excel, он займет диапазон А1:J5 Как и в предыдущей задаче, определим объем выборки n, минимальное и максимальное значения в выборке. Поскольку теперь требуется не дискретный, а интервальный ряд, и число интервалов в задаче не задано, вычислим число интервалов k по формуле Стерджесса. Для этого в ячейку В10 введем формулу =1+3,322*LOG10(B7).
Рис.1.4. Пример 2. Построение равноинтервального ряда

Полученное значение не является целым, оно равно примерно 6,64. Поскольку при k=7 длина интервалов будет выражаться целым числом (в отличие от случая k=6) выберем k=7, введя это значение в ячейку С10. Длину интервала d вычислим в ячейке В11, введя формулу =(В9-В8)/С10.
Рис.1.5. Пример 2. Построение равноинтервального ряда

Теперь заполним массив «карманов» при помощи функции ЧАСТОТА, как это было сделано в примере 1.
Рис.1.6. Пример 2. Построение равноинтервального ряда


Мнение эксперта
Витальева Анжела, консультант по работе с офисными программами
Со всеми вопросами обращайтесь ко мне!
Задать вопрос эксперту
Если выбор количества интервалов или их диапазонов не устраивает, то можно в диалоговом окне указать нужный массив интервалов если интервал карманов включает текстовый заголовок, то нужно установить галочку напротив поля Метка. Если же вам нужны дополнительные объяснения, обращайтесь ко мне!
Расчет ширины интервала и таблица интервалов приведены в файле примера на листе Гистограмма . Для вычисления количества значений, попадающих в каждый интервал, использована формула массива на основе функции ЧАСТОТА() . О вводе этой функции см. статью Функция ЧАСТОТА() – Подсчет ЧИСЛОвых значений в MS EXCEL .

Для построений необходимо выделить всю таблицу вместе с заголовком и выполнить команду вкладка Вставка — инструмент Точечная. Выбираем вариант Точечная с гладкими кривыми и маркерами как более показательный.
| 10,4 | 18,6 | 10,3 | 26,0 | 45,0 | 18,2 | 17,3 | 19,2 | 25,8 | 18,7 |
| 28,2 | 25,2 | 18,4 | 17,5 | 41,8 | 14,6 | 10,0 | 37,8 | 10,5 | 16,0 |
| 18,1 | 16,8 | 38,5 | 37,7 | 17,9 | 29,0 | 10,1 | 28,0 | 12,0 | 14,0 |
| 14,2 | 20,8 | 13,5 | 42,4 | 15,5 | 17,9 | 19, | 10,8 | 12,1 | 12,4 |
| 12,9 | 12,6 | 16,8 | 19,7 | 18,3 | 36,8 | 15,0 | 37,0 | 13,0 | 19,5 |
Стиль и внешний вид гистограммы
После того, как вы создали гистограмму, вам может потребоваться внести корректировки в то, как выглядит ваш график. Для изменения дизайна и стиля используйте вкладку “Конструктор”. Эта вкладка отображается на Панели инструментов, когда вы выделяете левой клавишей мыши гистограмму. С помощью дополнительных настроек в разделе “Конструктор” вы сможете:
- добавить заголовок и другие дополнительные данные для отображения. Для того, чтобы добавить данные на график, кликните на пункт “Добавить элемент диаграммы”, затем, выберите нужный пункт из выпадающего списка:




Вы также можете использовать кнопки быстрого доступа к редактированию элементов гистограммы, стиля и фильтров:

Мнение эксперта
Витальева Анжела, консультант по работе с офисными программами
Со всеми вопросами обращайтесь ко мне!
Задать вопрос эксперту
Получили следующий набор данных 18,38,28,29,26,38,34,22,28,30,22,23,35,33,27,24,30,32,28,25,29,26,31,24,29,27,32,24,29,29 Постройте интервальный ряд и исследуйте его. Если же вам нужны дополнительные объяснения, обращайтесь ко мне!
Например:
Для распределения учеников по росту получаем: begin S^2=fraccdot 104,1approx 105,1\ sapprox 10,3 end Коэффициент вариации: $ V=fraccdot 100textapprox 6,0textlt 33text $ Выборка однородна. Найденное значение среднего роста (X_)=171,7 см можно распространить на всю генеральную совокупность (старшеклассников из других школ).
Интервальный вариационный ряд и его характеристики: построение, гистограмма, выборочная дисперсия и СКО
- автоматически рассчитаны интервалы значений (карманы);
- подсчитано количество значений из указанного массива данных, попадающих в каждый интервал (построена таблица частот);
- если поставлена галочка напротив пункта Вывод графика , то вместе с таблицей частот будет выведена гистограмма.
Ряды распределения одна из разновидностей статистических рядов (кроме них в статистике используются ряды динамики), используются для анализа данных о явлениях общественной жизни. Построение вариационных рядов вполне посильная задача для каждого. Однако есть правила, которые необходимо помнить.
Рассмотренные в лабораторной работе 2 распределения вероятностей СВ
опираются на знание закона распределения СВ. Для практических задач такое
знание – редкость. Здесь закон распределения обычно неизвестен, или известен с
точностью до некоторых неизвестных параметров. В частности, невозможно
рассчитать точное значение соответствующих вероятностей, так как нельзя
определить количество общих и благоприятных исходов. Поэтому вводится статистическое
определение вероятности. По этому определению вероятность равна отношению
числа испытаний, в которых событие произошло, к общему числу произведенных
испытаний. Такая вероятность называется статистической частотой.
Связь
между эмпирической функцией распределения и функцией распределения
(теоретической функцией распределения) такая же, как связь между частотой события
и его вероятностью.
Для
построения выборочной функции распределения весь диапазон изменения случайной
величины X (выборки)
разбивают на ряд интервалов (карманов) одинаковой ширины. Число интервалов
обычно выбирают не менее 3 и не более 15. Затем определяют число значений
случайной величины X, попавших
в каждый интервал (абсолютная частота, частота интервалов).
Частота интервалов – число, показывающее сколько раз значения,
относящиеся к каждому интервалу группировки, встречаются в выборке. Поделив эти
числа на общее количество наблюдений (n), находят относительную частоту (частость) попадания
случайной величины X в заданные
интервалы.
По
найденным относительным частотам строят гистограммы выборочных функций
распределения. Гистограмма распределения частот – это графическое
представление выборки, где по оси абсцисс (ОХ) отложены величины интервалов, а
по оси ординат (ОУ) – величины частот, попадающих в данный классовый интервал.
При увеличении до бесконечности размера выборки выборочные функции
распределения превращаются в теоретические: гистограмма превращается в график
плотности распределения.
Накопленная частота интервалов – это число, полученное
последовательным суммированием частот в направлении от первого интервала к
последнему, до того интервала
включительно, для которого определяется накопленная частота.
В Excel для построения выборочных функций распределения
используются специальная функция ЧАСТОТА
и процедура Гистограмма из пакета анализа.
Функция ЧАСТОТА (массив_данных,
двоичный_массив) вычисляет частоты появления случайной величины в интервалах
значений и выводит их как массив цифр, где
•
массив_данных
— это массив или ссылка на
множество данных, для которых
вычисляются частоты;
•
двоичный_массив
— это массив интервалов, по
которым группируются значения выборки.
Процедура
Гистограмма из Пакета анализа выводит
результаты выборочного распределения в виде таблицы и графика. Параметры диалогового окна Гистограмма:
•
Входной диапазон — диапазон исследуемых данных
(выборка);
•
Интервал карманов — диапазон ячеек или набор граничных
значений, определяющих выбранные интервалы (карманы). Эти значения должны быть
введены в возрастающем порядке. Если
диапазон карманов не был введен, то набор интервалов, равномерно распределенных между минимальным и
максимальным значениями данных, будет создан
автоматически.
•
выходной диапазон предназначен для ввода ссылки на левую верхнюю ячейку выходного диапазона.
•
переключатель
Интегральный процент позволяет установить режим включения в
гистограмму графика интегральных
процентов.
•
переключатель
Вывод графика позволяет установить режим автоматического создания встроенной диаграммы на листе, содержащем
выходной диапазон.
Пример 1. Построить эмпирическое распределение веса
студентов в килограммах для следующей
выборки: 64, 57, 63, 62, 58, 61, 63, 70, 60, 61, 65, 62, 62, 40, 64, 61, 59, 59, 63, 61.
Решение
1. В ячейку А1 введите слово Наблюдения,
а в диапазон А2:А21 — значения веса
студентов (см. рис. 1).
2.
В
ячейку В1 введите названия интервалов Вес, кг. В диапазон В2:В8 введите
граничные значения интервалов (40, 45,
50, 55, 60, 65, 70).
3.
Введите
заголовки создаваемой таблицы: в ячейки С1 — Абсолютные частоты, в ячейки D1 — Относительные
частоты, в ячейки E1 — Накопленные частоты.(см. рис. 1).
4.
С
помощью функции Частота заполните столбец абсолютных частот, для этого
выделите блок ячеек С2:С8. С
панели инструментов Стандартная
вызовите Мастер функций (кнопка fx). В появившемся диалоговом окне
выберите категорию Статистические и функцию
ЧАСТОТА, после чего нажмите кнопку ОК. Указателем мыши в рабочее поле Массив_данных
введите диапазон данных наблюдений (А2:А8). В рабочее поле Двоичный_массив
мышью введите диапазон интервалов (В2:В8). Слева на клавиатуре последовательно нажмите комбинацию клавиш Ctrl+Shift+Enter. В столбце C должен появиться массив абсолютных частот (см. рис.1).
5.
В
ячейке C9 найдите общее количество
наблюдений. Активизируйте ячейку С9, на
панели инструментов Стандартная нажмите кнопку Автосумма.
Убедитесь, что диапазон суммирования указан правильно и нажмите клавишу Enter.
6.
Заполните столбец относительных частот. В ячейку введите формулу
для вычисления относительной частоты: =C2/$C$9.
Нажмите клавишу Enter. Протягиванием (за правый
нижний угол при нажатой левой кнопке мыши) скопируйте введенную формулу в диапазон и получите массив относительных частот.
7.
Заполните
столбец накопленных частот. В ячейку D2 скопируйте значение относительной
частоты из ячейки E2. В ячейку D3 введите формулу: =E2+D3. Нажмите клавишу Enter. Протягиванием (за правый нижний угол при нажатой левой кнопке мыши) скопируйте введенную формулу
в диапазон D3:D8. Получим массив накопленных
частот.

Рис. 1. Результат вычислений из
примера 1
8.
Постройте диаграмму относительных и накопленных частот. Щелчком указателя
мыши по кнопке на панели инструментов вызовите Мастер диаграмм. В появившемся диалоговом окне выберите закладку Нестандартные
и тип диаграммы График/гистограмма. После
редактирования диаграмма будет иметь такой вид, как на рис. 2.

Рис. 2
Диаграмма относительных и накопленных частот из примера 1
Задания для самостоятельной работы
1. Для данных из примера 1 построить выборочные функции распределения, воспользовавшись процедурой Гистограмма из пакета Анализа.
2. Построить выборочные функции распределения
(относительные и накопленные частоты) для роста
в см. 20 студентов: 181, 169, 178, 178, 171, 179, 172, 181, 179, 168, 174, 167, 169, 171, 179, 181, 181,
183, 172, 176.
3. Найдите распределение по абсолютным частотам для
следующих результатов тестирования в
баллах: 79, 85, 78, 85, 83, 81, 95, 88, 97, 85 (используйте границы интервалов 70, 80, 90).
4. Рассмотрим любой из критериев оценки качеств педагога-профессионала,
например, «успешное решение задач обучения и воспитания». Ответ на этот вопрос
анкеты типа «да», «нет» достаточно груб. Чтобы уменьшить относительную ошибку
такого измерения, необходимо увеличить число возможных ответов на конкретный
критериальный вопрос. В табл. 1 представлены возможные варианты ответов.
Обозначим
этот параметр через х. Тогда в процессе ответа на вопрос величина х
примет дискретное значение х, принадлежащее определенному интервалу значений.
Поставим в соответствие каждому из ответов определенное числовое значение
параметра х (см. табл. 1).
Табл. 1 Критериальный вопрос: успешное решение задач обучения и воспитания
|
№ п/п |
Варианты ответов |
Х |
|
1 |
Абсолютно неуспешно |
0,1 |
|
2 |
Неуспешно |
0,2 |
|
3 |
Успешно в очень |
0,3 |
|
4 |
В определенной |
0,4 |
|
5 |
В среднем успешно, |
0,5 |
|
6 |
Успешно с |
0,6 |
|
7 |
Успешно, но |
0,7 |
|
8 |
Достаточно успешно |
0,8 |
|
9 |
Очень успешно |
0,9 |
|
10 |
Абсолютно успешно |
1 |
При проведении анкетирования в каждой отдельной
анкете параметр х принимает случайное значение, но только в пределах числового
интервала от 0,1 до 1.
Тогда в результате измерений мы получаем
неранжированный ряд случайных значений (см. табл. 2).
Таблица 2.
Результаты опроса ста учителей

Сгруппируйте полученную выборку, рассчитайте среднее
значение выборки, стандартное отклонение, абсолютную и относительную частоту
появления параметра, а также постройте график плотности вероятности f(x)=

где
W(x) – относительная частота наступления события;

— стандартное
отклонение;

=3,14.
Постройте график функции f(x) и сравните его с
нормальным распределением Гаусса.
Решение математических задач
средствами Excel: Практикум/ В.Я. Гельман. – СПб.: Питер, 2003 — с. 168-172
17 авг. 2022 г.
читать 3 мин
Выборочное распределение — это вероятностное распределение определенной статистики , основанное на множестве случайных выборок из одной совокупности .
В этом руководстве объясняется, как выполнить следующие действия с выборочными распределениями в Excel:
- Сгенерируйте выборочное распределение.
- Визуализируйте распределение выборки.
- Рассчитайте среднее значение и стандартное отклонение выборочного распределения.
- Рассчитайте вероятности относительно выборочного распределения.
Создание выборочного распределения в Excel
Предположим, мы хотим сгенерировать выборочное распределение, состоящее из 1000 выборок, в каждой из которых размер выборки равен 20 и происходит от нормального распределения со средним значением 5,3 и стандартным отклонением 9 .
Мы можем легко сделать это, введя следующую формулу в ячейку A2 нашего рабочего листа:
= NORM.INV ( RAND (), 5.3, 9)
Затем мы можем навести указатель мыши на правый нижний угол ячейки, пока не появится крошечный + , и перетащить формулу на 20 ячеек вправо и на 1000 ячеек вниз:
Каждая строка представляет выборку размера 20, в которой каждое значение получено из нормального распределения со средним значением 5,3 и стандартным отклонением 9.
Найдите среднее значение и стандартное отклонение
Чтобы найти среднее значение и стандартное отклонение этого выборочного распределения средних значений выборки, мы можем сначала найти среднее значение каждой выборки, введя следующую формулу в ячейку U2 нашего рабочего листа:
= AVERAGE (A2:T2)
Затем мы можем навести указатель мыши на правый нижний угол ячейки, пока не появится крошечный + , и дважды щелкнуть, чтобы скопировать эту формулу в каждую другую ячейку в столбце U:
Мы видим, что первая выборка имела среднее значение 7,563684, вторая выборка имела среднее значение 10,97299 и так далее.
Затем мы можем использовать следующие формулы для расчета среднего значения и стандартного отклонения среднего значения выборки:
Теоретически среднее значение выборочного распределения должно быть 5,3. Мы видим, что фактическое среднее значение выборки в этом примере равно 5,367869 , что близко к 5,3.
И теоретически стандартное отклонение выборочного распределения должно быть равно s/√n, что будет равно 9/√20 = 2,012. Мы видим, что фактическое стандартное отклонение выборочного распределения составляет 2,075396 , что близко к 2,012.
Визуализируйте распределение выборки
Мы также можем создать простую гистограмму для визуализации выборочного распределения выборочных средних.
Для этого просто выделите все средние значения выборки в столбце U, щелкните вкладку « Вставка », затем выберите параметр « Гистограмма » в разделе « Диаграммы ».
В результате получается следующая гистограмма:
Мы видим, что распределение выборки имеет форму колокола с пиком около значения 5.
Однако из хвостов распределения мы можем видеть, что некоторые выборки имели средние значения больше 10, а некоторые — меньше 0.
Рассчитать вероятности
Мы также можем рассчитать вероятность получения определенного значения среднего значения выборки на основе среднего значения совокупности, стандартного отклонения совокупности и размера выборки.
Например, мы можем использовать следующую формулу, чтобы найти вероятность того, что среднее значение выборки меньше или равно 6, учитывая, что среднее значение генеральной совокупности равно 5,3, стандартное отклонение генеральной совокупности равно 9 и размер выборки равен:
= COUNTIF (U2:U1001, " <=6 ")/ COUNT (U2:U1001)
Мы видим, что вероятность того, что среднее значение выборки меньше или равно 6, составляет 0,638.
Это очень близко к вероятности, рассчитанной Калькулятором распределения выборки :

Дополнительные ресурсы
Введение в выборочные распределения
Калькулятор распределения выборки
Введение в центральную предельную теорему
 При
При
большом объёме выборки её анализ требует
большого объёма вычислений, поэтому
естественно проводить его за компьютером.
Имеется большое число программных
средств, как специально предназначенных
для статистического анализа, так и
содержащихся в у ниверсальных
ниверсальных
программах в качестве подпрограмм и
опций. Достаточно возможностей для
этого предоставляет, в частности,
доступная всем программаExcel.
Команды для
проведения статистического анализа
можно найти в меню «Сервис![]() Анализ
Анализ
данных» и в меню «Функции![]() Статистические»
Статистические»
и «Функции![]() Работа
Работа
с базами данных».
Т аблица
аблица
1.
Рассмотрим
работу в этой среде на следующем примере.
В лабораторном практикуме группа из 25
студентов определяла концентрацию
некоторого вещества в выданном им
растворе. Каждый из них сделал по 4
параллельных определения. Их результаты,
округлённые до 0,5 г/л я занёс в таблицу
Excel
(табл.1).У
меня образовался массив, содержащий 4
столбца B,C,D
и E,
и 25 строк с №2 до №26. Далее я хочу найти
минимальное число из этого массива –
нижнюю границу выборки. Я щёлкаю по
пустой ячейке, в которой хочу найти
ответ, затем навожу курсор на «![]() »,
»,
и нажимаю левую клавишу мыши. Открывается
окно выбора функций – «Мастер функций».
В разделе «Категории» я открываю
«статистические» и нахожу тамМИН.


После
щелчка мышью по этому названию и “OK”
открывается диалоговое окно «Аргументы
функции» с пометкой МИН.
В окошко,
помеченное «Число 1», можно ввести сами
числа, что, конечно, неудобно. Вместо
этого я щёлкаю мышью по крайней левой
верхней клетке массива, затем нажимаю
“Shift”
и одновременно щёлкаю по крайней правой
нижней клетке. При этом в вышеуказанном
окошке появляются границы массива в
виде “$B$2:$E$26.
Ответ «300,5» появляется сразу, а при
щелчке «OK»
— в заготовленной клетке. Точно так же
я могу применить эту функцию к любой
прямоугольной части этого массива,
вызвав саму функцию МИН
(теперь её
позывной можно найти в категории
«Последние») и отметив, как описано
выше, щелчками мыши, клетки в начале и
конце выбранной части массива. Впрочем,
выделять массив можно и движением мыши,
если сначала навести курсор на начало
массива, нажать левую клавишу мыши, и,
не снимая нажатия, провести курсор до
конечной точки массива.
Конечно,
такое подробное описание вызовет улыбку
у продвинутого пользователя, но, возможно,
среди читателей есть и такие, которые
впервые в жизни откроют документ Excel.
Для
краткого описания действий при
использовании других функций будем
использовать следующие обозначения:
ЩАа
– щелчок по клетке начала диапазона,
ЪЩЯя
— щелчок по клетке конца диапазона с
одновременным нажатием Shift,
ЩСс
– щелчок по свободной ячейке, в которой
будет указан результат.
![]() ,
,
серв., дигр., адат, стат. – щелчки по
значкам
![]() ,
,
«сервис», «диаграмма», «анализ данных»,
«статистические» соответственно.
Напомним, что если какая-либо функция
используется повторно, то быстрее найти
её не через «статистические», а через
«последние».
Итак,
считаем, что в таблицу Excel
внесены
данные выборки в виде строки, столбца,
или двумерного массива. Цели и действия
представлены в таблице 2.
Таблица
2.
|
Что |
Действия |
|
Объём |
ЩСс, |
|
Нижнюю |
ЩСс, |
|
Верхнюю |
ЩСс, |
|
Среднее |
ЩСс, |
|
Моду |
ЩСс, |
|
Медиану |
ЩСс, |
|
Нижний |
ЩСс, |
|
Верхний |
ЩСс, |
|
Выборочную |
ЩСс, |
|
|
ЩСс, |
|
Доверительный |
ЩСс, |
|
Асимметрию |
ЩСс, |
|
Эксцесс |
ЩСс, |
В
таблице 1 в столбцах F—I
вы видите результаты выполнения
соответствующих функций для каждой из
25 строк массива. При этом нет необходимости
вводить формулу функции в каждую строку
отдельно – достаточно ввести её в первую
строку, а в окошко аргументов ввести
координаты начала и конца этой строки:
После
нажатия «![]() »
»
в ячейке, в которую введена данная
формула, появляется соответствующий
результат:

Если
теперь навести курсор на чёрный квадратик
в нижнем правом углу этой ячейки, и при
нажатой левой клавише мыши провести
его вдоль столбца до последней строки
массива данных, то после отпускания
клавиши весь столбец заполнится
результатами, полученными для всех
остальных строк по той же формуле.
Для
группировки данных и получения
интервального ряда можно использовать
функцию ЧАСТОТА.
Для её
применения
сначала
формируем столбец интервалов. Для нашего
примера, в котором объём выборки
![]() ,
,![]() ,
,
удобно выборку разбить на 7 равных
интервалов шириной 3 . При этом в ячейки
для массива интервалов вводим только
значения верхних границ интервалов.
Так, в ячейку![]() я внёс число 303 для интервала
я внёс число 303 для интервала![]() ,
,
в![]() — число 306 для интервала
— число 306 для интервала![]() ,
,
…, в![]() — 321 для интервала
— 321 для интервала![]() .
.
Затем я выделяю свободную ячейку![]() ,
,
и щёлкаю по![]() .
.
Появляется мастер функций, в котором я
нахожуЧАСТОТА
и раскрываю
шаблон для ввода аргументов. После
ввода вышеописанным способом границ
массива данных щёлкаем по окну массив
интервалов и
выделяем для ввода ячейки
![]() .
.
Обратите внимание, что выделена одна
дополнительная ячейка, как этого требует
синтаксис функции.
 После
После
нажатия
![]() в ячейке
в ячейке![]() появляется число вариант со значением
появляется число вариант со значением![]() ,
,![]() .
.
Для вывода остальных значений![]() надо выделить ячейки
надо выделить ячейки![]() ,
,
после чего нажать клавишу![]() ,
,
а затем![]() .
.
В результате в столбце![]() и появятся все компоненты вектора
и появятся все компоненты вектора
частот.
|
ЧАСТОТА |
|
|
303 |
4 |
|
306 |
12 |
|
309 |
23 |
|
312 |
31 |
|
315 |
21 |
|
318 |
7 |
|
321 |
2 |
Рассмотрим
теперь, какие возможности для первичной
обработки выборки имеются в меню
«сервис
![]() анализ данных». Раскроем диалоговое
анализ данных». Раскроем диалоговое
окно«описательная
статистика».
Первая
строка «Входной
интервал»
нам уже знакома: данные в неё можно
внести действиями ЩАа, ЪЩЯя, или
движениями мыши с нажатой правой кнопкой,
или непосредственно введя в окошко
номера левой верхней и правой нижней
ячеек массива, разделённые двоеточием
Аа:Яя. Далее предлагается выбрать
группировку – «По
строкам»
или «По
столбцам».
Дело в том, что эта «описательная
статистика»
может обрабатывать одновременно большое
количество выборок, каждая из которых
может быть введена либо в виде строки,
либо в виде столбца. Поэтому, если мы
выделим массив, содержащий 25 строк и 4
столбца, то программа не
будет рассматривать его как одну выборку,
содержащую 100 вариант. Если мы пометим
окошко «По
столбцам», то
программа будет обрабатывать массив
как 4 выборки по 25 вариант в каждой.
Соответственно, при флажке «По
строкам» мы
получим обработку 25 выборок по 4 варианта.
Далее следует окошко
«Метки в первой строке/столбце». Если
его не помечать, то результаты обработки
каждой из выборок будут помечены
надписями «Строка (Столбец) 1», «Строка
(Столбец) 2», «Строка (Столбец)3»… .Если
же мы хотим , чтобы результаты были
обозначены иначе, (например, фамилиями
студентов), то мы при вводе указаний
массива данных в строку Входной
диапазон должны
захватить и стоящий перед ним столбец
(строку) меток (фамилий или номеров
опытов в данном примере). На этом ввод
данных завершается.
Куда
выводить результаты:
|
Строка1 |
|
|
Среднее |
309,875 |
|
Стандартная |
1,599153422 |
|
Медиана |
309,5 |
|
Мода |
#Н/Д |
|
Стандартное |
3,198306844 |
|
Дисперсия |
10,22916667 |
|
Эксцесс |
-0,02453947 |
|
Асимметричность |
0,598903954 |
|
Интервал |
7,5 |
|
Минимум |
306,5 |
|
Максимум |
314 |
|
Сумма |
1239,5 |
|
Счет |
4 |
Параметры
вывода. Обычно при открытии
диалогового окна активизировано окошко
Новый рабочий лист.
Это означает, что результаты будут
выведены на новом листе, номер которого
при желании можно задать, так же как и
номер новой книги в окошке Новая
рабочая книга. Если же
надо поместить результаты на исходном
листе, то надо активизировать окошко
Выходной интервал,
после чего щёлкнуть по свободной ячейке,
которая будет левой верхней ячейкой
выходного массива.
Что
выводить.
При
установке флажка
«Итоговая статистика» для
каждой выборки будет выведена таблица
такого вида:
В
этой таблице под стандартным отклонением
понимается величина выборочного
стандарта
![]() ,
,
под стандартной ошибкой – выборочный
стандарт среднего![]() ,
,
интервал – разность между максимальным
и минимальным значениями выборки, сумма
– сумма всех значений выборки, счёт –
объём выборки. Остальные термины
пояснения не требуют.
Если
активизировать окошко «Уровень
надёжности»,
то выводится строка со значением
полуширины симметричного доверительного
интервала, соответствующим указанной
в этом окошке доверительной вероятности
и равным произведению
![]() на соответствующий квантиль распределения
на соответствующий квантиль распределения
Стьюдента:
|
Уровень |
5,089219898 |
Активизация
окошек К-ый
наименьший и
К-ый наибольший позволяет
выводить к-ое в порядке возрастания и
(или) к-ое в порядке убывания значения
в выборке, соответствующие указанным
номерам. Значениям к=1 соответствуют
минимальное и максимальное значения
вариант.

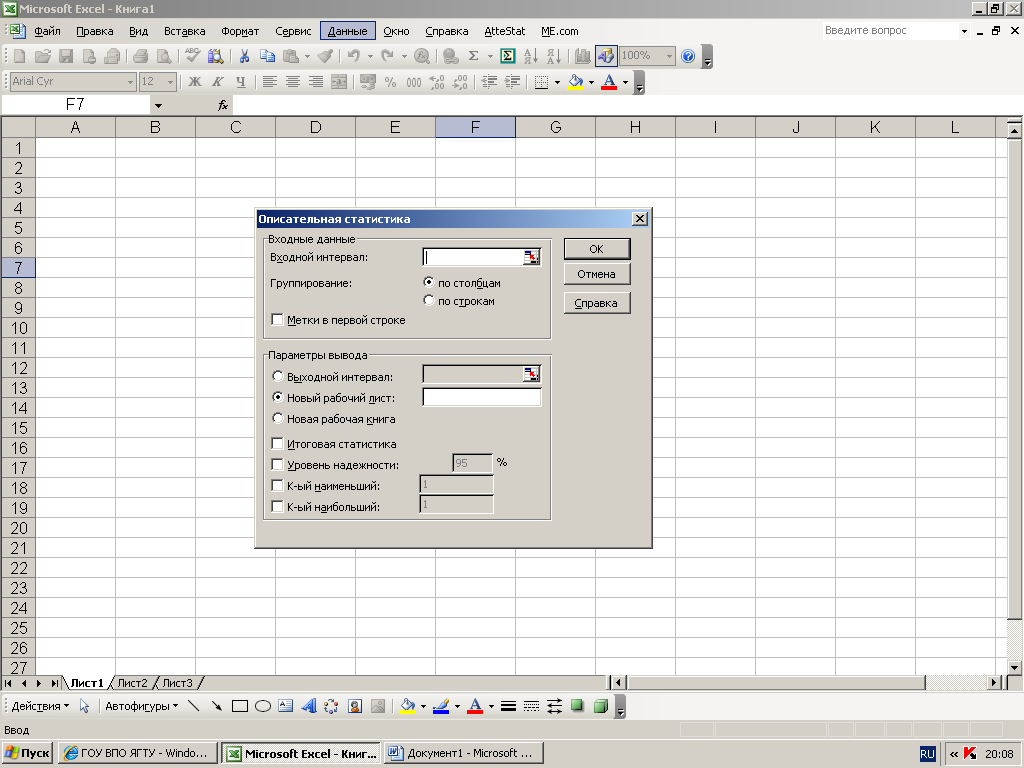
Обратимся
теперь к графическому изображению
данных. Для этого в меню Анализ
данных есть
функция Гистограмма,
в диалоговом окне которой в окошко
Входной
интервал вводим
одним из описанных ранее способов номера
ячеек начала и конца массива данных.
Затем в окошко Интервал
карманов вводим
таким же образом номера массива, в
котором указаны верхние границы
интервалов, на которые мы решили разбить
выборку (см. выше описание функции
Частота).
Флажок Метки
надо устанавливать только в том случае,
если в массив данных включён и столбец
меток. Как и в вышеописанных функциях
ставим флажок Новый
лист или
Новая книга (с
указанием номера или без), или Выходной
интервал. В
последнем случае в активизированное
окошко вводим номер левой верхней ячейки
диапазона вывода результата. Игнорируя
надпись Парето,
помечаем
Интегральный процент и
Вывод графика.
![]() выводит нам
выводит нам
во-первых,
таблицу, два первых столбца, как и после
исполнения функции Частота
представляют
интервальный вариационный ряд, а третий
столбец – аналог интегральной функции
распределения, показывает долю вариант
в выборки, имеющих значение меньшее или
равное указанного в первом столбце.
Кроме этого, появляется и графическое
изображение – гистограмма и график
интегрального процента. Можно редактировать
это изображение, но здесь мы не будем
рассматривать все многочисленные
возможности этого.


Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #